百万架构师成长之路(10):分布式事务的“银弹”?从2PC到SAGA、Seata的实践与反思
导语:微服务时代的“核武器”,该如何被安全地“掌控”?
在单体应用的“田园时代”,我们享受着数据库ACID事务带来的“岁月静好”。一个**@Transactional注解,就能轻松地将多个数据操作,包裹在一个原子性的、隔离的、一致的单元中。这是一种强大的、由底层数据库提供的“确定性”保证,我们早已习以为常。
然而,当我们拥抱微服务,将一个庞大的单体,拆分为数十上百个、拥有独立数据库**的微服务时,这片宁静被彻底打破。一个看似简单的业务操作,比如“用户下订单”,现在可能需要跨越三个服务才能完成:
订单服务:在自己的数据库中,创建一条订单记录。
库存服务:在自己的数据库中,扣减对应商品的库存。
账户服务:在自己的数据库中,扣除用户的账户余额。现在,一个致命的问题摆在了我们面前:如果订单创建成功,库存也扣减成功了,但在扣减用户余额时,账户服务因为网络抖动而超时失败了,我们该怎么办?
订单已经创建,库存已经扣减,这些操作已经“提交”到了它们各自的数据库中。
我们无法像单体应用那样,一个简单的ROLLBACK,就让一切恢复如初。
系统的数据,进入了一种“中间态”的、不一致的“薛定谔的猫”的状态。
这就是分布式事务的本质难题:如何协调多个独立的、分布式的参与者,让它们的操作,在逻辑上表现得如同一个不可分割的原子单元。
这个问题,被誉为分布式系统领域的“圣杯”之一,与分布式共识问题一样,充满了理论上的挑战和工程上的妥协。多年来,无数的科学家和工程师,从两阶段提交(2PC)的刚性约束,到可靠消息最终一致性的柔性妥协,再到SAGA模式的编排艺术,以及Seata框架的“黑魔法”,都在试图寻找那颗能够一劳永逸地解决这个问题的“银弹”。
本篇,就是你在这片布满陷阱的“军火库”中,安全导航的完整手册。我们将手持“逻辑推演”的放大镜,去审视每一种方案的内部机制、优劣权衡、性能损耗和适用场景。最终,你将明白,分布式事务没有“银弹”,只有最适合你当前业务场景的、经过深思熟虑的“权衡”。
第一章:理论的基石:ACID的“乌托邦”与BASE的“现实主义”
在踏入分布式世界之前,我们都生活在单体应用的“黄金时代”。在这个时代,我们拥有最强大的武器——数据库的ACID事务。

- 原子性(Atomicity):一个事务中的所有操作,要么全部完成,要么全部不完成。
- 一致性(Consistency):事务开始和结束时,数据库的完整性约束没有被破坏。
- 隔离性(Isolation):多个并发事务之间,相互隔离,互不干扰。
- 持久性(Durability):一旦事务提交,其结果就是永久性的。
ACID为我们构建了一个完美的“数据乌托邦”:一个有序、可信、确定性极高的世界。我们所有的业务逻辑,都建立在这块坚实的基岩之上。
然而,当我们拆分微服务,数据被分散到不同的数据库实例中时,这个“乌托邦”瞬间崩塌了。单个数据库的ACID,无法跨越网络的鸿沟。我们被迫进入了一个充满混沌和不确定性的新世界。
统治这个新世界的,是另外两套法则:CAP定理和BASE理论。
CAP定理:不可逾越的“物理定律”

- 一致性 (Consistency):所有节点在同一时间,看到的数据是完全一致的。(这里的C,比ACID的C更严苛,指“线性一致性”)
- 可用性 (Availability):每次请求,都能收到一个(非错误的)响应。
- 分区容错性 (Partition Tolerance):当网络发生分区时,系统仍然能够对外提供服务。
CAP定理指出:P是微服务架构的必然选择,因为网络永远不可靠。因此,我们必须在**C(强一致性)和A(高可用性)**之间做出抉择。
这个抉择,催生了分布式事务领域的两大流派:
- 刚性事务(CP阵营):追求强一致性,牺牲部分可用性。它试图在分布式环境中,最大程度地模拟ACID。两阶段提交(2PC)、三阶段提交(3PC)是其典型代表。它们如同古代重装铠甲的骑士,追求极致的防御和准确,但代价是笨重、迟缓,且在极端情况下,可能“阵亡”(阻塞)。
- 柔性事务(AP阵营):追求高可用性,牺牲强一致性。它拥抱BASE理论:
- Basically Available (基本可用):允许系统在出现故障时,损失部分功能,但保证核心功能可用。
- Soft state (软状态):允许系统中的数据存在中间状态,这个状态不影响系统整体可用性。
- Eventually consistent (最终一致性):系统中的所有数据副本,在经过一段时间后,最终能够达到一致的状态。TCC、SAGA、可靠消息最终一致性、Seata AT/TCC/SAGA模式,都属于这个流派。它们如同身手敏捷的刺客,追求灵活性和高可用性,但需要在业务逻辑上做出妥协和补偿。
深刻洞察:
从ACID到BASE,不仅仅是技术栈的切换,更是架构设计思想的根本转变。它要求我们从一个“确定性”世界的“完美主义者”,转变为一个“概率性”世界的“现实主义者”。我们不再奢求数据在每一时刻都是完美的,而是设计一套机制,来保证它在经历波折后,最终是完美的。这个思想转变的深度,决定了你能否驾驭复杂的分布式系统。
第二章:两阶段提交(2PC)的“理想国”与“囚徒困境”
1.1 两阶段提交(2PC):最早的“独裁者”
**2PC(Two-Phase Commit)**是分布式事务的“开山鼻祖”。它引入了一个“协调者(Coordinator)”的角色,来统一指挥所有的“参与者(Participant)”(即各个微服务)。
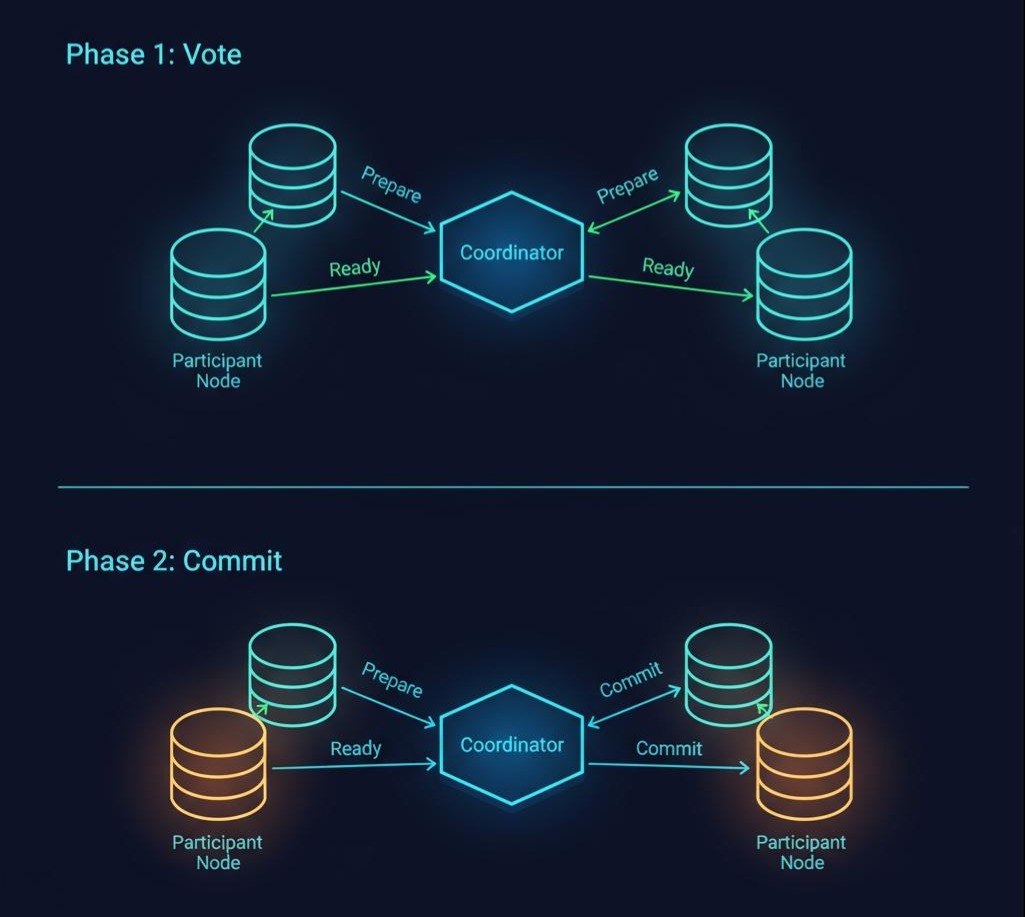
推演过程:
- 阶段一:准备/投票阶段(Prepare Phase)
- 协调者:向所有参与者,发送一个Prepare请求,并进入“等待”状态。这个请求的意思是:“各位,请你们准备好提交,告诉我你们是否能完成自己的任务?”
- 参与者:收到Prepare请求后,会执行本地事务(比如,执行SQL,锁定资源),但就是不提交(COMMIT)。它会将事务执行的结果(成功或失败),记录到事务日志中,然后向协调者返回“就绪(Ready)”或“中止(Abort)”的投票。
- 阶段二:提交/回滚阶段(Commit/Rollback Phase)
- 协调者:收集所有参与者的投票。
- 如果所有参与者都返回“就绪”:协调者就做出“全局提交”的决策。它会向所有参与者,发送一个Commit请求。
- 如果有一个或多个参与者返回“中止”,或者有参与者超时未响应:协调者就做出“全局回滚”的决策。它会向所有参与者,发送一个Rollback请求。
- 参与者:收到协调者的最终指令后,提交或回滚自己的本地事务,并释放所有锁定的资源。
2PC的致命缺陷:一场关于“阻塞”与“脑裂”的噩梦

2PC看起来很美好,但它在实践中,却充满了致命的缺陷:
- 同步阻塞(Synchronous Blocking):
- 在整个两阶段的过程中,所有参与者都在同步地、阻塞地等待协调者的最终指令。
- 特别是从Prepare成功到收到Commit/Rollback指令的这个时间窗口内,参与者所涉及的数据库资源(比如行锁)是全程被锁定的。
- 在一个高并发的系统中,这种长时间的资源锁定,会极大地降低系统的吞吐量,是性能的灾难。
- 协调者单点故障(Coordinator Single-Point-of-Failure):
- 如果协调者在阶段二,发送Commit指令的过程中宕机了……
- 场景:假设协调者只成功地向参与者A发送了Commit,但在给B发送Commit之前就挂了。
- 结果:A提交了事务,而B却因为收不到指令,永远地阻塞在那里,它所持有的锁也永远无法释放。整个系统的数据进入了不一致的状态,并且需要人工干预才能恢复。
- 数据不一致(脑裂):
- 在阶段二,如果协调者与部分参与者之间发生网络分区,也会导致数据不一致。协调者以为某个参与者超时了,决定全局回滚;而那个被分区的参与者,可能因为超时机制,自己决定提交了事务。
1.2 三阶段提交(3PC):一次“然并卵”的改良
为了解决2PC的同步阻塞和单点问题,**3PC(Three-Phase Commit)**被提了出来。它在“准备”和“提交”之间,增加了一个“预提交(Pre-Commit)”阶段,并引入了超时机制。
- CanCommit -> PreCommit -> DoCommit
- 核心思想:试图通过PreCommit阶段,来减少参与者的阻塞时间,并通过超时机制,让参与者在收不到协调者指令时,能“自行”决定提交或回滚。
3PC的困境:
3PC虽然在理论上,降低了阻塞的概率,但它并没有完全解决数据不一致的问题。在网络分区等极端情况下,不同参与者根据自己的超时判断,依然可能做出不一致的决策(一个提交,一个回滚)。
而且,它增加了通信的轮次,使得性能更差,实现也更复杂。因此,在工业界,3PC几乎没有被真正应用过。
架构师的启示:
刚性事务(2PC/XA规范)的思路,是试图用一个“上帝般”的协调者,去强制所有分布式节点,像一个单体应用一样,进行同步的、阻塞式的操作。这种反分布式的思路,注定了它在高并发、高可用的互联网场景下,必然会“水土不服”。
- 它的适用场景:仅限于那些对数据强一致性要求极高,且并发量不大、容忍低性能的内部系统(比如,银行内部的系统之间)。
- 对于互联网应用,我们必须彻底抛弃刚性事务的幻想,转向更具弹性的“柔性事务”。
第二章:柔性事务——在“最终一致”的世界里,优雅地妥协
柔性事务,放弃了对ACID的完全追求,特别是I(隔离性)和C(强一致性),转而追求一种更符合分布式世界的BASE理论——Basically Available(基本可用)、Soft State(软状态)、Eventually Consistent(最终一致性)。
它的核心思想是:允许数据在处理过程中,存在短暂的、中间态的不一致,但我们通过各种“补偿”机制,来保证数据最终会达到一致的状态。
2.1 可靠消息最终一致性:MQ的“妙用”
这是业界应用最广、也最经典的柔性事务方案。它利用消息队列,来保证“下游任务一定会被执行”。

灵魂拷问:直接在业务操作后,发一条MQ消息,就能保证可靠吗?
答案:不能!
- 场景:
- 订单服务本地数据库事务,执行COMMIT。
- 在COMMIT之后,mqProducer.send()之前,订单服务突然宕机。
- 结果:订单创建成功了(本地事务已提交),但通知库存服务扣减库存的消息,却永远地丢失了!
真正的“可靠消息”方案:本地消息表
这个方案的核心,是将“发送MQ消息”这个不可靠的网络操作,转化为一个“写入本地数据库”的可靠的本地操作。
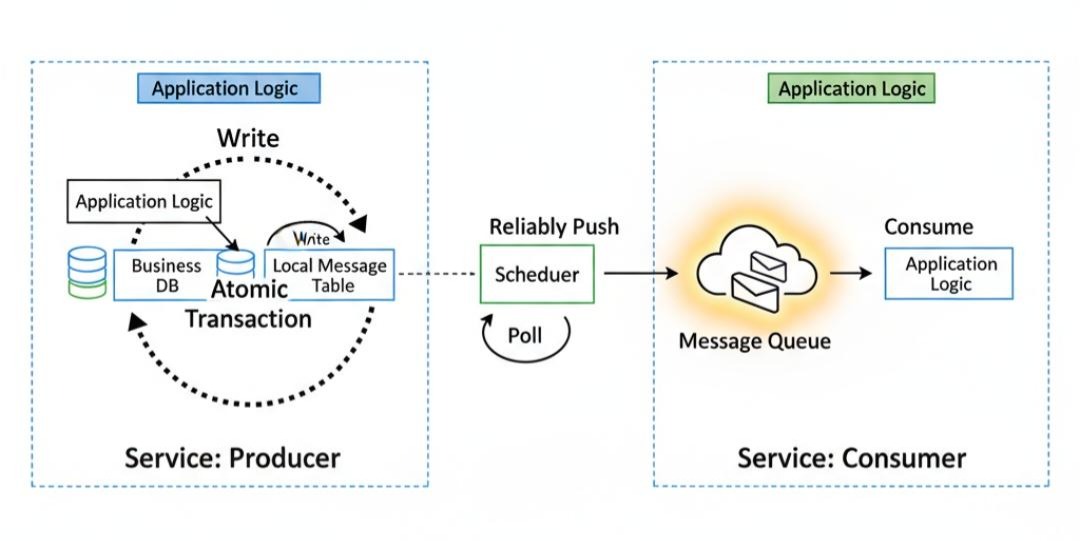
手写一个实现(推演过程):
- 数据库设计:在订单服务的数据库中,创建一张local_message表。
1 | CREATE TABLE local_message ( |
- 生产者(订单服务)的改造:
- 将“创建订单”和“写入本地消息表”,包裹在同一个本地事务中!
1 |
|
- 深刻洞察:利用数据库的原子性,我们保证了:只要订单创建成功,那么这条“待发送”的消息,就一定被可靠地记录了下来。 绝不会出现前面那种“订单成功,消息丢失”的情况。
- 消息的“投递者”:一个独立的后台任务
- 我们需要一个独立的、可靠的后台任务(比如,一个定时调度任务,或者一个独立的微服务),来专门负责“扫描”这张local_message表。
- 工作流程:
- 定时扫描local_message表中,所有status=0的记录。
- 将这些消息,真正地发送到MQ Broker。
- 如果发送成功,就将这条记录的status更新为1。
- 如果发送失败,无所谓,下次扫描时,它会被重新捞出来,继续重试。
- 高可用:这个后台任务本身,也需要保证高可用,可以部署多个实例,通过分布式锁来防止重复扫描。
- 消费者(库存服务):
- 消费者只需要正常地消费MQ消息即可。
- 重要:消费者必须实现幂等!因为后台任务的重试机制,可能导致同一条消息被发送到MQ多次。
方案总结:
| 优点 | 缺点 |
|---|---|
| 高可靠:将不确定性,全部收敛到了本地数据库事务中。 | 业务耦合:需要在每个生产者服务中,都创建一张本地消息表。 |
| 实现相对简单,不依赖任何第三方事务框架。 | 数据一致性的延迟:取决于后台任务的扫描频率。 |
| 性能好,核心流程是异步的。 | 消息投递者需要保证高可用。 |
2.2 SAGA模式:长事务的“编排艺术”
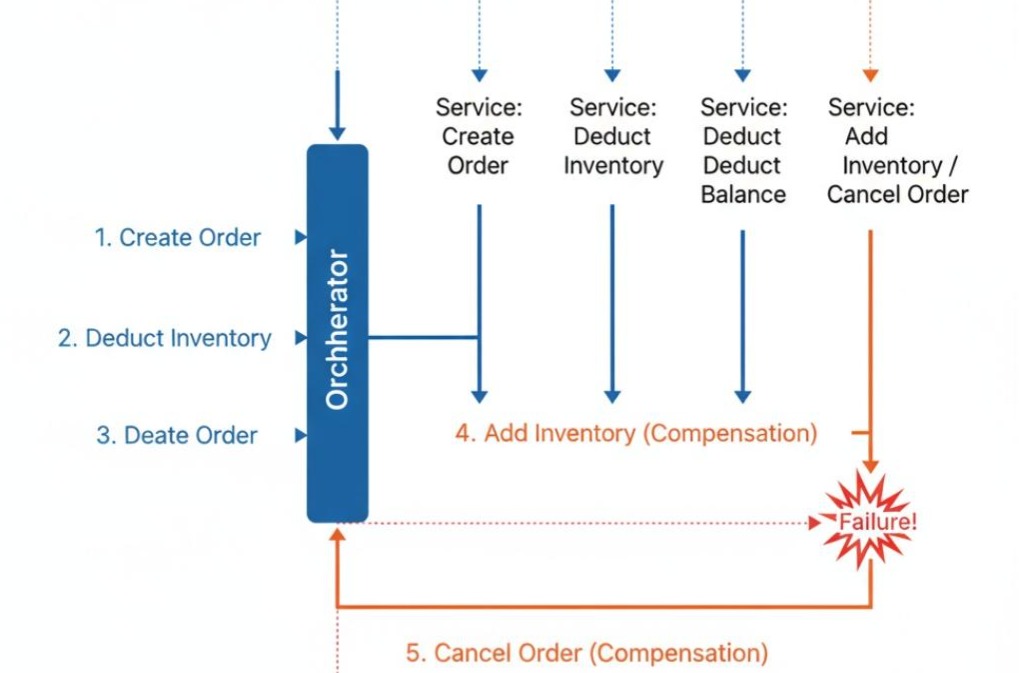
SAGA模式,源于一篇1987年的古老论文。它的核心思想是,将一个长的、全局的事务,拆分成一系列有序的、本地的子事务。
- 正向操作(Forward Recovery):依次执行T1, T2, T3, …, Tn。
- 补偿操作(Backward Recovery):如果任何一个子事务Ti失败了,SAGA会反向地、依次地调用之前所有已成功子事务的“补偿操作” Ci, C(i-1), …, C1。
以“下单”为例:
| 子事务 (Ti) | 补偿操作 (Ci) |
|---|---|
| T1: 创建订单 | C1: 取消订单 |
| T2: 扣减库存 | C2: 增加库存 |
| T3: 扣减余额 | C3: 增加余额 |
SAGA的两种实现方式(协调器):
- 编排式(Orchestration):
- 引入一个中央协调器(Orchestrator),比如一个专门的“订单流程服务”。
- 这个协调器,负责集中地、顺序地调用每一个子服务。
- 它维护着整个SAGA事务的状态。如果某个步骤失败,由它来负责调用补偿操作。
- 优点:逻辑清晰,状态集中管理,易于理解和监控。
- 缺点:引入了协调者的单点风险。
- 协同式/事件驱动(Choreography):
- 没有中央协调器。
- 每个服务,在完成自己的本地事务后,会发布一个事件(通过MQ)。
- 下一个服务,会订阅这个事件,并触发自己的本地事务。
- 优点:完全去中心化,服务之间松散耦合。
- 缺点:整个事务的调用链,分散在各个服务中,非常难以追踪和调试。补偿逻辑也变得非常复杂。弹”,只有最适合你当前业务场景的、经过深思熟虑的“权衡”。
SAGA的挑战:
- 补偿操作的设计:补偿操作必须是可靠的、幂等的。
- 缺乏隔离性:因为每个子事务都是立即提交的,所以S-AGA事务无法保证隔离性。在一个SAGA事务的执行过程中,一个外部的读请求,可能会看到一个“只创建了订单,但还没扣库存”的中间状态。
第三章:Seata的“魔法”——试图对业务“无侵入”的终极尝试
前面我们讨论的可靠消息、SAGA等柔性事务方案,虽然解决了问题,但都有一个共同的“痛点”:对业务代码的侵入性太强。
- 可靠消息方案,要求我们在业务代码中,手动地去操作local_message表。
- SAGA方案,要求我们为每一个正向操作,都手动地编写一个对应的补偿接口。
这对于开发者来说,心智负担很重,也容易出错。Seata项目的诞生,其核心目标之一,就是尽可能地降低分布式事务对业务代码的侵入性,让开发者能够像使用本地**@Transactional**一样,去使用分布式事务。
Seata提供了多种事务模式(AT, TCC, SAGA, XA),其中,最具“魔法”色彩、也最被广泛讨论的,就是它的AT(Automatic Transaction)模式。
3.1 Seata AT模式的核心思想:自动补偿
AT模式,本质上是一种基于“两阶段提交”协议的、自动生成补偿逻辑的方案。它巧妙地结合了2PC的形态和SAGA的补偿思想。
AT模式的三个核心组件:
- TC (Transaction Coordinator) - 事务协调者:
- 一个独立的Server,负责维护全局事务和分支事务的状态。它就像是2PC中的那个“协调者”。
- TM (Transaction Manager) - 事务管理器:
- 嵌入在事务发起方(比如,订单服务)的框架中。
- 负责开启、提交或回滚一个全局事务。
- RM (Resource Manager) - 资源管理器:
- 嵌入在每一个参与者服务(比如,库存服务、账户服务)的框架中。
- 负责管理和注册分支事务,并与TC进行协调。
3.2 AT模式的“魔法”揭秘:一次UPDATE背后的Undo Log
让我们来完整地、深入地推演一次AT模式的执行流程。假设订单服务发起一个全局事务,需要调用库存服务扣减库存。
全局事务发起方(订单服务):
1 | // 这就是魔法的入口 |
分支事务参与者(库存服务):
1 | // 这是一个本地事务注解 |
注意,库存服务的代码,看起来完全感知不到自己正在参与一个分布式事务!
这背后,到底发生了什么?
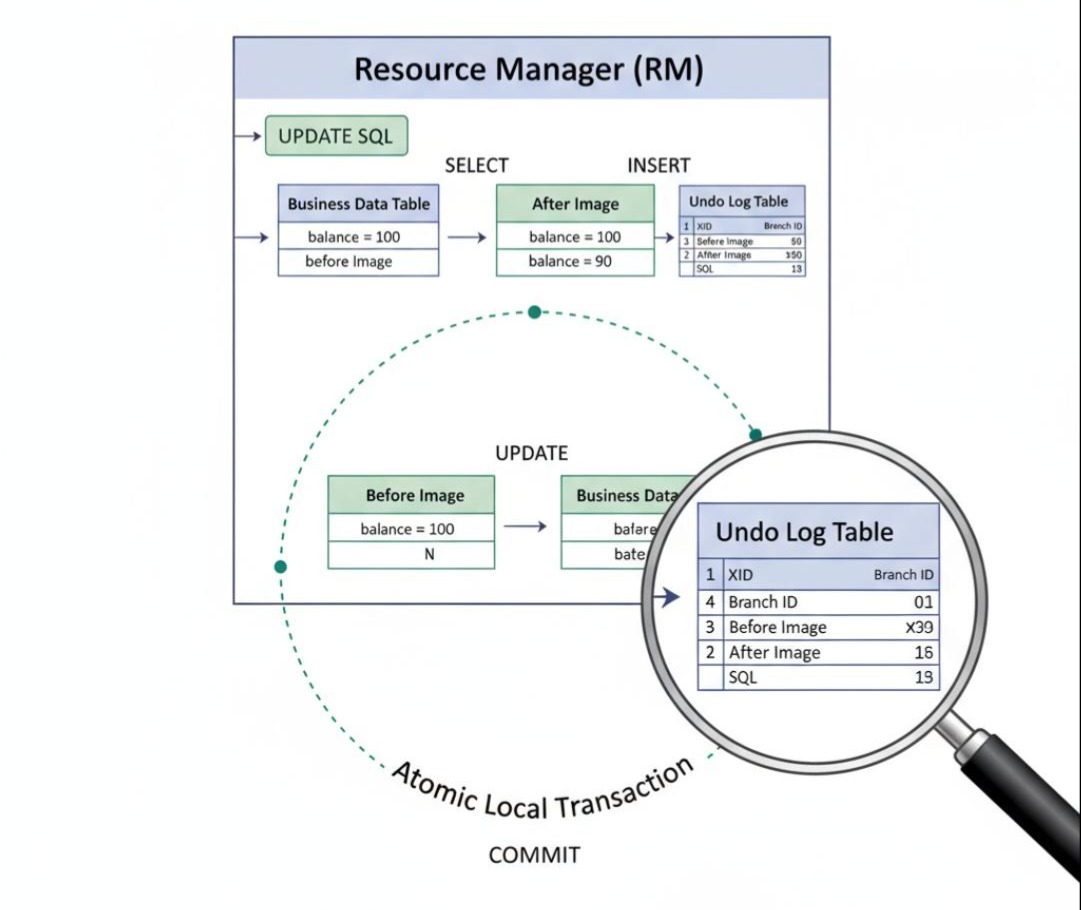
阶段一:执行与“快照”
- TM开启全局事务:当placeOrder方法被调用时,@GlobalTransactional注解会驱动TM,向TC注册一个全局事务,并获取一个全局唯一的XID。
- XID的传播:TM会将这个XID,通过RPC调用的上下文(比如HTTP Header),隐式地传递给库存服务。
- RM拦截SQL:库存服务的RM,通过代理数据源(DataSource Proxy),拦截到了**stockMapper.updateStock(…)**这条SQL。
- 解析SQL并生成Undo Log(魔法核心!):
- 在执行这条UPDATE语句之前,RM会先查询出这行数据更新前的镜像(Before Image)。
- 然后,它执行这条UPDATE语句,并查询出这行数据更新后的镜像(After Image)。
- 接着,它将这个“前镜像”和“后镜像”,连同SQL本身、表名、主键等信息,一起序列化,生成一条Undo Log。
- RM将这条Undo Log,与它自己的本地业务数据更新,在同一个本地数据库事务中,一起提交。
- 深刻洞察:这一步,是AT模式的绝对核心!它保证了:只要你的业务SQL执行成功,那么用于“回滚”你这个操作的Undo Log,就一定被可靠地持久化下来了。
- 注册分支事务并锁定资源:
- 本地事务提交成功后,RM会向TC注册一个分支事务,并将自己持有的全局锁(锁的粒度是表名+主键)信息,上报给TC。
- TC会集中管理所有分支事务持有的全局锁。如果其他全局事务,也想修改同一行数据,TC会在锁检查时,发现冲突并让其等待。
- 返回成功:库存服务执行完毕,向订单服务返回成功。
阶段二:全局提交或回滚

- TM请求全局提交:订单服务的placeOrder方法执行完毕,没有抛出异常。TM会向TC,发起一个“全局提交”的请求。
- TC协调提交:
- TC收到全局提交请求后,会异步地向所有参与该XID的分支事务的RM,发送“分支提交”的请求。
- RM收到分支提交请求后,会异步地、快速地将之前存储的Undo Log删除,并释放全局锁。这个过程非常快,因为它只是删除一条日志。
- 如果发生异常(全局回滚):
- 假设在placeOrder方法中,调用完库存服务后,又调用了账户服务,而账户服务抛出了异常。
- TM请求全局回滚:@GlobalTransactional注解会捕获到这个异常,并驱动TM,向TC发起一个“全局回滚”的请求。
- TC协调回滚:TC会向所有(包括已经成功的库存服务)分支事务的RM,发送“分支回滚”的请求。
- RM执行自动补偿:库存服务的RM收到回滚请求后,它会:
- 找到该分支事务对应的Undo Log。
- 解析Undo Log,从中拿出“前镜像(Before Image)”。
- 自动地、反向地生成一条UPDATE语句,将数据恢复回“前镜像”的状态。
- 执行这条恢复SQL,完成补偿。
AT模式的权衡分析:
| 优点 | 缺点 |
|---|---|
| 对业务无侵入:开发者几乎无需关心分布式事务的细节,极大降低了使用门槛。 | 性能损耗:每一次写操作,都会变成“SELECT FOR UPDATE+UPDATE+INSERT Undo Log”,并伴随着RPC通信,性能损耗相对较大。 |
| 自动补偿:框架自动生成Undo Log和补偿逻辑,避免了手动编写的复杂性和错误。 | 隔离性问题:AT模式默认的隔离级别是“读未提交(Read Uncommitted)”。在一个全局事务提交之前,另一个本地查询,可能会读到这个事务修改的“脏数据”。 |
| 适用范围广:适用于绝大多数基于JDBC的数据库操作。 | 全局锁:依赖TC进行全局锁的管理,TC可能成为性能瓶颈。 |
如何解决AT模式的“脏读”问题?
Seata提供了两种方案:
- 全局锁(默认):在查询时,也去TC获取全局锁,实现“读已提交(Read Committed)”的隔离级别。但这会极大地影响并发读的性能。
- SQL中加入FOR UPDATE:在SELECT语句中,手动加入FOR UPDATE,利用数据库自身的悲观锁,来保证读取时,不会读到其他未提交事务的数据。
第四章:终极反思——没有“银弹”,只有“权衡”的艺术
我们已经遍历了从2PC的刚性约束,到可靠消息、SAGA的柔性妥协,再到Seata AT模式的自动补偿。现在,是时候跳出具体的技术实现,站在一个更高的维度,来审视这场关于“一致性”的战争了。
分布式事务的“不可能三角”
我们可以构建一个简化的决策模型,来帮助我们进行选型。一个分布式事务方案,通常需要在以下三个维度中进行权恒:
- 一致性强度(Strong <-> Eventual):从强一致性到最终一致性。
- 性能损耗(High <-> Low):方案本身带来的性能开销。
- 业务侵入性(High <-> Low):对现有业务代码的改造程度。
主流方案的雷达图对比:
| 方案 | 一致性强度 | 性能损耗 | 业务侵入性 | 适用场景 |
|---|---|---|---|---|
| 2PC/XA | 最强 | 最高 | 中 | 低并发、强一致性要求的内部系统。 |
| 可靠消息 | 最终一致 | 最低 | 高 | 异步化、高吞吐、对延迟不敏感的场景。 |
| SAGA | 最终一致 | 低 | 最高 | 长事务、需要人工介入的、复杂的业务流程。 |
| Seata TCC | 最终一致 | 中 | 高 | 需要自定义补偿逻辑、对性能要求高的场景。 |
| Seata AT | 准强一致 | 中 | 最低 | 绝大多数需要分布式事务的CRUD业务场景。 |
(注:Seata TCC模式,是SAGA思想的一种实现,需要手动实现Try-Confirm-Cancel三个接口,提供了更高的灵活性和性能,但侵入性也更高。)
架构师的终极思考与建议:
- 能不用,就不用(Avoidance is the Best Strategy):
- 在进行微服务拆分时,最重要的原则之一,就是按照“业务领域”和“事务边界”来拆分。如果能将需要强一致性操作的业务,都内聚在同一个微服务内部,利用其单体数据库的本地事务来解决,这永远是最优的、成本最低的方案。
- 灵魂拷问:你真的需要分布式事务吗?这个业务场景,是否可以通过异步的、最终一致性的方案来满足?(比如,转账操作,银行内部系统之间也大量使用异步对账,而非全局的强事务)。
- 优先选择“最终一致性”的柔性事务(Embrace Eventual Consistency):
- 对于绝大多数互联网应用,用户的体验,对可用性和性能的敏感度,远高于对数据瞬间强一致性的敏感度。
- 可靠消息最终一致性方案,虽然有侵入性,但其模型简单、可靠、性能好,应该成为你的首选武器。
- 将Seata AT作为“最后的堡垒”(Use Seata AT as the Last Resort):
- 当你确实面临一个无法通过业务改造来避免、且要求准实时一致性的场景时,Seata AT模式,以其极低的业务侵入性,提供了一个非常高效的开发时解决方案。
- 但是,你必须清楚地意识到,你正在为这种“便利”,支付性能损耗和隔离性降低的代价。你必须对你的系统进行充分的压力测试,来评估Seata引入的TC和全局锁,是否会成为你的性能瓶颈。
结语:从“追求完美”,到“管理不完美”
分布式事务的探索之旅,更像是一次架构师心智成熟的旅程。我们从最初对ACID“完美世界”的执着,到逐渐理解并接受分布式世界“不完美”的现实,最终学会了如何去“管理这种不完美”。
- 2PC,是试图用命令来消除不完美的“理想主义者”。
- 可靠消息/SAGA,是承认不完美,并通过补偿来最终修复它的“现实主义者”。
- Seata AT,是试图用技术来为我们屏蔽掉这种不完美的“魔术师”。
没有哪一种方案是“银弹”。卓越的架构师,不是那个手握“银弹”的人,而是那个拥有一个装满了各式武器的“军火库”,并能深刻理解每一种武器的威力、射程、后坐力和适用场景,然后在最恰当的时机,选择最恰当武器的“武器大师”。
你的职责,不再是追求一个技术上“完美”的方案,而是在业务需求、技术成本、团队能力、未来演进等多个维度之间,找到那个当下最合适的、优雅的妥协。
这,就是架构的艺术。

