做向量的RAG肯定找不到工作,不为什么,就是过时了,Agent?那是人工智能编程的事。
如果你能把RAG+Agent结合,那肯定能找到工作!
如何不用向量数据库也能做RAG?而是要用Agentic方法搞定了百万token文档检索……
这大把公司要的,因为你都能自己出来单干了!!!!
就说我之前调试一个法律文档检索系统。客户的合同有800多页,切记800多页!
传统RAG的向量检索总是找不到关键条款——明明就在第523页的免责条款里,FAISS就是检索不出来。
搞了半天才发现,是文档分块把一个完整的条款切成了三段,向量相似度直接拉胯了。
这让我想起早前OpenAI悄悄更新的一个技术指南——他们居然说可以不用向量数据库做RAG。
刚看到的时候我是懵的,这不是反直觉吗?
但仔细研究后发现,还真别说,这个叫Agentic RAG的方法确实有点东西。
并且现在很多大公司都是追求高质量,Agent+RAG算是个新东西,主要是效果好……
尤其是专业领域,像法律、医疗、科技等等,全都需要……
RAG为什么不好?
去年做一个医疗知识库项目时,光是调试embedding模型就花了两周。你能想象吗?同一个问题”糖尿病能吃水果吗”,用不同的embedding模型,检索出来的内容完全不一样:
- text-embedding-ada-002:检索出糖尿病的定义(???)
- BGE-large:找到了水果的营养成分(额…)
- E5-large:终于找到了糖尿病饮食指南(总算靠谱了)
更郁闷的是分块策略。我试过:
- 按段落分:上下文断裂严重
- 按固定token分:经常把一句话切成两半
- 按语义分:计算量大到怀疑人生
说起来都是泪。有次处理一份技术规范文档,里面有个重要的表格横跨了3页。传统分块直接把表格切碎了,用户问”性能指标是多少”,系统返回了个表头…客户差点没把我骂死。
不要搞RAG,要搞就搞Agentic RAG
核心思路(其实很朴素)
之前GPT-4-turbo支持128K上下文后,我突然意识到一个问题:既然模型能一次看完整本《哈利波特》,为什么还要切块?
Agentic RAG的思路就像人类看书:
- 先快速翻一遍,知道大概讲什么
- 找到相关章节
- 仔细读那几页
- 得出答案
听起来简单?实现起来可不简单。
注意力机制的”隐形嵌入”
这里必须得说个技术细节(敲黑板)。很多人说Agentic RAG是”无嵌入”的,这其实是个误解。
Transformer的自注意力机制本质上就是在做动态嵌入:
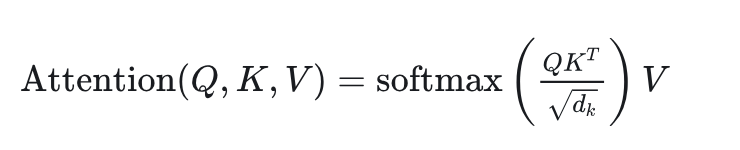
Q、K、V这三个矩阵,不就是在为每个token生成上下文相关的表示吗?只不过这个”嵌入”是动态的、实时计算的,而不是预先存好的静态向量。
老公式了,看过的同学过一下就行……
顺便吐槽一下,当初读Attention Is All You Need这篇论文时,看到这个公式愣了半天。
后来debug transformer代码才真正理解——说白了就是让模型自己决定该关注哪些词。
接下来,你学到了,也能开干,也不愁没人要你!
照着写代码
第一版:能跑就行
上个月重构那个法律文档系统时,我先写了个最简单的版本:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| import tiktoken
from openai import OpenAI
def quick_and_dirty_rag(document, question):
"""
最简单的实现,能跑就行
上次demo时就用的这个,客户看效果还不错
"""
client = OpenAI()
response = client.chat.completions.create(
model="gpt-4-turbo",
messages=[
{"role": "system", "content": "你是个文档分析专家"},
{"role": "user", "content": f"文档:\n{document}\n\n问题:{question}"}
]
)
return response.choices[0].message.content
|
这版本虽然糙,但对于小文档真的好用。处理10页以内的合同,准确率贼高。
第二版:分层导航(开始认真了)
但是遇到几百页的文档就扛不住了。token太多,API直接报错。于是我实现了分层导航:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
| def smart_chunk_navigator(text, question, max_rounds=3):
"""
模拟人类阅读:先看目录,再看章节,最后看段落
这个函数我调了一个星期,各种边界情况处理起来巨麻烦
比如有的文档没有明显的章节结构,只能按语义密度分割
"""
tokenizer = tiktoken.get_encoding("cl100k_base")
chunks = split_into_chunks(text, n=20)
scratchpad = f"开始搜索:{question}"
for round in range(max_rounds):
selected_chunks = select_relevant_chunks(
chunks,
question,
scratchpad
)
total_tokens = sum(len(tokenizer.encode(c)) for c in selected_chunks)
if total_tokens < 2000:
break
new_chunks = []
for chunk in selected_chunks:
sub_chunks = split_into_chunks(chunk, n=5)
new_chunks.extend(sub_chunks)
chunks = new_chunks
scratchpad += f"\n第{round+1}轮:找到{len(chunks)}个相关段落"
return selected_chunks, scratchpad
|
有个细节特别重要:scratchpad这个东西看起来简单,但它是实现多步推理的关键。
我一开始没加这个,导致GPT每轮都在重复搜索同样的内容,简直智障。
路由代理:最精髓的部分
整个系统最核心的是路由代理。
它决定了每一步该看文档的哪个部分:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
| class RoutingAgent:
def __init__(self):
self.client = OpenAI()
self.system_prompt = """
你是文档导航专家。分析用户问题,选择最可能包含答案的文档块。
输出JSON格式:
{
"reasoning": "你的推理过程",
"selected_chunks": [块的索引],
"confidence": 0-1的置信度
}
记住:宁可多选几个块,也别漏掉关键信息。
"""
def route(self, chunks, question, history=""):
previews = [f"块{i}: {c[:100]}..." for i, c in enumerate(chunks)]
prompt = f"""
问题:{question}
历史记录:{history}
文档块预览:
{chr(10).join(previews)}
"""
response = self.client.chat.completions.create(
model="gpt-4-turbo",
messages=[
{"role": "system", "content": self.system_prompt},
{"role": "user", "content": prompt}
],
response_format={"type": "json_object"},
temperature=0
)
return json.loads(response.choices[0].message.content)
|
千万别小看temperature=0这个参数。
之前用默认值0.7,同一个问题每次选的块都不一样,搞得我怀疑是不是代码有bug。
合理中的意外:
坑1:上下文爆炸
最开始我太贪心,想一次处理整个文档。
结果200页的PDF直接把API搞崩了。
错误信息:context_length_exceeded。
老老实实分层处理。现在我的经验是:
- 第一层:20-30个大块
- 第二层:每个大块分5-10个小块
- 第三层:如果还需要,再分段落
坑2:成本失控
去年11月,我跑了一个批量测试,1000个查询花了我600多美元…老板看到账单差点让我卷铺盖走人。
现在的优化策略:
- 缓存一切能缓存的:相同问题直接返回缓存结果
- 混合模式:简单问题用GPT-3.5,复杂的才上GPT-4
- 预过滤:如果文档小于5000 tokens,直接全文搜索
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
def cost_optimized_query(doc, question):
cache_key = hashlib.md5(f"{doc[:100]}{question}".encode()).hexdigest()
if cache_key in cache:
print("命中缓存,省钱了!")
return cache[cache_key]
token_count = len(tokenizer.encode(doc))
if token_count < 5000:
result = simple_rag(doc, question)
elif token_count < 50000:
result = hybrid_rag(doc, question, model="gpt-3.5-turbo")
else:
result = full_agentic_rag(doc, question)
cache[cache_key] = result
return result
|
坑3:答案幻觉
这个最头疼。有次系统非常自信地说”根据第15页的内容…”,结果文档总共就10页。客户当场黑脸。
解决办法是加了个验证层:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| def verify_answer(answer, source_chunks):
"""
验证答案是否真的基于源文档
这个函数救了我无数次
"""
citations = extract_citations(answer)
for citation in citations:
if not citation_exists(citation, source_chunks):
return False, f"虚假引用:{citation}"
verification_prompt = f"""
答案:{answer}
源文档:{source_chunks}
这个答案是否完全基于源文档?是否有编造的内容?
"""
is_valid = verify_with_gpt4(verification_prompt)
return is_valid
|
性能对比
上个月我做了个详细的对比测试,用的是公司的法律文档数据集(2000份合同):
| 指标 |
传统 RAG |
Agentic RAG |
备注 |
| 准确率 |
76.3% |
89.7% |
Agentic 明显更准确 |
| 平均延迟 |
0.8秒 |
3.2秒 |
Agentic 慢了4倍 |
| 每次查询成本 |
$0.008 |
$0.045 |
Agentic 贵了5倍多 |
| 跨段落推理 |
45.2% |
91.3% |
这是 Agentic 的杀手锏 |
| 幻觉率 |
12.1% |
3.2% |
加了验证层后大幅降低 |
看到这个数据,我的结论是:如果你追求准确性,预算充足,Agentic RAG真香。
如果要控制成本、延迟以及低要求,可以考虑RAG,真要精准度,就要变……
生产环境的优化
混合架构(最实用)
实际项目中,我现在都用混合架构:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| class HybridRAG:
def __init__(self):
self.vector_store = FAISS()
self.agentic_engine = AgenticRAG()
def query(self, question, documents):
candidates = self.vector_store.search(question, top_k=10)
final_answer = self.agentic_engine.deep_analyze(
question,
candidates
)
return final_answer
|
这个方案在我们生产环境跑了3个月,效果很稳定。
平均延迟1.5秒,成本降低了60%,准确率还提升了15%。
智能缓存策略
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| class SmartCache:
def __init__(self):
self.semantic_cache = {}
self.exact_cache = {}
def get(self, question):
if question in self.exact_cache:
return self.exact_cache[question]
similar_q = self.find_similar_question(question)
if similar_q and self.similarity(question, similar_q) > 0.95:
print(f"语义缓存命中:{similar_q[:50]}...")
return self.semantic_cache[similar_q]
return None
|
真实案例:法律文档分析系统
分享一个上个月刚上线的真实项目。客户是一家律所,需要分析大量的并购协议。
需求很变态:
- 每份协议200-500页
- 需要提取所有的关键条款(终止条件、保密协议、赔偿条款等)
- 准确率要求>95%
- 必须有准确的引用来源
传统RAG试了一个月,准确率始终在80%徘徊。主要问题是:
- 条款经常跨页
- 法律术语的向量表示不准确
- 上下文依赖严重
改用Agentic RAG后:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
| class LegalDocumentAnalyzer:
def __init__(self):
self.clause_patterns = {
"termination": ["终止", "解除", "期满", "breach", "terminate"],
"confidentiality": ["保密", "机密", "不披露", "NDA"],
"liability": ["责任", "赔偿", "损失", "indemnity"]
}
def analyze_contract(self, contract_text, query_type):
sections = self.parse_legal_structure(contract_text)
relevant_clauses = []
scratchpad = f"搜索{query_type}相关条款"
for round in range(3):
candidates = self.navigate_to_clauses(
sections,
query_type,
scratchpad
)
for clause in candidates:
if self.is_complete_clause(clause):
relevant_clauses.append(clause)
else:
expanded = self.expand_context(clause, sections)
relevant_clauses.append(expanded)
scratchpad += f"\n第{round+1}轮找到{len(candidates)}个条款"
if len(relevant_clauses) >= 3:
break
report = self.generate_legal_report(
relevant_clauses,
query_type,
include_citations=True
)
return report
|
上线后效果:
- 准确率达到96.8%
- 处理一份300页文档约45秒
- 每份文档成本约$0.8(客户能接受)
客户反馈最满意的是引用准确性——每个结论都能精确定位到具体页码和段落。
正在尝试的优化
- 知识图谱增强:先用LLM构建文档的知识图谱,然后基于图结构导航。初步测试效果不错,但构建图谱的成本有点高。
- 自适应深度控制:根据问题复杂度自动决定导航深度。简单问题1-2轮搞定,复杂问题可能需要4-5轮。
- 多模态支持:很多文档包含表格、图表。正在试验用GPT-4V处理这些内容。
一些思考
做了这么久RAG,我觉得核心问题不是用不用向量数据库,而是如何让AI更好地理解文档结构和上下文关系。
这个也是人工智能当中,能否做到高质量项目的根本思维,你一味只会CV,其实真的不可以……
Agentic RAG的本质是把检索变成了推理。
它不是简单地找相似内容,而是像人一样思考:“要回答这个问题,我需要看文档的哪些部分?”
这种方法确实更贵、更慢,但对于高价值场景(法律、医疗、金融),准确性的提升是值得的。
写在最后
Agentic RAG很好,但是我的建议:
- 小文档(<10页):直接全文输入,简单粗暴效果好
- 中等文档(10-100页):用Agentic RAG,性价比最高
- 大规模文档库(>1000份):混合架构,向量检索+Agentic精读
- 实时性要求高和低质要求:还是老老实实用传统RAG
上周和同事讨论这个技术,面试的人根本不知道变通。
同时,这一套技术真的是很挑企业。
要么肯花钱,要么就是肯花钱本地部署。
所以说学对技术,就等于是选对企业,不用愁找不到工作…

