百万架构师成长之路(13):软件交付的“高速公路”:云原生时代的DevOps与FinOps体系建设
导语:你的“交付能力”,定义了你的“创新速度”
在前十二篇中,我们如同一个全能的建筑师和城市规划师,设计了宏伟的系统帝国,规划了高效的组织结构。
然而,一个无法被快速、可靠、低成本地建造、迭代和维护的城市,终究只是一张美丽的废纸。软件交付(Software Delivery),就是连接“架构蓝图”与“商业价值”的最后,也是最关键的一公里。
想象一下,两个团队,A和B,他们都拥有同样才华横溢的工程师,同样优雅的微服务架构:
团队A:他们的软件交付流程,是一条泥泞、崎岖的“乡间小路”。一次发布,需要开发、测试、运维多个团队之间,通过邮件、工单、手动执行脚本来进行接力。整个过程耗时数天,充满了人为错误的风险。每一次上线,都像是一场“赌博”,所有人都要通宵待命,严阵以待。
团队B:他们的软件交付流程,是一条宽阔、平坦、全自动化的“高速公路”。一个开发者,在本地完成代码提交并推送到Git仓库后,一杯咖啡的时间,他的代码就已经通过了自动化测试、安全扫描、镜像构建,并以一种可控的、灰度的方式,安全地发布到了生产环境。
毫无疑问,团队B的创新速度,将是团队A的数十倍甚至上百倍。 他们可以每天进行数十次小规模、低风险的发布,快速地验证商业想法,快速地修复线上问题,快速地响应市场变化。而团队A,则被其落后的交付能力,牢牢地锁死在了“低速迭代、高风险发布”的恶性循环中。
在现代软件工程中,软件交付能力,已经不再是一个“工程效率”问题,它是一个核心的“商业竞争力”问题。 而构建这条“高速公路”的指导思想,就是DevOps。
DevOps,并非指某个工具或某个职位,它是一种文化哲学、实践和工具的集合。其核心目标是,打破开发(Dev)和运维(Ops)之间传统的“部门墙”,通过自动化和协作,来缩短从“代码提交”到“价值交付”的周期,同时保证系统的可靠性。
然而,在云原生时代,这条高速公路,延伸到了一个全新的、充满诱惑也充满陷阱的领域——无限的、按需付费的云资源。我们享受着弹性的同时,也面临着成本失控的巨大风险。一个未经优化的容器配置,一个被遗忘的测试集群,都可能在账单上,给我们带来一个“惊吓”。于是,DevOps的版图上,必须增加一块新的大陆——FinOps,即云财务管理。
本篇,就是你构建这条“DevOps + FinOps”双轨驱动的、现代化软件交付高速公路的完整蓝图。我们将从CI/CD流水线的设计哲学开始,深入云原生交付的终极范式GitOps。我们将站在Kubernetes的肩膀上,实现精妙绝伦的发布策略。最后,我们将戴上“CFO的眼镜”,学习如何度量、优化和治理我们的云成本,让技术创新,不再是一场“盲目的狂欢”,而是一场“精打细算的胜利”。
第一章:CI/CD流水线——软件工厂的“自动化装配线”
如果说DevOps是文化,那么**CI/CD(持续集成/持续交付/持续部署)**流水线,就是将这种文化,物化为现实的“自动化装配线”。
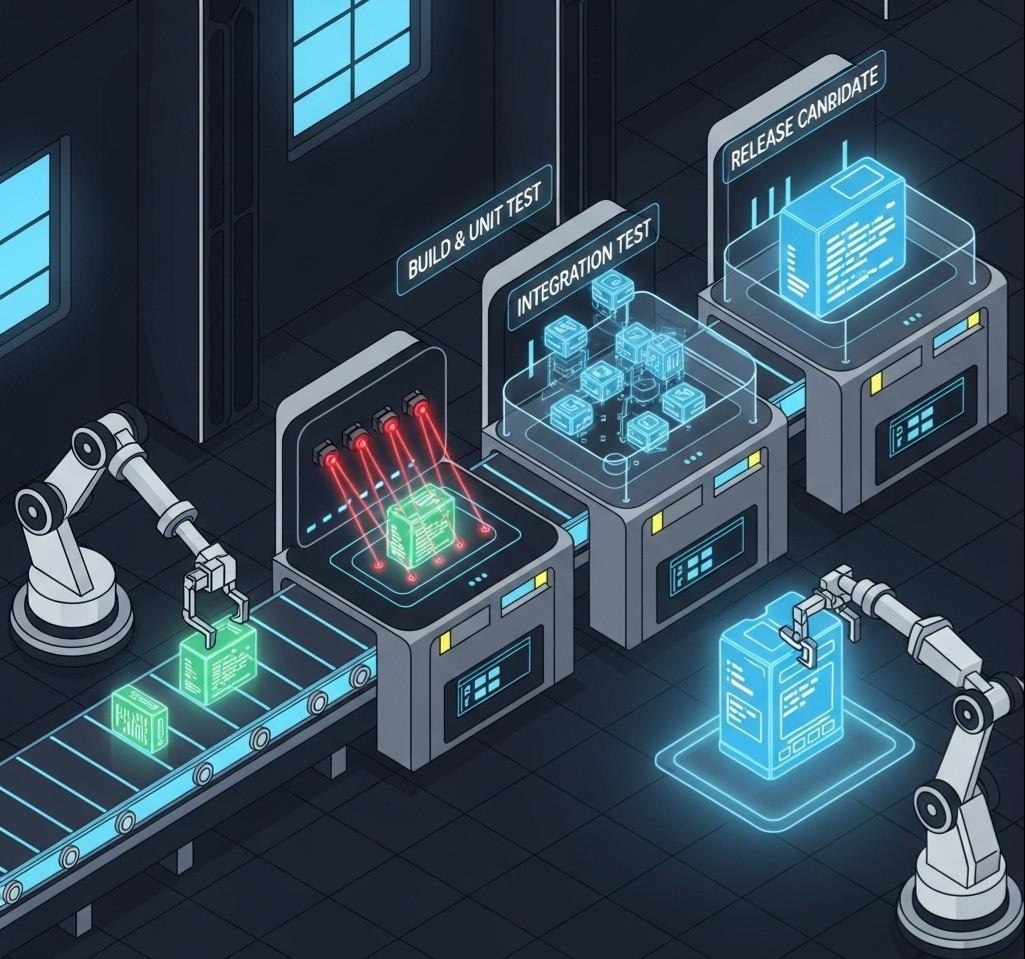
- 持续集成(Continuous Integration, CI):
- 核心:频繁地(每天多次)将所有开发者的代码,合并到主干分支。
- 目标:尽早地发现和解决代码集成冲突,通过自动化构建和单元测试,来保证主干分支的“随时可发布”状态。
- 反模式:长期存在、与主干差异巨大的“特性分支(Feature Branch)”。这种分支,在最后合并时,往往会引发“合并地狱(Merge Hell)”。
- 持续交付(Continuous Delivery, CD):
- 核心:CI的自然延伸。将通过了所有自动化测试的代码,自动地部署到一个“预生产环境”(如Staging环境)。
- 目标:确保我们随时拥有一个可以一键部署到生产环境的、经过完整验证的发布候选版本。部署到生产环境的最后一步,通常是手动的。
- 持续部署(Continuous Deployment, CD):
- 核心:CD的终极形态。将通过了所有测试的代码,自动地、无需人工干预地,直接部署到生产环境。
- 目标:实现“从代码提交到价值交付”的全流程自动化。这需要极高的自动化测试覆盖率和强大的发布策略支持。
1.1 流水线的设计哲学:分层、并行与快速失败
一个现代化的CI/CD流水线,应该像一个设计精良的“测试金字塔”。
流水线阶段(Stages):
- 提交阶段(Commit Stage) - 速度最快,频率最高
- 触发:每次代码push。
- 任务:
- 编译、打包。
- 单元测试(Unit Tests)。
- 静态代码分析(SonarQube, Linting)。
- 目标:在5-10分钟内,为开发者提供一个关于其代码“基本正确性”的快速反馈。如果此阶段失败,流水线应立即中止。
- 验收阶段(Acceptance Stage) - 更全面,但更耗时
- 触发:提交阶段成功后,自动触发。
- 任务:
- 构建Docker镜像。
- 将镜像部署到一个临时的、隔离的测试环境中。
- 运行集成测试(Integration Tests)和契约测试(Contract Tests)。
- 目标:验证服务与它的直接依赖(数据库、其他服务)之间的交互是否正确。
- 容量/性能测试阶段(Capacity Stage)
- 触发:通常是定时触发(如每晚),或者在发布到预发环境后触发。
- 任务:运行自动化性能测试、负载测试。
- 目标:确保新的代码变更,没有引入性能回退。
- UAT/预发阶段(UAT/Staging Stage)
- 部署:将应用部署到一个长期的、与生产环境高度一致的预发环境中。
- 任务:可以进行手动的功能探索性测试,或者向业务方进行演示。
- 生产发布阶段(Production Stage)
- 触发:手动触发(持续交付)或自动触发(持续部署)。
- 任务:执行蓝绿、金丝雀等高级发布策略。
深刻洞察:
这条流水线,是一个成本和信心的权衡过程。越往左(提交阶段),测试运行成本越低,速度越快,但提供的信心也越局部。越往右(生产发布),提供的信心越全面,但成本和风险也越高。**“快速失败”**的原则,要求我们在成本最低的阶段,尽可能多地发现问题。
1.2 GitOps:云原生时代的“声明式”交付

传统的CI/CD流水线,通常是“命令式(Imperative)”的。我们在Jenkins或GitLab CI的脚本里,写下了一系列的命令:docker build, docker push, kubectl apply…。这种模式的问题是:
- 配置与代码分离:应用代码在Git里,而部署脚本在另一个系统里。
- 状态漂移(State Drift):有人可能会绕过流水线,直接用kubectl命令,手动地去修改生产环境的配置。这导致我们的“期望状态”(Git里的脚本)与“实际状态”(集群里的运行状态)发生了不一致,形成了一个不可信的“黑盒”。
GitOps,由Weaveworks公司提出,是一种革命性的、**声明式(Declarative)**的交付范式。
核心思想:将你的整个系统的“期望状态”,包括应用代码、基础设施配置(Terraform)、Kubernetes部署清单(YAML)、监控告警规则等,全部以“声明式”的方式,存储在Git仓库中。Git,是唯一的“真理之源(Single Source of Truth)”。
- 工作流程:
- 开发者:不再直接与Kubernetes交互。他们只做一件事:向Git仓库,提交一个Pull Request,来声明他们期望的状态变更(比如,将镜像版本从v1改为v2)。
- 代码评审(Code Review):这个PR,会像普通代码一样,被同事评审、自动化检查。
- 合并(Merge):一旦PR被合并到主干分支,它就触发了GitOps的核心。
- 自动化代理(GitOps Agent):有一个部署在Kubernetes集群内部的代理(如ArgoCD, Flux),它在持续地监控Git仓库的变化。
- 自动同步:当代理检测到Git仓库的“期望状态”与集群的“实际状态”不一致时,它会自动地采取行动(比如,执行kubectl apply),将集群的实际状态,**拉(Pull)**向期望状态。
GitOps的巨大优势:
- 声明式与幂等性:你只关心“是什么”,而不是“怎么做”。
- 版本控制与审计:对系统的每一次变更,都有完整的Git提交历史、评审记录和责任人。
- 安全性:开发者不再需要生产环境的直接访问权限。
- 快速的故障恢复:如果一次发布导致了故障,恢复操作,就是简单地在Git上,执行一次git revert,将系统状态“回滚”到上一个健康的提交。
第二章:Kubernetes下的高级发布策略——流量的“精细外科手术”
Kubernetes,以其强大的编排能力和可扩展的API,成为了实现精细化发布策略的完美温床。结合Service Mesh(如Istio),我们可以将发布过程,从一场“粗暴的革命”,变成一场“优雅的、数据驱动的、外科手术式的”演进。
2.1 蓝绿发布(Blue-Green Deployment)

- Kubernetes实现:
- 部署“绿色”版本:在“蓝色”版本(旧版)稳定运行的同时,在同一个集群里,部署一套完整的“绿色”版本(新版)的Deployment和Pod。此时,外部流量依然全部指向蓝色版本。
- 内部验证:可以通过port-forward或内部域名,对绿色版本进行充分的测试。
- 流量切换:当绿色版本验证通过后,最关键的一步,是修改Kubernetes Service的selector,将其从指向app: myapp, version: blue,瞬间切换到指向app: myapp, version: green。
- 完成:Kubernetes的Service机制,会保证这个切换过程是原子的、无缝的。所有新的流量,都会被导向绿色版本。
- 回滚:如果绿色版本出现问题,回滚操作,就是再次修改Service的selector,将其指回蓝色版本,同样是秒级完成。
2.2 金丝雀发布/灰度发布(Canary Release)
蓝绿发布是“全有或全无”的。而金丝雀发布,则允许我们“一小步、一小步”地,将流量引入新版本,这是一种风险更低的模式。
- 基于Pod数量的“粗粒度”灰度:
- 实现:我们可以部署一个version: v1的Deployment(比如,9个副本)和一个version: v2的Deployment(1个副本)。然后,让一个Service同时selec-t这两个版本的Pod。Kubernetes的kube-proxy会近似地,将10%的流量,负载均衡到v2版本上。
- 缺点:不够精准,且无法基于请求内容进行控制。
- 基于Service Mesh的“细粒度”灰度(终极形态):
- 正如我们在上一篇所学,通过Istio的VirtualService,我们可以实现任意维度的、极其精细的流量切分。
- 渐进式交付(Progressive Delivery):
- 阶段一(1%流量):先将1%的流量,切分到v2版本。同时,启动一个自动化分析的流程,持续地比较v1和v2版本的关键业务指标(KPI)和技术指标(SLI/SLO)——比如,v2的转化率是否下降了?错误率是否上升了?延迟是否增加了?
- 自动化决策:如果所有指标都在可接受的范围内,自动化地将流量比例,增加到10%。
- 持续验证:继续监控。
- 全量与清理:如果一切顺利,最终将100%的流量切到v2,并自动清理掉v1的部署。
- 自动回滚:如果在任何一个阶段,监控到v2版本的指标出现异常,立即自动地将流量全部切回v1,并发出告警。
- 开源工具:Flagger, Argo Rollouts等开源项目,将这套“渐进式交付”的流程,进行了完美的自动化封装。
2.3 流量镜像/影子流量(Traffic Mirroring/Shadowing)
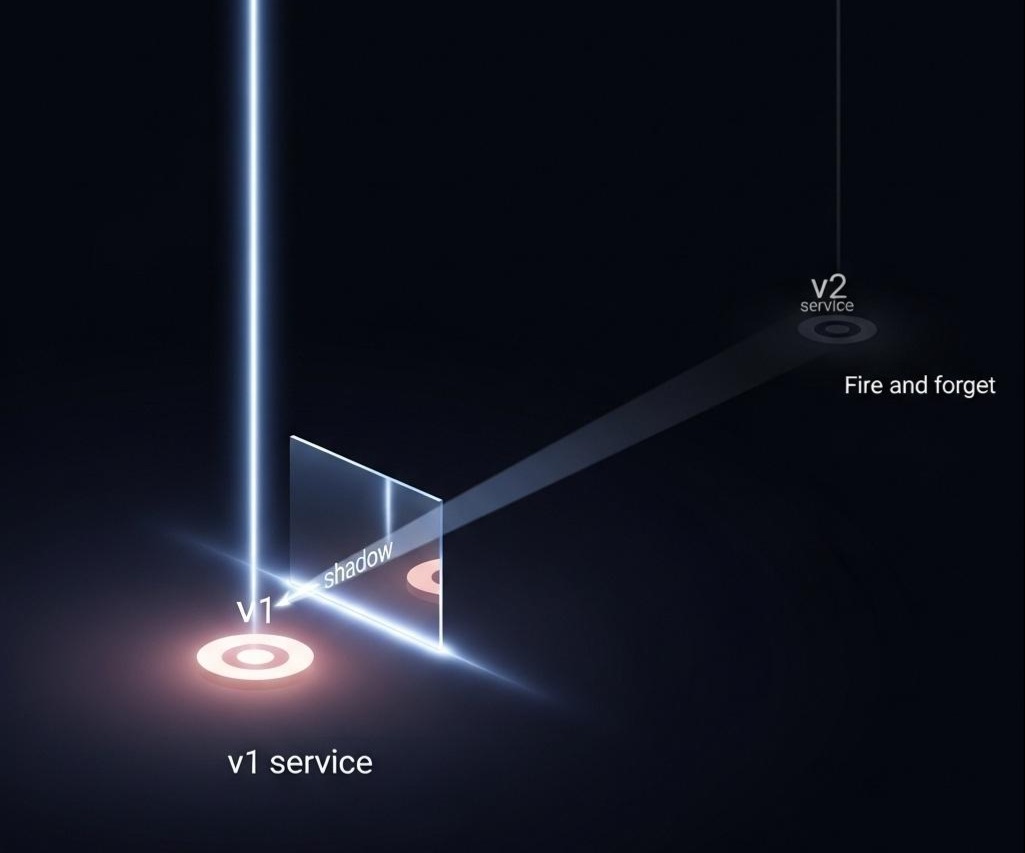
- 场景:当我们要上线一个重构后的、风险极高的服务时(比如,一个新的推荐算法引擎),我们希望用真实的生产流量来测试它,但又不希望它的任何错误,会影响到真实用户。
- Istio实现:
1 | - route: |
- 这条规则的含义是:将100%的主流量,发送给v1(稳定版)。同时,将这些流量复制一份(镜像),异步地、“Fire and Forget”地发送给v2(新版)。
- v2版本的任何响应或错误,都不会被返回给用户。但我们可以通过监控v2的日志和Metrics,来观察它在真实流量下的表现。
第三章:FinOps的黎明——为“无限”的云,装上“经济”的刹车
在DevOps和云原生的浪潮下,我们为开发者赋予了前所未有的“权力”。一个工程师,通过几行Terraform代码,或者一次Helm Chart的部署,就可以在几分钟内,创建出一个横跨全球、拥有数百个节点的Kubernetes集群。我们享受着这种“无限资源、按需获取”带来的极致弹性与速度。
然而,权力越大,责任越大。当权力没有被有效地约束和度量时,它就会演变成“浪费”。
- 一个开发者为了临时测试,启动了一个拥有10个GPU节点的大型集群,但测试结束后,忘记了关闭。
- 一个微服务的内存请求(Request)被设置为8GB,但实际平均使用率只有500MB。
- 日志系统因为错误的配置,正在以每天10TB的速度,吞噬着昂贵的对象存储。
这些“微小的”浪费,在成百上千个微服务、数十个团队的规模下,会迅速累积成一笔惊人的、足以让CFO心惊肉跳的“云税(Cloud Tax)”。
传统的财务预算和审批流程,对于云这种“动态、分布式、按秒计费”的消费模式,是完全无力的。我们需要一种新的、能够将技术、财务、业务三者结合起来的文化、实践和工具。这就是FinOps。
FinOps,是**“Finance”和**“DevOps”的结合。它的核心目标是:在云环境中,实现成本的“最大商业价值”。 它不是单纯地“省钱”,而是要建立一套数据驱动的、持续优化的成本治理体系,让花的每一分钱,都能与它所创造的商业价值,清晰地对应起来。
灵魂拷问:DevOps追求的是“速度”,FinOps追求的是“成本”,它们之间是矛盾的吗?
答案:不是。它们是同一枚硬币的两面。
一个没有成本意识的DevOps,会演变成一场“失控的狂欢”,最终因为财务不可持续而崩溃。一个没有DevOps自动化能力的FinOps,则会退化成“手动的、审批式的”传统财务管理,扼杀创新速度。
真正的云原生组织,必须是“DevFinOps”驱动的。速度和成本,是两个需要被同时优化的核心指标。
3.1 FinOps的生命周期:看见 -> 理解 -> 优化
FinOps的实践,遵循一个持续的、循环的生命周期。
阶段一:看见(Inform)——让成本“透明化”

你无法优化你看不到的东西。FinOps的第一步,是建立一个统一的、精细化的、可追溯的成本可视化体系。
- 挑战:云厂商(AWS, Azure, GCP)的账单,通常是极其复杂的。我们看到的是一堆EC2、S3、EKS的总费用,但我们无法回答一个最关键的问题:“‘订单服务’,在上个月,到底花了多少钱?”
- 解决方案:
- 统一的标签策略(Tagging Strategy):
- 这是FinOps的基石。必须制定一个强制性的、覆盖所有云资源的标签策略。
- 标准标签:owner_team(哪个团队拥有)、product(属于哪个产品线)、service_name(是哪个微服务)、environment(prod/staging/dev)。
- 自动化治理:通过策略即代码(Policy-as-Code)工具(如OPA, Kyverno),来强制所有新创建的资源,都必须带有这些标准标签,否则创建就会失败。
2.** 成本分配与分摊(Cost Allocation & Showback/Chargeback)**:
- 利用这些标签,将云账单进行分组和聚合。
- 对于一些共享资源(如共享的Kubernetes集群、数据库、网络流量),需要建立一个合理的成本分摊模型(比如,按CPU/内存的使用量比例进行分摊)。
- 构建成本仪表盘:将分摊后的成本数据,推送到一个可视化的仪表盘(如Grafana, Cloudability, Apptio Cloudability)中,让每一个团队的负责人,都能清晰地看到自己团队、自己服务的实时成本消耗。
- 深刻洞察:“Showback”(展示成本)是第一步,它能带来“成本意识”。更进一步的“Chargeback”(成本结算),是将成本,真正地计入到每个业务单元的预算中,从而驱动他们主动地去优化。
阶段二:理解(Analyze & Recommend)——从“花钱”到“投资”

当成本可见后,我们需要回答更深层次的问题:“我们花的钱,值吗?”
- 建立“单位经济模型(Unit Economics)”:
- 这是衡量云成本“商业价值”的核心。我们需要将云成本,与关键的业务指标关联起来。
- 示例:
- Cost Per User(每个活跃用户,分摊了多少云成本?)
- Cost Per Transaction(每完成一笔订单,背后的云成本是多少?)
- Cost Per API Call(每次API调用,成本是多少?)
- 通过追踪这些“单位成本”指标,我们可以:
- 评估新功能的ROI:一个新上线的功能,带来了10%的用户增长,但导致Cost Per User上涨了50%,这笔“投资”是否划算?
- 发现架构的“腐烂”:如果业务量没有增长,但Cost Per Transaction却在持续攀升,这通常意味着系统出现了性能回退或资源浪费。
- 自动化的优化建议:
- 平台团队,需要构建或引入工具,来自动地扫描整个云环境,并提供优化建议。
- 示例:
- “这个EC2实例类型,在过去30天,CPU平均使用率低于5%,建议降级为更小的实例。”
- “这个EBS卷,已经处于‘未挂载’状态超过14天,可能是被遗忘的资源。”
- “建议为你的团队购买一批AWS的‘预留实例(Reserved Instances)’或‘节省计划(Savings Plans)’,可以节省约40%的计算成本。”
阶段三:优化(Operate & Optimize)——将“节省”融入“日常”
这是将FinOps的价值,真正落地的最后一步。
- 资源权利调整(Rightsizing):
- 基于监控数据(如Prometheus的container_cpu_usage_seconds_total和container_memory_working_set_bytes),持续地、自动化地,去调整容器的Requests和Limits。
- Kubernetes工具:**VPA (Vertical Pod Autoscaler)**可以自动地为Pod推荐甚至设置最佳的资源请求。Goldilocks可以可视化地展示当前工作负载的资源“浪费”情况。
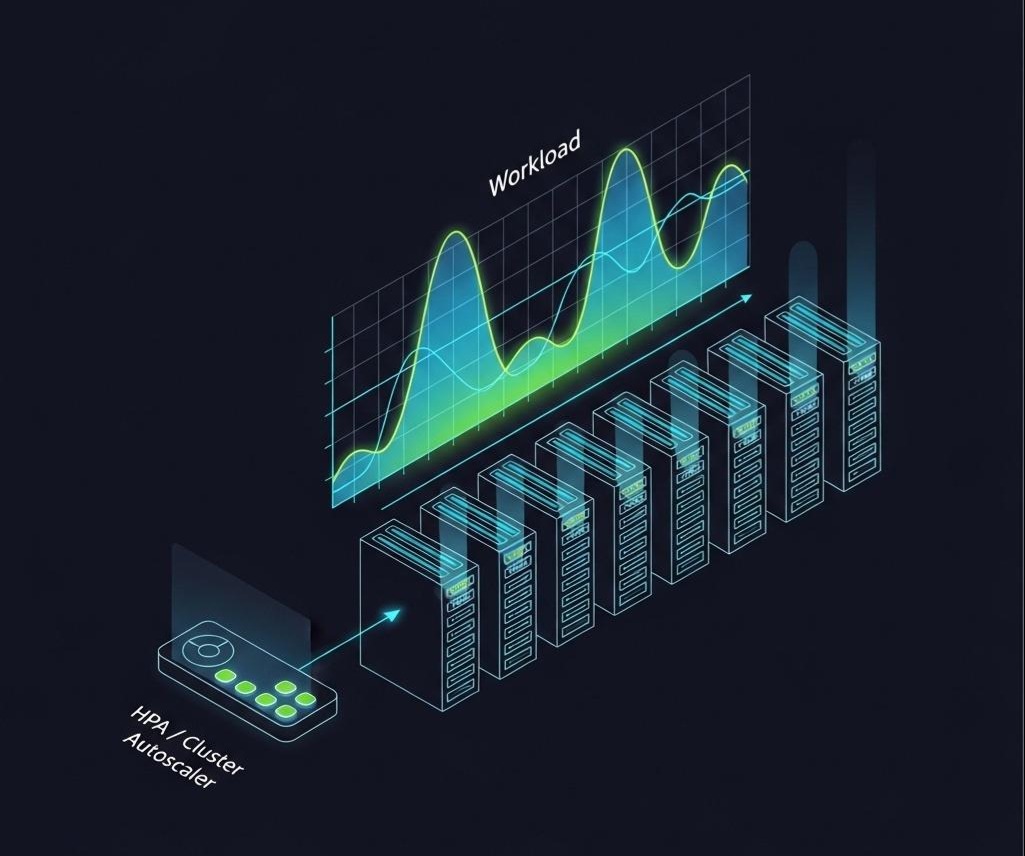
- 自动启停与弹性伸缩:
- 非生产环境:为所有的开发、测试环境,设置自动的启停策略(比如,工作日晚上7点自动关闭,早上9点自动启动)。
- 生产环境:充分利用HPA (Horizontal Pod Autoscaler)和Cluster Autoscaler,让应用和集群的规模,能够根据真实的负载,进行分钟级的、自动的弹性伸缩。不要为峰值付费,要为平均值付费。
- Spot实例的使用:
- 充分利用云厂商的Spot实例/抢占式实例,来运行那些无状态的、可容忍中断的工作负载(如批处理、CI/CD的Builder)。Spot实例的价格,通常只有按需实例的10%-30%。
3.2 将FinOps融入DevOps文化
FinOps的成功,最终不取决于工具,而取决于文化。
- 建立FinOps跨职能团队:组建一个由**技术(架构师/SRE)、财务(财务分析师)、产品(产品经理)**共同组成的虚拟团队,定期复盘云成本和业务价值。
- 将“成本”作为质量门禁:在CI/CD流水线中,集成成本估算工具(如Infracost),在基础设施代码(Terraform)提交PR时,就能自动地计算出这次变更,会带来多少成本的增加或减少。
- 激励与赋能:让工程师,像花自己的钱一样,去花公司的云资源。 将成本节约,作为团队和个人的绩效指标之一。为他们提供易于使用的工具和清晰的数据,让他们能够轻松地看到自己每一次优化的成果。
结语:从“交付速度”到“价值效率”的飞跃
我们完成了这次穿越软件交付“高速公路”的深度旅程。从CI/CD的自动化装配线,到GitOps的声明式宇宙,再到Kubernetes下的精妙发布舞蹈,我们构建了一套追求极致交付速度和质量的工程体系。
然而,FinOps的出现,为这条高速公路,增加了一个至关重要的、全新的“仪表盘”——经济效益。它迫使我们架构师,从一个纯粹的“技术成本中心”,向一个需要对“商业价值负责”的“价值创造中心”转变。
- DevOps,解决了“How fast can we go?”(我们能跑多快)的问题。
- FinOps,解决了“Are we driving in the right direction, efficiently?”(我们的方向对吗?开得有效率吗?)的问题。
一个只关心速度,不关心成本的组织,可能会像一辆耗尽了燃料的F1赛车,虽然曾经风光无限,但无法跑完全程。一个只关心成本,不关心速度的组织,则可能会在日新月异的市场竞争中,被远远地甩在身后。
DevFinOps,就是那套能让我们在这条赛道上,既能跑出“推背感”,又能保持“最佳燃油效率”的驾驶哲学。
作为架构师,你的职责,已经从单纯地“构建系统”,扩展到了“构建一个可持续的、高效的、经济的价值交付体系”。你需要左手拿着“技术罗盘”,右手拿着“财务报表”,带领你的团队,在这条机遇与挑战并存的云原生高速公路上,行稳致远。
至此,本系列的十三篇深度长文,已经为你构建了一幅从技术内核到组织哲学,从系统设计到价值交付的完整架构师世界观。这条路没有终点,技术的浪潮永不停歇,而架构师的价值,正是在这不息的浪潮中,掌舵、领航,并最终抵达商业价值的彼岸。

