百万架构师成长之路(4):从InnoDB到NewSQL,架构师的底层数据洞察
导语:告别“黑盒思维”,你与数据系统的“灵魂对话”
在大多数应用开发者的世界里,数据库是一个神奇的“黑盒”。我们通过SQL或ORM框架,向这个黑盒发出指令——INSERT, UPDATE, DELETE, SELECT——然后满怀期待地等待它返回正确的结果。当性能变慢时,我们可能会想到加个索引、优化一下查询语句。然而,我们很少会问:
当我们执行一条UPDATE语句时,数据库内部到底发生了怎样一场惊心动魄的风暴?数据是如何在内存和磁盘之间流转的?
为什么MySQL在面对海量写入时会“力不从心”,而像HBase、Cassandra这样的NoSQL数据库却能从容应对?它们在底层数据结构上到底做了什么不同的选择?
为什么传统的数据库分库分表方案如此痛苦,而像TiDB这样的NewSQL数据库,却能神奇地实现“无限”水平扩展,同时还保持着ACID事务的承诺?
为什么我们的业务数据库(OLTP)处理几千万条数据的聚合查询就可能要花费数分钟,而数据分析平台(OLAP)却能在同样甚至更大数据量上实现亚秒级响应?
这些问题,将“应用开发者”与“系统架构师”清晰地划分开来。前者将数据库视为一个需要学习如何“使用”的工具;而后者,则必须将其视为一个需要深刻“理解”的、有生命的复杂系统。
对数据库的认知深度,直接决定了你数据密集型应用架构的上限。 缺乏这种深度,你的架构设计将永远是脆弱的、凭经验的、无法应对极端场景的。而一旦你拥有了这种洞察力,你就能在技术选型时做出最明智的权衡,在系统出现性能瓶颈时直击要害,甚至能预测到未来业务增长可能遇到的数据挑战。
本篇,就是你开启与数据库系统进行“灵魂对话”的钥匙。我们将从大家最熟悉的InnoDB引擎开始,像法医一样解剖它的内部机制。然后,我们将进入B-Tree与LSM-Tree的史诗对决,理解OLTP与大数据存储的核心分野。接着,我们将探索NewSQL的星辰大海,看它是如何试图“统一”这个分裂的世界。最后,我们将揭开OLAP数据库“快如闪电”的秘密。
这不仅是一次技术的深度潜航,更是一次关于数据系统设计哲学的思想盛宴。
第一章:InnoDB的“封神之路”——关系型数据库的现代心脏
MySQL之所以能成为世界上最流行的开源关系型数据库,InnoDB存储引擎居功至伟。它以其对ACID事务的良好支持、崩溃恢复能力和出色的并发性能,成为了事实上的标准。理解InnoDB,是理解所有现代OLTP(在线事务处理)数据库的基石。
1.1 B+树索引:海量数据下的“O(logN)”奇迹

我们都知道索引能加速查询,但为什么快?尤其是,为什么在面对亿万行数据时,它依然能将查询锁定在几次磁盘I/O内?答案就是B+树。
- 为什么不是二叉搜索树或AVL树?
- 在数据库中,数据存储在磁盘上。磁盘I/O的成本极高(毫秒级),远高于内存操作(纳秒级)。
- 数据库索引设计的核心目标是:尽可能减少磁盘I/O的次数。
- 二叉树的“深度”太深了。一个存储了N个节点的平衡二叉树,其深度约为log2(N)。如果N是1亿,深度约为27。在最坏情况下,一次查询可能需要27次磁盘I/O,这是无法接受的。
- B+树的“降维打击”:
- “矮胖”的结构:B+树不是二叉的,而是“多叉”的。一个节点可以存储成百上千个“键值-指针”对。这使得树的高度被极大地压缩了。通常,一个高度为3-4层的B+树,就已经可以存储亿级别的数据。
- 数据只在叶子节点:与B树不同,B+树的非叶子节点只存储索引键值和指向下一层节点的指针,不存储任何行数据。这使得每个非叶子节点可以容纳更多的索引项,进一步降低了树的高度。
- 叶子节点双向链表:所有的叶子节点通过一个双向链表连接起来。这对于范围查询(如 WHERE id > 100)是巨大的优化。一旦定位到id=100的叶子节点,就可以通过链表指针,顺序地向后扫描,而无需再从树的根节点开始一次次地查找。
InnoDB的索引实现:
- 聚簇索引(Clustered Index):InnoDB的表本身就是按照主键组织的一棵B+树。叶子节点存储了完整的行数据。 因此,一张表只能有一个聚簇索引。这也是为什么按主键查询速度最快的原因,因为它不需要回表。
- 二级索引(Secondary Index):我们为其他列创建的索引。其叶子节点存储的不是行数据,而是该行数据对应的主键值。当通过二级索引查询时,需要先在二级索引树中找到主键,然后再拿着主键去聚簇索引树中查找完整的行数据。这个过程,就叫做“回表(Covering Index)”。
1.2 MVCC:无锁读的魔法——多版本并发控制
在大多数应用中,“读”操作的频率远高于“写”。如何让读写操作互不阻塞,是并发性能的关键。InnoDB通过MVCC(Multi-Version Concurrency Control),巧妙地实现了这一点。
- 核心思想:为每一行数据,保留多个历史版本。当一个读事务开始时,它只能看到在它启动之前,就已经提交了的事务所做的修改。
- 三大组件:
- 隐藏列:InnoDB会为每行数据,自动添加两个隐藏列:DB_TRX_ID(创建或最后修改该版本的事务ID)和DB_ROLL_PTR(指向该行上一个版本的Undo Log的指针)。
- Undo Log(回滚日志):当一个事务需要修改一行数据时,它会先把这行数据的旧版本,写入到一个叫做Undo Log的地方。DB_ROLL_PTR就指向这个旧版本。这样,一行数据就通过DB_ROLL_PTR,串成了一个版本链。
- Read View(读视图):当一个读事务(SELECT)开始时,它会创建一个“Read View”。这个Read View本质上是一个快照,记录了在这一刻,数据库中所有活跃的(未提交的)事务ID列表。
- “所见即所得”的规则:当这个读事务去读取某一行数据时,它会沿着版本链,从最新版本开始,逐个检查:
- 这个版本的DB_TRX_ID,是否在我创建Read View时,就已经存在于“活跃事务列表”中了?
- 如果是,说明这个版本是我“不应该”看到的(因为它是在我之后才开始修改,或者在我开始时还未提交)。于是,它会顺着DB_ROLL_PTR,去找上一个版本,继续这个判断。
- 直到找到一个它“应该”看到的版本为止。
深刻洞察:MVCC的精髓,在于用“额外的空间(Undo Log)”和“少量的计算(版本链遍历)”,换取了“读-写”操作之间的无锁并发。这也是为什么在InnoDB中,“快照读”(普通的SELECT)是如此之快,因为它不需要等待任何写操作的锁释放。
1.3 Buffer Pool, Redo/Undo Log:一条Update语句的奇幻漂流
我们现在来完整地追踪一条UPDATE语句在InnoDB内部的生命周期,这将串联起InnoDB所有核心组件。
UPDATE users SET name = ‘B’ WHERE id = 1; (假设name原来是’A’)

- 进入Buffer Pool(内存):
- InnoDB首先会去Buffer Pool(一块巨大的内存缓存区)中,查找id=1这行数据所在的数据页(Page)。
- 如果数据页在Buffer Pool中(命中),则直接在内存中进行后续操作。
- 如果不在(未命中),则会从磁盘中,将这个数据页加载到Buffer Pool的一个空闲位置。如果Buffer Pool满了,会通过**LRU(最近最少使用)**算法,淘汰掉一个旧的数据页。
- 写入Undo Log(内存 & 磁盘):
- 事务开始。在修改数据页之前,InnoDB会先将id=1这行数据的旧版本(name=’A’),记录到Undo Log中。Undo Log本身也是在Buffer Pool中有缓存的,并会定期刷盘。
- 修改数据页(内存):
- 现在,InnoDB可以安全地修改Buffer Pool中那个数据页的内容了,将name从’A’改为’B’。此时,这个数据页就成了“脏页(Dirty Page)”。
- 写入Redo Log(内存 & 磁盘) - WAL的关键:
- 为了保证事务的持久性(ACID中的D),修改不能只存在于内存中。但直接将一个16KB的脏页刷回磁盘,是非常慢的。
- 于是,InnoDB引入了Redo Log(重做日志)。它只记录物理上的变更,比如“在哪个文件的哪个页的哪个偏移量,把什么值改成了什么值”。这个日志非常小。
- 在修改数据页的同时,InnoDB会将这个变更操作,写入到Redo Log Buffer(一块内存区域)中。
- 这个Redo Log Buffer会以极高的频率(甚至在事务提交时),顺序地追加写入到磁盘上的Redo Log文件中。这个过程,就是WAL(Write-Ahead Logging,预写日志)。顺序写磁盘,远比随机写一个数据页要快得多。
- 事务提交(Commit):
- 当用户执行COMMIT时,InnoDB只需要确保对应的Redo Log已经成功刷盘。只要Redo Log落盘了,即使此时数据库突然断电,Buffer Pool中的所有脏页都丢失了,也没关系。因为在重启后,InnoDB可以通过扫描Redo Log,把所有已提交但未刷盘的修改,重新“播放”一遍,恢复出正确的数据。
- 脏页刷盘(后台):
- Buffer Pool中的脏页,并不会在事务提交时立即刷盘。它们会由后台的线程,根据一定的策略(比如LRU列表的冷端、脏页比例等),在系统不繁忙的时候,慢慢地、异步地刷回磁盘。
架构师的启示:
- 性能调优的核心:InnoDB性能调优的核心,就是尽可能地让数据操作在Buffer Pool中完成,并优化Redo Log的写入效率。Buffer Pool的大小、Redo Log文件的大小和刷盘策略,是DBA最重要的调优参数。
- WAL的哲学:WAL是一种用“顺序写”代替“随机写”的经典思想,它将数据持久化的成本,从昂贵的随机I/O,转移到了廉价的顺序I/O上。这个思想,在后续的LSM-Tree中,被发挥到了极致。
第二章:LSM-Tree vs B-Tree——大数据写入的范式革命
当数据量进入TB甚至PB级别,写入请求变得极其频繁时,B-Tree的“原地更新(In-place Update)”模型开始遇到瓶颈。每一次更新,都可能涉及到一次随机的磁盘I/O。为了解决这个问题,一种全新的、为“写密集型”场景而生的数据结构登上了历史舞台——LSM-Tree(Log-Structured Merge-Tree)。

2.1 LSM-Tree的核心思想:放弃“更新”,拥抱“追加”
LSM-Tree的哲学与B-Tree截然相反。它彻底抛弃了“原地更新”:
所有的写入操作(INSERT, UPDATE, DELETE),都只进行顺序的、追加式的写入。绝不修改任何已有的数据文件。
- 一个UPDATE操作,在LSM-Tree中,会被转换成一个带新值的INSERT操作。
- 一个DELETE操作,会被转换成一个带特殊“墓碑(Tombstone)”标记的INSERT操作。
LSM-Tree的典型结构:
- MemTable(内存):所有新的写入,首先会进入内存中的一个有序数据结构(通常是跳表或红黑树),我们称之为MemTable。
- Immutable MemTable(内存):当MemTable的大小达到一个阈值时,它会被“冻结”为只读状态,成为Immutable MemTable。同时,系统会创建一个新的、空的MemTable来接收新的写入。
- SSTable (Sorted String Table, 磁盘):后台线程会异步地将Immutable MemTable中的数据,顺序地刷写到磁盘上,形成一个有序的、不可变的文件。这个文件,就是SSTable。
- Compaction(合并):随着时间推移,磁盘上会积累大量的SSTable文件。后台线程会定期执行Compaction操作,将多个小的、旧的SSTable文件,读取出来,在内存中进行归并排序,然后将合并后的、更紧凑的、有序的新SSTable文件,顺序地写回磁盘。在这个过程中,旧的、重复的、被标记为删除的数据,就会被自然地清理掉。
2.2 “三大放大”:LSM-Tree的代价与权衡
LSM-Tree用极致的顺序写,换来了无与伦比的写入性能。但根据“没有免费午餐”定律,它也必须付出代价。这个代价,就是著名的“三大放大”问题:
- 写放大(Write Amplification):
- 定义:你实际写入到数据库的数据量,与这些数据在磁盘上被写入的总次数之比。
- 原因:在Compaction过程中,一份“活”的数据,可能会被反复地从旧的SSTable读出,再写入到新的SSTable中。如果Compaction策略不当,一份数据在它的生命周期里,可能会被重写几十次。
- 影响:极大地消耗了磁盘的I/O带宽,并严重影响SSD的寿命。
- 读放大(Read Amplification):
- 定义:为了找到一行数据,需要进行的磁盘I/O次数。
- 原因:当执行一次读请求时,LSM-Tree必须从新到旧,依次查询:MemTable -> Immutable MemTable -> 一系列磁盘上的SSTable文件。在最坏的情况下,它可能需要检查所有的SSTable,才能找到(或确认不存在)所要的数据。
- 优化:为了缓解这个问题,LSM-Tree通常会使用布隆过滤器(Bloom Filter)来快速判断一个SSTable中是否可能包含某个key。
- 影响:LSM-Tree的点查询性能,通常劣于B-Tree。它的范围查询性能也因为数据分散在多个文件中而受到影响。
- 空间放大(Space Amplification):
- 定义:数据在磁盘上实际占用的物理空间,与它逻辑大小之比。
- 原因:由于旧的数据和被删除的数据,在下一次Compaction发生之前,仍然会占用磁盘空间。
- 影响:需要预留比实际数据量大得多的磁盘空间。
权衡总结:
| 特性 | B-Tree (InnoDB) | LSM-Tree (RocksDB, HBase) |
|---|---|---|
| 写性能 | 差(随机写,锁竞争) | 优(顺序写,无锁) |
| 读性能 | 优(点查、范围查快) | 差(需要查询多个文件) |
| 写放大 | 低 | 高(Compaction导致) |
| 读放大 | 低(通常几次I/O) | 高 |
| 空间放大 | 低 | 高 |
| 适用场景 | OLTP,读多写少,需要强事务 | 大数据,写密集型,时序数据,日志分析 |
第三章:NewSQL的崛起——试图“统一”世界的美丽新世界
长久以来,数据库世界被清晰地划分为两大阵营:
- 传统关系型数据库(SQL):以MySQL, PostgreSQL为代表,提供了强大的ACID事务保证和灵活的SQL查询能力,但在**水平扩展(Scale-out)**方面举步维艰。我们被迫采用痛苦的、对业务侵入性极强的“分库分表”方案,来应对数据量的增长。
- NoSQL数据库:以HBase, Cassandra, MongoDB为代表,天生为分布式而生,拥有近乎无限的水平扩展能力。但它们往往以牺牲ACID事务和SQL为代价,换取了这种扩展性。
多年来,架构师们不得不在“一致性与易用性”和“扩展性”之间做出艰难的二选一。直到NewSQL的出现,它试图打破这个僵局,提出一个诱人的愿景:我们能否同时拥有SQL的便利、ACID的保证,以及NoSQL的弹性扩展能力?
以TiDB为例,我们来剖析这个“美丽新世界”是如何构建的。TiDB是一个开源的、兼容MySQL协议的分布式数据库,它的架构完美地诠释了NewSQL的核心思想。
3.1 TiDB的“三位一体”架构:计算与存储的分离
TiDB的架构设计,借鉴了Google Spanner和F1的论文,其核心是计算与存储的彻底分离。

- TiDB Server (计算层):
- 这是一个无状态的SQL计算引擎。它负责接收客户端的SQL请求,进行语法解析、查询优化,并生成分布式的执行计划。
- 因为无状态,TiDB Server可以无限地水平扩展。当你的应用QPS增长时,你只需要简单地增加更多的TiDB Server节点即可。
- 它通过标准的MySQL协议与客户端通信,使得现有的应用几乎可以“无缝”地从MySQL迁移过来。
- PD (Placement Driver, 调度层):
- 这是整个集群的“大脑”。它是一个独立的集群(通常由3或5个节点组成,通过Etcd保证高可用),负责存储整个集群的元数据。
- 核心职责:
- 数据路由:告诉TiDB Server,你需要的某一行数据,具体存储在哪个TiKV节点上。
- 全局授时与ID分配:为所有事务分配一个全局唯一且单调递增的时间戳(TSO),这是实现分布式事务的关键。
- 负载均衡与调度:监控所有TiKV节点的状态(容量、负载等),并自动地进行数据的迁移(Region aalancing)和分裂/合并(Region Split/Merge),以保持整个集群的负载均衡。
- TiKV (存储层):
- 这是一个分布式、支持事务的键值(Key-Value)存储引擎。所有的数据(包括表数据和索引数据),最终都被映射成Key-Value对,存储在这里。
- 数据分片(Sharding):TiKV会自动地将整个Key空间,切分成一个个连续的段,我们称之为Region。每个Region默认大小约为96MB。
- 高可用与数据复制:每个Region都会有多个副本(Replica),分布在不同的TiKV节点甚至不同的机房。这些副本通过Raft一致性协议,来保证数据的一致性和高可用。
3.2 Raft协议:分布式世界里的“民主选举”
如何保证一个Region的多个副本之间,数据是强一致的?TiDB选择了业界事实上的标准——Raft协议。

- 核心思想:在一个副本组(Raft Group)中,通过“民主选举”,选出一个“领导者(Leader)”。
- 写入请求:所有的写入请求,都必须发送给Leader。
- 日志复制:Leader接收到写入请求后,并不会立即应用,而是先将其作为一个“日志条目”,复制给组内的其他“跟随者(Follower)”。
- 多数派确认:当Leader收到超过半数(包括自己)的Follower确认“已收到该日志条目”的响应后,它才会将这个写入操作**应用(Apply)**到自己的状态机中,并向客户端返回成功。
- Leader选举:如果Leader节点宕机,剩下的Follower会发起新一轮的选举,投票选出新的Leader,整个过程是自动的。
深刻洞察:Raft协议的精髓在于,它将分布式系统中的“数据一致性”问题,巧妙地转化成了一个更简单的“日志序列一致性”问题。只要保证所有副本的日志序列是完全一样的,那么它们最终的状态也必然是一致的。
3.3 Percolator分布式事务模型:Google的“两阶段提交”魔法
ACID事务是关系型数据库的灵魂。在一个单机数据库中,实现事务相对简单。但在一个数据可能分布在上百个节点上的分布式数据库中,如何保证事务的原子性(要么都成功,要么都失败)?
TiDB借鉴了Google Percolator论文中的**两阶段提交(2PC)**模型,并结合了MVCC。
简化版的流程:
假设一个事务需要修改分布在不同Region上的Key1和Key2。
- 选择主键(Primary Key):TiDB会从所有需要修改的Key中,选择第一个作为这个事务的“主键”。
- 第一阶段:预写(Prewrite)
- 事务协调者(通常是TiDB Server)向所有涉及的Region的Leader节点,并行地发起prewrite请求。
- 对于每一个Key,prewrite请求会做两件事:
- 写入数据:将要修改的新值,写入到TiKV。
- 加锁:在该Key上加一个“锁”,锁信息里包含了这个事务的开始时间戳,并指向那个“主键”。
- 所有Leader节点在收到prewrite请求后,会进行冲突检测(例如,这个Key是否已经被其他事务锁定了)。如果检测通过,就执行写入和加锁,并返回“成功”给协调者。
- 第二阶段:提交(Commit)
- 如果协调者收到了所有prewrite请求的“成功”响应,那么它就认为这个事务可以提交了。
- 它会向那个“主键”所在的Region Leader,发起一个commit请求。
- 主键Leader收到commit请求后,会清理主键上的锁,并写入一条“提交记录”。只要主键的提交记录写入成功,整个事务就被认为成功了。
- 然后,协调者会异步地向所有其他的“次键(Secondary Key)”发送commit请求,去清理它们上面的锁。这个异步清理的过程,即使失败了,也不影响事务的最终状态,因为其他事务在遇到一个“锁”时,会通过锁信息里的指针,去检查“主键”的状态,从而得知这个锁是应该被清理,还是应该等待。
深刻洞察:Percolator模型,巧妙地通过“主键”这个中心点,将一个分布式事务的“原子性提交点”,从多个节点收敛到了一个节点上。同时,它结合MVCC,通过时间戳来进行冲突检测,实现了**快照隔离(Snapshot Isolation)**级别的事务。
架构师的启示:
NewSQL不是银弹,它用极其复杂的内部机制(Raft, 2PC, TSO),为我们屏蔽了底层的分布式复杂性。作为架构师,你需要理解:
- 性能权衡:这种分布式事务的延迟,必然高于单机事务。它的性能瓶颈,往往在于跨地域网络延迟和PD的TSO分发能力。
- 适用场景:它非常适合那些既需要ACID事务,又面临海量数据和高并发,且无法忍受传统分库分表方案复杂性的业务场景,比如金融科技、电商后台、大型SaaS服务等。
第四章:列式存储的威力——OLAP数据库“快如闪电”的秘密
到目前为止,我们讨论的所有数据库(InnoDB, HBase, TiDB),本质上都是“行式存储(Row-based Storage)”。它们的数据在磁盘上,是以“行”为单位,连续存储的。这非常适合OLTP场景,因为我们通常需要一次性获取或修改一整行的所有字段。
但是,在OLAP(在线分析处理)场景中,我们的查询模式完全不同了:
1 | SELECT SUM(sales_amount) FROM orders WHERE product_category = 'Electronics' AND order_date BETWEEN '2023-01-01' AND '2023-03-31'; |
这个查询的特点是:
- 只关心少数几列(sales_amount, product_category, order_date)。
- 需要扫描海量的数据行(可能是数亿甚至数十亿行)。
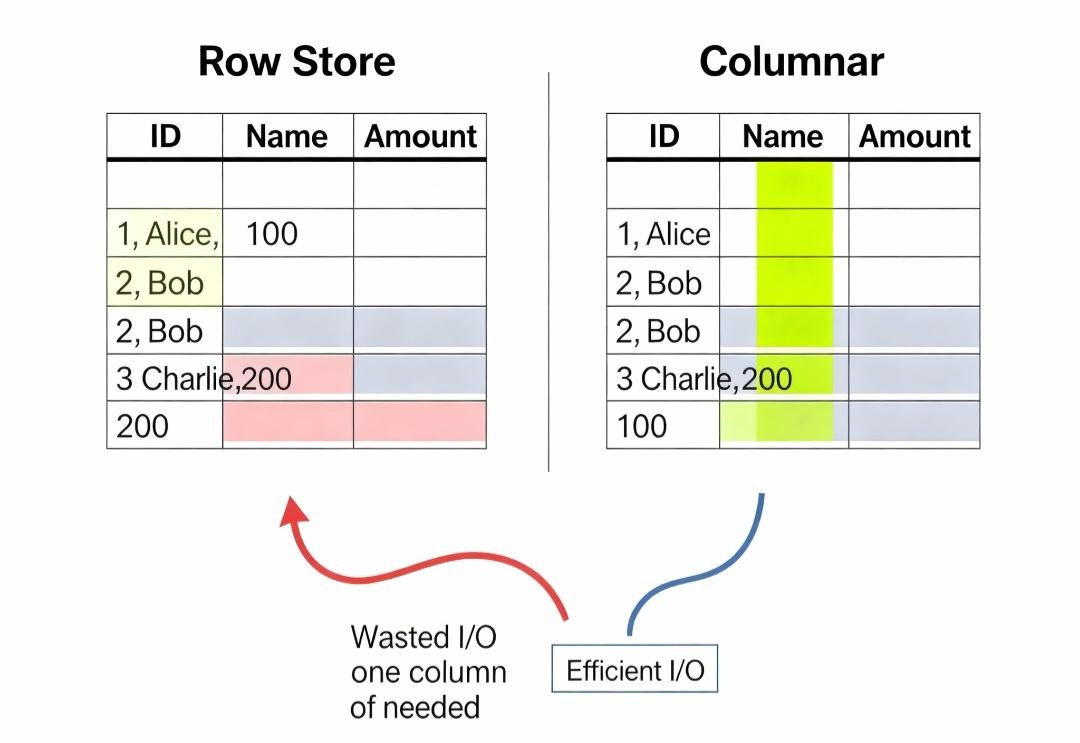
如果用行式存储来执行这个查询,数据库将不得不把数亿行数据的所有字段(包括我们完全不关心的user_id, shipping_address等),全部从磁盘加载到内存中。这造成了巨大的、无效的I/O浪费。
为了解决这个问题,列式存储(Columnar Storage)应运而生。以ClickHouse, Druid等为代表的OLAP数据库,其核心秘密就在于此。
4.1 数据的“旋转90度”:列式存储的本质
列式存储的理念非常简单:将同一列的数据,连续地存储在一起。
| 行式存储(一行一行存) | 列式存储(一列一列存) |
|---|---|
| [1, ‘Alice’, 100], [2, ‘Bob’, 150], [3, ‘Charlie’, 200] | [1, 2, 3],[‘Alice’, ‘Bob’, ‘Charlie’],[100, 150, 200] |
这个看似简单的“旋转90度”,带来了革命性的性能优势:
- 极低的I/O:对于上面的聚合查询,列式数据库只需要读取sales_amount, product_category, order_date这三列的数据文件。其他所有列的文件,连碰都不会碰一下。I/O量瞬间减少了几个数量级。
- 惊人的数据压缩率:
- 类型相似性:同一列的数据,其类型是完全相同的(都是整数、字符串或日期)。
- 内容相似性:同一列的数据,其内容往往也具有很高的相似性(例如,“商品类目”这一列,可能只有几百个不同的值)。
- 这使得列式存储可以采用极其高效的压缩算法。例如,对于重复度很高的列,可以使用字典编码;对于连续的整数或日期,可以使用增量编码(Delta Encoding)。通常,列式数据库的数据压缩率可以达到5-10倍,甚至更高。这进一步减少了需要从磁盘读取的数据量。
4.2 向量化执行引擎:CPU的“流水线”加速
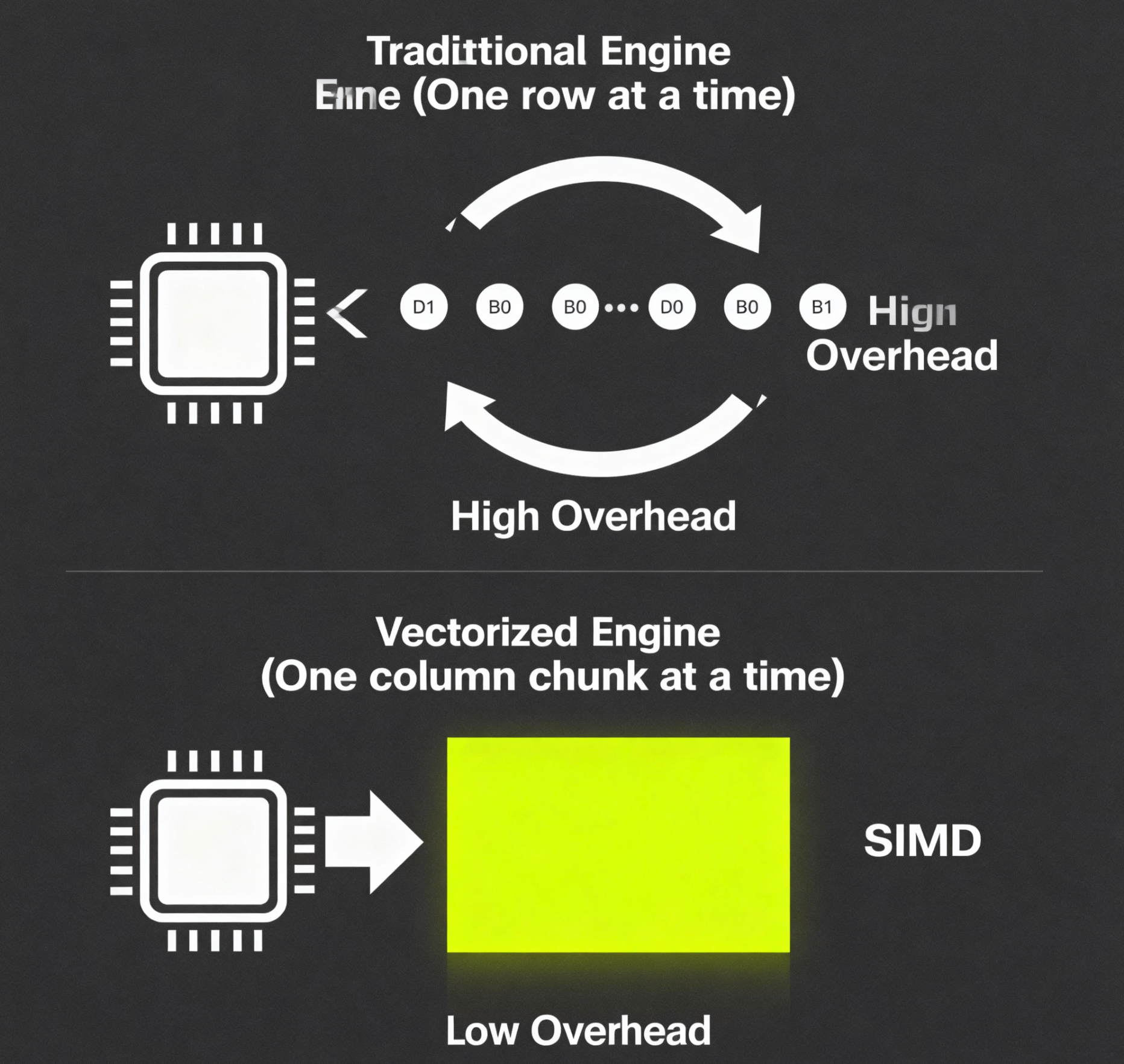
传统数据库的查询执行引擎,通常是“一次一元组(Tuple-at-a-time)”的火山模型。就像一个循环,每次从下层算子取一行数据,进行处理,再交给上层算子。这个过程,涉及大量的虚函数调用和CPU分支预测失败,CPU的“流水线”无法被充分利用。
而现代的OLAP数据库,则采用了向量化执行引擎(Vectorized Execution Engine)。
- 核心思想:不再是一次处理一行数据,而是一次处理一批(一列)数据。数据在内存中,是以连续的“列向量(Column Vector)”的形式存在的。
- CPU的狂欢:
- 消除函数调用开销:所有的计算,都在一个紧密的内循环中完成。
- 利用SIMD指令:CPU提供了**SIMD(Single Instruction, Multiple Data)**指令集(如SSE, AVX)。它允许一条CPU指令,同时对多个数据进行运算(例如,一条指令同时完成8个整数的加法)。向量化执行引擎,可以完美地利用SIMD,实现并行计算,将CPU的性能压榨到极致。
深刻洞查:如果说列式存储是从I/O层面解决了OLAP的瓶颈,那么向量化执行引擎,就是从CPU计算层面,对OLAP查询进行了终极加速。两者的结合,共同造就了ClickHouse等数据库亚秒级查询的“神话”。
架构师的启示:
- 没有万能的数据库:永远不要试图用一个OLTP数据库(如MySQL)去解决一个OLAP的问题。它们在底层的存储结构和计算引擎上,是为完全不同的场景设计的。
- 数据架构的分层:一个成熟的数据架构,必然是分层的。我们会用MySQL/TiDB来支撑在线的事务处理,然后通过ETL/CDC工具,将数据同步到ClickHouse/Druid这样的数据仓库中,来满足复杂的分析和报表需求。理解每个数据库的“基因”,是做出正确技术选型的根本。
结语:从“使用者”到“洞察者”的蜕变
我们完成了一次令人窒息的数据库内核之旅。从InnoDB那精巧如钟表的事务与并发控制,到B-Tree与LSM-Tree在读写哲学上的根本对立;从NewSQL试图统一天下的雄心壮志,到列式存储与向量化执行在分析领域的降维打击。
我们看到,每一个成功的数据库系统,都不是技术的随机堆砌,而是围绕着一个核心的权衡(Trade-off),构建起来的一套自洽的、优雅的逻辑体系。
InnoDB:用复杂的日志和多版本机制,在单机上,换取了ACID与高性能并发的平衡。
LSM-Tree:用读放大和空间放大,换取了极致的写入性能和扩展性。
NewSQL:用复杂的分布式协议,换取了SQL+ACID+扩展性的“三位一体”。
列式存储:用牺牲单行写入和更新的灵活性,换取了海量数据分析的极致性能。
作为架构师,当你能够清晰地看到这些系统背后的“第一性原理”和“核心权衡”时,你就不再是一个数据库的“使用者”,而是一个能与数据系统进行灵魂对话的“洞察者”。你手中的数据库,不再是一个个孤立的“黑盒”,而是一套可以根据不同业务场景,进行精准选择和组合的、透明的“工具箱”。
这,就是你构建坚不可摧的数据密集型应用的信心之源。

