查询转换:让提问精准匹配知识库
多查询重写:针对用户表述模糊
思路:将原始输入转化为多个变体的问题查询
假设文档法( HyDE ) :用户问题和知识库差异大
思路:先生成一个理想的、假设的答案,然后将这个答案向量化后与知识库匹配,弥补了原始问题和真实答案之间的语义鸿沟
问题与应对:如果生成的假设文档和真实文档的匹配相似度低(比如:<0.7),系统会触发“二次检索”,换一种方式再找一遍。
问题分解和回退:针对复杂问题和无直接答案
思路:如果原始查询是一个太复杂或者知识库中没有具体答案的问题,系统不会放弃回答,而是“尝试拆解”大问题到小问题,或者“退一步”找个更宽泛的答案。
“退一步”找个更宽泛的答案,是因为前边的所有的提问都没法命中,一种兜底的策略。
分解策略选择表:
| 问题类型 |
策略 |
案例说明 |
| 多步骤推理 |
串行分解 |
“RAG流程?” -> 分解成“检索阶段”和“生成阶段” |
| 跨领域问题 |
并行分解 |
“AI医疗应用?” -> 分解成 “AI技术”和“医疗应用” |
| 细节查询失败 |
抽象回退 |
“特斯拉Q3财报?” -> 回退为“查找新能源企业财报?” |
伪代码:
1
2
3
4
5
6
7
8
9
| def decompose_query(query):
if is_multi_step(query):
return split_into_steps(query)
elif is_cross_domain(query):
return split_into_domains(query)
elif is_too_specific(query):
return generalize_query(query)
else:
return [query]
|
路由优化:构建智能分发网络
构建一个问答系统时,不能把所有的问题都交给同一个模型来处理。针对不同的问题要交给不同的“领域专家模型”来处理,这就引出来“路由优化”方法,同时针对每个“领域专家模型”的回答也不能用同一个Prompt模板来回复,所以引出来“Prompt路由”方法。
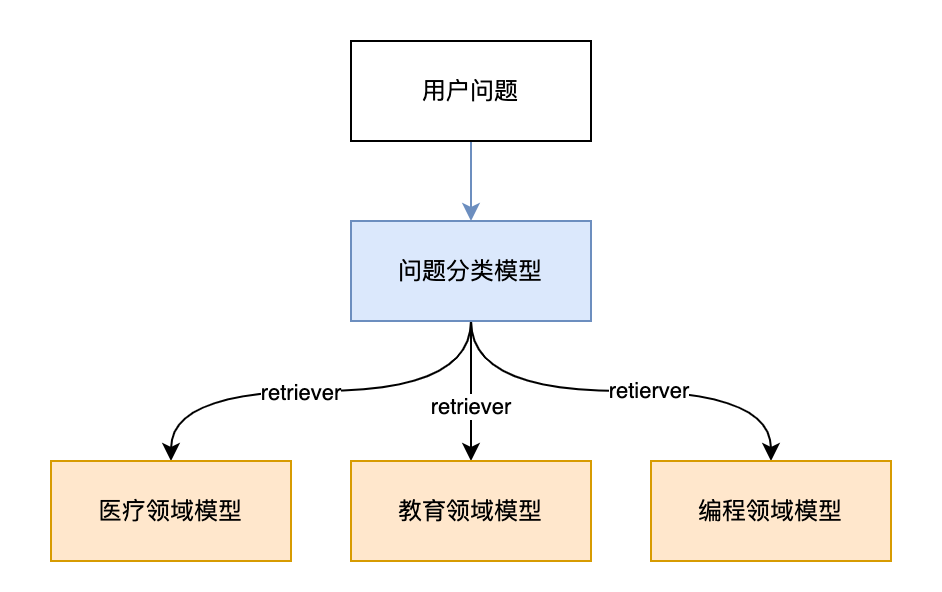
元数据路由引擎
思路:类似于一个问题的“智能分拣中心”,这里的元数据指的是问题的元数据,比如问题的分类标签、问题类型等。
举例说明:用户问题是一个“快递”,元数据路由引擎会根据问题的内容,去分析Meta-Data元数据(比如问题类型),判断问题属于哪个领域(比如:医疗、教育、编程等),然后把问题交给特定的“领域专家模型”来进行处理。
伪代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
def llm_classify(query):
if "病" in query or "医生" in query:
return "medical"
elif "代码" in query or "函数" in query:
return "code"
else:
return "default"
def medical_retriever(query):
return f"[医疗检索] 正在查找与 '{query}' 相关的医学资料..."
def code_retriever(query):
return f"[代码检索] 正在查找与 '{query}' 相关的编程资料..."
def default_retriever(query):
return f"[通用检索] 正在查找与 '{query}' 相关的一般资料..."
def route_query(query):
topic = llm_classify(query)
if topic == "medical":
return medical_retriever(query)
elif topic == "code":
return code_retriever(query)
else:
return default_retriever(query)
print(route_query("我最近总是头痛,可能是什么原因?"))
|
关键参数说明
动态Prompt路由
思路:Prompt是给模型的“答题模板”,不同的答案需要不同的回复模板。
- 技术人员喜欢看代码和架构图
- 学生希望有通俗易懂的解释
- 商务人士希望简洁明了的总结
实现流程

伪代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
| from sklearn.metrics.pairwise import cosine_similarity
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('paraphrase-MiniLM-L6-v2')
prompt_templates = {
"technical": "请用数学公式和架构图解释{query}",
"educational": "请用通俗易懂的语言解释{query}",
"business": "请用简洁明了的方式总结{query}"
}
user_query = "解释Transformer注意力机制"
query_embedding = model.encode([user_query])
template_embeddings = model.encode(list(prompt_templates.values()))
similarities = cosine_similarity(query_embedding, template_embeddings)
best_index = similarities.argmax()
best_template = list(prompt_templates.keys())[best_index]
best_score = similarities[0][best_index]
if best_score > 0.8:
print(f"匹配成功:使用 {best_template} 模板,相似度 {best_score:.2f}")
final_prompt = prompt_templates[best_template].format(query=user_query)
print("生成的Prompt:", final_prompt)
else:
print("没有找到合适的模板")
|
输出示例
1
2
| 匹配成功:使用 technical 模板,相似度 0.87
生成的Prompt:请用数学公式和架构图解释解释Transformer注意力机制
|
索引优化:知识库的智能重构
多表征索引 ( Multi-Representation )
什么是表征(Representation)?
简单来说,表征就是将现实世界中的信息(如:文字、语音、图片等)转换成机器可以理解和计算的数据形式(即向量或者张量)
本质:一种信息的编码,计算机只能处理数字。它将原始、复杂、高维的数据(例如一段文字、一张图片)映射到一个低纬、连续的向量空间中。
思路:给知识库的每一段内容,从不同的角度“拍照”,每张照片都是一种理解的方式。用户搜索时就会有更高的几率去命中匹配。
多表征索引流程图
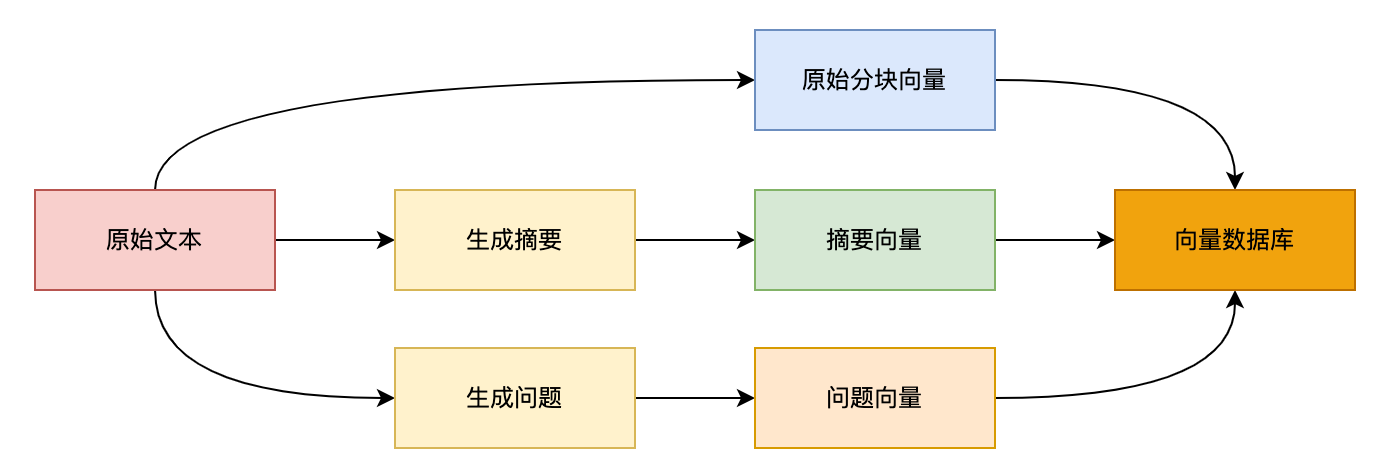
多表征索引策略
| 嵌入类型 |
拍照方式 |
作用说明 |
| 原始分块 |
把文本按固定长度切开 |
保留原始信息,就像原图一样清晰 |
| 摘要向量 |
用模型生成摘要 |
抓住整体意思,像看图说故事一样 |
| 问题向量 |
模型模拟用户可能问的问题 |
提高匹配度,像提前猜到你想问啥 |
举例说明
假设你有一段关于“人工智能”的内容,多表征索引生成三重嵌入策略如下:
- 原始分块就是原文本。
- 摘要向量是大模型生成的摘要“人工智能是模拟人类智能的技术”类似的内容向量。
- 问题向量是大模型生成的“什么是人工智能?”、“AI有哪些应用?”这些用户可能问的问题。
存储优化:三重嵌入策略的向量存储方式
FAISS是一个高效的向量数据库。
| 嵌入类型 |
生成方式 |
存储优化 |
| 原始分块 |
文本分割 |
FAISS-IVF |
| 摘要向量 |
T5生成摘要 + 嵌入 |
量化索引(PQ) |
| 问题向量 |
GPT生成“可能被问的问题” |
HNSW图索引 |
注意,表中IVF_PQ是它的一种压缩索引方式。
- 类比:就像把高清图片压缩成小图,既节省空间又不影响查找。
- 效果:内存占用减少4倍,相当于把100G的数据压缩到25G。
IVF_PQ 和 HNSW 的性能收益:
- 内存占用降低4倍(IVF_PQ量化)
- 检索速度提升3倍(HNSW近邻搜索)
RAPTOR分层索引 ( 处理超长文档 )
RAPTOR:Recursive Abstractive Processing for Tree-Organized Retrieval,通过递归抽象化构建一个树结构的索引。
RAPTOR是将大模型的文本生成能力(用户总结)和检索系统的多层结构(用于索引)完美结合的表现。
RAG的工作方式和痛点?
- 传统RAG:将长文档切分为固定大小的扁平化(Flat)文档块(Chunk),对每个文档块embedding并存储到向量数据库。
- 局限性:
- 丢失高层次语义:只能检索到具体的、低层次的细节。当用户询问涉及到文档的主题、跨章节的概念等高层次问题时,传统的RAG往往无法准确查询。
- 上下文窗口限制:检索出的文档块数量有限,难以将整个文档的背景信息纳入到大模型的上下文(Context)。
RAPTOR思路:构建一个多阶段、递归式的索引过程,最终形成一个金字塔式的知识结构。
RAPTOR流程图

索引构建过程:从下到上的递归抽象
检索过程:从上到下的分层检索和融合
当用户查询时,RAPTOR可以根据查询的性质,灵活的在树状结构中进行检索:
伪代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
|
MAX_CHUNK_SIZE = 512
CLUSTERING_METHOD = "HDBSCAN"
EMBED_MODEL = EmbeddingModel("BGE-M3")
LLM_SUMMARIZER = LLM("GPT-4o-mini")
MAX_RECURSION_DEPTH = 3
ALL_INDEX_NODES = []
def build_raptor_tree_recursive(current_texts: list[str], current_depth: int):
"""
递归地将文本列表聚类、总结,并构建树的下一层。
Args:
current_texts (list[str]): 当前层级的文本列表 (可能是原始Chunk或上一层的Summary)。
current_depth (int): 当前递归深度。
"""
if not current_texts or current_depth > MAX_RECURSION_DEPTH:
return []
print(f"\n--- 正在处理第 {current_depth} 层级 ({len(current_texts)} 个节点) ---")
current_embeddings = EMBED_MODEL.encode(current_texts)
clusters = cluster_texts(current_embeddings, method=CLUSTERING_METHOD)
next_layer_summaries = []
for cluster_id, text_indices in clusters.items():
clustered_texts = [current_texts[i] for i in text_indices]
prompt = f"请对以下相关文本进行高度抽象的总结和概括:\n\n{clustered_texts}"
summary_text = LLM_SUMMARIZER.generate(prompt)
summary_node = {
"text": summary_text,
"level": current_depth + 1,
"source_nodes": [current_texts[i] for i in text_indices]
}
next_layer_summaries.append(summary_text)
ALL_INDEX_NODES.append(summary_node)
print(f" - 生成了 {cluster_id} 簇的高层总结。")
if next_layer_summaries:
return build_raptor_tree_recursive(next_layer_summaries, current_depth + 1)
else:
return next_layer_summaries
def raptor_indexing_pipeline(raw_document_text: str):
initial_chunks = split_text_into_chunks(raw_document_text, MAX_CHUNK_SIZE)
for chunk in initial_chunks:
ALL_INDEX_NODES.append({"text": chunk, "level": 0, "source_nodes": []})
print(f"原始文档切分为 {len(initial_chunks)} 个 Chunk。")
build_raptor_tree_recursive(initial_chunks, current_depth=0)
print("\n--- RAPTOR 索引构建完成 ---")
print(f"总共创建了 {len(ALL_INDEX_NODES)} 个可检索节点(包括原始 Chunk 和所有 Summary)。")
return ALL_INDEX_NODES
def split_text_into_chunks(text: str, chunk_size: int) -> list[str]:
return [f"Chunk {i+1}: {text[i*chunk_size:(i+1)*chunk_size]}" for i in range(len(text)//chunk_size + 1)]
DOCUMENT = "大型语言模型(LLM)的兴起推动了检索增强生成(RAG)技术的发展。RAG通过引入外部知识库来解决LLM的幻觉问题。然而,传统的RAG面临着长文档的高层次语义丢失的挑战。RAPTOR方法通过递归地聚类和总结文档块,构建了一个分层的树状索引。这个索引在查询时能够同时提供细节和抽象信息,从而提高了复杂问答的准确性。RAPTOR的构建过程包括初始分块、基于嵌入向量的语义聚类,以及使用LLM进行抽象总结,这个过程会重复进行,直到达到预设的抽象层级。"
raptor_index = raptor_indexing_pipeline(DOCUMENT)
print("\n--- 检索流程(概念) ---")
QUERY = "RAG技术的局限性以及RAPTOR是如何解决的?"
print(f"查询 '{QUERY}' 将会同时匹配到底层的 RAG 局限性细节和高层的 RAPTOR 解决总结。")
|
分块优化黄金法则
分块就像切蛋糕,切得太大吃起来不方便;切得太小,又容易丢失整体的味道。
分块大小建议
| 嵌入模型 |
最佳分块长度 |
重叠区间 |
| text-embedding-ada-002 |
256 token |
50 token |
| bge-large-zh |
512 token |
100 token |
重叠部分:前后两部分重叠,避免断句导致信息丢失。
语义分块器 (Semantic Chunker)
1
2
| from langchain_experimental.text_splitter import SemanticChunker
splitter = SemanticChunker(embeddings, breakpoint_threshold=0.7)
|
- embeddings:模型对文本的理解来源
- breakpoint_threshold:设定一个“语义断点”的阈值,超过这个值就切开。
流程图

RAG策略优化:混合检索 + 重排序 + Self-RAG自检
生成控制:工业级部署关键
性能优化和基准测试
RAG优化落地检查表

