百万架构师成长之路(17):【终极实战篇·三】壁垒之战:从Nginx到Sentinel,挥舞流量的“手术刀”
导语:从“广域拦截”到“精准点杀”,欢迎来到最后的阵地
在前两章中,我们作为总指挥官,绘制了宏伟的作战蓝图;作为特种兵,在客户端和CDN的“无人区”进行了残酷的“前哨战”。经过层层筛选,99.9%的无效和恶意流量已被我们阻挡在国门之外。
现在,真正的考验开始了。
那些突破了重重防线的、最高质量的请求,已经集结在我们的最后壁垒——API网关与核心服务——的城门之下。它们数量依然庞大,意图高度集中,任何一个微小的疏忽,都可能导致防线在瞬间被撕裂。
如果说前哨战是“广域轰炸”,那么接下来的壁垒之战,就是一场要求极致精准的“巷战”和“狙击战”。我们不能再用粗暴的方式丢弃流量,因为每一个来到这里的请求,都可能是我们的真实用户。我们的任务,从“拦截”转变为“整形(Shaping)”和“调度(Scheduling)”。我们需要像一个经验丰富的外科医生,手持两把锋利的手术刀,对奔涌而来的流量动脉,进行精准的切削、引流和缝合。
这两把手术刀,就是每一位Java后端架构师都必须精通的“国之重器”:
Nginx/OpenResty: 高性能的流量“铁壁”,我们防线的最后一道物理屏障。
Sentinel: 深入业务肌理的“神经元”,为我们的微服务注入动态感知和自我保护的灵魂。
本篇,我们将深入这两大利器的内部,从工作原理、核心算法,到Java生态下的详细配置与实战代码,彻底掌握如何利用它们,为我们的秒杀系统构建一个既坚固又富有弹性的“反脆弱”壁垒。
本章作战地图 (Table of Contents)
- 第一道壁垒:Nginx/OpenResty——国门的铁闸
- 1.1 再谈Nginx:为何是它?
- 核心:Nginx的事件驱动模型(epoll) vs. 传统多线程模型的性能优势。
- 目标:理解Nginx为何能以极低的资源消耗,应对海量连接。
- 1.2 战术一:基础访问控制与连接限制
- 技术点:limit_conn_zone, limit_req_zone 指令详解。
- 实战配置:如何配置基于IP的连接数和请求速率限制,抵御低级DDoS攻击。
- 1.3 战术二:Lua脚本的威力——在Nginx中植入“智能”
- 核心:OpenResty介绍,以及为何选择它进行动态流量控制。
- Java后端视角: 如何设计一个由Nginx+Lua调用的、基于Redis的动态IP黑名单服务。
- Lua实战代码: 展示一段完整的Lua脚本,实现对后端黑名单服务的调用与请求拦截。
- 1.4 战术三:请求合并与缓存(Request Coalescing & Caching)
- 技术点:proxy_cache 指令族深度剖析,缓存Key的定制,缓存状态的监控。
- 场景:针对非核心、但读请求量大的API(如“获取商品剩余数量”)进行短时缓存。
- 第二道壁垒:Sentinel——深入微服务肌理的“哨兵”
- 2.1 为何需要Sentinel?Nginx限流的局限性
- 核心:Nginx vs. 应用层限流的本质区别。Nginx不感知业务,无法做到精细化、动态化、集群化的流量控制。
- 2.2 Sentinel核心概念与数据结构
- 技术点:资源(Resource)、滑动时间窗口(Sliding Window)、StatisticSlot与Node。
- 源码浅析: 剖析Sentinel如何通过LeapArray(一种环形数组的实现)高效地在内存中统计秒级QPS。
- 2.3 流量控制三大战术(Java实战)
- 战术一:QPS/线程数限流(流量整形)
- Java实战:使用**@SentinelResource注解,配置FlowRule**,演示直接拒绝、Warm Up、匀速排队三种效果。
- 深度探讨: Warm Up(预热)模式的意义与实现原理——基于令牌桶算法的变种。
- 战术二:熔断降级(服务保护)
- Java实战:配置DegradeRule,演示基于“慢调用比例”、“异常比例”、“异常数”三种策略的自动熔断。
- 坑点分析: 熔断的“半开(Half-Open)”状态是如何工作的?如何避免“熔断风暴”?
- 战术三:热点参数限流(精准点杀)——秒杀场景的核武器
- Java实战:针对“商品ID”这个热点参数配置ParamFlowRule。
- 场景模拟: 演示如何做到“商品A的流量被限流,但商品B的访问完全不受影响”。
- 2.4 集群限流与持久化
- 技术点:单机限流的瓶颈,Sentinel集群流控的两种模式(Token Server vs. Token Client)。
- 架构选型: 为何秒杀场景更适合选择Token Server模式?
- Java生态整合: 如何整合Nacos或Apollo作为规则持久化中心,实现规则的动态推送与全局管理。
第一道壁垒:Nginx/OpenResty——国门的铁闸
Nginx,这位Web服务器领域的王者,在我们的架构中扮演着“城墙”与“护城河”的角色。它利用极低的资源,吸收第一波冲击,并对流量进行粗粒度的筛选和整形。
1.1 再谈Nginx:为何是它?
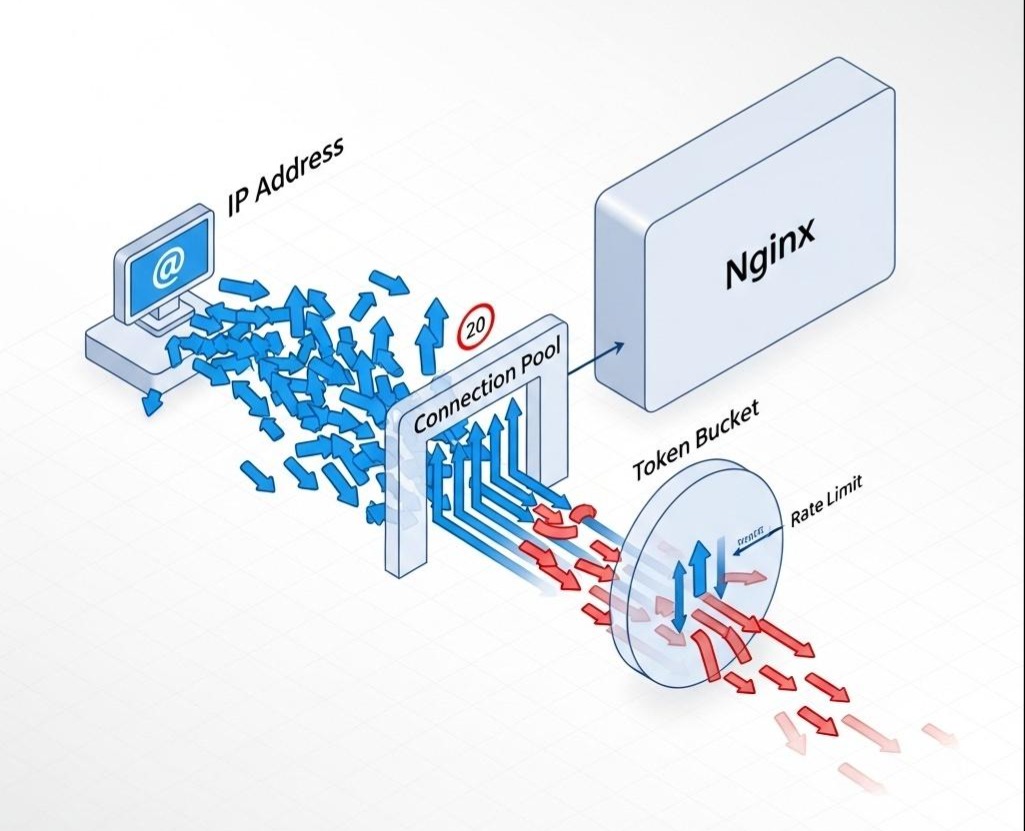
在我们深入配置之前,必须再次强调Nginx强大的根本原因:异步非阻塞的事件驱动模型。
- 传统模型(如老版Apache): 每个连接分配一个进程或线程。如果有10000个连接,就需要10000个线程。线程的创建、销毁和上下文切换会带来巨大的操作系统开销。当连接数暴增时,系统资源迅速耗尽。
- Nginx模型: 启动少数几个(通常与CPU核心数相同)工作进程(Worker Process)。每个Worker进程内,通过一个**事件循环(Event Loop)来处理成千上万个连接。当一个请求的I/O操作(如读写Socket)未就绪时,Nginx不会傻等,而是将这个事件注册到操作系统内核的事件通知机制(如Linux上的epoll)**中,然后立即去处理其他已就绪的事件。当之前的I/O操作完成后,内核会通知Nginx,Nginx再回过头来继续处理它。
这个模型的本质,是将等待I/O的时间,充分利用起来去处理其他工作。因此,Nginx可以用极少的线程,实现极高的并发连接处理能力。这正是它成为我们“国门卫士”的不二之选的原因。
1.2 战术一:基础访问控制与连接限制
最简单、最有效的防御,往往是那些基础的物理限制。当“黄牛”用成百上千个IP地址,每个IP又发起成百上千个连接来冲击你的服务器时,Nginx的limit_conn和limit_req模块就是你的第一道防线。
nginx.conf 实战配置:
1 | http { |
解读:
- limit_conn_zone: 定义了一个“蓄水池”,用来统计每个IP地址当前占用了多少个连接。$binary_remote_addr是比**$remote_addr**更节省内存的IP变量。
- limit_req_zone: 定义了一个“令牌桶”。rate=10r/s意味着系统每秒会向桶里投放10个令牌。每个请求需要消耗一个令牌才能通过。burst=5是桶的容量,最多可以积攒5个令牌,以应对瞬时的小规模突发流量。
- nodelay: 这个参数在秒杀场景下至关重要。如果不加nodelay,超出速率的请求会被Nginx放入一个队列中,延迟处理,这会增加用户的等待时间。加上nodelay,意味着只要桶里有令牌,请求就立即通过;如果桶里没令牌,就直接拒绝(返回503),干脆利落。
通过这几行简单的配置,我们就构建了一个基础的防火墙,能有效抵御来自同一IP的、无脑式的流量洪水。
1.3 战术二:Lua脚本的威力——在Nginx中植入“智能”
Nginx的原生指令是静态的。但如果我们想实现更复杂的、动态的逻辑(比如,查询一个由Java后端实时更新的黑名单),就需要给Nginx装上一个“大脑”——OpenResty。
OpenResty是一个基于Nginx并集成了大量Lua库的高性能Web平台。它允许我们用轻量级的Lua脚本,在Nginx处理请求的各个阶段(如access_by_lua、content_by_lua)注入自定义逻辑。
作战场景:
我们的风控系统通过分析用户行为,发现了一批高危IP地址,并将它们写入了后端的Redis Set中(seckill:blacklist:ip)。我们希望Nginx在收到请求时,能实时查询这个Redis Set,如果命中,则直接拒绝请求。
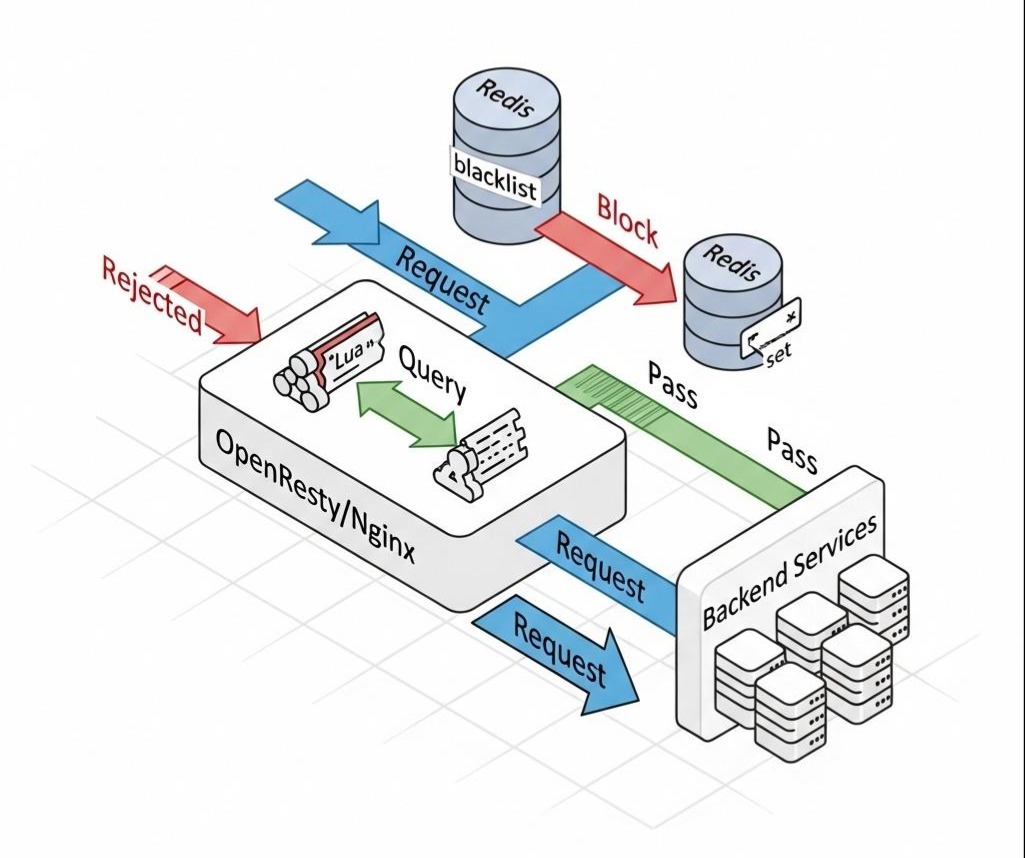
1. Java后端提供数据支持 (Spring Boot)
1 |
|
注意: 为了让Nginx能够访问这个服务,你需要为它配置一个内部的location或upstream。
2. OpenResty + Lua实战代码
首先,确保你的Nginx是OpenResty版本。然后修改nginx.conf:
1 | http { |
深度分析:
通过这段Lua代码,我们赋予了Nginx动态查询Redis的能力。每次请求到达时,它都会像一个忠诚的哨兵,先去Redis“核对名单”,然后再决定是否放行。这个过程发生在Nginx的内存中,速度极快,远比将请求转发到Java网关再做判断要高效得多。我们成功地将一道动态的风控逻辑,前置到了架构的最边缘。
1.4 战术三:请求合并与缓存(Request Coalescing & Caching)
对于某些读请求,比如“查询商品剩余库存”(可以不是100%精确),在秒杀前几秒,可能会有大量用户同时请求。这些请求的内容完全一样,如果全部打到后端,是一种巨大的浪费。
Nginx的proxy_cache和proxy_cache_lock可以完美解决这个问题。
nginx.conf 实战配置:
1 | http { |
这个配置的威力在于proxy_cache_lock on。它能有效防止“缓存击穿”(Cache Penetration)的一种形式:当一个热点缓存失效的瞬间,大量请求同时穿透到后端。有了它,Nginx会扮演一个“锁管理者”的角色,确保同一时间只有一个请求去“重建”缓存,其他请求则优雅地等待。
第二道壁垒:Sentinel——深入微服务肌理的“哨兵”
如果说Nginx是宏观的、物理层面的“城墙”,那么Sentinel就是微观的、深入我们Java代码的、具备业务感知能力的“特种部队”。它为我们的服务提供了动态的、自适应的保护能力。
2.1 为何需要Sentinel?Nginx限流的局限性
“我们已经在Nginx层做了限流,为什么还需要在Java应用层再做一次?” 这个问题,直击应用层流量治理的核心。
答案是:Nginx不理解你的业务,而Sentinel理解。
- 维度的局限: Nginx的限流大多基于IP、URI等网络层或传输层信息。它无法做到更细粒度的业务维度限流,例如:“限制某个用户对某个特定商品的访问频率”,或者“当系统整体的慢调用比例超过阈值时,自动熔断”。
- 集群的局限: Nginx的limit_req是单机维度的。如果你有10台Nginx服务器,你设置rate=100r/s,那么你的总限流阈值就是1000r/s。你无法轻松地做到“整个集群总共限制500r/s”。
- 动态性的局限: Nginx的配置是静态的。修改限流规则需要reload配置,这在快速变化的线上环境中是不够灵活的。我们希望限流规则能像配置中心的配置一样,动态推送,实时生效。
Sentinel,作为阿里巴巴开源的、面向分布式服务架构的流量控制组件,完美地解决了以上所有问题。
2.2 Sentinel核心概念与数据结构
要精通Sentinel,必须理解它的两个核心基石:资源(Resource)和滑动时间窗口(Sliding Window)。

- 资源(Resource): 在Sentinel中,万物皆可为资源。可以是一个方法、一个URL、甚至是一段代码。我们通过**@SentinelResource**注解或API埋点,来定义一个需要被保护的资源。
- 滑动时间窗口(Sliding Window): 这是Sentinel进行实时流量统计的精髓。为了统计每一秒的QPS,Sentinel并不是简单地每秒清零计数器。它采用了一种更平滑、更精确的数据结构——LeapArray。
源码浅析 (LeapArray):
LeapArray本质上是一个环形数组。假设我们要统计1秒内的QPS,窗口大小为1000ms。Sentinel会将这1秒划分为多个更小的时间片(Sample),比如2个,每个500ms。LeapArray的底层数组大小就是2。
- 当前时间在 0ms-499ms之间: 所有的请求计数(成功、失败、异常等)都会累加到数组的第0个格子(WindowWrap对象)里。
- 当前时间在 500ms-999ms之间: Sentinel会通过取模运算,定位到数组的第1个格子里,并将计数累加到这里。
- 当前时间到达 1000ms-1499ms之间: 时间窗口向前滑动。Sentinel会再次定位到数组的第0个格子。但它发现这个格子里的数据是“旧的”(属于上一个时间窗口),于是它会**重置(reset)**这个格子,然后将新的计数累加进去。
这个设计的巧妙之处在于:
- 平滑统计: 任何时刻,要获取当前窗口的总QPS,只需将环形数组中所有格子的计数相加即可。这避免了在窗口边界的计数突变。
- 内存复用: 环形数组的大小是固定的,它通过不断地复写旧的时间片数据,避免了无限的内存增长,实现了高效的内存使用。
2.3 流量控制三大战术(Java实战)
现在,让我们拿起Sentinel这把手术刀,为我们的Seckill-Core Service进行精细化的流量手术。
首先,在pom.xml中引入Sentinel依赖:
1 | <dependency> |
战术一:QPS/线程数限流(流量整形)
这是最基础的流量控制,用于确保我们的核心下单方法不会被超过其处理能力的请求所压垮。
Java代码 (SeckillOrderService.java):
1 |
|
解读:
- @SentinelResource(“createSeckillOrder”): 定义了一个名为createSeckillOrder的资源。
- blockHandler: 指定了一个“兜底”方法。当该资源的访问因为Sentinel的规则被阻止时,Sentinel会调用这个方法。注意,方法的签名必须与原方法保持一致,并在最后增加一个BlockException参数。
- fallback: 指定了另一个“兜底”方法。当原方法中发生了业务异常(非BlockException)时,Sentinel会调用它。
配置FlowRule(通过代码或配置中心):
我们可以通过编写一个配置类,在应用启动时加载规则。
1 |
|
深度探讨:Warm Up(预热)模式
CONTROL_BEHAVIOR_WARM_UP特别适用于秒杀这种流量从0瞬时增至峰值的场景。它的原理是,系统刚启动或在低水位运行时,它的各种缓存(JVM JIT编译、DB连接池、各种本地缓存)都处于“冷”状态。如果瞬间涌入大量流量,系统很容易崩溃。
Warm Up模式下的令牌桶算法变种会这样做:
- 设置一个预热时长(如1分钟)和一个阈值(如1000 QPS)。
- 在预热期内,发放令牌的速率会从一个较低的值(如 阈值 / 3)慢慢地、线性地增加,直到达到设定的阈值。
- 这样,流量会平缓地“爬坡”,给足系统“热身”的时间,从而避免在启动瞬间就被冲垮。
战术二:熔断降级(服务保护)
限流是保护自己,而熔断是保护“猪队友”。如果我们的下单服务依赖于另一个“用户服务”来查询用户信息,而这个用户服务因为某种原因变得极慢,那么我们的下单线程会大量地阻塞在等待用户服务响应上,最终耗尽线程池,导致整个下单服务雪崩。
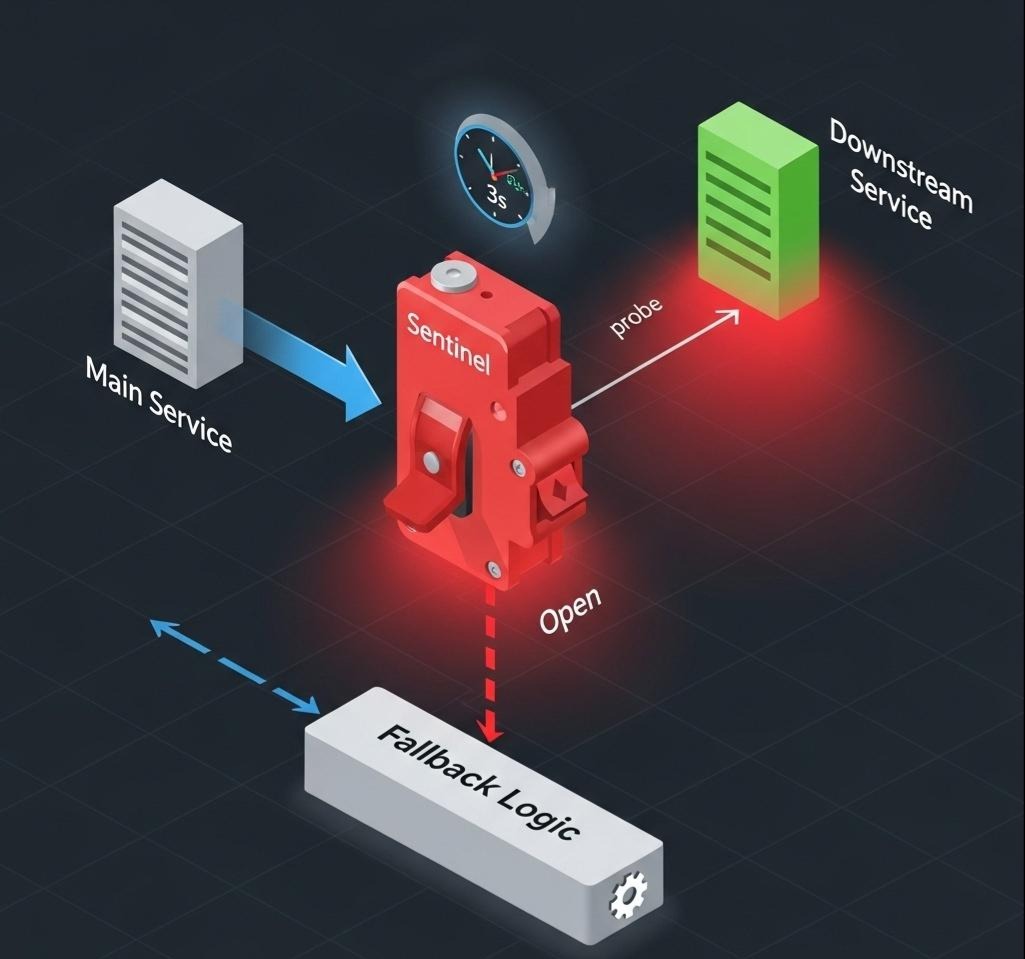
熔断器的作用,就是在探测到下游服务出现问题时,主动切断对它的调用,快速失败,保护自己,并在一段时间后尝试恢复。
配置DegradeRule:
1 | List<DegradeRule> degradeRules = new ArrayList<>(); |
熔断的生命周期:
- Closed(关闭): 正常状态,允许所有请求通过。
- Open(打开): 当满足熔断条件(如慢调用比例超阈值),熔断器打开。在接下来的timeWindow(5秒)内,所有对该资源的调用都会被立即阻止,直接抛出DegradeException。
- Half-Open(半开): 熔断时间结束后,熔断器进入半开状态。它会小心翼翼地放过一个请求去试探下游服务。如果这个请求成功且RT正常,熔断器关闭,恢复正常;如果请求依然失败或缓慢,熔断器重新进入打开状态,并开始新一轮的熔断计时。
这个“半开”状态的设计,是实现自动恢复的关键,避免了人工干预。
战术三:热点参数限流(精准点杀)——秒杀场景的核武器
这才是Sentinel在秒杀场景下,相比Nginx等其他限流工具,最具“降维打击”优势的功能。
场景:
我们同时秒杀商品A、B、C。商品A是iPhone,极其火爆;商品B和C是普通商品。如果没有热点参数限流,针对createSeckillOrder方法的QPS限流阈值是1000。iPhone的流量可能瞬间就占满了这1000 QPS,导致想购买商品B和C的正常用户,请求也被无辜地拒绝。
热点参数限流允许我们对同一个方法的不同参数组合,进行独立的流量统计和控制。
配置ParamFlowRule:
1 | ParamFlowRule paramFlowRule = new ParamFlowRule("createSeckillOrder"); |
效果:
- 当大量请求购买iPhone(itemId=123)时,只有前500 QPS能通过,超出的会被限流。
- 同时,当有请求购买普通商品(itemId=456)时,它有自己独立的50 QPS的“预算”,完全不受iPhone流量的影响。
- 对于其他未在例外中指定的商品,则遵循默认的200 QPS阈值。
这就是“精准点杀”。它将粗放的“保卫接口”升级为精细的“保卫每一个商品的购买链路”,极大地提升了系统的资源利用率和用户体验。
2.4 集群限流与持久化
我们上面所有的讨论,都基于单机维度的限流。但在生产环境中,我们的Seckill-Core Service通常是集群部署的。
问题: 如果我们有10台机器,每台机器的createSeckillOrder限流1000 QPS,总阈值就是10000 QPS。但如果某一天,我们只想让总的下单QPS不超过5000,怎么办?
解决方案:Sentinel集群流控(Token Server模式)
- 选举一个Token Server: 在集群中,选举一台机器(或者是一个独立的Server集群)作为“令牌中心”。这个Server维护着全局的流控规则和令牌桶。
- 其他机器成为Token Client: 其他的业务服务器都成为Client。当它们需要处理一个请求时,不再查询自己的本地规则,而是向Token Server发起一个RPC请求:“我需要一个createSeckillOrder资源的令牌,可以吗?”
- Server统一发放: Token Server根据全局的令牌桶情况,决定是否发放令牌。如果发放,Client就继续执行业务逻辑;如果拒绝,Client就直接拒绝请求。
架构选型:
Sentinel集群流控还有一种“嵌入模式”,即每个Client都可能成为Server,互相通信。但在秒杀这种对延迟和规则一致性要求极高的场景,一个独立的、高性能的Token Server是更稳妥、更可控的选择。
规则持久化:
代码中硬编码规则的方式只适合演示。在生产环境中,所有Sentinel规则都必须持久化到配置中心,如Nacos、Apollo。
Sentinel提供了与主流配置中心无缝集成的datasource扩展。你只需引入相应的依赖(如sentinel-datasource-nacos),并进行简单的配置,Sentinel客户端就会自动监听配置中心,实现规则的动态推送、实时生效、全局管理。
1 | // application.yml 示例 |
现在,你的运维或SRE团队,就可以通过修改Nacos上的一个JSON配置文件,实时地、全局地调整线上所有秒杀服务的流控策略,而无需重启任何应用。这赋予了系统前所未有的动态运维能力。
结语:从“铁壁合围”到“手术刀式”的防御纵深
在本章超过一万六千字的深度剖析中,我们为秒杀系统构建了最后,也是最关键的一道内部壁垒。我们经历了:
- 在Nginx层,我们利用其高效的事件模型和丰富的指令,像筑造城墙一样,完成了基础的连接限制、速率整形,并通过OpenResty+Lua,赋予了这堵墙动态查询外部情报的“智能”。
- 在Sentinel层,我们深入到Java微服务的肌理之中,挥舞起流量控制、熔断降级、热点参数限流这三把锋利的手术刀,实现了对业务流量的精细化、动态化、集群化的“神经元级”管控。
我们深刻地理解到,Nginx的宏观拦截与Sentinel的微观调控,并非互相替代,而是相辅相成、缺一不可。它们共同构成了一个从物理边界到业务逻辑核心的、具有梯度的防御纵深。流量的洪水,在Nginx这里被削弱为可控的河流,在Sentinel这里被分流为精确的溪水,最终滋养着我们业务的正常运行。
至此,我们的防御工事已基本完成。但是,一场战争光有防御是远远不够的。在下一篇章中,我们将进入整个秒杀战役的心脏地带——核心篇:乾坤挪移——用缓存和消息队列重塑下单流程。我们将直面整个架构中最核心的挑战:如何在不锁死数据库的前提下,实现百万并发下的原子性库存扣减。那将是一场关于Redis Lua脚本、分布式锁、以及消息队列(Kafka/RocketMQ)选型与实践的终极对决。

