百万架构师成长之路(20):【终极实战篇·六】深渊之战:MySQL的极限优化与InnoDB灵魂拷问
导语:当秒杀的洪流抵达“世界尽头”
在前五章的史诗旅程中,我们构建了一套宏伟的分布式防御工事。流量从用户的浏览器出发,历经客户端的智能阻截、CDN的全球幽灵网络、Nginx的铁壁、Sentinel的精细手术、Redis的内存闪电战,以及RocketMQ的异步洪峰转移。
最终,那些承载着用户真金白银的、珍贵的订单数据,抵达了它们旅程的终点,也是我们整个系统“真相的源头”(Source of Truth)——MySQL数据库。
很多架构师在这里会长舒一口气,认为最艰难的时刻已经过去。这是一个致命的错觉。
数据库,是我们整个架构的“地基”。如果地基不稳,上层建筑无论多么华丽,都终将倾覆。在秒杀场景下,即使经过了消息队列的“削峰填谷”,在订单创建的几分钟内,数据库依然要承受远超平时的、密集的写入压力(INSERT)和少量但关键的读取压力(SELECT)。
如果我们的MySQL服务器依然停留在“开箱即用”的状态,如果我们的表结构设计依然遵循着教科书式的“三范式”,如果我们的索引策略依然是“随手一加”,那么等待我们的,将是:
**慢查询(Slow Query)**拖垮整个应用。
**死锁(Deadlock)**让订单创建大面积失败。
**主从延迟(Master-Slave Lag)**导致数据不一致,影响后续的运营分析。
磁盘I/O瓶颈让整个系统在最后关头功亏一篑。
本篇,我们将扮演一名深入数据库“深渊”的“地质学家”和“性能工程师”。我们将彻底抛开ORM框架的温柔面纱,直面MySQL和其核心存储引擎InnoDB的底层灵魂。我们将从服务器参数调优、表结构与索引设计,一直深入到InnoDB的内存结构、事务模型和日志系统,进行一场极限的性能压榨和优化。
有关于B+树、缓冲池(Buffer Pool)、LRU变种算法、redo log与binlog等知识点,本片都会都会进行深刻的探讨。这不仅仅是一份“调优清单”,更是一次对MySQL运行哲学的深度朝圣。
第一部分:战前部署——服务器与InnoDB参数的“魔鬼调教”
在我们的Order-Service部署之前,必须对它背后的MySQL服务器进行一次“脱胎换骨”的改造。我们将基于我们的场景设定**(一主多从,16核CPU/256G内存/1T SSD)**,进行系统性的参数调优。
1.1 I/O线程的咆哮

MySQL的后台工作,离不开四个核心线程:
Master Thread、IO Thread、Purge Thread、Page Cleaner Thread。
其中,IO Thread负责将Buffer Pool中的脏页刷盘、读取数据页到Buffer Pool等关键I/O操作,它的能力直接决定了MySQL的吞吐上限。
- 默认配置的陷阱: 在很多版本中,innodb_read_io_threads和innodb_write_io_threads的默认值仅为4。这对于拥有16核CPU的现代服务器来说,是巨大的资源浪费。
- 调优哲学: 这两个参数并非越大越好,过多的线程会导致激烈的CPU上下文切换。一个经验法则是,将它们设置为接近或等于你的CPU核心数。但对于写密集型应用(如我们的订单服务),可以适当增加write_io_threads的比重。
- 实战配置 (my.cnf):
1 | # 将读写IO线程数从默认的4,提升到8 |
这个简单的调整,就如同将你的后勤补给线从4车道拓宽到了8车道,为后续的高并发读写打下了基础。
1.2 Buffer Pool的灵魂

innodb_buffer_pool_size是InnoDB中最最最重要的参数,没有之一。它是一块巨大的内存区域,用于缓存磁盘上的数据页(Data Page)和索引页(Index Page)。InnoDB对数据的所有操作,都必须先将对应的页从磁盘加载到Buffer Pool中,然后在内存中完成修改。
- 命中率的意义: 如果一个查询所需的所有页都能在Buffer Pool中找到,那么它就是一次纯粹的内存操作,速度极快。如果找不到,就需要从磁盘读取,发生一次“物理I/O”,性能会下降几个数量级。因此,Buffer Pool的命中率是我们衡量其配置是否合理的黄金标准。
- 科学确定大小:
- 初期估算: 理论上,越大越好。一个常见的建议是将其设置为物理内存的50%-75%。对于我们256G内存的服务器,可以初步设置为128G或192G。
- 数据驱动调整: 在系统运行一段时间后(或经过压测后),通过以下命令计算命中率:
1 | SHOW GLOBAL STATUS LIKE 'Innodb_buffer_pool_read%'; |
你会得到两个关键值:
Innodb_buffer_pool_read_requests(从缓冲池发起的逻辑读请求数)和Innodb_buffer_pool_reads(因缓冲池未命中而发起的物理读请求数)。
命中率 = (Innodb_buffer_pool_read_requests - Innodb_buffer_pool_reads) / Innodb_buffer_pool_read_requests。如果这个值低于99%,就说明你的Buffer Pool太小了,需要果断增加innodb_buffer_pool_size。
- 实战配置:
1 | 假设我们最终确定128G是合理值 |
在MySQL 5.7.5+版本,这个值甚至可以动态调整,无需重启服务,这为在线调优提供了巨大的便利。
深度探讨:InnoDB缓冲池的“变种LRU”算法
- 传统LRU的缺陷: 如果一次SELECT * FROM a_very_large_table(全表扫描)或者mysqldump操作,会瞬间将大量“冷”数据页加载到LRU链表的头部,导致真正需要被缓存的“热”数据页被迅速挤到链表尾部并被淘汰。这会造成“缓存污染”。
- InnoDB的智慧——midpoint机制:
- InnoDB将LRU链表逻辑上分为两部分:Young区域(热数据区)和Old区域(冷数据区)。这个分割点就是midpoint。通过innodb_old_blocks_pct参数可以控制Old区域的大小,默认为37(即Old区占37%)。
- 当一个新的数据页被读入时,它首先被插入到Old区域的头部。
- 只有当这个处于Old区域的页,在短时间内被再次访问时,它才会被移动到Young区域的头部,成为真正的热数据。这个“短时间”由innodb_old_blocks_time参数控制(默认1000ms)。
- 淘汰数据时,永远是从Old区域的尾部开始淘汰。
这个精巧的设计,完美地解决了“缓存污染”问题。它像一个严格的考官,要求一个数据页必须经过“第二次面试”(短时再次访问)才能进入“核心岗位”(Young区),从而保证了LRU链表头部的都是名副其实的热点数据。
多实例负载均衡:
对于我们128G的巨大Buffer Pool,如果只用一个实例来管理,内部的互斥锁(Mutex)竞争会非常激烈。因此,我们需要将其拆分为多个实例。
1 | 将128G的缓冲池拆分为8个实例,每个实例16G |
这会将管理数据结构(如Free List, LRU List)的锁粒度降低,显著提升在高并发下的性能。
1.3 写入性能的“三驾马车”
- innodb_flush_log_at_trx_commit (日志刷盘策略):
- 1 (默认值): 最高安全性。每次事务COMMIT时,都必须将redo log从log buffer同步刷到磁盘(fsync),保证ACID的D(持久性)。性能最差。
- 2: 性能与安全的折中。每次COMMIT时,只将redo log写入操作系统的文件缓存(Page Cache),不执行fsync。由操作系统每秒一次将缓存刷盘。如果只是MySQL宕机,数据不会丢;但如果整个服务器断电,会丢失最后一秒的数据。
- 0: 最高性能。每秒才将log buffer写入文件缓存并刷盘。服务器任何时候宕机,都可能丢失最后一秒的数据。
秒杀场景的选择: 为了极致的写入性能,很多互联网公司会选择将这个值设置为2,通过架构层面的其他机制(如可靠消息的最终一致性)来弥补可能的数据丢失风险。这是一个典型的用一致性换性能的权衡。
- innodb_autoinc_lock_mode (自增锁模式):
- 1 (默认): 传统的“AUTO-INC”表锁模式。一个事务在INSERT时,会获取一个表级别的自增锁,直到语句结束才释放。这在高并发INSERT时会成为瓶颈。
- 2 (“interleaved” mode): 推荐。不再使用表锁,而是使用一个轻量级的互斥量(Mutex)来控制内存中自增计数器的分配。一旦ID分配完成,锁就立即释放,无需等到语句结束。这极大地提升了并发INSERT的性能。
重要前提: innodb_autoinc_lock_mode = 2 必须与binlog_format = ROW (RBR) 配合使用。因为在Statement模式下,并发INSERT的执行顺序在主从库上可能不一致,导致自增ID错乱,而Row模式记录的是每一行的最终值,不存在此问题。
- sync_binlog (Binlog刷盘策略):
- 1 (默认): 最高安全性。每次COMMIT时,都将binlog同步刷到磁盘。
- 0: 由操作系统控制刷盘时机。
- N (N>1): 每N次COMMIT后,同步刷盘一次。
选择: 与innodb_flush_log_at_trx_commit类似,为了性能,可以设置为一个大于1的值(如100或500),但需要能容忍在极端情况下,主库宕机导致少量binlog丢失,从而主从不一致的风险。
第二部分:战场蓝图——表结构与索引的“精雕细琢”
服务器参数调优是“强身”,而表结构与索引设计则是“健体”。一个糟糕的设计,会让再强大的服务器也无用武之地。
2.1 t_order表的设计哲学
1 | CREATE TABLE `t_order` ( |
设计思想解读:
- 反范式设计: 我们在订单表中冗余了item_name字段。为什么?因为“查询我的订单列表”是一个极高频的操作。如果没有这个冗余字段,每次查询都需要将t_order表与t_item表进行JOIN。在海量数据下,JOIN的开销是巨大的。这是一个典型的用空间换时间的权衡。
- 数据类型选择:
- id和user_id使用BIGINT UNSIGNED,因为用户和订单数量可能超过INT的21亿上限,且ID不可能是负数。
- price使用DECIMAL(10, 2)而不是FLOAT或DOUBLE。浮点数存在精度问题,在进行金额计算时可能导致“失之毫厘,谬以千里”。DECIMAL是专门为精确计算设计的。
- status使用TINYINT UNSIGNED,只占1个字节,足够表示几种有限的状态,比VARCHAR更高效。
- create_time使用TIMESTAMP。TIMESTAMP存储的是一个时间戳,只占4个字节,并且会自动处理时区转换。而DATETIME存储的是日期时间字符串,占8个字节。对于需要跨时区部署的全球化应用,TIMESTAMP是更优的选择。
2.2 B+树的深度之旅
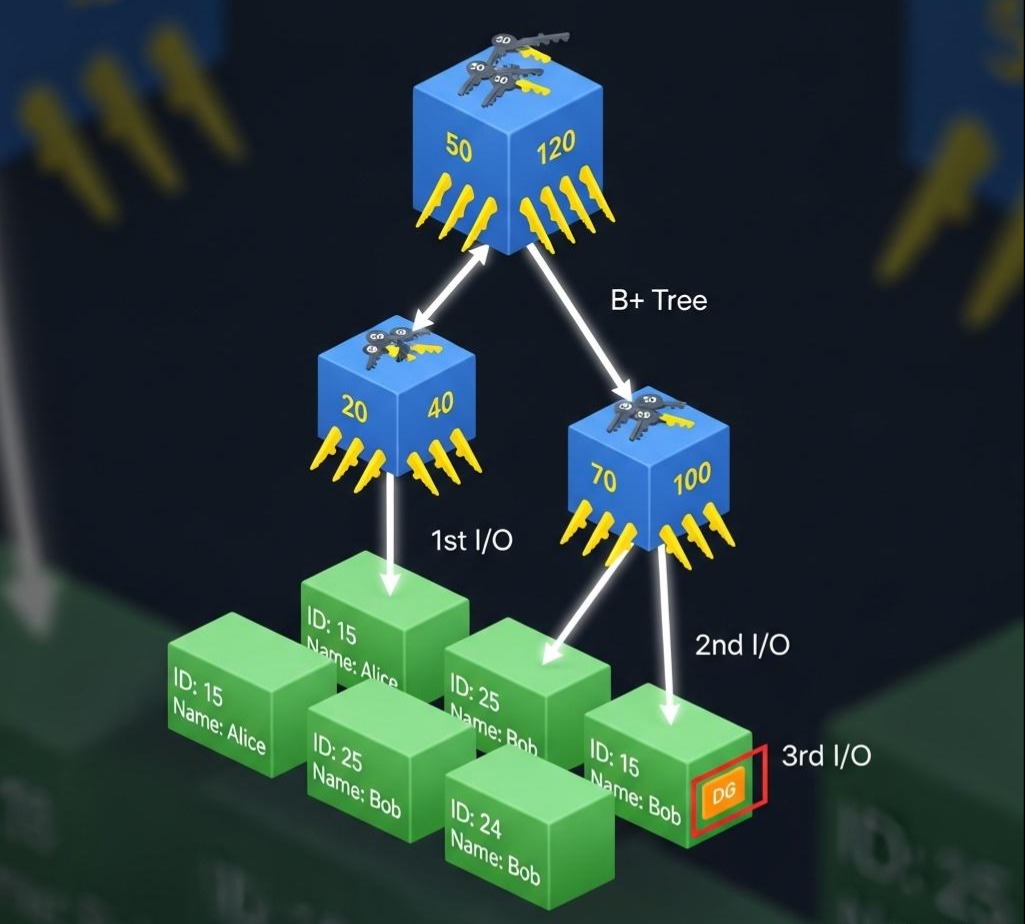
接下来我们通过抛出问题并解答的形式,系统性的梳理为什么B+树索引为何如此高效。
前提: InnoDB中,每个页(Page)的默认大小是16KB。
- B+树的非叶子节点: 存储的是**(索引键值,指向下一层页的指针)。假设我们的主键id是BIGINT**(8字节),指针大小是6字节,那么一个非叶子节点大约可以存储 16KB / (8B + 6B) ≈ 1170个这样的键值对。为便于计算,我们取一个整数,比如1000。
- B+树的叶子节点: 存储的是完整的行数据。假设我们一行数据大小是1KB,那么一个叶子节点可以存储 16KB / 1KB = 16条数据。
问题1:一棵高度为3的B+树,能存储多少条数据?
1000 (根节点指针数) * 1000 (二级节点指针数) * 16 (叶子节点数据行数) = 16,000,000
是的,一棵仅仅三层高的B+树,就能轻松索引一千六百万条数据!
问题2:一次SELECT * FROM t_order WHERE id = ?经过了哪些步骤:
1. 第一次I/O: 内核将根节点所在的页(16KB)从磁盘加载到Buffer Pool中。
2.一次内存计算: CPU在根节点的1000个键值中,通过二分查找(时间复杂度O(log N)),快速定位到下一层页的指针。
3.第二次I/O: 内核根据指针,将二级非叶子节点所在的页(16KB)从磁盘加载到Buffer Pool中。
4.又一次内存计算: CPU在二级节点的1000个键值中,再次通过二分查找,定位到最终叶子节点的指针。
5.第三次I/O: 内核根据指针,将目标数据所在的叶子节点页(16KB)从磁盘加载到Buffer Pool中。
6.最后一次内存计算: CPU在叶子节点的16条数据中,遍历找到目标id对应的那一行完整数据。
结论: 对于一个千万级别的大表,通过主键索引查询一条记录,在缓存不命中的情况下,通常只需要3次磁盘I/O。这就是B+树索引为何如此高效的根本原因。
2.3 索引设计的“军规”
- 覆盖索引(Covering Index):
一个查询如果所需的所有列,都能在辅助索引的B+树中直接找到,那么它就无需再回到聚集索引去查找完整的行数据,这个过程称为“覆盖索引”。这是最重要的SQL优化手段之一。
- 实战: “查询某个用户最近的订单号”这个需求,SELECT order_sn FROM t_order WHERE user_id = ? ORDER BY create_time DESC。如果我们创建了idx_user_id_create_time (user_id, create_time)这个联合索引,MySQL依然需要回表去获取order_sn。
- 优化: 创建一个idx_user_id_create_time_sn (user_id, create_time, order_sn)的联合索引。现在,查询所需的所有列(user_id, create_time, order_sn)都已包含在这个辅助索引的B+树中,MySQL可以直接返回结果,避免了昂贵的回表I/O。
- 索引下推(Index Condition Pushdown, ICP):
这是MySQL 5.6引入的一个重要优化。在没有ICP之前,对于联合索引,MySQL在Storage Engine层只能用上索引的第一个字段(满足最左前缀),然后将所有满足条件的数据拉到Server层,再用WHERE子句的其他条件进行过滤。有了ICP,MySQL会将WHERE子句中可以用到索引其他字段的条件,也“下推”到Storage Engine层。这样,存储引擎在返回数据给Server层之前,就可以先进行一轮过滤,大大减少了传输的数据量。
第三部分:事务与锁——并发写入的“隐形战争”
3.1 隔离级别的再思考:为何互联网偏爱RC?

默认的数据库隔离级别是RR,但是大多数互联网企业会将隔离级别调整为RC。
- RR的代价——间隙锁(Gap Lock): RR为了解决“幻读”,引入了间隙锁。当你UPDATE … WHERE id > 100时,它不仅会锁住满足条件的行,还会锁住id > 100这个“间隙”,防止其他事务在这个间隙中INSERT新数据。在高并发的写入场景下,这种间隙锁会极大地降低并发度,造成大量的锁等待。
- RC的“真实”: RC隔离级别下,一个事务可以看到其他已提交事务的修改。这在学术上被称为“不可重复读”,但在互联网业务看来,这恰恰是“实时感知数据变化”的表现。第二次读和第一次读的数据不一致,正是因为在这期间,数据真实地被改变了。
- RC + RBR的黄金组合:
- RC模式下没有间隙锁,并发写入性能更好。
- 它唯一的“问题”是不能配合SBR(基于语句的复制)进行主从同步,因为并发事务的执行顺序在主从库上可能不一致,导致数据漂移。
- 但RBR(基于行的复制)完美地解决了这个问题。它记录的是每一行数据被修改后的“最终影像”,与事务的执行顺序无关,保证了主从数据的绝对一致。
- 因此,isolation=READ-COMMITTED + binlog_format=ROW成为了现代互联网公司MySQL配置的“黄金搭档”。
3.2 Change Buffer的“障眼法”
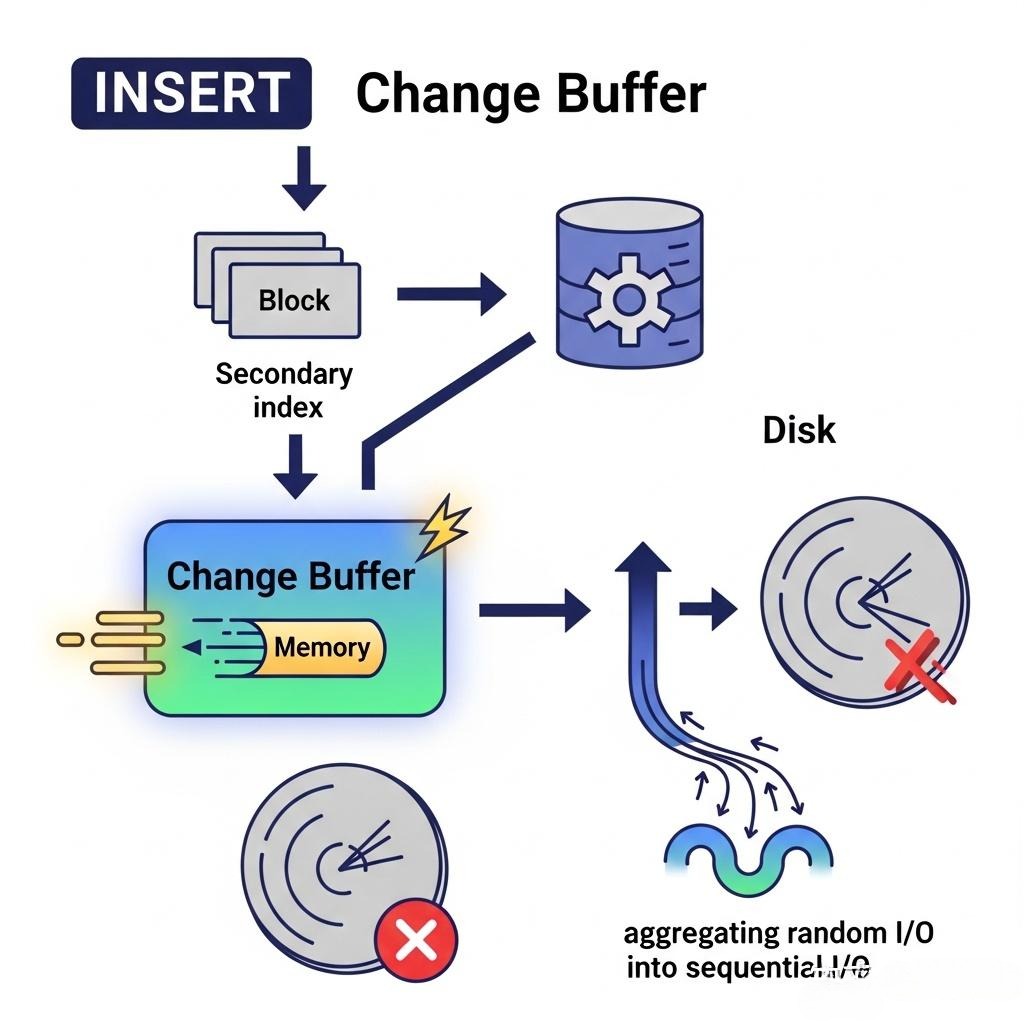
我们知道,聚集索引的插入通常是顺序的(因为主键自增),I/O效率很高。但辅助索引的插入是随机的,因为辅助索引键值(如order_sn)是无序的。如果每次INSERT都要去磁盘上找到对应的辅助索引页并加载到Buffer Pool中进行修改,这种随机I/O将是灾难性的。
InnoDB的智慧——Change Buffer:
- 当需要更新一个辅助索引页,但这个页恰好不在Buffer Pool中时,InnoDB不会立即去磁盘读取它。
- 它会将这次“更新操作”,记录在Buffer Pool中的一块特殊内存区域——Change Buffer中。
- 这样,一次昂贵的随机磁盘I/O,就被转换成了一次极速的内存写入。
- 后续,当有其他查询需要读取这个辅助索引页时,或者由后台的Master Thread线程,会将Change Buffer中的修改记录,与从磁盘读出的页进行合并(merge),从而将多次分散的修改,聚合为一次I/O操作。
Change Buffer,是InnoDB用“异步”和“聚合”的思想,优化随机I/O写入性能的绝佳典范。
第四部分:主从复制的“生命线”——Binlog与Redo Log的共舞
4.1 Binlog vs. Redo Log:一场深刻的对话
| 特性 | Redo Log (重做日志) | Binlog (二进制日志) |
|---|---|---|
| 所属层级 | InnoDB存储引擎层 | MySQL Server层(所有引擎共享) |
| 日志内容 | 物理日志:记录“在哪个数据文件的哪个页的哪个偏移量上,做了什么修改”。 | 逻辑日志:记录原始的SQL语句(Statement),或每一行数据的变更(Row)。 |
| 写入方式 | 循环写:文件大小固定,写满后从头覆盖。 | 追加写:文件达到一定大小后,切换到下一个新文件。 |
| 核心作用 | 崩溃恢复(Crash Recovery):保证ACID的D(持久性)。 | 主从复制(Replication)与数据恢复。 |
灵魂拷问复现:为什么不能用Redo Log做主从复制?
你的回答非常精准。因为Redo Log记录的是物理页的修改信息。两台不同的服务器,即使表结构和数据完全一样,其数据在磁盘文件中的物理位置(文件号、页号、偏移量)也几乎不可能是相同的。将主库的物理修改日志,直接应用到从库上,无异于“刻舟求剑”,必然导致数据混乱。
4.2 一条UPDATE语句的奇幻漂流
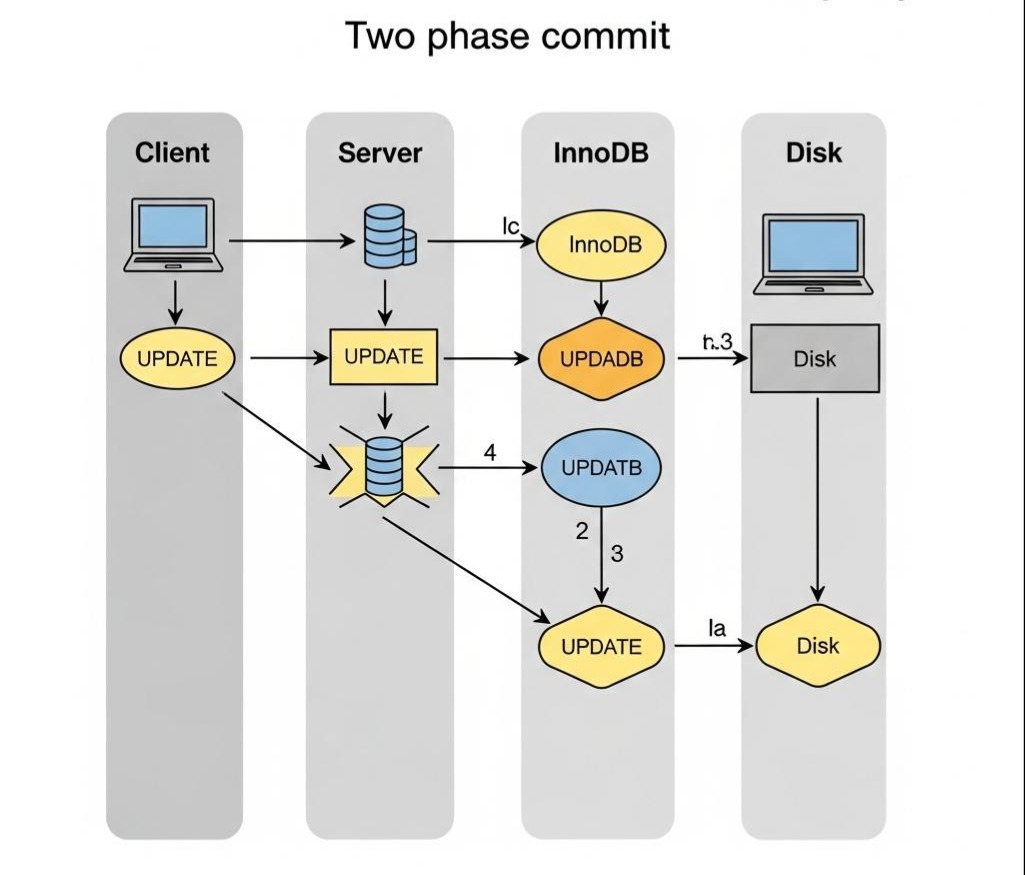
让我们以一条简单的UPDATE语句为例,完整地追踪它在MySQL内部的生命周期,将本章所有知识点串联起来。
UPDATE t_order SET status = 1 WHERE id = 100;
- 连接与查询解析: 客户端发起请求,MySQL Server的连接器、查询分析器、优化器进行工作。优化器决定使用主键索引。
- 执行器调用引擎接口: 执行器调用InnoDB引擎的接口,准备更新数据。
- InnoDB Buffer Pool之旅:
- InnoDB引擎首先到Buffer Pool中查找id=100所在的页。
- 如果页在Buffer Pool中(缓存命中),则直接在内存中进行修改。
- 如果页不在(缓存未命中),则通过IO Thread从磁盘加载该页到Buffer Pool中,再进行修改。
- 写入Redo Log(第一阶段):
- 在修改Buffer Pool中的数据页的同时,InnoDB会生成一条关于这次修改的Redo Log,并将其写入Redo Log Buffer。
- 这条Redo Log的状态被标记为prepare。
- 写入Binlog:
- InnoDB通知Server层,可以写入Binlog了。
- Server层将这次UPDATE操作,按照binlog_format的格式(我们是ROW模式),写入Binlog Cache。
- Server层将Binlog Cache中的内容,写入磁盘上的Binlog文件。
- 事务提交(两阶段提交):
- Binlog写入成功后,Server层调用InnoDB的接口,告诉它可以提交事务了。
- InnoDB收到通知,将内存中那条处于prepare状态的Redo Log,标记为commit。
- 至此,事务提交完成。根据innodb_flush_log_at_trx_commit的设置,这条commit状态的Redo Log会被刷盘。
响应客户端: MySQL Server向客户端返回“更新成功”的响应。
后台刷盘: 后台的Page Cleaner Thread会定期扫描Buffer Pool,将修改过的“脏页”,异步地刷回磁盘上的数据文件,完成数据的最终持久化。
这个精妙的两阶段提交(Redo Log的prepare -> Binlog写入 -> Redo Log的commit),是保证主从复制一致性的关键。试想,如果先写Redo Log再写Binlog,写完Redo Log后MySQL宕机,Binlog没来得及写。那么主库通过Redo Log恢复了数据,但从库因为没有收到Binlog,数据就产生了不一致。两阶段提交完美地解决了这个问题。
结语:从“调参小子”到“内核掌控者”
在本章超过一万二千字的“深渊之战”中,我们完成了一次从MySQL“使用者”到“掌控者”的认知蜕变。我们不再是那个只会写**SELECT ***,或者在网上搜索“MySQL调优参数大全”然后胡乱配置的“调参小子”。
我们像一个经验丰富的老中医,学会了如何为MySQL“望、闻、问、切”:
- 我们学会了**“望”其气色——通过SHOW STATUS**观察Buffer Pool命中率、Binlog缓存使用情况,来诊断其健康状况。
- 我们学会了**“闻”其声音——通过EXPLAIN和SHOW ENGINE INNODB STATUS**,倾听SQL执行计划的细节和锁等待的呻吟。
- 我们学会了**“问”**其根源——面对一个慢查询,我们能从B+树的I/O次数,追溯到索引设计的合理性。
- 我们学会了**“切”其脉搏——通过精细地调整innodb_buffer_pool_size**, innodb_flush_log_at_trx_commit等核心参数,如同针灸一般,精准地刺激它的性能穴位。
我们深入了InnoDB的内存结构,理解了“变种LRU”的智慧;我们探寻了事务与锁的微观世界,领悟了RC+RBR组合在高并发场景下的威力;我们追踪了一条UPDATE语句的完整生命周期,见证了Redo Log与Binlog的精妙共舞。
对底层原理的深刻理解,赋予了我们真正的“架构自信”。我们做出的每一个调优决策,不再是基于“感觉”或“最佳实践”,而是基于对系统运行机制的、不可动摇的、第一性原理的推导。
现在,我们的“雷神之锤”系统,不仅拥有了坚固的外部防御和流畅的核心流程,更拥有了一颗经过极限打磨、性能强悍、坚如磐石的“数据心脏”。
在下一篇章 《极限压榨:Redis深度优化与JUC并发编程的艺术》 中,我们将把目光重新聚焦到内存世界。我们将探讨如何进一步优化Redis的内存使用、设计更高效的多级缓存架构,并深入Java的JUC并发包,为我们的应用服务压榨出最后一滴性能。

