百万架构师成长之路(3):深入计算机底层:操作系统与网络如何塑造你的上层建筑
导语:从“应用开发者”到“系统架构师”的最后一块拼图
在成为架构师的旅途中,我们花费了大量时间学习分布式理论、设计模式、云原生技术。我们熟练地使用Spring Cloud构建微服务,用Kubernetes编排容器,用Redis缓存热点数据。我们仿佛成了高层建筑的设计师,在云端之上,挥洒自如地规划着宏伟的蓝图。
然而,一个幽灵般的问题,始终萦绕在我们身边:
为什么我的多线程并发程序,在增加了线程数之后,性能反而急剧下降?
为什么Netty的性能可以比Tomcat高出一个数量级?它们不都是跑在JVM上吗?
为什么我的两个微服务之间,明明网络带宽充足,但RPC调用延迟总是在某个阈值上下剧烈抖动?
为什么我的Docker容器在宿主机上看起来资源充足,但在容器内部却频繁遭遇性能瓶颈?
这些问题的答案,无法在任何一本《微服务实战》或《云原生架构》中找到。它们隐藏在我们日常开发中看似“透明”的、被我们视为理所当然的底层世界里——在CPU的缓存行里,在Linux内核的epoll实现里,在TCP协议栈的状态机里,在Cgroups的资源调度算法里。
99%的上层应用问题,都能在底层找到它的根源。 作为一个应用开发者,你可以暂时忽略它们;但作为一个系统架构师,洞察底层,是你构建稳健、高效、可预测上层建筑的最后一块,也是最关键的一块拼图。
从这一刻起,忘掉你是一个“Java架构师”、“Go架构师”或“业务架构师”。你首先是一个“计算机系统架构师”。你的职责,是打通从应用代码到CPU指令、从HTTP请求到网络包的每一个环节,看到那些别人看不到的“魔鬼细节”。
本篇,就是你深入底层世界的探险地图。我们将从CPU与内存的微观世界出发,穿越I/O模型的演进史,潜入TCP/IP协议栈的深海,最终抵达容器技术的内核基石。这趟旅程,将彻底重塑你对“性能”、“并发”、“网络”和“隔离”的认知。
第一章:CPU与内存的“微观战争”——并发性能的终极战场
我们总以为,并发性能的瓶颈在于锁、在于线程调度。但很多时候,真正的战争,发生在我们看不见的、只有几纳米宽的战场上——CPU与内存之间。
1.1 CPU缓存体系:现代计算机性能的核心秘密
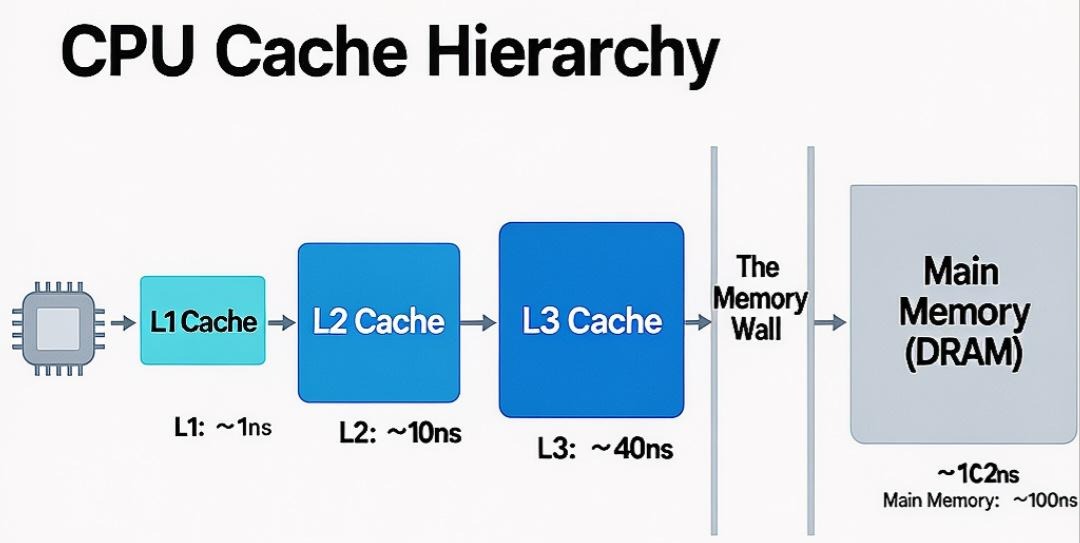
现代CPU的运行速度与主内存(DRAM)的访问速度之间,存在着一道巨大的鸿沟,我们称之为“内存墙(Memory Wall)”。CPU执行一条指令可能只需要不到1纳秒,而一次内存读取,则可能需要50-100纳秒。这意味着,如果CPU每次都需要直接从主内存读取数据,它的绝大部分时间都将处于“饥饿等待”状态。
为了打破这堵墙,计算机科学家设计了一套精密的“缓存体系(Cache Hierarchy)”:
- L1 Cache (一级缓存):位于CPU核心内部,容量极小(几十KB),但速度最快,访问延迟约1-2纳秒,几乎与CPU同速。
- L2 Cache (二级缓存):同样位于CPU核心内部,容量稍大(几百KB到几MB),速度稍慢,访问延迟约10-15纳秒。
- L3 Cache (三级缓存):位于多个CPU核心之间共享,容量更大(几十MB),速度更慢,访问延迟约30-50纳秒。
- 主内存 (Main Memory/DRAM):容量巨大(GB级别),但速度最慢,访问延迟50-100纳秒。
这个体系的工作原理,基于一个核心原则:局部性原理(Principle of Locality)。
- 时间局部性:如果一个数据项被访问了,那么它在不久的将来很可能被再次访问。
- 空间局部性:如果一个数据项被访问了,那么它附近的内存地址上的数据项,也很可能在不久的将来被访问。
当CPU需要读取数据时,它会先在L1缓存中查找,如果未命中(Cache Miss),则去L2查找,再未命中则去L3,最后才去主内存。一旦从主内存中找到了数据,它不会只加载这一个数据项,而是会把这个数据项及其相邻的一块连续内存,一起加载到各级缓存中。这块连续内存的最小单位,就是——缓存行(Cache Line)。
1.2 缓存行与伪共享:并发编程的“隐形杀手”
缓存行(Cache Line)是CPU与主内存之间数据交换的最小单位。 在现代CPU中,一个缓存行的大小通常是64字节。

这意味着,当你程序中读取一个long类型变量(8字节)时,CPU实际上会把包含这个变量在内的、从某个64字节对齐地址开始的整整64字节数据,全部加载到缓存中。
在单线程程序中,这是极大的优化。但在多线程并发程序中,这就埋下了一颗性能炸弹——伪共享(False Sharing)。
伪共享的原理:
想象一个场景,我们有一个Java类:
1 | public class SharedObject { |
我们创建这个类的一个实例 shared,然后创建两个线程:
- 线程1:在一个循环中,只修改 shared.valueA。
- 线程2:在另一个循环中,只修改 shared.valueB。
从代码逻辑上看,这两个线程完全没有竞争,它们操作的是不同的变量。我们期望它们的性能应该很高。但实际运行下来,性能却出奇地差。为什么?
- 内存布局:在内存中,valueA和valueB是连续存储的。由于一个long是8字节,它们俩很可能被分配在同一个缓存行内。例如,一个从地址0x1000开始的64字节缓存行,可能同时包含了valueA和valueB。
- MESI协议:为了保证多核之间缓存的一致性,CPU使用了一种名为MESI(Modified, Exclusive, Shared, Invalid)的缓存一致性协议。简单来说:
- 当一个CPU核心需要修改某个缓存行中的数据时,它必须先获得这个缓存行的独占权(Exclusive/Modified)。
- 为了获得独占权,它必须向其他所有CPU核心广播一个消息,通知它们:“你们都把我这个缓存行设置为无效(Invalid)状态!”
- “乒乓效应” (Cache Line Bouncing):
- 时刻1:线程1在核心1上运行,需要修改valueA。核心1将包含valueA和valueB的缓存行加载进来,并将其状态置为Modified。同时,它通知其他核心(比如核心2)将此缓存行置为Invalid。
- 时刻2:线程2在核心2上运行,需要修改valueB。核心2发现自己本地的缓存行是Invalid的,于是它必须从核心1那里,重新获取这个缓存行的最新数据。
- 时刻3:核心2获取到数据后,将缓存行状态置为Modified,并通知核心1将此缓存行置为Invalid。
- 时刻4:线程1又要修改valueA了,它发现自己的缓存行又变成Invalid了……
看到了吗?尽管两个线程在逻辑上毫无关系,但由于它们操作的数据物理上位于同一个缓存行,导致这个缓存行在两个CPU核心之间,像乒乓球一样来回传递。每一次传递,都伴随着昂贵的总线通信和等待。这就是伪共享,一个由硬件底层机制引发的、在代码层面完全不可见的性能杀手。
如何解决伪共享?——缓存行填充(Cache Line Padding)
解决方案的核心思想是:用空间换时间。 我们通过手动在变量之间填充一些无用的“占位”数据,来强制将它们分开到不同的缓存行中。
1 | public class PaddedSharedObject { |
在Java 8之后,更优雅的方式是使用 @Contended 注解(需要开启JVM参数 -XX:-RestrictContended)。像Java并发包中的ConcurrentHashMap、Disruptor框架中的RingBuffer等高性能组件,都大量运用了这种技术。
架构师的启示:
当你设计一个对性能要求极致的并发数据结构时(例如,交易系统的计数器、实时风控的指标统计),你必须跳出“锁”和“CAS”的思维框架,开始像CPU一样思考。你需要关注数据的内存布局,思考它们在多核环境下,将如何在缓存行中分布。这种深入到硬件层面的优化意识,是通往高性能编程的必经之路。
第二章:I/O模型演进史——从“阻塞”到“异步”,Netty封神之路
网络编程是所有分布式系统的基石。而网络编程的性能,在很大程度上取决于其底层的I/O模型。理解从BIO到NIO,再到AIO的演进史,以及其在Linux内核中的实现原理,是理解一切高性能网络框架(如Netty)的钥匙。
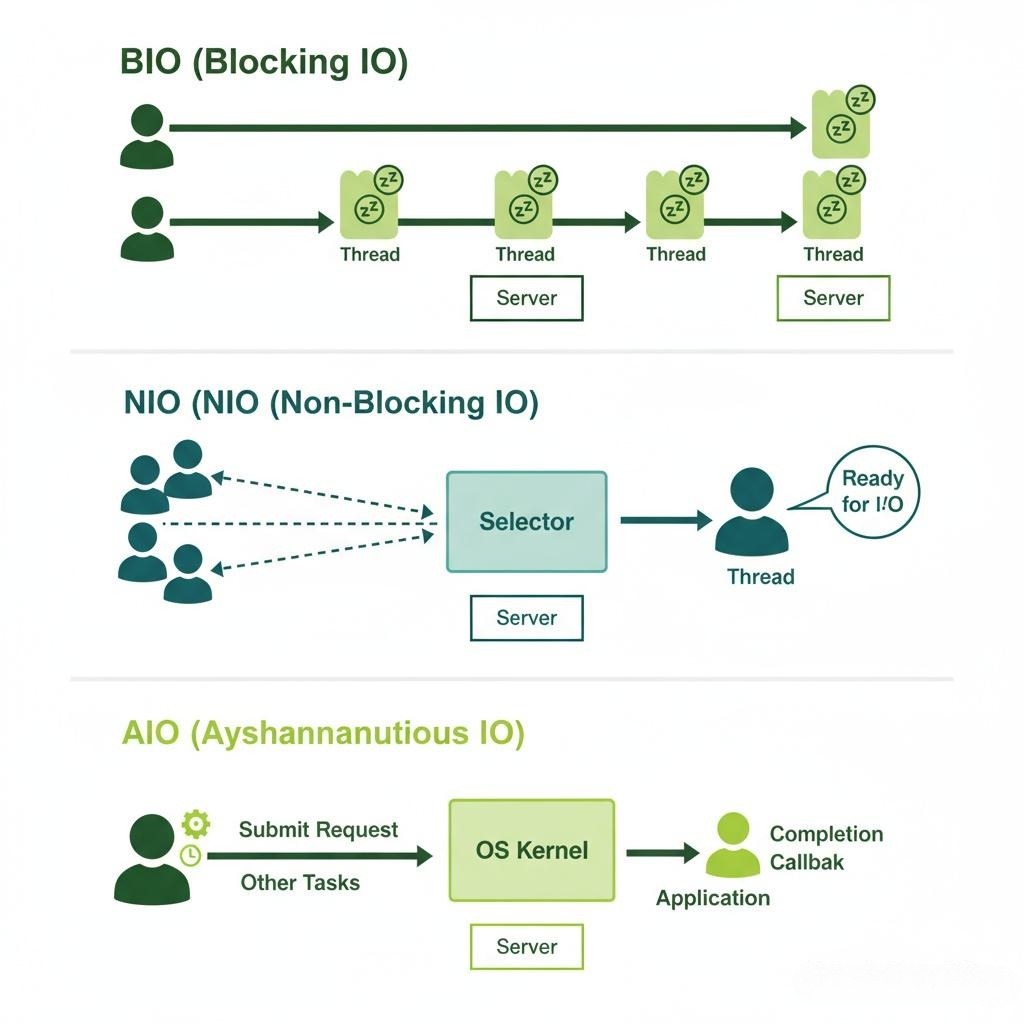
2.1 BIO (Blocking I/O) - “一人一厨”的餐厅
模型:想象一家餐厅,只有一个服务员,也只有一个厨师。服务员接到一个客人的点单后,必须亲自把菜单送到厨房,然后站在厨房门口一直等着,直到厨师把菜做完,再端给客人。在等待的过程中,这个服务员不能做任何其他事情,比如接待新客人或给其他桌倒水。
这就是BIO。服务器为每一个客户端连接,都创建一个新的线程。这个线程在调用read()或write()方法时,会一直阻塞,直到数据准备好或发送完毕。
- 优点:模型简单,代码直观。
- 缺点:极度浪费资源。 一个线程在Java中会占用约1MB的内存,并且线程上下文切换的开销巨大。当连接数达到几百上千时,系统就会因为创建大量线程而崩溃。它适用于连接数非常少的场景。
2.2 NIO (Non-Blocking I/O) / IO Multiplexing - “一人多桌”的服务员
模型:餐厅升级了。现在还是只有一个服务员,但他变得非常聪明。他手里有一个“事件登记本”。
- 当客人A点单时,服务员把菜单交给厨房,然后立即离开,去接待客人B。
- 他会告诉厨师:“菜做好了,在我的登记本上打个勾。”
- 服务员会不断地轮询他的登记本,看哪个客人的菜(事件)好了。
- 当他看到客人A的菜好了,他才去厨房取菜,并送给A。
这就是NIO,也叫I/O多路复用(IO Multiplexing)。这里的核心思想是,用一个线程来管理多个连接(Channel)。这个线程不会阻塞在任何一个**read()或write()**上,而是将所有它感兴趣的Channel注册到一个“选择器(Selector)”上(这就是那个“事件登记本”)。
然后,这个线程会调用selector.select()方法,这个调用是阻塞的,但它阻塞的不是某一个具体的I/O操作,而是等待“任何一个”已注册的Channel上发生I/O事件。一旦有事件发生,**select()**方法就会返回,然后线程就可以去处理那些已经“就绪”的Channel。
Linux内核的实现:select -> poll -> epoll
- select:最早的实现。它需要拷贝整个文件描述符集合到内核空间,并且每次都需要遍历所有文件描述符来查找就绪的,性能随连接数增加而线性下降(O(N))。它还有最大文件描述符数量的限制(通常是1024)。
- poll:解决了select的数量限制问题,但拷贝和遍历的问题依然存在。
- epoll (Event Poll):Linux上的革命性升级,也是NIO性能的真正基石。
- 内核/用户空间共享内存:通过epoll_create创建一个epoll实例时,内核会开辟一块共享内存区域,用于存放文件描述符。epoll_ctl进行注册时,不再是每次都全量拷贝,而是增量添加。
- 事件驱动:epoll不再需要轮询。当一个socket上的数据准备好时,内核会通过回调机制,主动将这个socket加入到一个“就绪队列”中。
- 直接返回就绪列表:当用户进程调用epoll_wait时,内核只需要检查这个“就绪队列”是否为空。如果不为空,就直接返回这个队列的内容。其时间复杂度是O(1),与监听的总连接数无关!
2.3 AIO (Asynchronous I/O) - “外卖平台”模式
模型:餐厅再次升级,接入了外卖平台。现在,服务员接到点单后,把菜单交给厨房,然后就彻底不管了,继续做自己的事。厨房做好菜后,不是通知服务员,而是直接通知外卖小哥。由外卖小哥负责取餐和配送。当配送完成后,外卖小哥会反过来通知服务员:“A客人的订单已完成”。
这就是AIO(异步I/O)。用户进程发起一个I/O操作后,立即返回,不用等待任何结果。当I/O操作真正完成时,由操作系统(外卖平台)来回调用户进程预先注册好的回调函数。
- 与NIO的区别:NIO是“我问你好了没”(用户进程调用select去问内核),是同步非阻塞的。AIO是“你好了再告诉我”(内核主动通知用户进程),是真正的异步非阻塞。
- AIO的困境:听起来很完美,但AIO在Linux上一直没有得到很好的支持。Linux上的原生AIO(libaio)有很多限制,主要用于数据库等场景。而基于epoll模拟的AIO,在性能上并没有比NIO有本质的优势。因此,在网络编程领域,NIO(基于epoll)仍然是事实上的王者。
2.4 Netty为何封神?——对NIO的极致封装与优化
Netty本身并没有发明新的I/O模型,它的伟大之处在于,将极其复杂、易错的Java NIO API,封装成了一个极其优雅、高性能、可扩展的框架。
- 主从Reactor模式:Netty经典的线程模型。一个BossGroup(主Reactor)只负责处理客户端的accept事件,一旦连接建立,就将这个连接(Channel)扔给WorkerGroup(从Reactor)。WorkerGroup中的EventLoop负责处理该Channel上所有的读写和业务逻辑。这种职责分离,使得accept操作不会被耗时的I/O操作所阻塞。
- 零拷贝(Zero-Copy):在数据传输过程中,最大限度地避免CPU将数据在内核缓冲区和用户缓冲区之间来回拷贝。Netty通过CompositeByteBuf、FileRegion等技术,以及对操作系统sendfile系统调用的封装,实现了多种形式的零拷贝。
- 内存池化与对象池化:为了避免高并发下频繁创建和销毁ByteBuf对象带来的GC压力,Netty设计了高效的内存池(基于jemalloc思想)。同时,对内部使用的许多对象也进行了池化复用。
- 无锁化设计:在关键路径上,Netty大量采用CAS操作和线程绑定(即将一个Channel的所有操作都绑定在一个固定的EventLoop线程上),避免了使用重量级的锁。
架构师的启示:
当你选择一个网络框架或RPC框架时,不要只看它的API是否友好。你必须深入一层,去审视它的线程模型、I/O模型以及内存管理方式。一个基于BIO的框架,无论上层API如何封装,其性能天花板都是极低的。而Netty的成功告诉我们,真正的性能优化,往往来自于对底层操作系统机制的深刻理解和极致利用。
第三章:TCP/IP协议栈的“魔鬼细节”——微服务通信的隐形枷锁
我们每天都在使用HTTP、RPC进行微服务通信,但我们往往忽略了,这些上层协议都构建在TCP/IP这个看似可靠的基座之上。然而,TCP的“可靠”,是靠一系列复杂的、动态的机制换来的。这些机制,正是影响你微服务通信性能的“魔鬼”。

3.1 TCP三次握手与SYN Flood攻击
- 三次握手:客户端SYN -> 服务端SYN+ACK -> 客户端ACK。这个过程是为了**同步双方的初始序列号(ISN)**并确认双方的收发能力都正常。
- 半连接队列(SYN Queue):当服务端收到客户端的SYN包后,会将这个连接信息放入一个队列,并进入SYN_RECV状态。这个连接此时是“半开”的。
- SYN Flood攻击:攻击者伪造大量源IP,向服务器发送海量的SYN包,但就是不发送第三次的ACK。这会导致服务器的半连接队列被迅速占满,无法再接受任何新的正常连接,造成服务不可用。
- 架构师的防御:
- 调整内核参数net.ipv4.tcp_max_syn_backlog,增大半连接队列的长度。
- 开启net.ipv4.tcp_syncookies,当半连接队列满了之后,服务器不再将连接信息放入队列,而是通过一个特殊的算法(基于源IP、端口、时间戳等)计算出一个“cookie”作为序列号发送给客户端。如果收到客户端后续的ACK,再通过这个cookie反向校验其合法性。
- 在网络边界(如WAF、防火墙)上部署专业的DDoS防护策略。
3.2 Nagle算法与延迟ACK:一对“好心办坏事”的组合
- Nagle算法:为了防止网络中出现大量的小数据包(例如,你在telnet里每敲一个字母就发一个包),TCP默认开启了Nagle算法。它的逻辑是:当一个连接上有“已发送但未被确认”的数据时,后续的小数据包会被缓存起来,直到收到前一个数据的ACK,或者缓存的数据达到一个MSS(最大报文段长度)时,再一起发送。
- 延迟ACK (Delayed ACK):为了提高效率,TCP接收方在收到数据后,不会立即发送ACK,而是会等待一小段时间(例如200ms),看是否能捎带上自己要发送的数据一起回传,或者是否有后续的数据包一起到达,可以合并ACK。
- 致命的组合:想象一个“请求-响应”式的RPC调用。
- 客户端发送一个小的请求包(例如几十字节)。
- 根据Nagle算法,客户端在收到服务端的ACK前,不会发送第二个请求。
- 服务端收到了请求包,并迅速处理完,准备返回一个小的响应包。
- 但根据延迟ACK,服务端不会立即为收到的请求包发送ACK,它会等待200ms。
- 客户端因为迟迟收不到ACK,也不会发送下一个请求。
- 结果:整个RPC调用的延迟,被人为地增加了200ms!
- 解决方案:对于延迟敏感的RPC通信场景,必须通过TCP_NODELAY这个socket选项,禁用Nagle算法。几乎所有的RPC框架(如Dubbo, gRPC)都默认禁用了它。
3.3 TCP拥塞控制:慢启动、拥塞避免、快速重传
TCP被设计用于一个不可靠的、带宽未知的广域网。它的核心哲学是“小心翼翼地试探,知错就改”。
- 慢启动(Slow Start):连接刚建立时,TCP不知道网络的容量有多大。它会以一个很小的“拥塞窗口(cwnd)”开始发送数据(例如1-10个MSS)。每收到一个ACK,cwnd就指数级增长(翻倍)。
- 拥塞避免(Congestion Avoidance):当cwnd增长到一个“慢启动阈值(ssthresh)”后,指数增长就停止了,变为线性增长(每个RTT增加一个MSS)。
- 丢包与重传:当发生丢包时(通过超时或者收到3个重复ACK判断),TCP认为网络发生了拥塞。
- 它会将ssthresh降为当前cwnd的一半。
- cwnd会骤降回1,重新开始慢启动(对于超时重传)或者降为ssthresh(对于快速重传)。
对微服务通信的影响:
在数据中心内部,网络通常是稳定且高速的。但TCP的这套“保守”的拥塞控制机制,对于短连接、突发流量的微服务调用来说,可能非常不友好。
- 一个RPC调用可能只需要传输几KB的数据,但由于慢启动,连接刚建立时,发送速率被严重限制,可能还没达到网络带宽的上限,整个调用就结束了。
- 数据中心内部的瞬时抖动(例如交换机缓冲区溢出)也可能导致丢包,这会被TCP误判为严重的网络拥塞,导致传输速率急剧下降,造成服务间的“雪崩”。
3.4 QUIC协议(HTTP/3)的革命
QUIC(Quick UDP Internet Connections)协议,是Google为了解决TCP的这些“历史包袱”而设计的,它现在是HTTP/3的底层传输协议。
- 基于UDP:QUIC抛弃了TCP,直接构建在不可靠的UDP之上。这意味着,拥塞控制、可靠传输、流量控制等逻辑,完全从内核态的TCP协议栈,上移到了用户态的QUIC协议库中。这使得QUIC的算法可以快速迭代和定制。
- 解决了队头阻塞(Head-of-Line Blocking):TCP是基于字节流的,如果一个数据包丢失,后续的所有数据包都必须在接收端缓冲区等待,直到丢失的包被重传回来。而QUIC是基于多个独立的“流(Stream)”的,一个流上的丢包,完全不会影响其他流的数据传输。
- 更快的连接建立:QUIC将传输层(类比TCP)和加密层(TLS)的握手合并了。对于首次连接,只需要1-RTT;对于已有连接,可以实现0-RTT的连接恢复。
架构师的启示:
不要将底层的网络协议视为一个“黑盒”。你的上层应用性能,被这个黑盒的行为模式深深地束缚着。
- 在进行服务治理时(如超时设置、重试策略),你必须考虑到TCP的重传和拥塞控制机制。
- 在进行技术选型时,要关注新的网络协议(如QUIC)带来的范式转变。未来,将拥塞控制等逻辑从内核上移到应用层,进行更精细化的定制,将是一个重要的趋势。
第四章:容器技术的底层基石——Linux内核的“障眼法”
容器技术(以Docker和Kubernetes为代表)已经成为现代软件交付的基石。我们享受着它带来的环境一致性、快速部署和弹性伸缩。但作为架构师,你必须看穿容器这层“魔法”的外衣,去理解其底层的内核实现。因为,所有的“隔离”都是相对的,所有的“资源限制”都是有代价的。
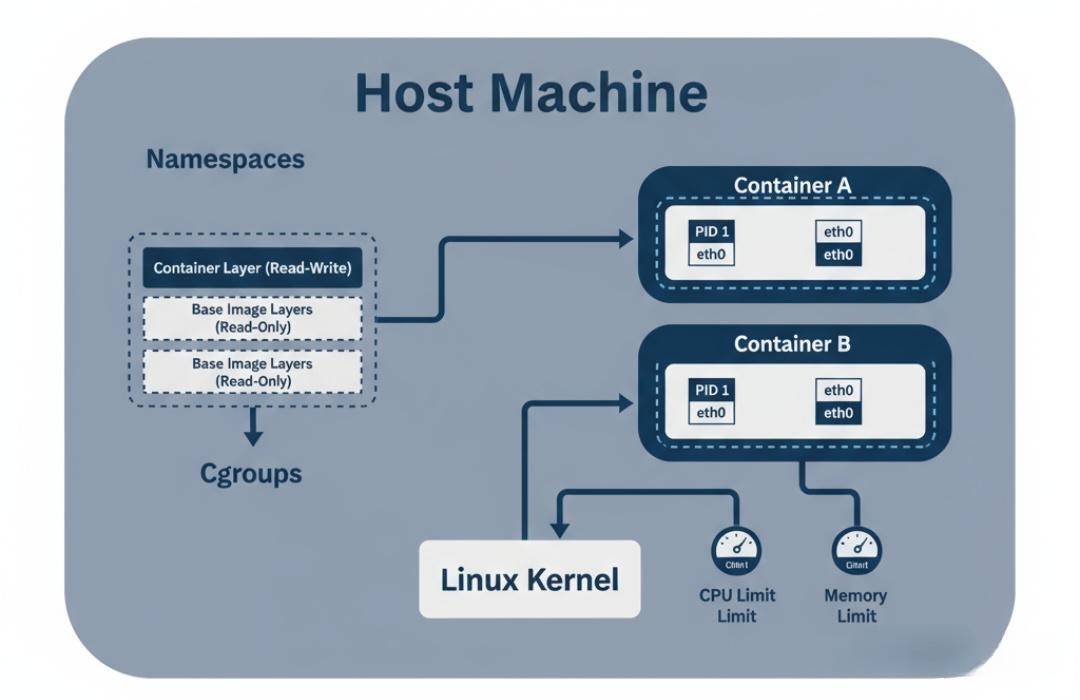
4.1 Namespace - 我“看”不见你:视图的隔离
容器的本质,是进程。当你在一个Docker容器里启动一个Nginx服务时,你可以在宿主机上通过ps命令看到这个Nginx进程。那么,为什么在容器内部,Nginx进程看到的却是一个“干净的”、仿佛独立操作系统的环境呢?(例如,它看到的PID是1,它看不到宿主机上的其他进程)
答案就是Linux Namespace。Namespace是内核提供的一种视图隔离机制。它能让一个进程,仿佛拥有了自己独立的系统资源视图。
- PID Namespace:进程ID隔离。容器内的进程看到的PID是从1开始的,它们看不到宿主机或其他容器的进程。
- NET Namespace:网络隔离。每个容器都拥有自己独立的网络协议栈、IP地址、路由表、端口空间。这就是为什么你可以在同一台宿主机上的不同容器里,都启动一个监听80端口的服务。
- MNT Namespace:文件系统挂载点隔离。容器拥有自己独立的根文件系统(/)。
- UTS Namespace:主机名和域名隔离。
- IPC Namespace:进程间通信隔离。
- User Namespace:用户和用户组ID隔离。
深刻洞察:Namespace并没有创造任何新的物理资源,它只是巧妙地“欺骗”了进程的眼睛,让它以为自己独占了整个世界。这种隔离是逻辑上的,而非物理上的。
4.2 Cgroups - 你的“蛋糕”有多大:资源的限制
如果说Namespace解决了“看不见”的问题,那么Control Groups (Cgroups)就解决了“用多少”的问题。Cgroups是内核提供的另一种机制,它可以限制、记录和隔离一组进程所使用的物理资源。
- CPU Cgroup:
- cpu.shares:按比例分配CPU时间。如果容器A的shares是1024,容器B是512,那么在CPU繁忙时,A获得的CPU时间大约是B的两倍。
- cpu.cfs_period_us 和 cpu.cfs_quota_us:绝对的CPU时间限制。例如,设置period为100ms,quota为50ms,就意味着这个容器每100ms内,最多只能使用50ms的CPU时间,相当于它被限制为只能使用0.5个CPU核心。
- Memory Cgroup:
- memory.limit_in_bytes:硬性限制容器能使用的最大内存量。一旦超过,内核的**OOM Killer (Out Of Memory Killer)**就会介入,杀死容器内的某个进程(通常是占用内存最大的那个),导致容器退出。这是K8s中Pod被OOMKilled的根源。
- Blkio Cgroup:限制对块设备(磁盘)的I/O速率。
- Devices Cgroup:控制容器对哪些设备的访问权限。
架构师的陷阱与思考:
- CPU Throttling (节流):当你为一个容器设置了硬性的CPU limit(通过cfs_quota),即使宿主机CPU非常空闲,这个容器的CPU使用率也无法超过限制。这在高并发、延迟敏感的应用中,可能会导致性能瓶颈。你需要仔细权衡是使用相对的shares还是绝对的limit。
- Memory Overhead:不要将容器的内存limit设置得与JVM的**-Xmx**完全相等。因为除了JVM堆内存,容器内还有其他内存开销(例如,JVM本身的元空间、线程栈、JIT代码缓存,以及应用使用的堆外内存)。通常需要为limit预留10%-25%的额外空间。
- “邻居效应” (Noisy Neighbor):尽管Cgroups可以限制资源,但某些资源的争用是很难被完美隔离的。例如,多个容器对磁盘I/O的疯狂争抢,或者共享L3缓存的争用,都可能导致“吵闹的邻居”问题,即一个行为不佳的容器影响到同一宿主机上的其他容器。这要求我们在进行容器编排和调度时,需要考虑应用的I/O特性和CPU缓存敏感性。
4.3 UnionFS - “层层叠加”的魔法:镜像与容器文件系统
Docker镜像是如何做到如此轻量和可复用的?为什么启动一个容器可以如此之快?答案是联合文件系统(Union File System),如AUFS, OverlayFS。
- 分层存储:一个Docker镜像是由多个只读的“层(Layer)”堆叠而成的。每一层都只记录了相对于上一层的文件变更。
- 写时复制(Copy-on-Write):当你基于一个镜像启动一个容器时,Docker会在只读的镜像层之上,再挂载一个可写的“容器层”。
- 当你需要读取一个文件时,会从上到下,逐层查找,直到找到为止。
- 当你需要修改一个已存在的文件时,UnionFS会触发“写时复制”:它先把这个文件从下方的只读层,复制到最上方的可写容器层,然后再进行修改。
- 当你需要删除一个文件时,并不会真的删除只读层的文件,而是在容器层创建一个“whiteout”标记,表示这个文件“看起来”被删除了。
架构师的启示:
- 优化镜像大小:理解分层存储,可以帮助你构建更小、更高效的镜像。例如,将多个RUN命令合并成一个,可以减少镜像的层数。在一个RUN命令中,先安装编译依赖,编译完后再卸载这些依赖,可以确保这些临时文件不会被带入最终的镜像层。
- 容器内I/O性能:由于写时复制的存在,对容器内大量文件的首次写入,会比原生文件系统有额外的开销。对于I/O密集型应用(如数据库、消息队列),通常建议使用数据卷(Volume),将数据直接挂载到宿主机的文件系统上,绕过UnionFS,以获得最佳性能。
结语:向下扎根,向上生长
我们完成了一次从CPU微架构到容器内核的深度穿越。这趟旅程或许艰辛,充满了陌生的术语和复杂的机制,但它所带来的回报是无与伦比的。
当你能用“缓存行”去解释一个并发性能问题,用“epoll”去论证一个技术选型的优劣,用“TCP拥塞控制”去诊断一个服务间调用的延迟抖动,用“Cgroups”去规划一个集群的资源分配时,你就真正拥有了架构师的“X光视野”。你不再是一个被底层技术“黑盒”所束缚的应用开发者,而是一个能够驾驭整个技术栈、从第一性原理出发去构建系统的系统思想家。
记住,所有上层架构的优雅与自由,都源于你对底层世界规则的深刻理解与敬畏。向下扎根,才能向上生长。

