百万架构师成长之路(22):【终极实战篇·终章】终极试炼:全链路压测与混沌工程——为系统注入“反脆弱”的基因
导语:从“祈祷它能工作”到“确信它不会失败”
经过数月的精心设计与极限优化,我们的“雷神之锤”秒杀系统,已经从一张蓝图,变成了一套部署在云端的、由数十个微服务组成的复杂生命体。它拥有了坚固的外部防御、流畅的核心流程、经过深度优化的数据存储和高效的并发模型。
在上线前的最后一次架构评审会上,你向CTO和所有相关方,自信地展示了这套堪称艺术品的架构。
“…我们的系统,理论上可以承受百万QPS的入口流量,核心下单链路的P99延迟在50ms以内,并且通过多级缓存和异步解耦,保证了数据库的绝对安全…”
在你汇报结束时,CTO点了点头,然后提出了那个所有架构师都必须回答的终极问题:
“理论上?你怎么证明?你怎么让我相信,在双十一那天凌晨,当真实的、混乱的、不可预测的流量洪峰涌来时,你这套完美的‘理论’不会像纸糊的城堡一样,一触即溃?”
这个问题,直击灵魂。它标志着架构师工作的下半场——验证——的开始。上半场,我们追求的是“构建正确(Build it Right)”;下半场,我们必须证明我们“构建的是正确的系统(Build the Right System)”。
从“祈祷它能工作(Hope it works)”到“确信它不会失败(Know it won’t fail)”,这中间隔着的,就是本章将要深入探讨的两大“黑魔法”:
全链路压测(Full-Link Stress Testing): 如同在F1赛车上赛道前,对其进行的极限风洞测试和赛道模拟。我们用远超预期的模拟流量,去主动寻找系统的性能瓶颈和容量拐点。
混沌工程(Chaos Engineering): 如同为身经百战的特种兵注射疫苗。我们不再被动地等待故障发生,而是主动地、有控制地在生产环境中注入真实的故障,以检验系统的弹性和自我修复能力,将“未知”的弱点,转化为“已知”的、可被修复的缺陷。
本篇,我们将扮演“首席压力官”和“首席破坏官”,为“雷神之锤”系统组织一场最残酷的“毕业典礼”。这将是一场从代码自信到工程自信的终极跃迁。
第一部分:全链路压测——科学地寻找“第一块倒下的多米诺骨牌”
1.1 压测的“心法”:我们到底在测什么?

压测的目的绝不仅仅是得出一个“我们系统能抗2万QPS”的虚荣数字。它是一场科学的实验,核心目标有三:
- 容量规划(Capacity Planning): 摸清系统在当前硬件配置下的极限容量。例如,单个Seckill-Core实例最优QPS是多少?需要部署多少个实例才能满足10万QPS的下单目标?
- 发现性能瓶颈(Bottleneck Discovery): 在高压下,系统中最先达到饱和的资源(CPU、内存、网络、I/O、连接池等)就是瓶颈。压测的使命,就是找到这块“最短的木板”。
- 验证系统稳定性(Stability Verification): 在长时间的高压下(如持续1小时),系统是否存在内存泄漏、连接池泄露、响应时间逐渐变长等问题。
反模式批判:
- 只压单个接口: 这是最常见的错误。一个真实的秒杀场景,流量是混合的。只压order接口,无法体现getItemInfo等读接口对缓存、带宽的占用,也无法反映真实的用户行为模式。
- 不带think time的压测: 真实用户在操作之间会有思考和停顿。如果压测脚本以程序的最大速率循环请求,会产生远超真实的、不切实际的瞬时压力,得出的结论毫无意义。
- 压测数据不隔离: 用生产数据进行压测,会产生大量垃圾数据,污染生产环境。
1.2 压测环境的“洁癖”

一个可靠的压测,必须在一个“干净”的环境中进行。最佳实践是:
- 1:1生产环境克隆: 压测环境的硬件配置、网络拓扑、软件版本、操作系统参数,都必须与生产环境完全一致。
- 数据脱敏与模拟: 将生产数据进行脱敏后,导入到压测环境的数据库中。并且,你需要编写脚本,模拟出与生产环境相似的数据量和数据分布。这是一个庞大但必要的前置工作。
- 影子库/影子表方案: 更高级的做法是,在压测流量的请求头中加入一个特殊标记(如X-Test-Traffic: true)。当请求在链路中传递时,所有微服务都能识别这个标记,并将其对数据库的读写操作,路由到一个专门的“影子库”或“影子表”中,从而实现压测流量与真实流量在同一套环境中运行,但数据相互隔离。
1.3 压测工具的选择:k6的崛起
- JMeter: 老牌王者,功能全面,生态丰富。但其基于Java Swing的UI和多线程模型,在单机上能产生的压力有限,且资源消耗巨大。
- k6: Go语言编写,为性能而生。单机能轻松产生数万甚至数十万的虚拟用户和RPS(每秒请求数)。其脚本用JavaScript编写,语法现代,支持模块化,并且与Grafana、Prometheus等云原生工具有着天然的集成。
我们的选择: k6。因为它代表了现代压测工具的方向——高性能、可编程、云原生。
1.4 压测方案设计与脚本实战
1. 压测场景定义:
- 场景A (基准压测): 单独对Seckill-Core服务的deductStock接口进行压测,摸清单个服务实例的性能天花板。
- 场景B (混合场景压测): 模拟真实的用户旅程。
- 80%的用户:只刷新商品详情页(请求静态资源)。
- 15%的用户:尝试秒杀但失败(请求被限流或库存不足)。
- 5%的用户:成功完成秒杀并创建订单。
2. 压测模型:阶梯式增压(Stepping-up Load)
我们不采用一次性将压力加到目标值的方式。而是像爬楼梯一样,逐步增加并发用户数(VUs)或RPS,每个阶段持续一段时间,然后观察系统的各项指标。
这种模型的好处是,可以清晰地看到系统在哪个压力水平开始出现性能拐点(响应时间急剧上升,错误率开始出现)。
3. k6脚本实战 (seckill-test.js):
1 | import http from 'k6/http'; |
1.5 压测执行与结果分析
当我们在终端运行k6 run seckill-test.js后,真正的战斗开始了。我们的眼睛,必须像鹰一样,同时盯住k6的输出和Grafana的作战大盘。
瓶颈定位实录:
第一次压测(压力达到1000 VU):
- 现象: k6输出显示P95延迟飙升到800ms,错误率达到10%。Grafana大盘显示,API-Gateway服务的CPU使用率率先达到95%,而下游的Seckill-Core和Order-Service CPU使用率都很低。
- 分析: 压力被网关顶住了。问题出在网关。我们立刻对Gateway的一个实例进行CPU火焰图分析(通过async-profiler等工具)。火焰图显示,jackson.databind.ObjectMapper.writeValueAsString这个方法占据了CPU时间的60%。
- 定位: 网关在请求转发前后,对JSON请求体和响应体进行了序列化和反序列化,这个操作在巨大的流量下,成为了CPU瓶颈。
- 优化: 对于某些透传的请求,在网关层避免不必要的body读写。或者,考虑将JSON序列化库从Jackson更换为性能更好的fastjson或GSON。
第二次压测(优化网关后,压力达到5000 VU):
- 现象: k6输出显示P95延迟依然很高,但错误率很低。Grafana大盘显示,Gateway和Seckill-Core的CPU、RT都很平稳,但RocketMQ Messages Undelivered(消息积压数)这个指标,像火箭一样飙升。
- 分析: 生产速度远大于消费速度。Seckill-Core向MQ扔消息的速度很快,但下游的Order-Service处理不过来。
- 定位: 我们去看Order-Service的监控面板。发现它的CPU不高,但HikariCP Pool Connections Active(数据库连接池活跃连接数)已经达到了配置的最大值。同时,MySQL的慢查询日志中,出现了大量的**INSERT …**语句。
- 优化:
- 增加Order-Service的数据库连接池大小。
- 对Order-Service的消费者逻辑进行优化,将单条INSERT改为批量INSERT,极大地提升数据库写入吞吐量。
- 对t_order表进行分区,降低单表写入的热度。
通过这样一轮轮的“压测 -> 分析 -> 定位 -> 优化”,我们像剥洋葱一样,一层层地揭开系统性能的真相,直到所有的短板都被补齐。
第二部分:混沌工程——在生产环境中“主动放火”
压测,解决了“已知”的性能问题。但混沌工程,是为了应对“未知”的、必然会发生的生产环境故障。

2.1 混沌工程的哲学:拥抱失败,构建“反脆弱”
Nassim Taleb在《反脆弱》一书中提出:有些事物能从冲击中受益,当暴露在波动性、随机性、混乱中时,它们会茁壮成长。这种特性,就是“反脆弱性”。
我们的系统,不应该仅仅是“健壮(Robust)”的——即在压力下保持不变。它应该力求成为“反脆弱”的——每一次经历故障和冲击,都能让它变得更强大、更有弹性。
混沌工程,就是实现“反脆弱性”的工程实践。它不是随意地搞破坏,而是一门科学实验。
2.2 混沌工程的五大原则
- 建立“稳定状态”的假说: 定义一个可量化的、代表系统健康的业务指标。例如,“在正常情况下,系统的下单成功率应大于95%”。
- 在真实世界中进行实验: 实验应尽可能在生产环境中进行,因为只有生产环境的流量和复杂性才是真实的。
- 注入多样化的、真实的故障: 模拟服务器宕机、网络延迟/丢包、磁盘/CPU占满等真实世界会发生的事件。
- 自动化地持续运行实验: 将混沌实验集成到CI/CD流水线中,让它像单元测试一样,成为系统发布的一部分。
- 最小化“爆炸半径”: 实验必须在一个可控的范围内进行。例如,只影响一小部分用户,或者在一个特定的时间窗口进行。如果监控到系统稳定状态被破坏,实验必须能被立即中止。
2.3 工具的选择:Chaos Mesh的崛起
对于运行在Kubernetes上的我们的Java微服务来说,Chaos Mesh是实施混沌工程的不二之选。
- 云原生: 它本身就是为K8s设计的,通过CRD(Custom Resource Definitions)的方式,让你能像管理Pod和Service一样,用YAML文件来“声明”一个故障。
- 故障类型丰富: 支持Pod故障(杀Pod)、网络故障(延迟、丢包、重复、带宽限制)、I/O故障、压力故障(CPU、内存)等。
- 可视化UI: 提供了友好的Web UI来创建和管理实验。
2.4 混沌实验实战:为秒杀系统“注射疫苗”
现在,让我们为“雷神之锤”系统,设计并执行几个关键的混沌实验。
实验一:验证Redis哨兵的高可用切换
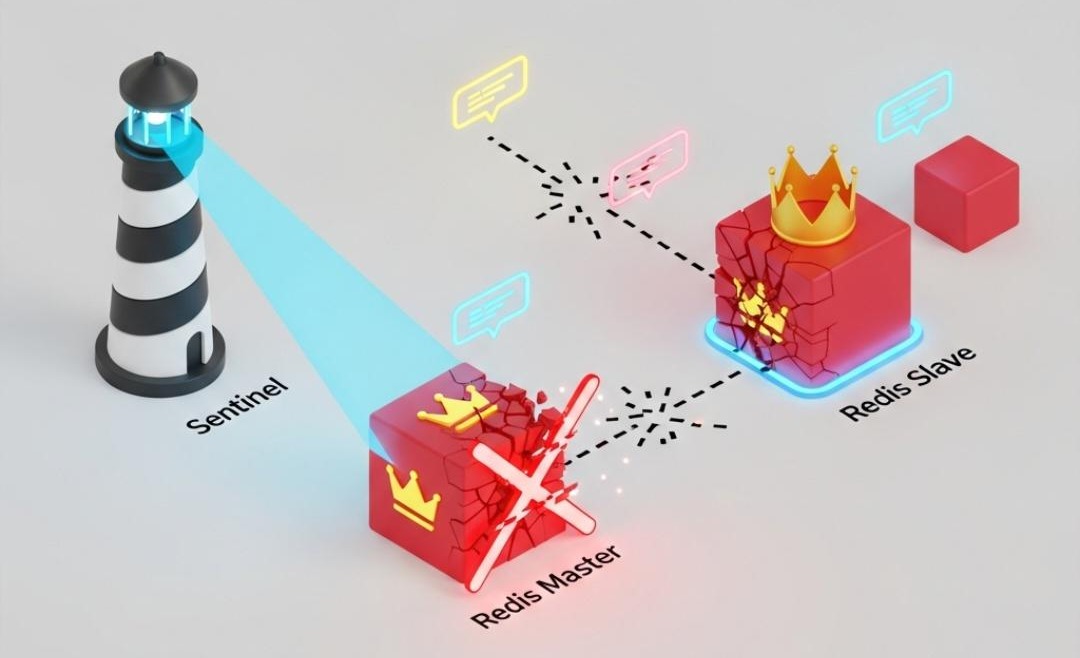
- 假说: 当Redis主节点(Master)被强制杀死后,Redis Sentinel应能在30秒内选举出新的Master。在此期间,秒杀下单请求会失败(因为无法扣减库存),但系统不会崩溃。当新的Master选举成功后,业务应自动恢复。
- 实验步骤:
- 定义稳定状态: 通过Grafana大盘,确认当前秒杀QPS稳定在1000,错误率为0。
- 编写Chaos Mesh YAML (kill-redis-master.yaml):
1 | apiVersion: chaos-mesh.org/v1alpha1 |
- 执行实验: kubectl apply -f kill-redis-master.yaml
- 观测与验证:
- Grafana大盘:
- seckill_error_rate指标立即飙升至100%。
- redis_connected_clients指标瞬间下跌。
- 大约15-25秒后,seckill_error_rate迅速回落至0。
- 日志系统(Kibana): 在故障期间,Seckill-Core的日志中出现大量RedisConnectionException。
- Redis Sentinel日志: 可以看到**+sdown**, +odown, +switch-master等选举过程的日志。
- 结论: 实验成功。验证了我们的Redis高可用方案是有效的。如果切换时间超过预期(如超过1分钟),则说明Sentinel的配置或网络存在问题,需要优化。
实验二:验证Sentinel的熔断降级能力

- 假说: 当Seckill-Core服务所依赖的User-Service(假设用于查询用户风控等级)响应时间变长时,Sentinel应能自动熔断对User-Service的调用,并执行我们预设的fallback逻辑,保证秒杀核心链路不受影响。
- 实验步骤:
定义稳定状态: 秒杀QPS稳定,seckill-core的P99延迟低于50ms。
编写Chaos Mesh YAML (user-service-latency.yaml):
1 | apiVersion: chaos-mesh.org/v1alpha1 |
- 执行实验: kubectl apply -f user-service-latency.yaml
- 观测与验证:
- Sentinel控制台:
- User-Service相关资源的实时监控中,RT曲线立即飙升至300ms以上。
- 很快,该资源的熔断状态从Closed变为Open。
- Seckill-Core的日志: 开始大量出现我们之前在fallback方法中定义的降级日志,例如“调用用户服务熔断,执行默认风控策略”。
- Grafana大盘: 最关键的是,seckill_order_qps和seckill_p99_latency这两个核心业务指标,应保持平稳,不受影响。
- 结论: 实验成功。证明了我们的熔断降级策略是有效的,成功地隔离了下游服务的故障,保证了核心业务的稳定性。
结语:从“建造者”到“守护神”,架构师的终极进化
在本章这趟充满了“破坏”与“重生”的终极试炼中,我们完成了架构师角色的最后一次,也是最重要的一次升华——从一个系统的“建造者”,进化为它最忠诚、也最严苛的“守护神”。

我们不再仅仅满足于纸面上的完美设计,而是用全链路压测这把“探针”,深入到系统的每一个角落,去寻找它在高压下的真实脉搏和脆弱瓶颈。我们学会了用科学的方法去度量、分析、优化,将“我觉得”变成了“数据显示”。
我们更进一步,拥抱了混沌工程这一革命性的思想,从被动地“响应故障”,进化为主动地“管理混乱”。我们像一个经验丰富的医生,通过为系统“注射疫苗”,激发并验证了它的免疫系统——高可用切换、熔断降级、弹性伸缩——是否真的如我们设计般健壮和智能。
经过这场洗礼,“雷神之锤”秒杀系统,对我们来说,不再是一个冰冷的“黑盒”。我们知其然,更知其所以然。我们了解它的极限,洞悉它的弱点,更对它在真实风暴中的表现,拥有了前所未有的确定性和自信。
这,就是架构师工作的闭环。从一个模糊的商业想法开始,经历思想的跃迁、架构的权衡、技术的选型、代码的实现、底层的优化,最终回归到最朴素也最核心的目标——构建一个在真实世界中,能够可靠地、持续地创造商业价值的系统。
《百万架构师成长之路》的实战篇章至此告一段落。但真正的架构师之路,永无终点。它是一场永无止境的、在创造与验证、构建与反思之间的修行。
愿你在这条路上,永远保持好奇,永远拥抱变化,永远敢于向自己亲手构建的世界,挥出那“混沌”的一锤。因为你知道,每一次冲击,都只会让它变得更加坚不可摧。

