百万架构师成长之路(11):可观测性的“圣三一”:Logging, Metrics, Tracing的融合与未来
导语:从“摸黑排障”的“盲人摸象”,到“上帝视角”的“洞若观火”
想象一下,凌晨三点,你被急促的告警电话惊醒:“线上支付接口P0级故障,大量用户反馈‘系统繁忙’!” 你睡眼惺忪地连上VPN,打开终端,开始了那场你我早已身心俱疲的“摸黑排障”仪式:
1.你先tail -f应用日志,希望能从海量的INFO和DEBUG中,找到一丝ERROR的踪迹。
**2.**接着,你登录监控系统,试图从几十条令人眼花缭乱的CPU、内存、QPS曲线上,找到那个“异常”的拐点。
**3.**然后,你猜测可能是下游的数据库慢了,于是又去翻看DBA提供的慢查询日志。
**4.**最后,在花费了数小时,协调了多个团队之后,你可能才定位到,问题的根源,竟然是某个不起眼的、被三次RPC调用间接依赖的“优惠券服务”,因为缓存失效而导致的数据库慢查询。这场混乱、低效、依赖直觉和运气的“盲人摸象”式排障,是每一个运维和开发人员的噩梦。它暴露了一个残酷的现实:一个没有被良好“观测”的分布式系统,其复杂性将远超人类大脑的处理极限。
传统的“监控(Monitoring)”,更多的是一种被动的、基于已知问题的“白盒”检查。我们设置一些阈值(CPU > 80%),当系统触碰这些阈值时,发出告警。它能回答“什么(What)”坏了,但很难回答“为什么(Why)”坏了。
而“可观测性(Observability)”,是一个更主动、更深刻的概念。它源于控制理论,指的是:仅通过观察一个系统的外部输出,就能推断出其内部状态的能力。 在软件领域,这意味着,我们不应该去“预测”未来可能发生什么故障,而是应该收集足够丰富、足够关联的数据,使得当任何未知的故障发生时,我们都有能力去提问、探索、下钻,并最终定位到根源。
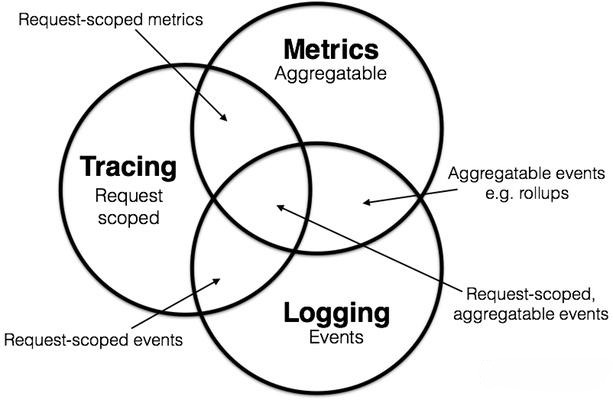
Logging (日志), Metrics (指标), Tracing (追踪),就是支撑起可观测性的“神圣三位一体”。
Logging:记录了系统中发生的、离散的、具体的事件。它告诉我们“发生了什么”。
Metrics:是可聚合的、数字化的度量。它告诉我们“系统表现如何,趋势怎样”。
Tracing:记录了单个请求,在分布式系统中的完整生命周期和路径。它告诉我们“一个请求经历了什么”。
本篇,我们将深入这“三位一体”的内核。我们将看到,它们并非孤立存在,而是正在OpenTelemetry的旗帜下,走向融合。我们将直面Metrics领域的“核难题”——高基数,并解剖Tracing的魔法核心——上下文传播。最终,你将学会如何构建一个真正的、从“被动监控”迈向“主动观测”的“上帝之眼”。
第一章:三大支柱——从信息孤岛到协同作战
在构建可观测性体系的初期,我们往往会为“圣三一”的每一位成员,分别建立它们的“神殿”。
1. Logging(日志)- 帝国的“起居注”
日志是我们最熟悉的朋友,也是最古老的遥测信号。它以文本或JSON的形式,详实地记录下程序运行的每一个关键足迹。
- 典型生态: Filebeat -> Logstash/Kafka -> Elasticsearch -> Kibana (ELK Stack)
- 超能力: 提供了最丰富的细节和上下文。当一个错误发生时,只有日志能提供详尽的堆栈信息、变量值和业务场景描述。它是事后调试(Post-mortem Debugging)的终极真相来源。
- 阿喀琉斯之踵:
- 非结构化之痛: 传统日志是为人类阅读而设计的,机器难以解析和聚合。即使是JSON日志,其结构也往往不统一。
- 查询风暴: 在海量数据中进行全文检索,成本极高。对TB级的日志进行一次复杂的关联查询,可能会耗时数分钟,甚至让Elasticsearch集群不堪重负。
- 缺乏宏观视角: 日志是离散的“点”,你很难从无数的点中,看出系统负载的“趋势线”。
2. Metrics(指标)- 帝国的“国情罗盘”
指标是数值化的、可聚合的数据点,通常以时间序列(Time Series)的形式存储。
- 典型生态: Prometheus Server -> Alertmanager -> Grafana
- 超能力:
- 高效的存储与查询: 时间序列数据库(TSDB)为数值聚合和范围查询,进行了极致的优化。
- 强大的数学能力: Prometheus的PromQL查询语言,可以对指标进行丰富的数学运算(rate, sum, histogram_quantile),轻松洞察趋势、计算SLA/SLO。
- 监控告警的基石: 几乎所有可靠的自动化告警,都建立在对Metrics的阈值判断之上。
- 阿喀琉斯之踵:
- 细节的丢失: 指标是聚合后的结果。它能告诉你“过去5分钟,API的平均延迟是500ms,P99延迟是2s”,但它无法告诉你,是哪一个用户的哪一次具体请求,贡献了那个2s的延迟。
- 预定义之困: 你只能分析那些你预先定义和采集了的指标。如果出现一个未知问题,而你又没有埋点相关的指标,你将束手无策。
3. Tracing(追踪)- 帝国的“情报地图”
分布式追踪通过一个全局唯一的TraceID,将一个请求在所有微服务中的调用路径,串联成一个完整的调用链(Trace)。每个服务中的一次具体操作,被称为一个跨度(Span)。
- 典型生态: Jaeger / Zipkin / SkyWalking
- 超能力:
- 性能瓶颈的“显微镜”: 通过可视化的火焰图,可以一目了然地看到整个请求的耗时,分布在哪个服务的哪个方法上。
- 服务依赖的“活地图”: 追踪系统能自动生成服务间的依赖拓扑图,帮助我们理解复杂的系统架构。
- 阿喀琉斯之踵:
- 巨大的存储开销: 记录每一次请求的完整调用链,数据量是惊人的。因此,绝大多数生产系统都只能进行“采样(Sampling)”,比如只记录1%的请求。
- “盲人摸象”的风险: 如果你遇到的问题,恰好发生在那未被采样的99%的请求中,追踪数据就帮不了你。
信息孤岛的困境:

当线上发生告警(Metrics),工程师需要先去Grafana查看指标图表,然后根据时间戳,去Kibana的汪洋大海中捞取相关的日志(Logging),如果运气好,日志里打印了TraceID,他才能再去Jaeger系统查询具体的调用链细节(Tracing)。这个过程充满了猜测和跳转,效率低下。
深刻洞察:
Logging, Metrics, Tracing的真正力量,不在于它们各自为政时提供的孤立信息,而在于它们无缝关联后产生的协同效应。我们的终极目标,是在查看Metrics图表的一个异常尖峰时,能一键下钻(Drill Down)到造成这个尖峰的、所有相关的Traces;在查看某一个Trace的异常Span时,能立刻看到它在那个时间点打印的所有Logs。实现三大支柱的数据关联,是可观测性从“可用”走向“高效”的里程碑。
第二章:大一统:OpenTelemetry,可观测性世界的“秦始皇”
在OpenTelemetry(简称OTel)出现之前,可观测性领域如同一个“春秋战国”:Prometheus有自己的数据格式,Zipkin有B3传播规范,Jaeger有自己的格式,各大云厂商(Datadog, New Relic)更是壁垒森严。你的应用程序一旦使用了某家的SDK进行埋点,就被“锁定”了。
OTel的诞生,就是要“书同文,车同轨”,结束这场混战。它是一个由CNCF(云原生计算基金会)托管的、开源的、厂商中立的规范和工具集,旨在标准化遥测数据(Logs, Metrics, Traces)的生成、采集和导出。
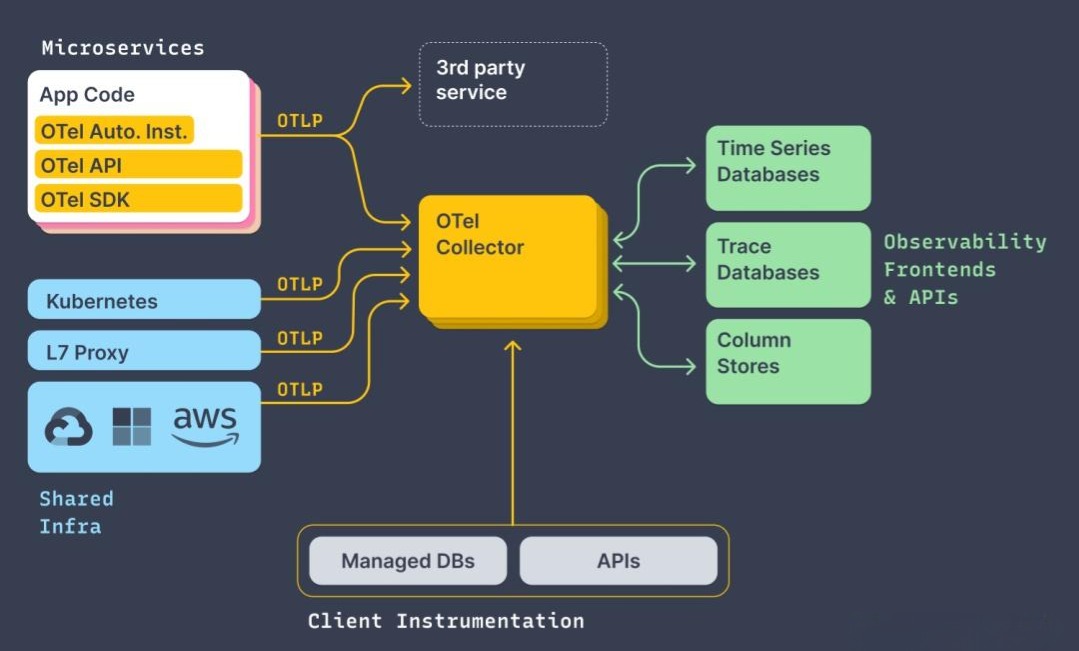
OTel 不是一个后端系统,而是一个“标准”和“管道”。
它的核心组件包括:
- Specification(规范):这是OTel的“宪法”。它定义了Trace、Metric、Log的统一数据模型,以及API、SDK的行为规范。这是所有组件的理论基础。
- APIs & SDKs(应用程序接口与软件开发工具包):这是植入你应用代码中的“探针”。OTel为所有主流语言(Java, Go, Python…)都提供了官方的实现。你的代码只需要调用OTel API,而无需关心数据最终会发送到哪里。
- 自动探针(Auto-Instrumentation):对于Java等语言,OTel提供了Java Agent,可以无侵入地、自动地为你所有的主流框架(Spring MVC, Dubbo, gRPC, JDBC…)生成追踪和指标数据。这是落地的杀手锏。
- Collector(采集器):这是OTel体系的“瑞士军刀”和“数据总线”。它是一个独立部署的、高性能的代理服务,可以:
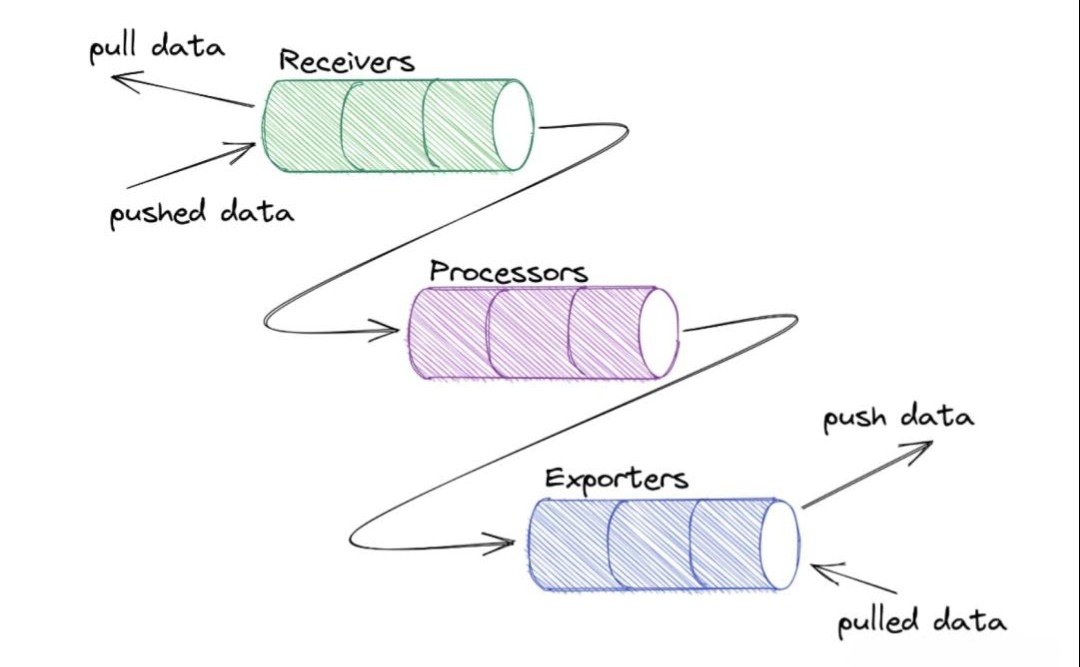
- 接收(Receiver):以多种格式(OTel的OTLP, Prometheus, Jaeger, Zipkin…)接收遥测数据。
- 处理(Processor):对数据进行过滤、转换、丰富、采样、批量处理。比如,给所有数据都加上k8s的pod name标签。
- 导出(Exporter):将处理后的数据,以目标后端系统所需的格式,导出到任意多个目的地(Prometheus, Jaeger, Elasticsearch, Kafka, 各大云厂商…)。
OTel如何实现“大一统”?
关键在于其统一的数据模型。在OTel的世界里:
- 一个Span(Trace的一部分)天生就带有关联的Resource信息(如服务名、主机名)和Attributes(标签)。
- 一个Log记录,不再是孤立的字符串,它可以直接附加上TraceId和SpanId,从诞生起就与某个调用链绑定。
- 一个Metric数据点,可以通过Exemplars(范例)的特性,附加上一个TraceId,指向一个在此时刻贡献了这个指标值的具体请求。
架构演进的启示:
- Before OTel: 应用需要内嵌多个Agent/SDK,分别对接不同的后端,更换后端系统是“伤筋动骨”的大手术。
- After OTel: 应用只需要一个OTel SDK。所有的数据都发送给OTel Collector。未来想增加或更换后端系统(比如从自建Jaeger换成商业APM),只需要修改Collector的配置,应用代码无需任何改动。
深刻洞察:
OpenTelemetry标志着可观测性领域的一次范式转移:从关注“工具”转向关注“数据”。它将遥测数据本身,提升为一种标准化的、可移植的、与供应商解耦的“一等公民”。开发者只需按照统一标准“一次埋点”,就可以“到处运行”,彻底摆脱了供应商锁定的枷锁。OTel Collector则成为了数据管道的“中央枢纽”,赋予了架构师前所未有的灵活性和控制力,去构建一个面向未来的、可插拔的观测体系。
第三章:指标的“诅咒”:高基数(High Cardinality)的挑战与应对
当我们拥抱了Metrics,很快就会遇到它最大的敌人——高基数。

什么是基数(Cardinality)?
基数,指的是一个Metric所有标签(Label)组合后,产生的唯一时间序列(Time Series)的数量。
- 低基数Metric: http_requests_total{method=”GET”, path=”/api/v1/users”}。method和path的组合是有限的,比如几十、几百个。
- 高基数Metric: http_requests_total{…, user_id=”12345”, request_id=”uuid-abc-def”}。如果你的系统有百万用户,user_id这个标签就会产生百万个唯一的时间序列。request_id更是灾难,每个请求都不同,基数是无穷的。
为什么高基数是“诅咒”?
Prometheus等TSDB,为了实现快速查询,会为每一个唯一的时间序列,在内存中建立索引。
- 内存爆炸: 百万级的基数,意味着百万级的索引条目,会迅速耗尽Prometheus服务器的内存。
- 性能雪崩: 查询和聚合这些海量的时间序列,会给CPU和磁盘I/O带来巨大压力,导致查询超时、甚至服务崩溃。
- 成本飙升: 存储这些数据,也会带来高昂的成本。
高基数的诱惑与陷阱:
我们总有一种冲动,想把尽可能多的信息塞进Metric的标签里,因为它能提供更精细的切分维度。但这种“贪婪”正是通往“地狱”的捷径。
工业级的应对方案:
- 防御性设计(代码层):
- 克制与规范: 制定严格的埋点规范,严禁将用户ID、请求ID、邮箱、订单号等无限集合的维度,作为Metric的标签。
- 维度聚合: 对于有一定基数但又想分析的维度(如商品ID),不要直接使用ID,而是将其聚合成“商品品类(Category)”,大大降低基数。
- **管道中清洗(OTel Collector / Prometheus Relabeling):**这是更灵活的“事中控制”手段。通过在采集管道中配置规则,动态地丢弃或修改标签。
1 | # Prometheus relabel_config example |
- **Exemplars(范例)- 鱼与熊掌兼得的艺术:**这是解决高基数问题的最优雅、最现代的方案,也是OTel和新版Prometheus主推的特性。
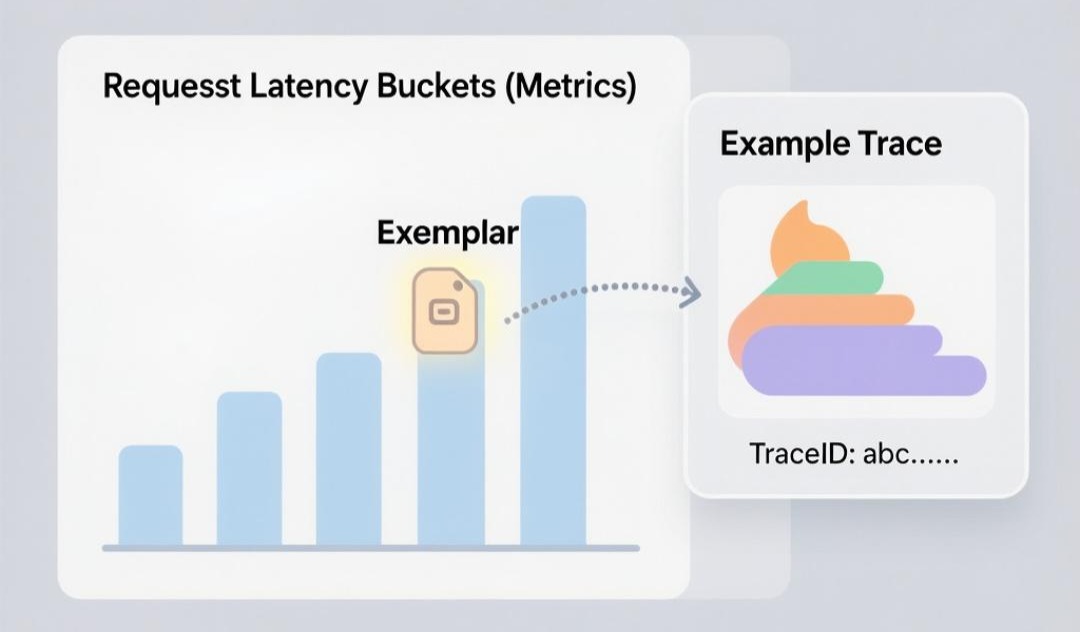
- 原理: 它允许你在一个聚合的Metric数据点上,附加一个或多个“范例”,这个范例就是导致这个数据点的具体TraceID。
- 举例: 我们有一个低基数的http_request_latency_seconds_bucket直方图。当一个请求的延迟是5秒,落入le=”5.0”这个桶时,Prometheus不仅会让这个桶的计数器+1,还会记录下这个请求的TraceID作为Exemplar。
- 效果: 在Grafana的图表上,你不仅能看到延迟的P99曲线,还能在曲线的尖峰处,看到一个标记,点击它,就能直接跳转到造成这个尖峰的那个请求的Jaeger Trace页面!
- 价值: Exemplars完美地将宏观的Metrics和微观的Traces关联了起来,它让你既能享受低基数Metrics的性能和存储优势,又不会丢失定位具体问题的细节信息。
- **探索性后端(Logging-based Metrics):**对于某些临时的、探索性的高基数分析需求,可以反其道而行之:将带有丰富标签的数据,作为结构化日志(Logging)存入Loki、Elasticsearch等系统。然后,通过这些系统的查询语言(LogQL, Lucene),在查询时(Query-time),动态地生成指标。这牺牲了查询性能,但换取了极大的灵活性。
深刻洞察:
对待高基数问题,展现了一个架构师的成熟度。初学者往往陷入“要么全有,要么全无”的困境,而高手则懂得如何进行“有损压缩”和“信息链接”。Exemplars的出现,是可观测性领域的一个里程碑,它标志着我们不再需要将所有细节都硬塞进Metric里,而是学会了用更聪明的“指针(TraceID)”,在高维度的聚合数据和低维度的样本数据之间,建立起一座高效的桥梁。
第四章:追踪的“丝线”:上下文传播(Context Propagation)的实现原理
分布式追踪的魔法,在于它能将一个请求在几十上百个服务间的漫游轨迹,串成一条线。支撑这个魔法的底层技术,就是上下文传播(Context Propagation)。
核心问题:
当Service A调用Service B时,Service B如何知道,这个请求是源于Service A正在处理的那个Trace的一部分?
解决方案:上下文(Context)
上下文是一个轻量级的、与业务逻辑无关的数据载体,它通常包含:
- Trace ID: 全局唯一的ID,标识了整个请求链路。
- Parent Span ID: 调用方(Service A)的Span ID。Service B创建的新Span,将以此作为父ID。
- Sampling Decision: 是否采样的决定。
- Baggage: 其他需要跨服务传递的业务数据(如用户灰度标签)。
传播(Propagation)- 接力棒的传递:
- **跨进程传播(Inter-Process Propagation):当服务间通过网络调用时(HTTP, gRPC, MQ),上下文需要被序列化(Inject)并注入到协议的载体中。接收方则需要从中提取(Extract)**并反序列化。
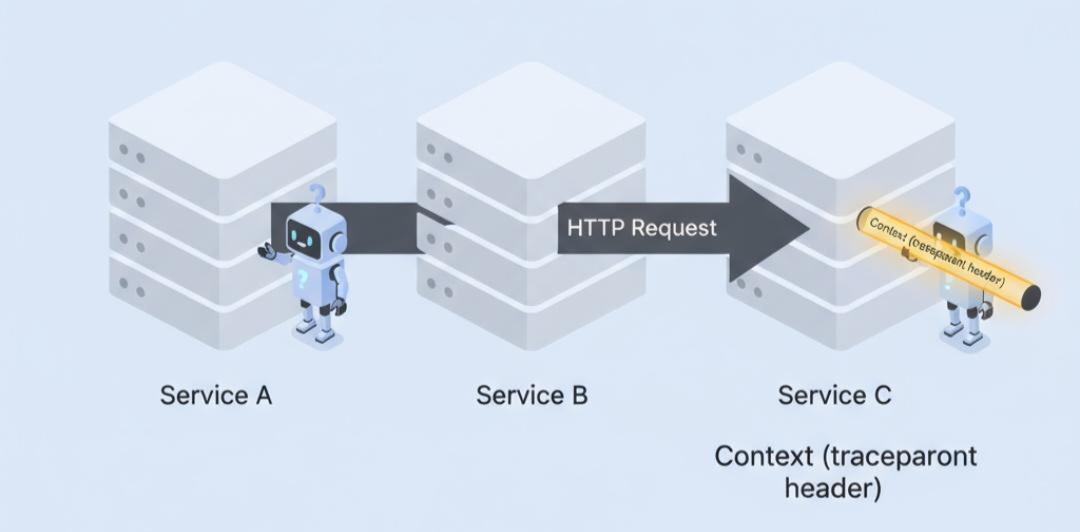
- W3C Trace Context 标准: 为了解决各家追踪系统传播头不统一的问题,W3C制定了标准。现在,几乎所有的框架和云服务商都支持它。
- traceparent 头:包含了版本、TraceID、Parent Span ID、采样标志。例如: 00-0af7651916cd43dd8448eb211c80319c-b7ad6b7169203331-01
- tracestate 头:用于携带特定供应商的附加信息。
- 工作流程(以HTTP为例):a. Service A(Client)的OTel探针,在发送HTTP请求前,从当前上下文中获取Trace信息,生成traceparent头,并注入到HTTP Headers中。b. Service B(Server)的OTel探针,在收到请求时,检查HTTP Headers,如果发现traceparent头,就将其提取出来,作为当前新线程的上下文。
- **进程内传播(Intra-Process Propagation):**在一个服务内部,methodA()调用methodB(),上下文是如何传递的?
- 方案一:显式传递(侵入性强,不推荐)
1 | // Every method needs a Context parameter |
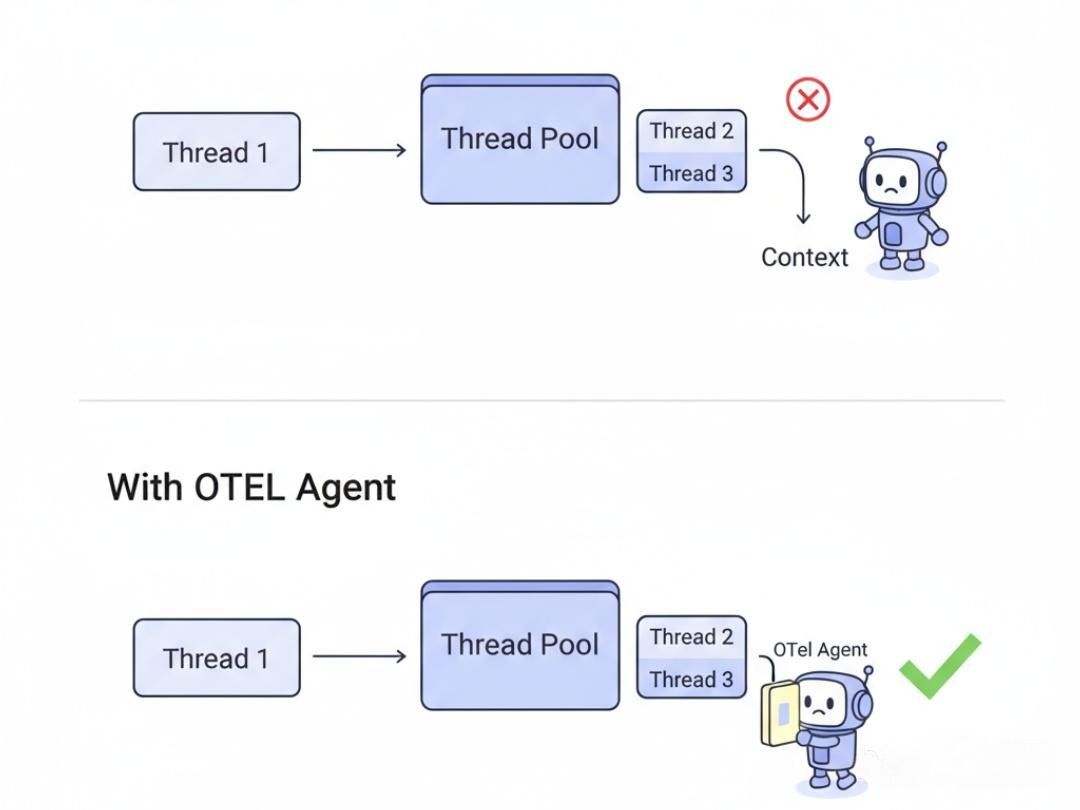
- 方案二:隐式传递(主流方案)利用ThreadLocal。当一个请求进入服务时,探针会将上下文存入一个ThreadLocal变量。这样,在这个线程的整个生命周期中,任何地方的代码,都可以通过一个静态方法(如Context.current())获取到当前的上下文,而无需在方法签名中显式传递。
异步编程的挑战:
在现代的异步/响应式编程中(CompletableFuture, Project Reactor, Go goroutine),业务逻辑会在不同的线程(池)之间跳转。ThreadLocal会失效!
- 解决方案: OTel等探针库,会深入到这些异步框架的底层。当一个异步任务被提交或调度时,探A针会自动地将当前线程的上下文,“捕获”下来,并与这个任务绑定。当这个任务在另一个线程上开始执行时,探针又会负责将这个“捕获”的上下文,设置到新线程的ThreadLocal中。这个过程对开发者是完全透明的。
深刻洞察:
上下文传播,是分布式系统的“隐形脉络”。它是一种典型的**切面(Aspect-Oriented)**思想的应用。一个成熟的可观测性体系,必须通过自动化探针,将这种与业务无关、但又至关重要的“脉络”,无侵入地织入到系统的每一寸肌理之中。理解上下文传播的机制,尤其是它在异步场景下的挑战与实现,是区分一个“会用”追踪工具的工程师和一个“懂”分布式系统的架构师的关键。
结语:从“三足鼎立”到“数据融合”的未来
我们完成了这次穿越可观测性“圣三一”的深度旅程。我们看到了日志如何从“无序”走向“结构化”,Metrics如何在“高基数”的挑战下砥砺前行,Tracing如何用“上下文传播”的魔法,为我们绘制出请求的生命轨迹。
这“三位一体”,并非孤立存在。它们的真正力量,在于“融合”。
- 当你在Metrics图表上,发现一个错误的尖峰时,你应该能一键下钻,看到在那个时间点,所有相关的错误日志。
- 当你在日志中,找到一条关键的ERROR时,你应该能通过日志中嵌入的trace_id,一键跳转到对应的分布式追踪链路图,看到这个错误发生的完整上下文。
- 当你在追踪链路图中,发现某个Span的延迟异常高时,你应该能关联到这个Span所在服务的、在那个时间段内的所有Metrics(CPU, GC, 线程池状态),来进行深度根因分析。
OpenTelemetry,正在为我们铺平通往这个“数据融合”未来的康庄大道。它将可观测性的能力,从一种需要专家级知识才能构建的“奢侈品”,变成了一种任何开发者都可以轻松接入的、标准化的“水电煤”。
作为架构师,你的职责,已经从“构建监控工具”,转变为“构建一种可观测的文化”。你需要:
- 推动标准的落地:在你的组织中,将OpenTelemetry作为可观测性的唯一标准。
- 教育和赋能:教会每一个开发者,如何正确地使用结构化日志,如何定义有意义的Metrics,如何在关键业务逻辑中添加自定义的Span。
- 打破数据孤岛:推动监控平台、日志平台、追踪平台的深度集成和关联,为你的团队,提供一个真正统一的、无缝下钻的“上帝视角”。
因为,只有当系统变得“可观测”时,它才是真正“可理解”的。而只有当它变得“可理解”时,我们才可能去“掌控”和“演进”这个日益复杂的、由代码构成的数字世界。
至此,本系列的十一篇深度技术长文,为你构建了一幅从思维、底层、数据、共识、流量、治理到观测的完整后端架构师知识图谱。这趟旅程,是对技术深度和广度的极限探索。

