从“能聊”到“能干”:一部AI Agent的进化史——深度拆解Function Calling、MCP与Anthropic Skills的演进之路
序章:AI的“巴别塔”困境
在2023年之前,大型语言模型(LLM)的世界更像是一座座信息孤岛。它们是博学的“数字鹦鹉”,被囚禁在自己庞大的训练数据之中。
你可以问它“法国的首都是哪里?”,它能对答如流;
但你若让它“帮我订一张去巴黎的机票”,它只能抱歉地告诉你:“我只是一个语言模型,无法执行现实世界中的操作。”
这就是当时整个行业面临的“巴别塔”困境——AI能“说”不能“做”。
AI与现实世界的工具、数据库和API之间,语言不通,无法协作。如何打破这堵无形的墙,让AI从一个“知识库”进化成一个真正的“行动者”?这成为了所有顶尖AI实验室必须回答的核心问题。
这篇长文,将带您穿越这段波澜壮阔的技术演进史,从最初的破冰之举,到行业标准的建立,再到专家知识的注入,一步步见证AI智能体(Agent)如何学会“动手”,真正地“能干活”。
第一章:黎明前的破晓 —— Function Calling/Tool Use的诞生
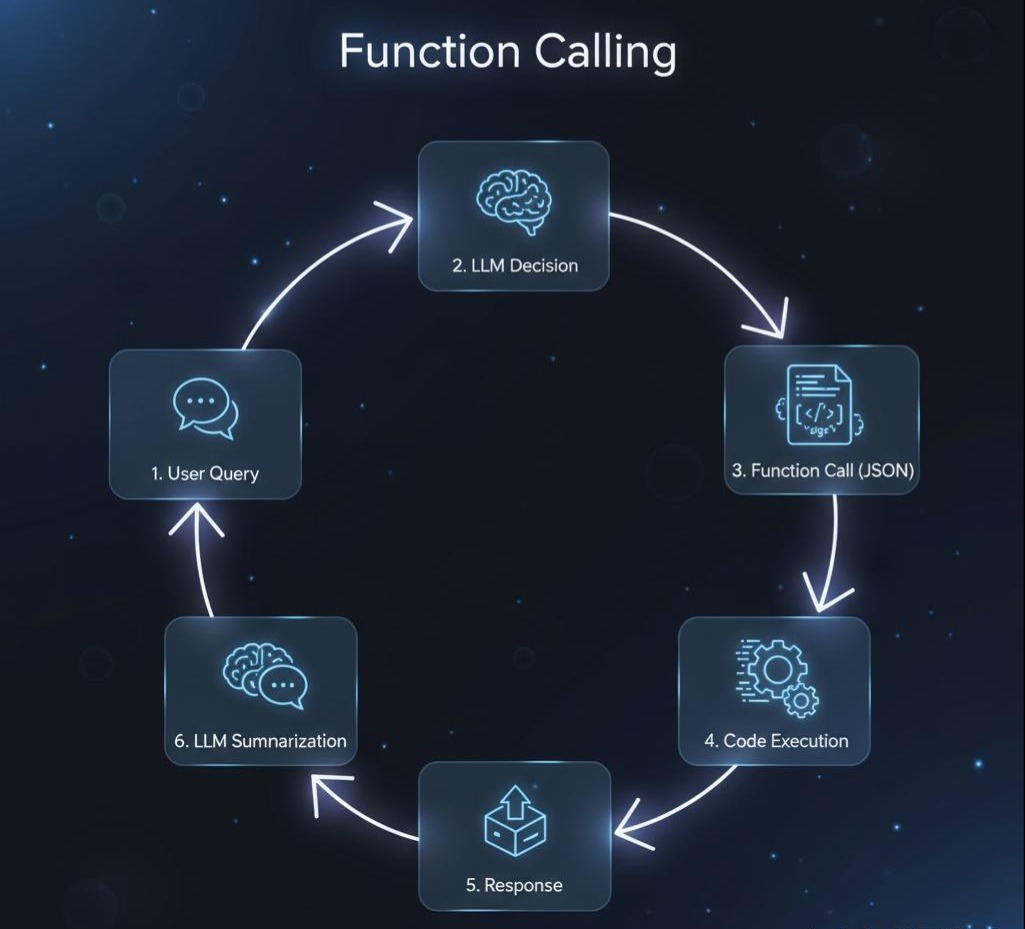
大约在2023年中期,以OpenAI为代表的公司率先迈出了革命性的第一步,推出了函数调用(Function Calling),后来被更广泛地称为工具使用(Tool Use)。这不亚于在AI的“巴别塔”上凿开的第一扇窗。
1.1 核心原理:AI的“意图翻译器”
Function Calling的逻辑非常精妙。它并非让AI自己去运行代码,而是赋予了AI一种新的能力:将人类的自然语言指令,翻译成机器可以理解的、结构化的“工作指令”(即JSON)。

其工作流程就像一位聪明的助理和一位执行者:
- 开发者提供工具说明书:开发者在系统提示词中用特定格式(JSON Schema)向AI模型“描述”自己拥有的工具,告诉AI“我们有这些工具,它们能干什么,需要什么参数”。
- AI助理理解意图:当用户下达指令时(如“查天气”),AI助理利用其强大的语言能力,判断这个指令能用哪个工具来完成。
- AI助理填写工作单(JSON):AI助理不会亲自去做,而是会生成一份标准的“工作单”(JSON对象),清晰地写明:“请调用
getCurrentWeather这个工具,参数是北京”。 - 执行者执行任务:你的应用程序(后端)拿到这份工作单,解析并真正地调用自己的函数或外部API。
- 执行者汇报结果:应用程序将执行结果(如“天气晴,22度”)再传回给AI助理。
- AI助理总结汇报:AI助理将收到的枯燥结果,用自然、流畅的语言组织起来,最终向用户汇报。
1.2 实战演练:一个经典的天气查询例子
让我们看看这位“助理”和“执行者”是如何协作的。
第一步:提供工具说明书
在调用AI时,附上工具描述:
1 | { |
第二步:用户与AI的交互
- 用户:“北京今天天气怎么样?”
- AI助理的思考过程:用户的意图是“查询天气”,匹配了
getCurrentWeather函数。地点是“北京”。单位没说,用默认的就好。
AI助理输出的“工作单”:
1 | { |
- 你的应用程序(执行者):
a. 收到tool_calls响应,知道有活要干。
b. 解析出函数名是getCurrentWeather,参数是location: "北京"。
c. 调用自己的天气APImy_weather_api("北京"),得到结果{"temperature": "22", "unit": "celsius", "condition": "晴"}。
d. 将这个结果再次汇报给AI助理。 - AI助理的最终回复:“北京今天的天气是22摄氏度,晴天。”
1.3 历史的局限:Function Calling的“三大原罪”
Function Calling是伟大的第一步,但它很快就暴露了阻碍其发展的“三大原罪”:
- 标准化之罪(生态分裂):每家AI厂商(OpenAI, Google, Anthropic)的“工具说明书”和“工作单”格式都不同。就像不同品牌的手机用着不同的充电口,为Claude写的工具无法直接给ChatGPT用,导致开发者重复劳动,无法形成统一的“AI工具商店”。
- 扩展性之罪(成本高昂):每次对话,你都得把厚厚的“工具说明书”作为Prompt的一部分发给AI。如果你的应用有100个复杂工具,这份说明书会变得异常庞大,不仅消耗宝贵的上下文窗口,还显著增加了API成本和延迟。
- 发现性之罪(封闭孤立):AI无法主动发现互联网上存在的工具。一个工具必须由开发者“手动喂给”AI,它才能使用。这与开放、动态的互联网精神背道而驰。
问题已经浮现:我们如何才能创造一个统一、开放、可扩展的AI工具生态系统? 历史的车轮滚滚向前,MCP应运而生。
第二章:统一的时代 —— MCP(模型上下文协议)的宏伟蓝图
面对Function Calling带来的混乱,Anthropic在2024年提出了一个极具野心的解决方案,并迅速将其开源,推动其成为行业标准——这就是模型上下文协议(Model Context Protocol, MCP)。
MCP的目标,是成为**“AI工具世界的USB-C接口”**,彻底解决标准化、扩展性和发现性的问题。
2.1 核心逻辑:从“自带说明书”到“在线下载驱动”
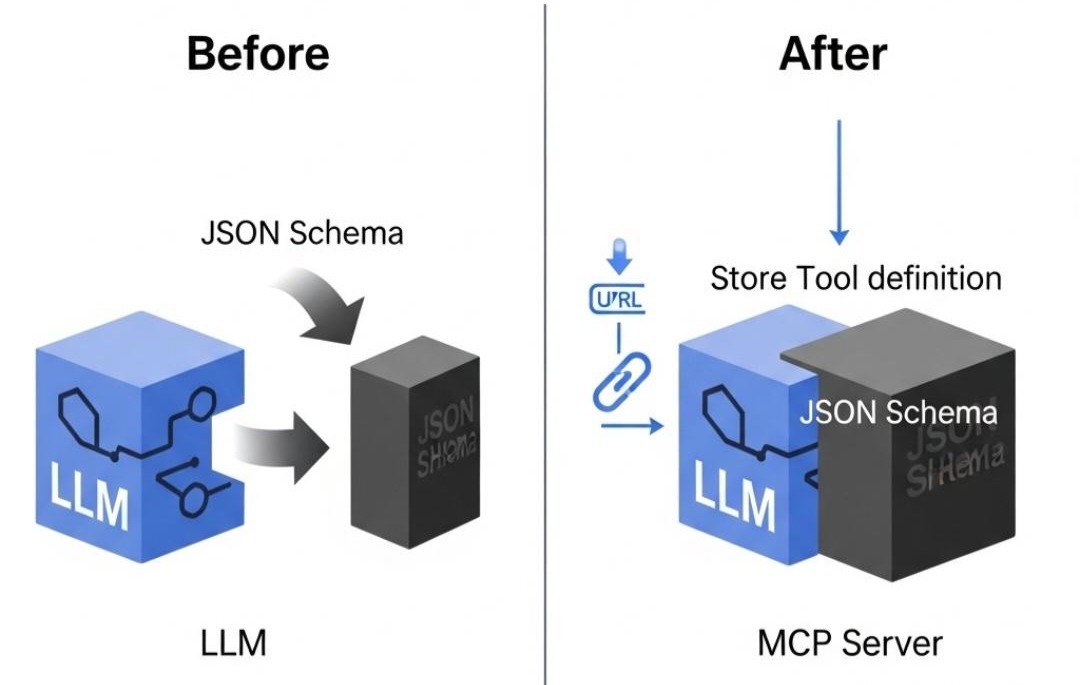
MCP的革命性在于,它将工具的定义与AI的调用进行了解耦。
- 过去(Function Calling):每次都把厚厚的说明书(JSON定义)塞给AI。
- 现在(MCP):工具提供者搭建一个遵循MCP规范的Web服务器,并提供一个标准的清单文件(mcp.json)。这份清单就像一个“驱动程序下载页面”的地址。
AI应用只需要知道这个清单文件的URL,就可以像电脑安装新打印机一样,瞬间了解这个工具的所有功能,并直接通过标准的HTTP请求来使用它。
2.2 实战演练:用MCP重构“天气查询”工具
让我们看看之前的天气查询工具,在MCP的世界里会是什么样子。
第一步:搭建MCP服务器,提供“驱动”和“服务”
你需要一个Web服务器,它对外暴露两个东西:
- 清单文件(驱动页面):
/mcp.json - 实际功能接口:
/v1/weather
1 | // McpWeatherController.java |
第二步:AI应用如何使用它

现在,任何支持MCP的AI应用,只需在配置中添加一行,告诉它“驱动”地址:USE_TOOL: https://api.myweather.com/mcp.json
交互流程就变成了:
- AI应用启动,访问该URL,瞬间理解了
StandardWeatherService的用法。 - 用户:“巴黎天气如何?”
- AI模型决策后,AI应用直接向
https://api.myweather.com/v1/weather?city=巴黎发起一个GET请求。 - MCP服务器返回
{"temperature": "15°C", "condition": "多云"}。 - AI模型将结果组织成自然语言回复。
2.3 MCP的局限:“知道有什么工具”不等于“知道怎么干活”
MCP是一次伟大的飞跃,它成功地为AI工具世界建立了“铁路轨距”和“集装箱”标准。
然而,MCP也并非万能。它完美地解决了**“连接”的问题,但一个新的、更深层次的问题浮现出来:“流程”**的问题。
想象一下,MCP给了AI一套完整的厨具(锅、碗、瓢、盆)和所有食材(菜、肉、调料)。但如果你想让它做一道工序复杂的“佛跳墙”,它就傻眼了。
- 它不知道菜谱(The “How-To” Problem):MCP告诉AI可以调用
切菜()、烧水()、倒油()这些原子操作,但它不知道做佛跳墙需要“先将食材A浸泡2小时,再用小火慢炖,同时将食材B过油…”这一整套复杂的程序性知识。 - 它不了解企业内部的“家规”(The Organizational Knowledge Gap):每个公司都有大量隐性的SOP(标准作业程序)。例如,“制作周报PPT,必须用公司模板,颜色只能用主色#345C7D,第一页是标题,第二页是数据总览……”这些复杂的、多步骤的、包含特定规则的“手艺”,是MCP无法承载的。
新的问题再次出现:我们如何不仅给AI工具,还要教会它包含专家经验的“菜谱”和“手艺”? 于是,Anthropic在2025年,为Claude模型推出了点睛之笔——Anthropic Skills。
第三章:注入灵魂的工艺 —— Anthropic Skills的诞生
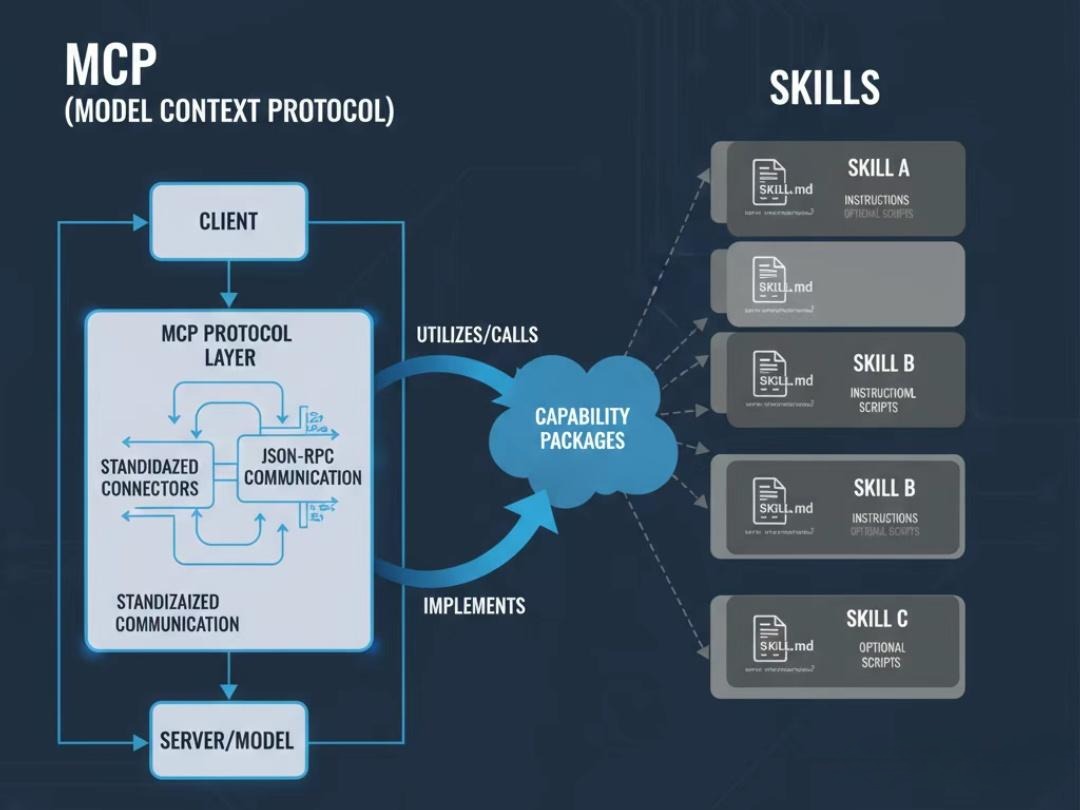
如果说MCP是为AI提供了标准化的“四肢和工具”,那么Skills则是为AI注入了**“专家的大脑和肌肉记忆”**。它旨在解决MCP无法解决的“流程”和“知识”问题。
3.1 核心原理:“渐进式披露”的上下文魔术
Skills的实现方式堪称天才,其核心是一种名为**“渐进式披露”(Progressive Disclosure)**的策略。它彻底解决了上下文窗口被无效信息占满的难题。
把它想象成查阅一部巨大的百科全书:
- 只看目录(轻量级索引):对话开始时,AI不读任何技能的详细内容,只快速扫描所有技能说明文件的第一行描述,形成一个极小的“技能目录”。这几乎不占用任何上下文空间。
- 按需翻页(动态加载):当用户的请求(如“做个PPT”)与目录中的某一项匹配时,系统在那一刻,才会将该技能的完整说明书(
SKILL.md文件)动态地加载到当前的对话上下文中。 - 成为专家(专家级执行):此时,AI的上下文中充满了关于如何完成这个特定任务的详细步骤、规则和最佳实践。它瞬间从一个“通才”变身为一个“PPT制作专家”,并严格按照这份“SOP”来主导工作流程。
3.2 实战演练:创建一个“企业级PPT制作”高级技能
让我们来构建一个解决MCP无法处理的复杂流程任务的Skill。
第一步:创建Skill的文件结构(工具箱)
Skill是一个结构化的文件夹,像一个工具箱,里面有说明书、参考资料和范例。
1 | /my_claude_skills |
第二步:编写灵魂文件 SKILL.md
这是整个Skill的大脑,它不是代码,而是给AI看的、包含严格指令的自然语言“剧本”。
1 | # SKILL.md |
3.3 交互流程的升华
- 初始状态:Claude启动,上下文中只有一行轻量级信息:“corporate_presentation_maker: …创建专业的演示文稿。”
- 用户:“我们要做个季度汇报,帮我弄个PPT。”
- 激活与加载:AI路由系统匹配到关键词“PPT”,立即激活技能,
SKILL.md的全部内容瞬间被加载到上下文中。 - AI化身专家:Claude的下一句话,将严格遵循SOP的第一步:“您好,我是您的品牌合规助理。我将协助您严格按照Acme公司规范创建演示文稿。我们开始构建标题页。请提供您的主标题和副标题。”
看到区别了吗? AI不再是被动地等待调用,而是主动地、专家级地主导整个工作流程。它从一个听话的工具,变成了一个懂规矩、懂流程的项目经理。
第四章:厘清核心 —— Workflow 与 Skill 的本质区别
很多人会将Skill与传统的Workflow(工作流引擎)混淆,但它们的底层逻辑截然不同。

传统的Workflow(比如用代码实现的流程引擎)是这样的:
- 代码是刚性的:if (step == 1) { call_api_A(); } else if (step == 2) { call_api_B(); }//当然这个代码可能是作为工作流画布中某个节点的准入条件,亦或者是代码中的硬编码。
- 状态由引擎管理:引擎自己记录着“当前在第二步”。
- 反馈是给引擎的:API_A返回的结果,是交给流程引擎的代码去处理,然后决定下一步。
而 Skill 的工作方式完全不同:
- SKILL.md 是柔性的:它是一份自然语言的说明书,告诉AI“你的角色是什么”、“你的行事原则是什么”、“你应该遵循哪些步骤”。
- AI(LLM)本身就是“引擎”:AI利用其强大的阅读理解和推理能力,来“理解”这份说明书,并决定下一步做什么。
- 反馈是给AI的:工具执行的结果,会作为新的信息,放回对话上下文中,让AI“看到”,并基于这个新信息,结合SKILL.md的指示,进行下一步的推理。
“Skill执行引擎”的幕后工作流程(The Secret Sauce)

我们仍然用“企业级PPT制作”Skill来一步步拆解,看看当用户说“帮我弄个PPT”时,到底发生了什么:
第一轮交互:
- [用户] -> “我们要做个季度汇报,帮我弄个PPT。”
- [Skill执行引擎]:
- 接收到用户输入。
- 通过意图识别(这里可以是意图识别模型,也有可能是一个LLM,意图识别也是LLM应用中的必修课),匹配到了 corporate_presentation_maker 这个Skill。
- 【关键步骤】 它将 SKILL.md 的全部内容加载进来,然后将它和用户的请求拼接成一个巨大的、隐藏的Prompt,发送给Claude模型。
- [Claude LLM]:
- 它收到的输入(在它的“脑海”里)是这样的:
1 | 你是一个AI助手。以下是你当前可用的一个特殊技能的说明书: |
- [Claude LLM 的推理过程]:
- “好的,我看到了我的技能说明书。我的身份是‘品牌合规助理’。”
- “说明书的**[工作流程]第一步是启动与确认**。”
- “这一步要求我以一个特定的句子作为开场白。”
- “所以,我下一步的行动就是输出这个句子。”
5.[Claude LLM] -> 输出一个纯文本回应。
6.[Skill执行引擎] -> 将这个纯文本回应直接展示给用户。
- [用户看到的界面] -> “您好,我是您的品牌合规助理。我将协助您严格按照Acme公司规范创建演示文稿。我们开始构建标题页。请提供您的主标题和副标题。”
到这里,Skill的第一步就完成了。注意,全程没有调用任何工具,这完全是LLM在“角色扮演”。
第二轮交互(调用工具):
假设用户提供了标题,并且现在提到了需要数据。
- [用户] -> “好的,主标题是‘Q3销售业绩回顾’。另外,帮我把最新的销售数据放进去。”
- [Skill执行引擎]:
- 接收到用户的新输入。
- 【关键步骤】 它将这次的整个对话历史(包括AI自己的上一句回复)和 SKILL.md 的内容,再次拼接成一个新的、更长的隐藏Prompt,发送给Claude。
- [Claude LLM]:
- 它现在“脑海”里的信息更多了:
1 | ...(SKILL.md的全部内容)... |
- [Claude LLM 的推理过程]:
- “我收到了用户的回复。我需要处理‘最新的销售数据’这个请求。”
- “我快速回顾我的技能说明书 SKILL.md。”
- “啊哈!在**[工作流程]的第4步写着:‘如果用户提到“需要最新的销售数据”,你必须**调用名为 AcmeSalesDB 的MCP工具中的 get_quarterly_sales() 函数…’”
- “所以,我下一步的行动不是回复一句话,而是生成一个工具调用指令。”
- [Claude LLM] -> 输出一个特殊的JSON对象(和Function Calling一样!):
1 | { |
- [Skill执行引擎]:
- 它截获了这个JSON,知道这不是给用户看的内容。
- 它解析JSON,并去真正地执行了 AcmeSalesDB 这个MCP工具的 get_quarterly_sales() 函数。
- 假设工具返回了结果:{“sales”: “5.2M”, “growth”: “15%”}。
- 【关键步骤】 引擎将这个工具返回的结果,再次打包,作为新的信息,反馈给LLM。
- [Claude LLM]:
- 它现在收到的信息是(这是同一次推理的延续):
1 | ...(之前的全部上下文)... |
- [Claude LLM 的最终推理]:
- “好的,我拿到了销售数据。我的SKILL.md要求我制作PPT。我现在应该将这个数据整合成自然语言,并继续引导用户。”
9.[Claude LLM] -> 输出最终的纯文本回应。
- [用户看到的界面] -> “好的,标题页已设定。根据我获取到的最新数据,本季度销售额为520万美元,增长了15%。您希望如何将这个数据呈现在幻灯片上?例如,作为一个关键指标,还是一个图表?”
结论:Skill是给AI的“导演手记”
现在你应该明白了:
- Workflow是代码,是给机器执行的指令。
- Skill是剧本,是给AI演员的表演指南。
SKILL.md 之所以强大,是因为它没有把AI当成一个笨拙的、只能一步一调用的工具。它把AI当成一个有智慧的代理(Agent),通过一份详尽的说明书来约束和引导它的行为。
AI在每一步都会“重读”剧本(SKILL.md),回顾之前的“剧情”(对话历史),然后利用自己的“演技”(LLM的推理能力)来决定是说一句“台词”(回复用户),还是做一个“动作”(调用工具)。
这就是从“能聊”到“能干”的进化中,最深刻的范式转变:我们不再为机器编写僵化的流程,而是为智能体编写灵活的使命和原则。
第五章:地平线之外 —— AI智能体的未来图景
我们已经走过了一段非凡的旅程:从Function Calling在混沌中凿开的第一道光,到MCP为世界建立的统一秩序,再到Skills为AI注入的专家级灵魂。但这并非故事的终点,而仅仅是真正“智能体时代”的序幕。
如果说过去的进化解决了AI“如何动手”的问题,那么未来的进化将聚焦于三大主题:自主性(Autonomy)、协作性(Collaboration)和生态性(Ecosystem)。
以下,是我们对AI智能体未来的四大猜想,它们共同描绘了一幅激动人心的图景。
未来图景一:从静态“菜谱”到动态“自学成才”的厨师
- 现状:目前的Anthropic Skills本质上是人类专家编写的、静态的“菜谱”(SOP)。AI是一个忠实的厨师,严格按菜谱做菜,但如果菜谱本身有缺陷,它也无能为力。
- 未来:未来的AI智能体将拥有元认知(Meta-cognition)和自我完善的能力。它不再仅仅是菜谱的执行者,更是菜谱的改进者。
- 分析成败:智能体在执行任务后,会分析自己的行为日志。比如一个“客户支持Skill”可能会发现,按现有流程,有30%的工单最终还是需要人工介入。
- 定位问题:通过分析这些失败案例,AI会总结出模式:“当用户提到‘发票错误’时,我提供的标准解决方案成功率只有10%。”
- 提出改进:基于这个发现,AI会主动提出一个修改建议,甚至给它的
SKILL.md文件生成一个Pull Request:“建议在SOP的第三步增加一个分支:如果用户提到‘发票错误’,则直接调用BillingSystem_Tool的get_invoice_details()函数,而不是提供通用帮助链接。” - 验证效果:在获得批准后,AI甚至可以小范围A/B测试新流程,用数据证明其有效性,最终将其固化为新的标准菜谱。
这意味着,AI将从一个“数字员工”进化成一个**“数字流程优化专家”**。它们形成了学习、实践、反思、优化的闭环,不断地自我迭代。
未来图景二:从“独行侠”到“智能体公会”
- 现状:我们目前的模型是“一个大脑,多个工具”。一个通用的AI模型(如Claude)作为中心大脑,协调调用不同的工具。
- 未来:我们将进入一个**“智能体社会(Society of Agents)”**。在这个社会里,复杂的任务会被分解,并分配给一个由高度专业化、独立的智能体组成的网络,就像一个各司其职的公会。
想象一下用户提出一个宏大目标:“为我的新咖啡品牌策划一场线上发布会。”
- 一个“项目总管Agent”(高级协调型AI)会接下任务,但它不会自己做所有事。
- 它会立即“雇佣”并激活一个“市场分析Agent”,这个Agent拥有自己独特的Skills(如竞品分析),并调用专业的MCP数据工具。
- 市场分析Agent完成后,总管Agent会将其结论传递给一个“创意设计Agent”(擅长文案和视觉)和一个“社媒运营Agent”(擅长内容分发)。
- 这些Agent之间甚至可能存在一个微型经济系统,总管Agent会根据任务的完成质量,向其他Agent支付“代币”或计算资源。
这将催生一个全新的技术栈,包括Agent间的通信协议、信誉系统和结算层。我们将从与单个AI对话,转向向一个AI“董事会”下达战略目标。
未来图景三:AI的“App Store”——通用工具市场
- 现状:MCP定义了标准,但工具的发现和集成在很大程度上仍依赖于开发者手动配置。
- 未来:MCP的终极形态,将是一个全球性的、去中心化的**“通用工具市场”**。
- 开发者发布工具:任何人都可以将自己的API打包成MCP兼容的工具,发布到市场上,并设定定价模型(如按次调用付费)。
- AI自主采购工具:当AI需要一个它没有的能力时(如“视频翻译并配音”),它可以直接查询这个市场。
- AI智能决策:AI不仅能找到工具,还能像一个精明的买家,比较不同提供商的工具,权衡其价格、API速度、可靠性评级、安全认证等因素,然后选择最合适的。
- 即插即用:一旦选定,AI可以动态地、即时地将该工具集成到自己的能力集中,无需人类开发者介入。
这将引爆一个全新的“AI工具经济”。开发者的服务对象将从人类扩展到AI,极大地加速AI能力边界的扩张。
未来图景四:从“聊天框”到“意图操作系统”
- 现状:我们与AI交互的主要媒介,仍然是一个线性的聊天框。我们一步步告诉它做什么。
- 未来:这个界面将会“消失”,融入到一个更高维度的**“意图操作系统(Intent-Driven OS)”中。在这个范式下,你不再需要打开App或下达具体指令,你只需要**声明你的最终意图。
你对操作系统说:“安排一次和‘北极星项目’团队的紧急会议,讨论预算超支,时间定在明天下午,把相关的财务和项目报告准备好。”
- AI操作系统在后台会做什么?
- 它激活“日历Agent”找到所有人的空闲时间。
- 它激活“文件Agent”从公司数据库中检索出正确的报表。
- 它激活“通信Agent”起草并发送包含所有信息的会议邀请。
- 而你收到的,只是一个简单的结果:“会议已安排在明天下午3点,相关文件已附加到日历邀请中。”
这意味着,我们将从“使用工具的人”变成**“设定目标的人”**。技术的复杂性被完全隐藏,我们与数字世界的交互,将回归到人类最自然的沟通方式——表达意图。
最终章:伟大的融合 —— 从“对话”到“契约”
现在,我们终于可以回答那个终极问题:MCP和Skills到底是什么关系?
答案是:它们是构建高级AI智能体的、缺一不可的两个层面。它们是身与心的完美结合。
- MCP是骨骼与肌肉:它提供了标准化的、连接现实世界的物理能力。它解决了**“能不能做”**的问题。
- Skills是大脑与神经:它提供了复杂的、蕴含专家知识的智慧与策略。它解决了**“应该怎么做”和“如何做得更好”**的问题。
让我们用一个终极例子来展示它们的协同:自动化招聘筛选。
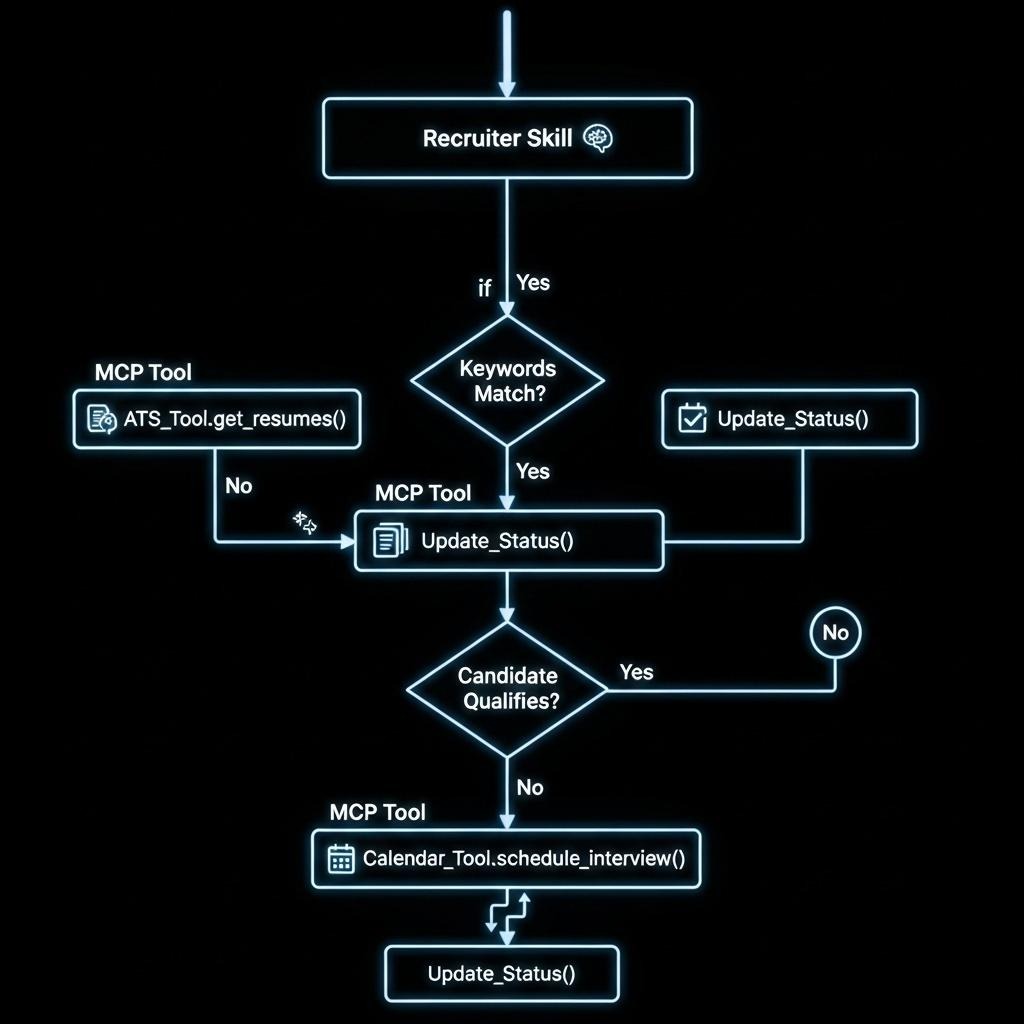
- MCP工具层 (士兵):
ATS_Tool (MCP): 连接招聘系统,提供获取新简历()和更新候选人状态()函数。Calendar_Tool (MCP): 连接日历,提供安排面试()函数。
- Skills知识层 (指挥官):
- 创建一个
recruiter_assistantSkill,其SKILL.md中定义了如下SOP:
- 每天早上9点,自动调用
ATS_Tool的获取新简历()函数。 - 对于每份简历,检查其“技能”字段是否同时包含 “Python”, “Docker” 和 “AWS”。
- 如果满足条件,调用
ATS_Tool的更新候选人状态()为“通过筛选”,然后调用Calendar_Tool的安排面试()。 - 如果不满足条件,则更新其状态为“未通过”。
- 最后,生成一份报告总结今日工作。
在这个场景中,Skill扮演了总指挥官的角色,它定义了整个业务流程的逻辑和策略。而MCP工具则像忠实的士兵,负责执行Skill下达的每一个具体、原子的命令。
结论:
我们从Function Calling的混沌初开,走到了MCP的秩序建立,最终见证了Skills的智慧注入。这是一部AI从一个“聊天伴侣”进化为一个“工作伙伴”的恢弘历史。
我们可以用三份“合同”来总结这段进化:
Function Calling:是AI与世界签订的第一份临时合约,一事一议,格式不通。
MCP:是AI世界共同遵守的日内瓦公约,它确立了所有工具交互的普适法则,让协作成为可能。
Anthropic Skills:则是企业与AI签订的深度定制化劳动合同,它详细规定了AI作为“数字员工”的岗位职责、工作流程和行为准则。
这三者的演进与融合,标志着我们正在进入一个全新的AI纪元。在这个纪元里,我们与AI的关系不再仅仅是“对话”,而是一种基于能力、流程和信任的深度**“契约”**。我们不再是简单地向AI提问,而是将真实世界中复杂的工作流,安全、可靠、高效地委托给它们。
这,就是AI从“能聊”到“能干”的全部故事。

