百万架构师成长之路(21):【终极实战篇·七】极限压榨:Redis内存优化与JUC并发编程的艺术
导语:当性能的战场,从磁盘转移到纳秒级的内存世界
在过去的几个篇章里,我们构建了从外到内的层层防御,重塑了核心的下单流程,并对最终的“真相之源”MySQL进行了深度优化。我们的“雷神之锤”系统,在宏观架构层面,已经趋于完善。
但真正的卓越,源于对微观世界的极限压榨。
现代高性能系统的战争,早已从毫秒级的磁盘I/O,升级到了微秒级甚至纳秒级的内存访问。在这场战争中,我们手中最锋利的两把剑,便是Redis和Java自身的内存与并发模型(JUC)。
Redis,作为我们架构的“首席内存官”,承载了库存预扣减、用户资格校验、分布式锁等最核心、最频繁的读写操作。它的性能和容量,直接决定了我们系统能支撑的并发上限。
Java应用(Seckill-Core服务),作为执行命令的“作战单元”,其内部的线程管理、内存使用效率,则决定了它能否将硬件的性能百分之百地转化为业务处理能力。
然而,我们常常满足于对它们“开箱即用”式的应用:redisTemplate.opsForValue().set()、Executors.newFixedThreadPool()。这种“黑盒”式的使用,在常规业务中或许无伤大雅,但在秒杀这种极限场景下,却隐藏着巨大的性能浪费和潜在风险。
本篇,我们将扮演一名“内存魔术师”和“并发编程大师”,戴上显微镜,深入这两大“内存战场”的细胞层面,进行一场极限的性能压榨。我们将直面并解决那个极具挑战性的问题:如何在不增加硬件、不删除数据的前提下,让Redis装下更多数据,跑得更快? 我们还将挑战传统的线程池配置思路,为秒杀流量定制一个更高效的并发执行模型。
这不再是关于“用什么”的讨论,而是关于“如何用到极致”的、属于顶尖高手的进阶之战。

第一部分:Redis内存的“空间魔术”——让1GB当2GB用
1.1 问题的提出
这是一个真实且极具挑战性的面试或实战场景:
“我们的一个核心业务,Redis内存使用率已达95%,接近报警阈值。业务高峰即将到来,我们没有预算增加新的机器或升级内存。同时,业务特性决定了我们不能删除任何现有数据,也不能简单地通过开启RDB/AOF将一部分冷数据淘汰。请问,你作为架构师,有什么办法在不改变硬件和数据总量的前提下,降低内存占用,并最好能提升性能?”
这是一个看似“无解”的问题。它要求我们不能从“外部”想办法(加机器、删数据),而必须向“内部”要效益。这要求我们必须深入到Redis数据结构的底层,从它存储每一个字节的方式中,去寻找优化的空间。
1.2 源码层面的“第一性原理”:Redis数据结构的内存开销
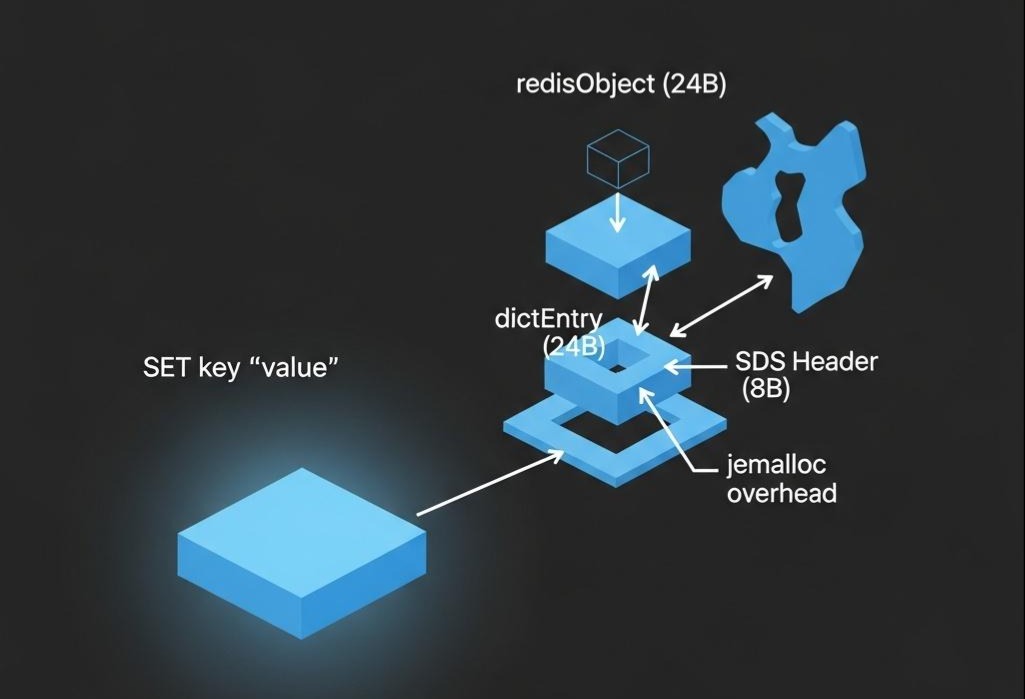
要优化内存,首先要知道内存花在了哪里。
一个常见的误解是:SET mykey “hello”,value是5个字节,所以它就占5个字节。大错特错!
在Redis中,任何一个Key-Value对,都不是简单地存储原始值。它至少包含以下几个部分的开销:
- dictEntry结构体: 在Redis的全局哈希表(dict)中,每个键值对都是一个dictEntry。这个结构体自身就包含了指向Key、指向Value、以及指向下一个dictEntry(解决哈希冲突)的三个指针。在64位系统中,仅这三个指针就占了 8 * 3 = 24 字节。
- redisObject结构体: Redis中任何一个Value,都会被封装成一个redisObject。这个结构体包含了type(类型)、encoding(编码)、lru(LRU时间)、refcount(引用计数)以及一个指向真正数据内容的*ptr指针。这又带来了 4 + 4 + 24(bits) + 4 + 8 = 24 字节(近似值)的额外开销。
- SDS (Simple Dynamic String): Redis中的Key,以及String类型的Value,都不是用C语言原生的char存储的,而是用一种叫做SDS的自定义结构。SDS除了存储字符串本身,还包含了*len(已用长度)和alloc(已分配长度)两个字段,至少有8个字节的额外开销。
- 内存分配器开销: Redis使用的内存分配器(如jemalloc)为了减少内存碎片,实际分配的内存块大小会比你申请的稍大一些(对齐到2的N次方)。
结论: 一个看似简单的SET key value操作,其附加的元数据开销,可能就高达50-60字节!当我们有数亿个这样的短Key-Value时,这些元数据开销的总和将是惊人的。
1.3 优化战术一:拥抱压缩数据结构
Redis的作者Antirez早就意识到了这个问题。因此,在Hash、List、ZSet、Set这四种数据结构中,当它们包含的元素数量较少,且每个元素的大小较小时,Redis不会使用标准的哈希表或双向链表等结构,而是会采用一种极其节省内存的压缩数据结构。

Redis 5.0之前:ziplist (压缩列表)
- 原理: ziplist放弃了常规数据结构中大量的指针,而是将所有元素存储在一块连续的内存中。它像一个“智能”的字节数组,每个节点(entry)包含三个部分:previous_entry_length(前一个节点的长度,用于反向遍历)、encoding(当前节点数据的编码方式)、content(实际数据)。
- 优势: 因为没有了指针,内存利用率极高。
- 灵魂拷问复现: ziplist的致命缺陷——连锁更新(Cascading Update)。由于每个节点都记录了前一个节点的长度,如果我们在一个很长的ziplist的头部插入一个新节点,而这个新节点的长度恰好导致了它后面那个节点的previous_entry_length字段需要从1字节扩展到5字节(因为前一个节点的长度变大了),这个扩展又可能导致它后面节点的previous_entry_length也需要扩展……这种多米诺骨牌效应,会让一次简单的头插操作,变成一次涉及大量数据拷贝的O(N^2)级别的灾难。
Redis 5.0之后:listpack
- 为了解决ziplist的连锁更新问题,Redis引入了listpack。
- 原理: listpack做了一个聪明的改变:它让每个节点只记录自己的长度,而不是前一个节点的长度。当需要反向遍历时,我们先找到当前节点,然后从当前节点的头部读取到自己的长度,再用指针当前地址 - 自己的长度,就能直接跳到前一个节点的起始位置。
- 优势: 彻底杜绝了连锁更新。任何节点的插入和删除,只会影响它自己,不会波及其他节点。
实战调优:
我们可以通过redis.conf来调整触发压缩数据结构的阈值。
1 | 对于Hash类型 |
优化策略:
在我们的场景中,我们可以适当地增大这些阈值。例如,经过测试,如果hash-max-ziplist-entries从512调整到1024,对于大部分业务场景,读写性能的下降并不明显(因为现代CPU处理内存拷贝的速度极快),但内存的节省却是实实在在的。这是一个典型的用少量CPU时间换取大量内存空间的权衡。
1.4 优化战术二:代码层面的“数据瘦身”
- 简化Key的命名:
- 反例: seckill:business:user:purchase_history:userid_123456
- 正例: sk:u:ph:123456在亿万级别的Key数量下,每个Key节省10个字节,就能节省出GB级别的内存。我们需要在可读性和空间效率之间做出权可衡,并形成团队的命名规范。
- 对大列表/大哈希进行“分片”:如果我们有一个需要存储10000个元素的List,而我们的压缩列表阈值是2048。直接存成一个大List,它会使用内存开销巨大的linkedlist编码。优化策略: 在代码层面,将这个大List拆分为5个小List,每个List存储2000个元素。
- Key的设计:my_list:shard_1, my_list:shard_2, …
- 这样,每个小List都能享受到ziplist/listpack带来的内存压缩红利。虽然在读取时需要多次LRANGE,但在内存极度紧张的情况下,这是值得的。
1.5 优化战术三:数据编码的“降维打击”
这是最高级,也是最有效的优化手段。其核心思想是,将业务层面的信息,用更紧凑的数据结构来表示。
实战案例:存储用户地理位置
假设我们需要存储用户的地理位置信息,如“北京市-朝阳区-望京街道”。
- 常规做法: HSET user:geo:123 city “北京市” district “朝阳区” street “望京街道”。这存储了大量的冗余中文字符串。
- 优化策略:
- 在Java应用层,维护一个映射关系。 我们可以预先将全国所有的省、市、区、街道信息加载到内存中,并为它们分配一个唯一的、从0开始的短整数ID。Google Guava库的BiMap(双向Map)是实现这种映射的绝佳工具,它能保证Key和Value都是唯一的,并且可以双向查询。
1 | / BiMap<String, Integer> cityMap = HashBiMap.create(); |
存储数字ID: 当需要存储用户地理位置时,我们不再存储字符串,而是存储对应的ID。HSET user:geo:123 city_id 1 district_id 101 street_id 10101
读取时反向映射: 从Redis中读取出ID后,在Java应用层通过**cityMap.inverse().get(1)**来反向查找出对应的字符串“北京市”。
战果分析:
原来存储一个地址可能需要几十上百个字节,现在只需要几个small int(几个字节)即可。内存占用实现了数量级的压缩。
另一个强大的工具:Bitmap和HyperLogLog
- Bitmap: 如果你需要记录用户的签到状态、在线状态等二值信息,Bitmap是无敌的。1亿用户,只需要100,000,000 / 8 / 1024 / 1024 ≈ 12MB内存。
- HyperLogLog: 如果你需要统计一个页面的UV(独立访客数),但不需要精确的数字,HyperLogLog可以用固定的12KB内存,估算出高达2^64个元素的基数,误差率仅为0.81%。
1.6 战术总结:性能的意外之喜
通过以上三大战术,我们成功地在不删除数据的情况下,大幅降低了Redis的内存占用。而这,会带来意想不到的性能提升:
- 更快的RDB快照和AOF重写: Redis生成快照时需要fork一个子进程,这个过程会拷贝父进程的页表。内存占用越小,fork的速度越快,阻塞主进程的时间越短。AOF重写也同理。
- 更快的主从复制: 主从全量同步时,需要传输RDB文件。文件越小,同步速度越快,从库能更快地提供服务。
- 更低的带宽占用: 无论是主从复制还是客户端通信,更小的数据意味着更低的网络带宽消耗。
至此,我们完美地回答了开篇那个“无解”的问题。极限的内存优化,最终会以性能提升的形式,给予我们丰厚的回报。
第二部分:多级缓存架构——为Redis构建“护城河”
2.1 为何需要多级缓存?Redis不是已经够快了吗?
是的,Redis单机QPS可以达到10万。但在秒杀场景下,我们面临一个更棘手的问题——缓存热点(Hotspot Key)。
想象一下,我们秒杀的是iPhone 18。那么,存储其库存的那个Key,seckill:stock:iphone18,会在瞬间被所有请求同时访问。即使你的Redis部署了集群,这个Key根据哈希规则,也只会落在一个**固定的分片(Shard)**上。这意味着,你整个集群的强大处理能力,在这一刻被“降维”到了单个Redis分片的CPU和网络带宽上。这个分片,会成为整个系统的瓶颈,并可能被打垮。
多级缓存,就是为了解决这个问题而生的。它旨在构建一个从应用本地内存 -> 分布式缓存的阶梯式、递减的访问体系,为Redis构建一道坚固的“护城河”。
text请求 -> L1: 本地缓存 (Caffeine) -> L2: 分布式缓存 (Redis) -> L3: 数据库 (MySQL)
目标是让绝大多数对热点Key的读请求,在第一级——最快的本地缓存中就被拦截和响应,从而极大地减轻Redis的压力。

2.2 本地缓存的选择:Caffeine的崛起
在Java世界,提到本地缓存,我们首先会想到ConcurrentHashMap、Google Guava的Cache。但在现代高性能应用中,Caffeine已经成为当之无愧的“本地缓存之王”。
为何是Caffeine?
- 极致的性能: Caffeine在吞吐量和命中率上,全面超越了Guava Cache。
- 智能的淘汰算法:W-TinyLFU。这是Caffeine的“核武器”。传统的LRU(最近最少使用)和LFU(最不经常使用)算法都有明显的缺陷。LRU无法应对偶然的批量数据访问(会污染缓存),而LFU无法快速适应访问模式的变化。W-TinyLFU巧妙地结合了LRU和LFU的优点,通过一个极小的布隆过滤器(Bloom Filter)来记录访问频率,同时保留了对近期访问的敏感性,实现了接近完美的最优页面置换算法的命中率。
2.3 数据一致性的梦魇
引入本地缓存,最大的代价就是数据一致性。当Redis中的库存被扣减后,如何让所有应用实例的本地缓存都感知到这个变化?
解决方案剖析:
- 超时剔除(TTL): 最简单,但一致性最差。给本地缓存设置一个极短的过期时间(如500ms)。优点是简单粗暴,缺点是在过期时间内,数据必然是不一致的。
- 主动更新(Cache-Aside Pattern):
- 读流程: 先读缓存,缓存没有则读DB,读到后再写回缓存。
- 写流程(关键): 先更新DB,再删除Cache。 为什么是删除而不是更新缓存?因为更新缓存的代价更高,而且在复杂的计算场景下,你可能无法直接计算出最新的缓存值。删除,让下一次读请求去重新加载,逻辑更简单。
- 并发下的“脏数据”问题:
线程A更新DB。
线程B在此时读取数据,发现Cache是空的(或旧的),去DB读取到了旧值。
线程A成功更新DB后,删除了Cache。
线程B将它之前读取到的旧值,写入了Cache。此时,Cache中存储的就是一个永远不会过期的脏数据。解决方案通常是延时双删(更新DB -> 删Cache -> 延时一段时间 -> 再次删Cache),但这增加了复杂性。
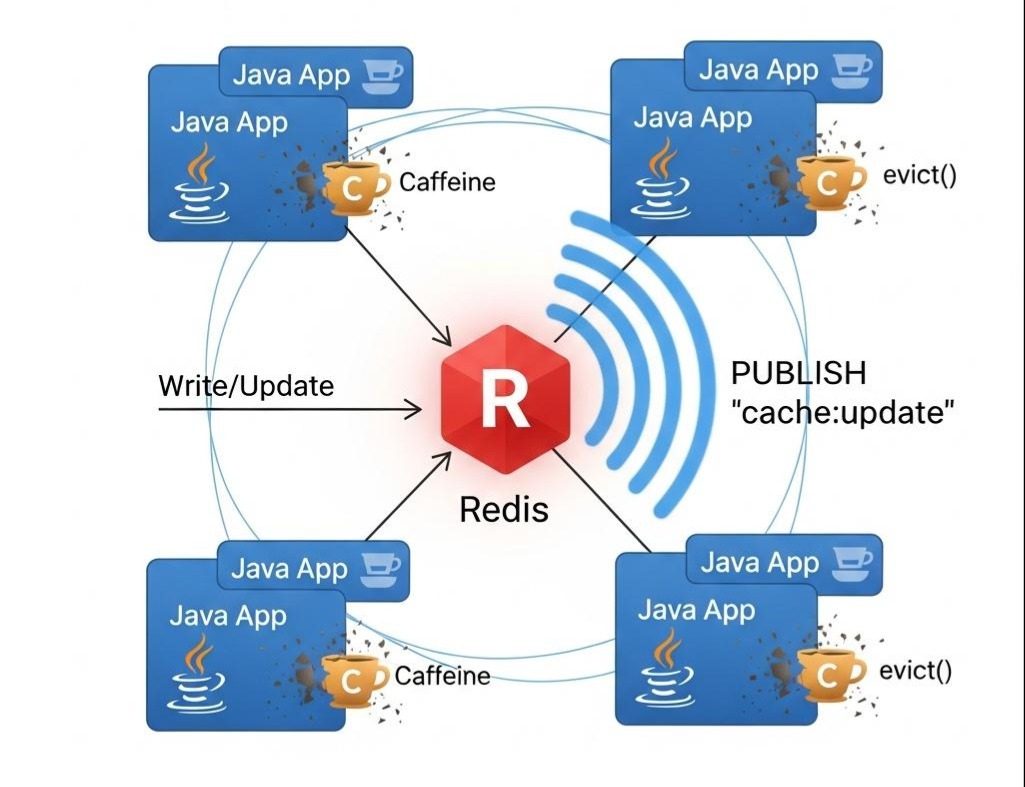
订阅消息(Pub/Sub)——最终一致性的优雅方案(推荐):
- 写流程: 当Seckill-Core服务通过Lua脚本成功扣减了Redis库存后,它额外做一件事:通过Redis的PUBLISH命令,向一个特定的频道(如seckill:stock:update)发布一条消息,内容可以是商品ID。
- 订阅流程: 所有的Java应用实例(Gateway, Core等),都作为订阅者,监听这个频道。
- 失效本地缓存: 当任何一个实例收到这条消息后,它会立即从自己的本地缓存(Caffeine)中,将对应的商品库存信息驱逐(evict)。
这个方案,利用了Redis轻量级的发布/订阅机制,实现了当分布式缓存变更时,对所有本地缓存的主动、精准的失效通知。虽然消息传递有网络延迟,但能达到最终一致性,对于秒杀场景的库存展示,已经足够。
2.4 Java实战:整合Spring Cache与Redis Pub/Sub
Spring的**@Cacheable**等注解为我们提供了声明式的缓存抽象。我们可以利用它来整合Caffeine和Redis。
- 引入依赖 (pom.xml):
1 | <dependency> |
- 配置多级缓存管理器 (CacheConfig.java):
1 |
|
- 实现Redis消息监听器,主动失效本地缓存:
1 |
|
- 在业务代码中使用缓存并发布消息:
1 |
|
通过这套组合,我们构建了一个健壮的、具备最终一致性保证的多级缓存体系,为我们的热点Redis Key,建立起了一道坚固的“护城河”。
第三部分:JUC并发编程——压榨CPU的最后一滴性能
我们的请求经过了层层关卡,抵达了Java应用。应用需要将请求交给一个线程去处理。线程,是CPU执行任务的最小单元。如何管理和调度这些线程,直接决定了我们的应用能否将服务器硬件的“马力”完全发挥出来。
3.1 线程池的“灵魂拷问”:秒杀场景,该用什么线程池?
谈到Java线程池,很多人的第一反应是Executors工厂类提供的几个静态方法:
- newFixedThreadPool(n): 固定大小的线程池。
- newCachedThreadPool(): 可缓存的线程池,线程数可无限增长。
- newSingleThreadExecutor(): 单线程的线程池。
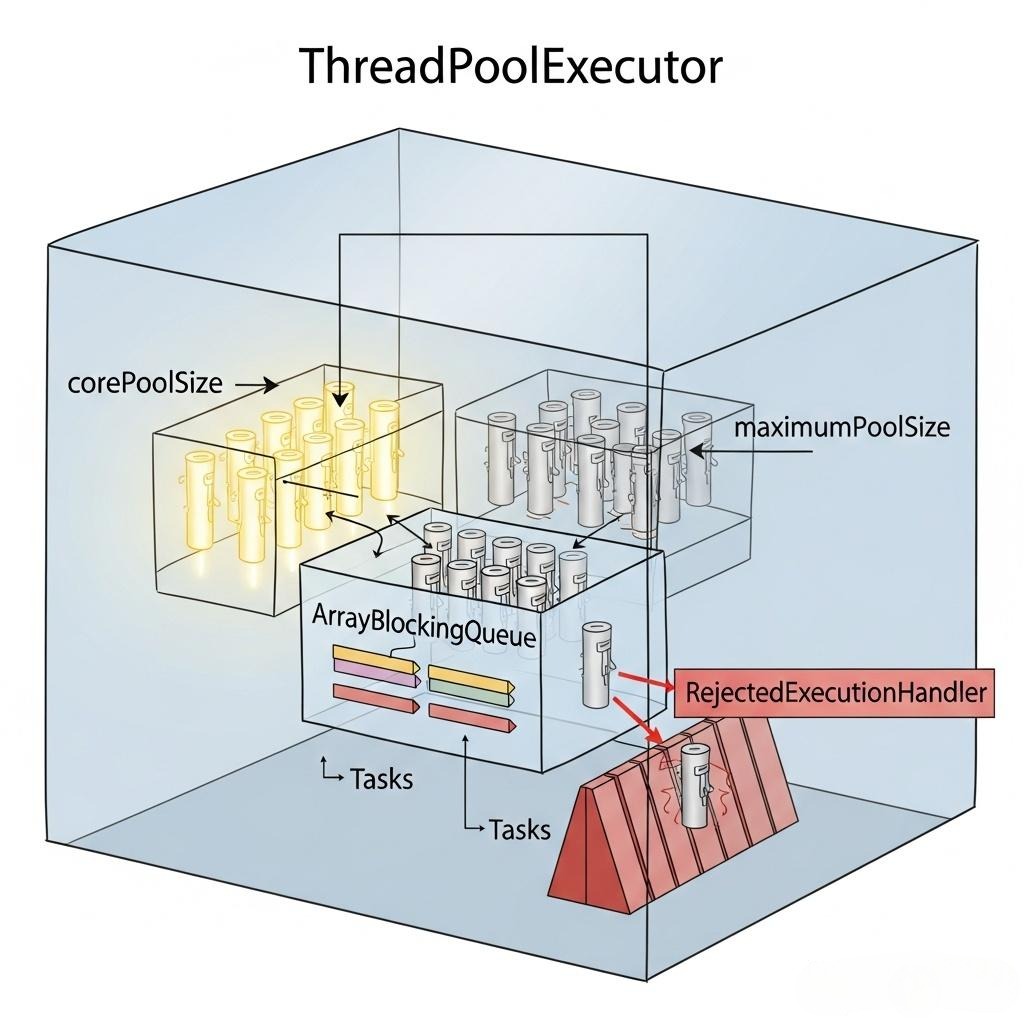
《阿里巴巴Java开发手册》中明确规定:【强制】不允许使用Executors去创建线程池,而是通过ThreadPoolExecutor的方式。
为什么?
- newFixedThreadPool和newSingleThreadExecutor:其内部的阻塞队列是LinkedBlockingQueue,且默认构造函数的容量是Integer.MAX_VALUE。这意味着,如果请求处理速度跟不上提交速度,任务会无限地堆积在队列中,最终可能导致OOM(内存溢出)。
- newCachedThreadPool:其maximumPoolSize是Integer.MAX_VALUE。如果请求洪峰到来,它会疯狂地创建新线程,最终可能因为创建过多线程而耗尽系统资源,同样导致OOM或系统僵死。
结论: 我们必须手动创建ThreadPoolExecutor,将所有参数的控制权都掌握在自己手中。
1 | // ThreadPoolExecutor的完整构造函数 |
秒杀场景下的“反常识”配置思考:
秒杀请求的核心逻辑是“访问Redis -> 发送MQ”,这是一个典型的I/O密集型任务,而不是CPU密集型。CPU在大部分时间里,都在等待网络I/O的返回。
- 传统CPU密集型任务(如计算圆周率): 线程池大小通常设置为CPU核心数 + 1,以减少线程上下文切换。
- I/O密集型任务: 为了让CPU在等待I/O时不闲着,我们需要创建远超CPU核心数的线程。一个经验公式是:线程数 = CPU核心数 * (1 + 平均等待时间 / 平均计算时间)。
阻塞队列的选择:
- ArrayBlockingQueue (有界队列): 这是秒杀场景下的首选。它有一个明确的容量,当队列满了之后,新任务的提交会触发拒绝策略。这相当于在应用内部设置了一个“熔断开关”,防止无限的任务堆积压垮系统。
- SynchronousQueue (同步队列): 一个不存储元素的队列。它要求一个put操作必须等待一个take操作。newCachedThreadPool就使用它。它非常适合那些需要“快速处理,否则就快速创建新线程”的场景,但对于需要排队的秒杀场景,并不合适。
一个为秒杀场景定制的线程池Bean:
1 |
|
3.2 动态线程池的艺术
上面的配置,依然是“静态”的。我们无法预知秒杀当天的真实流量到底有多大。如果流量远超预期,2000的队列容量可能很快被占满,触发拒绝策略,影响用户体验。
核心思想: 线程池的核心参数,应该像Sentinel的规则一样,是可动态调整的。
实战方案:引入开源动态线程池框架
社区中已经有非常成熟的开源项目,如美团的Dynamic-TP、Hippo-Dynamic-Threadpool等。它们的核心原理是:
- 应用内嵌Agent: 在应用中引入框架的starter。
- 对接配置中心: 框架会监听Nacos、Apollo等配置中心。
- 参数动态刷新: 当你在配置中心修改了某个线程池的corePoolSize或队列容量时,框架能通过Java的反射和JMX等技术,在不重启应用的情况下,动态地更新ThreadPoolExecutor实例的内部参数。
- 监控与告警: 框架通常会集成Micrometer,将线程池的活跃线程数、队列大小、任务拒绝数等关键指标暴露给Prometheus,并支持配置告警规则(如“队列使用率超过80%时发送钉钉告警”)。
调优策略:
- 日常模式: 将corePoolSize设置为一个较低的值(如10),maximumPoolSize设置为20,以节省资源。
- 秒杀前(通过预案或手动触发): 在Nacos上修改配置,将corePoolSize调大到50,maximumPoolSize调大到100,队列容量调大到5000,以应对即将到来的洪峰。
- 秒杀后: 再将其调回日常模式。
这赋予了我们前所未有的、对应用内部并发模型的实时、精细的管控能力。
3.3 虚拟线程的曙光(Project Loom)
我们之前所有的努力,都是在“优化”传统内核线程(Kernel Thread)模型带来的瓶颈。一个内核线程,对应一个操作系统线程,它的创建和上下文切换是“重”的。
而Java 19开始正式预览,并在Java 21中成为正式功能的虚拟线程(Virtual Threads),将从根本上颠覆这一切。
- 核心:M:N模型。 Loom将大量的(M个)虚拟线程,映射到少量的(N个)平台线程(即内核线程)上执行。
- “轻如鸿毛”: 一个虚拟线程,不再是一个完整的操作系统线程,而只是一个JVM内部管理的对象。它的创建和切换成本极低,我们可以轻松地创建数百万个虚拟线程。
- 阻塞不再可怕: 当一个虚拟线程执行I/O操作(如读写Socket)而被阻塞时,它所占用的平台线程会被JVM自动释放,去执行其他可运行的虚拟线程。当I/O完成后,JVM会再为这个虚拟线程分配一个平台线程来继续执行。
对秒杀架构的颠覆性影响:
在未来,我们可能不再需要费尽心思地配置复杂的异步回调、响应式编程(Reactor/WebFlux),甚至不再需要为I/O密集型任务精细调整线程池。我们的代码可以回归到最简单、最直观的同步阻塞式写法:
1 | // 在虚拟线程环境下,这段同步代码将具备极高的并发能力 |
这段代码,在传统的线程池模型下,会因为创建过多线程而瞬间崩溃。但在虚拟线程的世界里,它可以优雅地运行。
结论: 虚拟线程,是Java并发编程的未来。作为架构师,我们必须密切关注它的发展,因为它将极大地简化我们的高并发系统设计,让我们能用更简单、更符合人类直觉的代码,去实现更高的性能。
结语:从“用好”到“榨干”,在微观世界中决胜
在本章超过一万六千字的极限压榨中,我们深入了秒杀架构的两个核心“内存战场”:分布式内存(Redis)和本地内存(JVM/JUC)。
我们不再满足于仅仅“用好”这些工具,而是追求将它们的潜力“榨干”:
- 在Redis战场,我们像一个吝啬的“空间魔术师”,通过深入ziplist、listpack等底层数据结构,结合数据分片和编码降维,成功地在不增加成本的前提下,实现了“让1GB当2GB用”的魔法,并意外地收获了性能的提升。
- 在多级缓存的设计中,我们为Redis构建了坚固的“护城河”,并利用Redis Pub/Sub和Spring Cache,优雅地解决了业界难题——分布式环境下的缓存一致性。
- 在JUC并发战场,我们跳出了Executors的“舒适区”,挑战了传统的线程池配置思维,学会了如何为I/O密集型的秒杀场景量身定做线程池,并通过动态线程池技术,赋予了系统实时“变形”的能力。
- 最后,我们展望了虚拟线程的未来,看到了Java并发编程即将迎来的、更简单、更强大的曙光。
对微观世界的极致追求,是区分卓越架构师与优秀工程师的最后一道分水岭。它要求我们不仅要懂架构,更要懂代码、懂底层、懂算法。因为真正的性能瓶颈,往往就隐藏在那些我们习以为常的“黑盒”之中。
至此,我们的“雷神之锤”系统,在理论、架构、实现、优化等各个层面,都已达到了一个相当高的水准。是时候让它接受最残酷的实战检验了。
在下一篇章 《终极试炼:全链路压测与混沌工程——为系统注入“反脆弱”的基因》 中,我们将扮演“破坏者”和“考核官”。我们将学习如何设计科学的压测方案,找到系统的真实瓶颈;并主动向我们亲手构建的系统中注入故障,检验它的稳定性、弹性和恢复能力。这将是整个系列中最惊心动魄,也是最有价值的一章。

