从混沌到智慧:万字长文深度解析大模型生命周期(预训练、微调、强化学习、评估与部署)
引言:巨人的诞生与驯服
当我们与ChatGPT、Claude或文心一言进行流畅对话,惊叹于它们渊博的知识、严谨的逻辑和富有创造力的文采时,我们看到的其实是一座巨大冰山的尖端。水面之下,隐藏着一个复杂、昂贵且充满智慧的工程奇迹——大型语言模型的完整生命周期。
这并非魔法,而是一门融合了海量数据、庞大算力和尖端算法的“科学与艺术”。一个顶级的LLM,其诞生与成长,堪比人类文明中培养一位全知全能的学者:它需要经历漫长的“通识教育”(预训练),然后进入专业领域深造(微调),接着学习人类社会的价值观与沟通技巧(强化学习),通过一系列严格的考试证明自己(评估),最终才能走上工作岗位,为社会服务(部署)。
本文将作为你的深度向导,带你潜入冰山之下,用超过一万字的篇幅,系统性地、全方位地解构LLM生命周期的每一个环节。我们将不仅探讨“是什么”,更会深入“为什么”和“怎么做”。无论你是AI从业者、技术爱好者,还是对LLM充满好奇的探索者,这篇文章都将为你构建一个坚实而全面的知识框架。
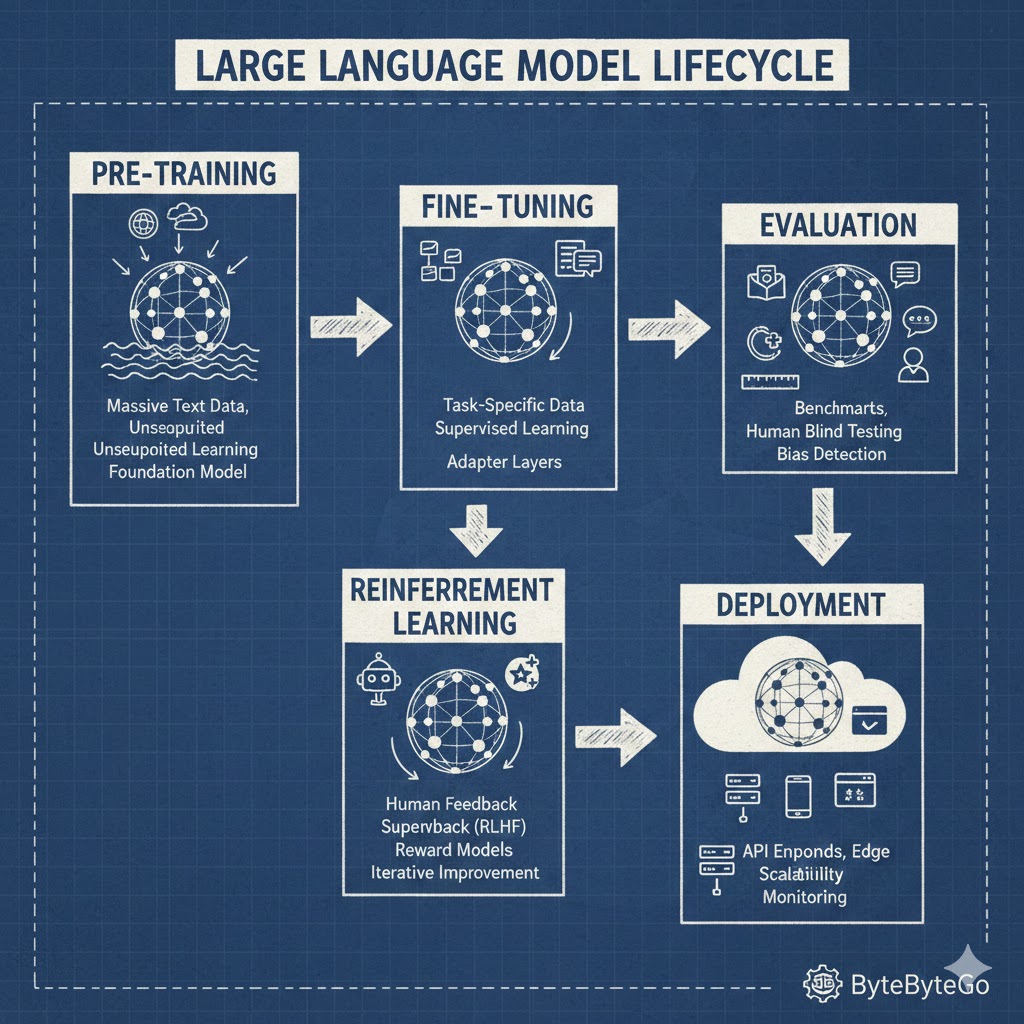
文章路线图:
- 第一部分:预训练(Pre-training) - 铸造神力:从零开始构建模型的原始力量。
- 第二部分:微调(Fine-tuning) - 赋予专长:将通用学者培养成特定领域的专家。
- 第三部分:强化学习(RLHF) - 注入灵魂:教会模型何为“有用、诚实、无害”。
- 第四部分:评估(Evaluation) - 终极考核:如何科学地衡量一个模型的优劣。
- 第五部分:部署(Deployment) - 服务社会:将模型转化为高效、可靠的在线服务。
第一部分:预训练(Pre-training)- 铸造神力:在数据海洋中锻造语言基础
预训练是LLM生命周期中最为昂贵、也最为关键的一步。它定义了模型的“智力上限”和“知识边界”。
核心思想: 通过在海量的、未经标注的文本数据上进行自监督学习(Self-supervised Learning),让模型掌握语言的内在规律、语法结构、事实知识,甚至初步的推理能力。
这个阶段的LLM,好比一个被关在世界最大图书馆里的孩子,他的任务不是回答问题,而是通过阅读馆内所有的书籍,学会一件事:根据上文,预测下一个词应该是什么。
1.1 核心架构:Transformer - 注意力是唯一的必需品
现代所有LLM的基石,都是2017年Google提出的Transformer架构。其革命性的**自注意力机制(Self-Attention)**彻底改变了序列数据处理的方式。
- 注意力机制的直观理解: 想象你在阅读句子:“银行的河岸上长满了青草。” 当你读到“银行”这个词时,你的大脑会根据上下文“河岸”来判断,这里的“银行”指的是river bank,而不是financial bank。自注意力机制就是模拟这个过程的数学模型。它允许模型在处理一个词时,动态地计算句子中其他所有词对这个词的“重要性”或“关联度”,并赋予不同的权重。
- 自注意力的数学表达: 对于输入序列中的每个词,我们都会创建三个向量:查询(Query, Q)、键(Key, K) 和 值(Value, V)。
- 打分: 用当前词的Q向量,去和所有词(包括自己)的K向量进行点积运算,得到一个注意力分数。这个分数代表了“我(Q)应该对你(K)投入多少关注”。
- 归一化: 将得到的分数通过Softmax函数进行归一化,使其总和为1,变成概率分布。
- 加权求和: 用这些归一化后的分数,去对所有词的V向量进行加权求和。最终得到的向量,就融合了整个句子的上下文信息,成为了当前词的新表示。
- 多头注意力(Multi-Head Attention): 为了让模型能从不同角度理解上下文(比如,一个头关注语法关系,另一个头关注语义关系),Transformer将Q、K、V向量在特征维度上切分成多个“头”,分别进行自注意力计算,最后再将结果拼接起来。这极大增强了模型的表达能力。
- 解码器-仅架构(Decoder-only): GPT系列模型采用的是纯解码器架构。在预训练时,它遵循严格的“从左到右”的顺序。在预测第
i个词时,它只能看到前i-1个词的信息,这被称为因果语言建模(Causal Language Modeling)。这种结构天然适合文本生成任务。
1.2 训练目标:下一个词的语言游戏
预训练的核心任务是下一个词预测(Next Token Prediction)。
- 目标函数: 给定一个文本序列
(x_1, x_2, ..., x_t),模型的目标是最大化整个序列的联合概率P(x_1, ..., x_t)。这可以分解为一系列条件概率的乘积:P(x_t | x_1, ..., x_{t-1})。 - 损失函数: 在实践中,我们使用交叉熵损失(Cross-Entropy Loss)。模型会为词汇表中的每个词输出一个概率,表示该词是下一个词的可能性。交叉熵损失会计算这个预测概率分布与真实分布(即真实下一个词的概率为1,其他为0)之间的差异。模型训练的过程,就是不断调整自身数千亿的参数,来最小化这个损失。
通过这个看似简单的任务,模型被迫学习到极其复杂的语言模式。为了准确预测“原子弹”后面的词是“的”,它必须理解“原子弹”是一个名词;为了预测“法国的首都是”后面的词是“巴黎”,它必须记忆事实知识。
1.3 预训练的三大支柱:数据、模型规模、算力
1.3.1 数据(Data):巨人的食粮
数据的规模、多样性和质量直接决定了模型的能力。
- 规模: 顶级的LLM通常使用数万亿(Trillions)个Token进行训练。1 Token约等于0.75个英文单词。
- 多样性: 数据来源极其广泛,包括:
- 网页文本: Common Crawl等数据集,提供了互联网的多样化语料。
- 书籍: Google Books等,为模型提供了结构化、高质量的叙事和知识。
- 代码: GitHub等,让模型学习编程语言的逻辑和模式。
- 对话文本: Reddit等,帮助模型理解对话的风格和流程。
- 百科知识: Wikipedia,是高质量事实知识的核心来源。
- 质量: 原始数据充满了噪声、偏见和有害信息。数据清洗是预训练中最关键的“脏活累活”,包括:去重、过滤低质量内容、去除个人身份信息(PII)、进行毒性内容筛选等。高质量的数据能让训练更高效,模型行为更可控。
1.3.2 模型规模(Scale):大力出奇迹
“尺度定律”(Scaling Laws)是LLM领域最重要的发现之一。研究表明,模型的性能与其参数量、数据集大小和计算量之间存在可预测的幂律关系。简单来说,模型越大、数据越多、算的越久,模型就越“聪明”。
- 涌现能力(Emergent Abilities): 当模型规模突破某个阈值后,会突然表现出在小模型上完全不存在的能力,如上下文学习(In-context Learning)、思维链(Chain-of-Thought)推理等。这正是各大公司竞相扩大模型规模的核心驱动力。
1.3.3 算力(Compute):巨人的引擎
预训练是地球上最耗费算力的计算任务之一。
- 硬件: 通常使用数千甚至上万块顶级GPU(如NVIDIA A100/H100)或TPU,进行长达数月的持续训练。
- 分布式训练: 单张GPU无法容纳巨大的模型。必须使用复杂的分布式训练技术:
- 数据并行(Data Parallelism): 将模型复制到多张卡上,每张卡处理不同批次的数据,然后同步梯度。
- 张量并行(Tensor Parallelism): 将模型的单个大矩阵运算(如权重矩阵)切分到多张卡上协同完成。
- 流水线并行(Pipeline Parallelism): 将模型的不同层(Layers)分配到不同的卡上,形成一条流水线。
- ZeRO(Zero Redundancy Optimizer): 一种先进的内存优化技术,通过将模型参数、梯度和优化器状态分散到所有GPU上,极大降低了单卡的显存压力。
预训练的产物: 一个“基础模型”(Base Model)。它拥有强大的语言能力和世界知识,但像一个不谙世事的“书呆子”,它不知道如何与人互动,不懂得遵循指令,甚至可能输出有害内容。它的力量是原始的、未经驯化的。
第二部分:微调(Fine-tuning)- 赋予专长:从通才到专家的蜕变
如果说预训练是通识教育,微调就是专业深造。这个阶段的目标是让模型适应特定的任务、领域或交互风格。
核心思想: 在一个规模较小、但质量极高的有监督数据集上,继续训练基础模型,使其“解锁”遵循指令的能力,并学习特定领域的知识。
2.1 全量微调(Full Fine-tuning)
最直接的方式,就是用新的标注数据更新模型的所有参数。
- 过程: 就像预训练一样,计算损失并反向传播梯度,但这次更新的是全部数千亿参数。
- 优点: 理论上效果最好,能最大程度地将新知识融入模型。
- 缺点:
- 成本高昂: 对数千亿参数进行微调,依然需要大量的GPU资源和时间。
- 灾难性遗忘(Catastrophic Forgetting): 模型在学习新知识时,可能会忘记预训练阶段学到的通用知识。
- 存储冗余: 每微调一个新任务,就需要存储一份完整的模型副本,成本极高。
由于这些缺点,全量微调在大模型时代已不常用。
2.2 参数高效微调(Parameter-Efficient Fine-Tuning, PEFT)
PEFT是当前微调的主流范式。其核心思想是:冻结基础模型的绝大部分参数,只训练一小部分新增的或指定的参数。
这好比给一个大脑固定的专家(基础模型)配上一个可擦写的“外挂笔记本”(新增参数),所有的学习和适应都发生在这个笔记本上。
2.2.1 LoRA(Low-Rank Adaptation):PEFT的王者
LoRA是目前最流行、最有效的PEFT方法。
- 核心洞察: 研究发现,模型在微调时,其参数的“变化量”(ΔW)矩阵通常是低秩(Low-Rank)的。这意味着这个巨大的变化矩阵,可以用两个小得多的矩阵相乘来近似表示。
- 实现方法:
- 冻结原始权重: 保持原始的预训练权重矩阵W不变。
- 注入适配器: 在模型的目标层(通常是注意力模块的权重矩阵)旁边,并联一个“旁路”。这个旁路包含两个低秩矩阵A和B(例如,W是10000x10000维,A可以是10000x8维,B可以是8x10000维)。
- 只训练A和B: 在微调时,只有矩阵A和B的参数被更新。
- 合并输出: 模型的最终输出是原始权重W的输出,加上旁路
x * B * A的输出。
- 优势:
- 极高的参数效率: 可训练参数的数量可以减少到原始模型的0.01%甚至更低。
- 效果媲美全量微调: 在许多任务上,LoRA的效果与全量微调相当甚至更好。
- 快速切换任务: 由于基础模型不变,你只需要为每个任务存储一个微小的LoRA权重文件(通常只有几十MB),可以随时加载和切换。
- 避免灾难性遗忘: 原始知识被完好地保存在冻结的参数中。
2.2.2 其他PEFT方法
- Prompt Tuning/P-Tuning: 冻结整个模型,只在输入端学习一段特殊的、可训练的“软提示”(Soft Prompt)向量。模型会学着将这个软提示解释为执行特定任务的指令。
- Adapter Tuning: 在模型的每个Transformer层之间插入一个小的、瓶颈状的神经网络模块(Adapter),只训练这些Adapter的参数。
2.3 指令微调(Instruction Tuning)
这是微调阶段最关键的应用。其目的是教会模型理解并遵循人类的指令。
数据集格式: 数据不再是连续的文本,而是结构化的“指令-响应”对(Instruction-Response Pair)。
1
2
3
4
5{
"instruction": "请总结以下文章的核心观点。",
"input": "文章内容...",
"output": "这篇文章的核心观点是..."
}训练过程: 使用这些数据对模型进行SFT。模型会学会将“指令+输入”作为上下文,并生成符合要求的“输出”。经过成千上万种不同指令的训练,模型泛化出强大的指令遵循能力。
微调的产物: 一个“指令模型”或“SFT模型”。它已经从一个只会续写的“书呆子”,变成了一个能听懂指令、会做各种任务的“助手”。但它可能还不够“圆滑”,有时会答非所问、固执己见,或者在面对敏感问题时口无遮拦。
第三部分:强化学习(RLHF)- 注入灵魂:对齐人类价值观
RLHF(Reinforcement Learning from Human Feedback)是让模型从“能用”到“好用”的关键一步,也是ChatGPT等顶尖模型之所以出色的“秘密武器”。
核心思想: 微调让模型学会了“做什么”,RLHF则教会模型“怎么做更好”。它通过引入人类的偏好作为奖励信号,使用强化学习来优化模型的行为,使其输出更符合人类的价值观(有用、诚实、无害)。
RLHF通常分为三个步骤:
3.1 步骤一:训练奖励模型(Reward Model, RM)
由于“好”与“坏”是一个主观概念,无法用简单的损失函数定义,我们首先需要训练一个模型来代替人类进行打分。
- 数据收集:
- 选取一批多样的提示(Prompt)。
- 用上一阶段的SFT模型,为每个提示生成多个不同的回答(例如,A、B、C、D)。
- 由人类标注员对这些回答进行排序(例如,D > B > A > C)。
- 模型训练:
- RM的结构通常是一个以SFT模型为骨干,但最后输出一个标量(分数)的模型。
- 训练目标: RM接收一个“提示+回答”对,输出一个代表“有多好”的分数。训练的目标是让RM给出的分数,与人类的排序偏好保持一致。
- 损失函数: 通常使用排名损失(Ranking Loss)。对于一对回答(A, B),如果人类偏好A>B,那么RM应该满足
score(A) > score(B)。损失函数会惩罚那些不满足这个条件的预测。
此阶段的产物: 一个“品味裁判”——奖励模型。它学会了用人类的眼光来评判LLM生成的回答质量。
3.2 步骤二:使用强化学习优化LLM
这是RLHF的核心。我们将LLM的微调过程,建模为一个强化学习问题。
RL要素定义:
智能体(Agent): 我们要优化的SFT模型。
策略(Policy): 模型本身。给定一个提示,生成回答的概率分布就是策略。
动作空间(Action Space): 整个词汇表。在每个时间步,模型选择一个词作为“动作”。
环境(Environment): 用户的提示。
奖励(Reward): 一个完整的回答生成后,由第一步训练好的**奖励模型(RM)**给出分数。
优化算法:PPO(Proximal Policy Optimization)
目标:* 调整SFT模型(策略)的参数,使其生成的回答能在奖励模型那里获得尽可能高的分数。
PPO的核心思想: PPO是一种在“探索”与“利用”之间取得精妙平衡的算法。它鼓励模型在寻找更高奖励的回答时,不要偏离原始SFT模型太远。
目标函数中的关键项:
- 奖励项: 来自RM的分数,我们希望最大化它。
- KL散度惩罚项: 计算当前模型策略与原始SFT模型策略之间的KL散度。这是一个“正则化”项,如果新模型与老模型行为差异过大,就会受到惩罚。这可以防止模型为了追求高分而“走火入魔”,生成一些奇怪但能在RM上得分的文本(奖励 hacking),同时保留了模型的语言能力。
3.3 DPO(Direct Preference Optimization)
DPO是近年来出现的一种更简洁、更高效的替代方案。它巧妙地绕过了“训练奖励模型”和“使用复杂PPO进行强化学习”这两个步骤。
- 核心思想: DPO证明,可以通过一个简单的损失函数,直接在人类偏好数据上对LLM进行优化,其效果等价于RLHF。它将偏好数据直接转化为一个分类问题,目标是让模型对于“更优回答”的生成概率,高于“较差回答”的生成概率。
RLHF/DPO的产物: 一个“对齐后的模型”(Aligned Model)。它不仅知识渊博、能力强大,而且更懂得如何与人合作,回答更安全、更有用、更符合人类的预期。它拥有了“情商”。
第四部分:评估(Evaluation)- 终极考核:为巨人量体裁衣
模型训练完成后,如何客观、全面地衡量它的能力?这是一个极其复杂且仍在快速发展的领域。
4.1 自动评估基准(Standardized Tests)
这类似于标准化的学术考试,通过一系列精心设计的问答数据集,来测试模型在不同维度的能力。
- 综合与知识类:
- MMLU (Massive Multitask Language Understanding): 包含57个科目(从初等数学到美国历史、法律等)的多项选择题,是衡量模型综合知识和推理能力的黄金标准。
- C-Eval/CMMLU: MMLU的中文版本。
- 推理与常识类:
- HellaSwag: 给定一个场景,选择最合理的结局。考察模型的常识推理。
- ARC (AI2 Reasoning Challenge):** 需要科学知识和推理才能回答的小学科学问题。
- GSM8K:** 小学生数学应用题,测试模型的数学推理和计算能力。
- 代码能力类:
- HumanEval: 给定函数签名和文档字符串,让模型生成函数体。通过单元测试来评估正确性。
- 安全性与真实性类:
- TruthfulQA: 包含一系列人类会误解的问题,测试模型是否会复述常见的错误信息。
自动评估的局限性:
- 数据污染: 如果评测集的数据不慎出现在了模型的预训练数据中,模型可能只是“背下了答案”,而非真正具备能力。
- 无法评估主观质量: 无法衡量回答的创造性、共情能力或风格。
- 静态与对抗性不足: 固定的评测集容易被“应试优化”,无法反映模型在真实、开放场景下的表现。
4.2 人工评估(Human Evaluation)
人工评估是评估模型真实体验的“金标准”。
- 方法:
- 并排比较(Side-by-side): 给标注员一个提示和两个模型(如模型A和模型B)的回答,让他们选择哪个更好,或者平局。这是评估模型相对性能最有效的方法。
- 评分制: 让标注员根据一系列标准(如准确性、流畅性、安全性)对模型的回答进行打分(如1-5分)。
- 红队测试(Red Teaming): 专门组织一个团队,像“黑客”一样,想尽一切办法诱导模型产生不安全、有偏见或错误的输出。这是评估模型安全性的关键环节。
4.3 Arena & Leaderboard
为了结合自动评估的效率和人工评估的真实性,社区发展出了新的评估范式。
- Chatbot Arena: 一个匿名的、众包的评估平台。用户同时与两个匿名的模型聊天,然后投票选出哪个更好。通过大量用户的投票,可以计算出模型的Elo等级分(类似于棋类比赛的评分),形成一个动态、公正的排行榜。
一个全面的评估体系,必须是自动评估和人工评估的结合,才能立体、客观地描绘出模型的真实能力。
第五部分:部署(Deployment)- 服务社会:从模型到产品的最后一公里
训练好的模型只是一个静态的文件,部署则是将其转化为一个稳定、高效、可扩展的在线服务,让成千上万的用户可以实时访问。
5.1 推理的挑战
模型推理(Inference)与训练有很大不同,它面临三大核心挑战:
- 延迟(Latency): 从收到用户请求到返回第一个Token的时间(Time to First Token)和生成后续Token的速度(Tokens per second)。用户对延迟非常敏感。
- 吞吐量(Throughput): 系统在单位时间内能处理的请求数量(Requests per second)或生成的总Token数。
- 成本(Cost): 运行推理服务的硬件和能源成本,通常按GPU小时计算。
5.2 核心优化技术
为了应对这些挑战,需要一系列复杂的优化技术。
5.2.1 量化(Quantization)
- 概念: 将模型权重和激活值的数值精度降低。标准的模型使用16位浮点数(FP16/BF16),量化可以将其降低到8位整数(INT8)甚至4位整数(INT4)。
- 优势:
- 减少显存占用: INT8模型大小减半,INT4减为1/4。这使得在更小的GPU上部署更大的模型成为可能。
- 提升速度: 整数运算通常比浮点运算更快,且更低的显存占用意味着更少的数据传输,从而降低延迟。
- 方法:** AWQ、GPTQ等是当前主流的“训练后量化”(Post-Training Quantization)技术,能在精度损失很小的情况下实现显著的性能提升。
5.2.2 KV缓存(KV Cache)
- 背景: 在生成文本时,模型每生成一个新词,都需要回顾之前所有的上下文。Transformer的自注意力机制天生具有二次方的计算复杂度。
- 优化: KV缓存是一种关键优化。对于已经处理过的Token,我们将其计算出的Key和Value向量缓存起来。在生成下一个Token时,无需重新计算,只需计算新Token的Q、K、V,并与缓存中的K、V进行注意力计算即可。
- 挑战: KV缓存会占用大量显存,特别是在处理长序列或高并发时。
5.2.3 推理引擎与服务框架
仅仅有模型和GPU是不够的,还需要一个高效的推理引擎来管理计算、内存和请求。
- vLLM: 当前最先进的开源推理引擎之一。它的核心创新是PagedAttention。
- PagedAttention: 借鉴了操作系统中虚拟内存和分页的思想,将KV缓存分割成非连续的“块”(Block),像管理内存页一样动态分配和释放。这完美解决了KV缓存的内存碎片问题,使得显存利用率接近100%,吞吐量相比传统方法能提升数倍。
- 连续批处理(Continuous Batching):** 传统的静态批处理(Static Batching)需要等待批次中所有请求都完成后才能处理下一批。而LLM请求的输入输出长度各不相同。连续批处理允许在批次处理过程中,动态地将已完成的请求移出,并加入新的等待请求,极大地提高了GPU的利用率。
5.3 部署架构
- 自建服务: 使用vLLM、TensorRT-LLM等开源框架,在自己的GPU服务器或云虚拟机上搭建服务。灵活性高,但维护成本也高。
- 托管服务: 使用云厂商提供的LLM服务平台(如Amazon SageMaker, Google Vertex AI, Azure Machine Learning),它们封装了底层的优化和运维工作,用户只需上传模型即可获得一个可自动扩展的API端点。
部署是LLM价值变现的最后一环,也是一个充满工程挑战的领域。极致的优化是降低服务成本、提升用户体验的关键。
结语:永无止境的循环
大型语言模型的生命周期并非一条线性路径,而是一个持续迭代、不断演进的循环。在部署之后,我们会收集用户的反馈和真实世界的数据,用这些新的“养料”来启动新一轮的微调和RLHF,甚至为下一代模型的预训练提供更高质量的数据。
从预训练的“蛮荒之力”,到微调的“百炼成钢”,再到强化学习的“画龙点睛”,经过评估的“千锤百炼”,最终通过部署“服务于人”,我们见证了一个数字生命从混沌中诞生,并逐渐被赋予智慧、专长和“灵魂”的全过程。
理解这个生命周期,就是理解当前人工智能发展的核心脉络。这条探索之路依然漫长,而我们,正处在这个伟大时代的黎明。

