百万架构师成长之路(5):分布式共识的“圣杯”:从Paxos的晦涩到Raft的黎明
导语:在“不可靠”的世界里,如何建立“可靠”的秩序?
想象一下,你正在设计一个关键的分布式系统,比如一个注册中心、一个分布式锁服务,或者一个高可用的数据库。这个系统由多个节点组成,它们通过一个不可靠的网络进行通信。网络会延迟,会丢包,甚至会中断。节点会宕机,会重启,甚至会“失忆”。
在这个混乱、充满不确定性的世界里,你面临着一个终极难题:如何让所有存活的节点,就一个“值”(比如,谁是主节点?某个配置项应该是A还是B?),达成完全一致的、不可撤销的共识?
这个问题,就是分布式系统的“共识问题”。它是构建一切可靠分布式系统的基石。没有共识,分布式系统就是一盘散沙。你的数据会错乱,你的服务会脑裂,你的锁会失效。可以说,一部分布式系统的发展史,就是一部人类与“共识问题”不断斗争的历史。
长久以来,这个问题如同横亘在所有系统设计师面前的一座高山,其顶峰的“圣杯”,就是由计算机科学巨匠莱斯利·兰伯特(Leslie Lamport)提出的Paxos协议。Paxos以其严谨的数学证明和极致的优雅,成为了共识问题的“第一个”通用解决方案。但它也以其极度的晦涩难懂,劝退了一代又一代的工程师,被称为“神谕般的算法”。
直到2013年,斯坦福大学的Diego Ongaro和John Ousterhout发表了一篇名为《In Search of an Understandable Consensus Algorithm》的论文,提出了Raft协议。Raft在保证与Paxos同等容错能力和性能的前提下,以其无与伦比的“易于理解”性,迅速席卷了整个工业界,开启了分布式共识的新纪元。
本篇,就是你征服这座高山的完整地图。我们将从那个著名的“拜占庭将军问题”开始,理解共识问题的本质困难。然后,我们将鼓起勇气,用最通俗的语言和严谨的图解,去挑战Paxos的“晦涩之美”。接着,我们将沐浴在Raft的“工程之光”下,看它是如何将复杂的问题分解得如此清晰。最后,我们将看到这些伟大的思想,如何在ZooKeeper、Etcd、TiKV等现实世界的系统中,化为坚不可摧的基石。
这不仅是一次算法的学习,更是一次思维的淬炼。它将教会你,如何在“不可靠”的世界里,建立起“可靠”的秩序。
第一章:“拜占庭将军问题”——共识难题的终极隐喻
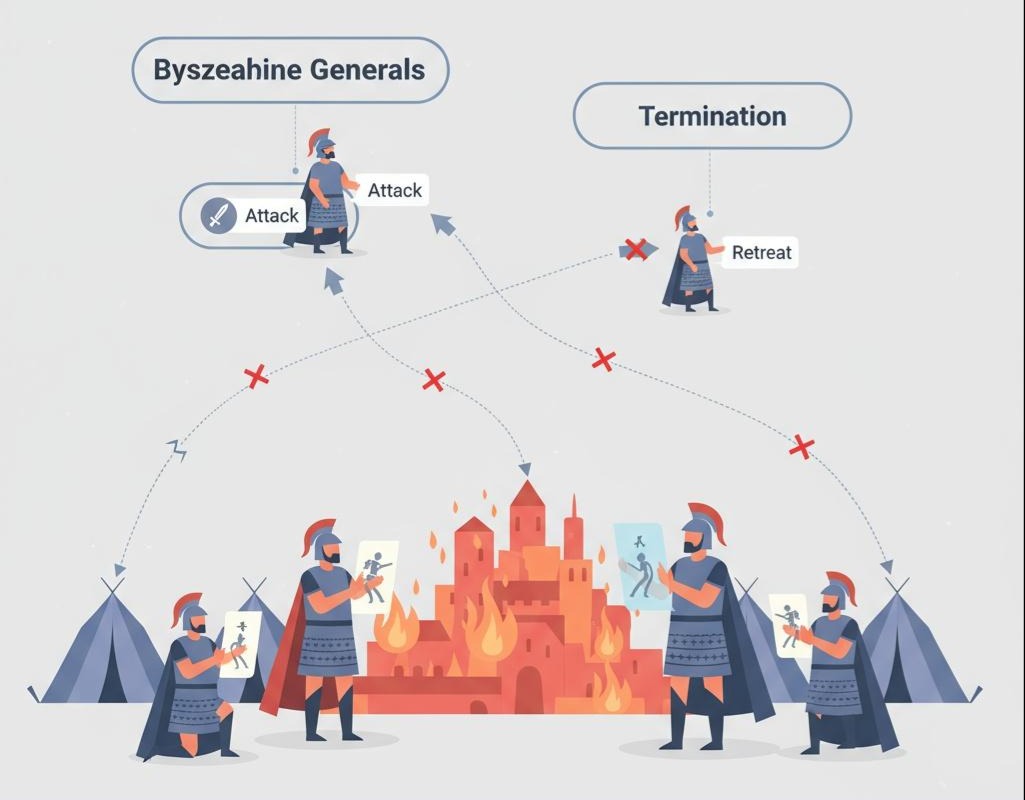
要理解共识,我们必须先回到公元4世纪的拜占庭帝国,听一个由兰伯特“杜撰”的军事故事。
故事场景:
拜占庭帝国的大军,由多个军团组成,驻扎在敌军城池的四周。每个军团都由一位将军率领。他们需要协同作战,要么一起进攻,要么一起撤退。任何不一致的行动,都将导致灾难性的失败(比如,只有一部分军团进攻,会被敌军逐个击破)。
通信的困境:
- 通信不可靠:将军们之间只能通过信使来传递信息。信使可能会被敌军俘虏或在路上迷失,导致消息丢失。
- 存在叛徒:将军中,可能存在叛徒。忠诚的将军会如实传达命令,而叛徒则会恶意地发送伪造的或矛盾的信息。比如,叛徒可能会对A将军说“进攻”,同时对B将军说“撤退”。
问题的核心:

在一个可能存在消息丢失和恶意节点(叛徒)的系统中,忠诚的将军们如何达成一个统一的、不可更改的作战计划(进攻或撤退)?
这就是“拜占庭将军问题”。它描述了分布式共识问题中最困难的一种场景,我们称之为“拜占庭容错(Byzantine Fault Tolerance, BFT)”。区块链技术(如比特币)解决的核心,就是这个问题。
简化问题:非拜占庭容错(CFT)
在大多数的数据中心内部环境中,我们可以做一个简化的假设:节点虽然会宕机(Crash)、网络虽然会中断(Fail-stop),但节点不会“说谎”,不会恶意地发送伪造信息。这种场景下的共识问题,我们称之为“非拜占庭容错(Crash Fault Tolerance, CFT)”。
我们接下来要讨论的Paxos和Raft,主要解决的就是CFT场景下的共识问题。它们处理的是节点宕机、网络分区、消息延迟和乱序,但不处理节点伪造信息的情况。
深刻洞察:拜占庭将军问题,为我们揭示了共识的两个核心要求:
- 一致性(Agreement):所有(诚实的)节点,最终必须决定相同的值。
- 可终止性(Termination):所有(诚实的)节点,最终都必须能做出一个决定。
这两个看似简单的要求,在不可靠的分布式环境中,实现起来却异常困难。
第二章:Paxos协议的“晦涩之美”——神谕的解读
Paxos是兰伯特在1990年提出的,但他用一个古希腊城邦Paxos岛的议会故事来描述它,使得论文异常晦涩。直到2001年,他发表了《Paxos Made Simple》,才让这个算法稍微“平易近人”了一些。我们将基于这篇论文,尝试解读这个伟大的算法。
Paxos的核心思想是“多数派(Majority)”和“承诺(Promise)”。它将达成共识的过程,模拟成一个议会投票的过程。
2.1 角色定义
- 提议者 (Proposer):提出一个“提议(Proposal)”的议员。提议通常包含一个提议编号(Proposal Number)和一个提议值(Value)。
- 接受者 (Acceptor):可以“接受”提议的议员。他们是共识的核心参与者。
- 学习者 (Learner):可以“学习”到最终被批准的提议的议员。
在实际实现中,一个节点可以同时扮演多种角色。
2.2 Basic Paxos:一轮投票的艺术
Basic Paxos只用于对一个值达成共识。它的过程分为两个阶段:

阶段一:准备(Prepare Phase)- “承诺”阶段
- 提议者 (P):选择一个全局唯一且单调递增的提议编号N。然后,向超过半数的接受者(A)发送一个**Prepare(N)**请求。
隐喻:一个议员站起来说:“我准备发起一个编号为N的提议,请大家听我说!”
- 接受者 (A):收到Prepare(N)请求后,会检查自己本地记录的、曾经承诺过的最高提议编号max_N。
- 如果 N > max_N:
- 接受者做出一个承诺:“我保证,我不会再接受任何编号小于N的提议了。” 它会将max_N更新为N。
- 然后,它会检查自己本地是否曾经**接受过(Accepted)**任何提议。
- 如果从未接受过任何提议,它就向提议者P返回一个Promise(OK)。
- 如果曾经接受过提议(假设是编号为accepted_N,值为accepted_V的提议),它就向提议者P返回Promise(OK, accepted_N, accepted_V)。
- 如果 N <= max_N:接受者直接拒绝这个请求,返回一个Promise(Reject)。
隐喻:议员们听到后,如果觉得这个提议编号够“新”,就会说:“好的,我听你的。顺便告诉你,我之前曾经同意过一个编号为accepted_N,内容为accepted_V的提议。”
阶段二:接受(Accept Phase)- “批准”阶段
- 提议者 (P):
- 如果收到了超过半数的接受者返回的**Promise(OK)**响应:
- 提议者现在可以发起一个Accept请求了。提议的值(Value)该如何选择呢?
- 它会检查所有收到的Promise响应。如果这些响应中,包含了之前被接受过的提议(即accepted_V不为空),那么,它必须选择那个提议编号accepted_N最大的提议所对应的accepted_V,作为自己这次Accept请求的提议值。
- 如果所有响应中,都没有任何accepted_V,那么,它才可以自由地使用自己最初想提议的值。
- 然后,它向超过半数的接受者,发送一个**Accept(N, Value)**请求。
- 如果没有收到超过半数的Promise(OK),提议者会选择一个更大的提议编号N’,重新从阶段一开始。
- 接受者 (A):收到Accept(N, Value)请求后,它会再次检查自己承诺的最高提议编号max_N。
- 如果N >= max_N:接受者正式接受这个提议。它会记录下这个**(N, Value),并向提议者和所有学习者返回一个Accepted(N, Value)**消息。
- 如果N < max_N:接受者拒绝这个请求。
- 学习者 (L):当一个学习者收到了超过半数的接受者发来的、关于同一个提议 (N, Value)的Accepted消息时,它就知道,这个值已经被**最终选定(Chosen)**了。共识达成。
Paxos的精髓与保证:
为什么这个看似复杂的过程能保证一致性?
关键在于第3步中,提议者选择提议值的规则。这个规则保证了:一旦一个值被超过半数的接受者接受了,那么后续任何更高编号的提议,都必须选择这个值。
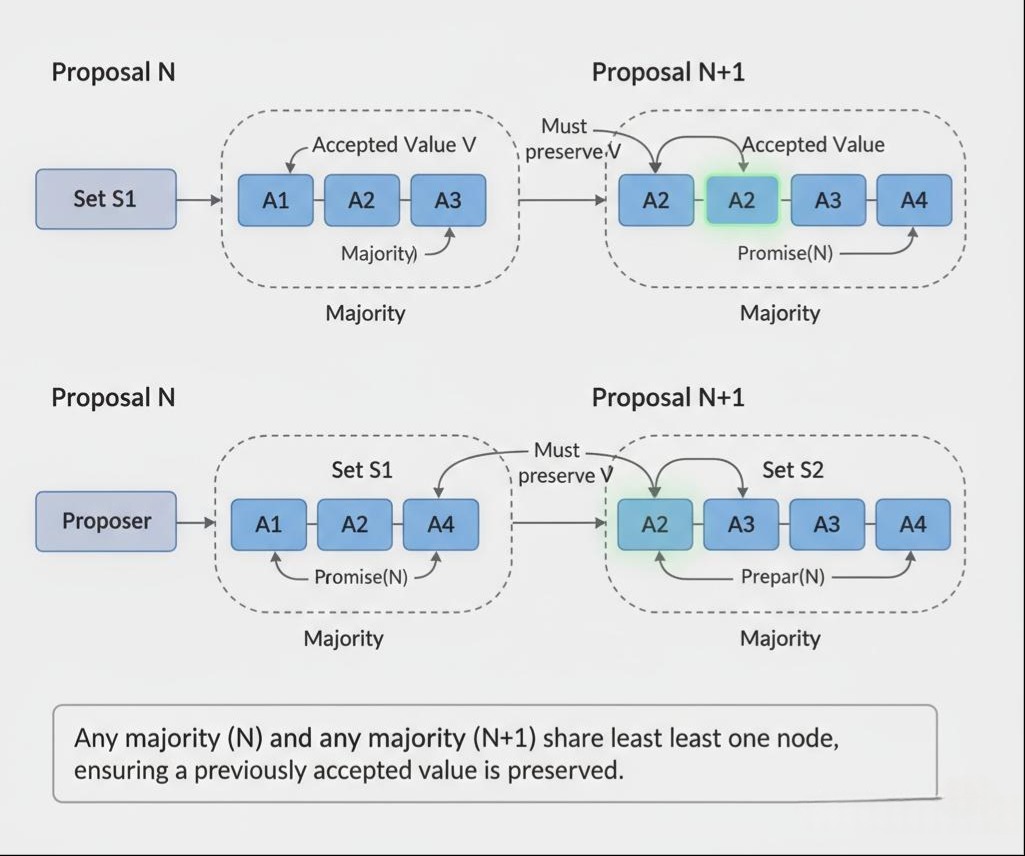
证明草图:假设一个值V在提议N中被多数派S1接受了。现在一个新的提议者发起了编号为N’(N’>N)的提议。根据“多数派”原则,这个新提议者发送Prepare(N’)时,所联系的多数派S2,必然与S1至少有一个交集。这个交集中的接受者,会向新提议者返回它曾经接受过的**(N, V)。新提议者根据规则,就必须选择V作为自己Accept请求的值。这样,值V**就“延续”下去了。
2.3 Multi-Paxos:从“一事一议”到“连续决策”
Basic Paxos的效率很低,因为每一次决策都需要完整的两阶段过程。在实际系统中,我们需要对一系列值(比如一条操作日志)达成连续的共识。Multi-Paxos就是为此而生的优化。
- 核心思想:选举一个唯一的、稳定的领导者(Leader)。
- 选举阶段:所有节点都可以通过一个Basic Paxos实例,来提议自己成为Leader。一旦某个节点获得了多数派的支持,它就成为了Leader。
- 执政阶段:
- 这个Leader,会长期“执政”。
- 对于后续的每一次决策(例如,第i条日志应该是什么),都由这个唯一的Leader来发起提议。
- 关键优化:因为Leader是唯一的,不存在多个提议者竞争的情况。所以,对于后续的第i+1, i+2…次决策,Leader可以省略掉Prepare阶段,直接向所有接受者发送Accept请求。
- 这使得正常的共识过程,从“两阶段提交”退化成了“一阶段提交”,大大提高了效率。只有当Leader发生变更时,才需要重新进行一次完整的Paxos流程来选举新Leader。
深刻洞察:Multi-Paxos的出现,使得Paxos从一个理论模型,向工程实现迈出了一大步。它引入的“Leader”概念,以及将共识过程区分为“稳定状态(一阶段)”和“异常状态(两阶段)”的思想,被后续的Raft协议完全继承和发扬光大。
第三章:Raft协议的“工程之光”——为了“可理解”而生
尽管Multi-Paxos在理论上可行,但其论文的描述依然非常抽象,留下了大量的工程实现细节空白,导致不同人实现出来的Multi-Paxos千差万别。Raft的诞生,就是为了解决这个问题。
Raft的作者认为,一个共识算法,可理解性(Understandability)与正确性同等重要。Raft通过两个核心思想,实现了这一点:
- 更强的领导者(Stronger Leader):Raft中的Leader,拥有比Multi-Paxos中更绝对的权威。所有的数据流,都必须从Leader流向Follower。
- 问题分解(Problem Decomposition):Raft将复杂的共识问题,清晰地分解为三个独立的子问题:
- 领导者选举 (Leader Election)
- 日志复制 (Log Replication)
- 安全性 (Safety)
3.1 Raft的角色与状态机

- 角色:
- Leader (领导者):处理所有客户端请求,并管理日志复制。任何时刻,系统中最多只有一个Leader。
- Follower (跟随者):完全被动。接收Leader的日志,并在选举中投票。
- Candidate (候选人):一种临时的、用于选举新Leader的角色。
- Term (任期):Raft将时间划分为一个个连续的“任期(Term)”。每个任期都以一次选举开始。任期编号是单调递增的。它扮演了逻辑时钟的角色。
3.2. 领导者选举 (Leader Election)
- 超时驱动:每个Follower都有一个选举计时器(Election Timeout),其时长是随机的(例如150-300ms)。
- 成为候选人:如果一个Follower在计时器超时之前,都没有收到来自Leader的任何消息(心跳),它就认为Leader可能已经宕机。于是,它会:
- 将自己的任期号Term加1。
- 将自己的角色转变为Candidate。
- 给自己投一票。
- 向集群中的所有其他节点,发送一个RequestVote RPC。
- 投票过程:其他节点收到RequestVote请求后,会遵循“先来先服务,一任期一票”的原则:
- 如果请求中的Term小于自己当前的Term,直接拒绝。
- 如果在当前Term内,自己还没有投过票,并且候选人的日志至少和自己一样“新”(这个是安全性的关键,后面详述),它就会投票给这个候选人。
成为Leader:如果一个Candidate收到了来自超过半数节点的投票,它就成功当选为新一任的Leader。
选举分裂与重置:如果多个Candidate同时发起选举,可能会导致选票被瓜分,谁也无法获得多数票。这种情况下,这一轮选举失败。每个Candidate的计时器会超时,它们会增加Term号,并发起新一轮的选举。由于每个节点的选举超时时间是随机的,下一次选举同时开始的概率就很小,最终总会有一个节点能率先获得多数票。
3.3 日志复制 (Log Replication)
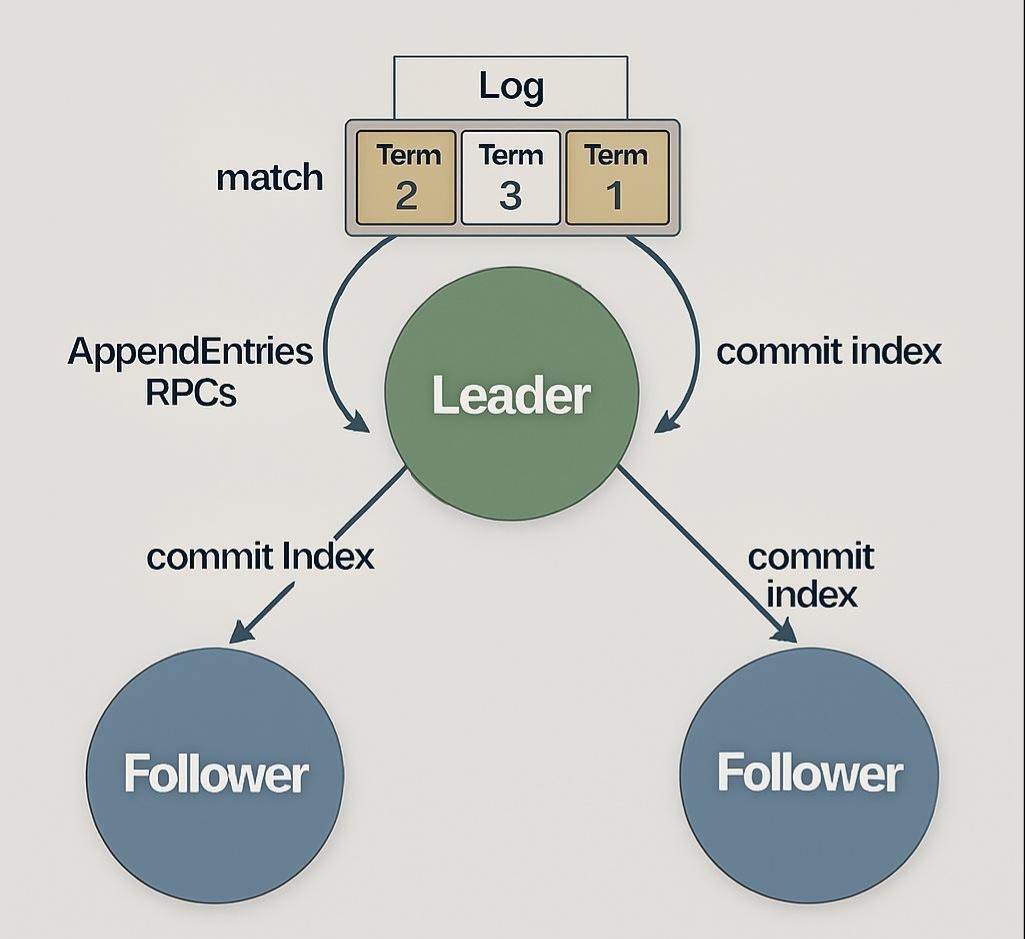
- Leader接收请求:当Leader当选后,它开始接收客户端的请求。每个请求都会被作为一个日志条目(Log Entry),追加到它自己的日志序列中。每个日志条目都包含了命令内容和它被创建时的Term号。
- 并行复制:Leader会并行地向所有Follower,发送AppendEntries RPC,将新的日志条目复制给它们。这个RPC也兼具“心跳”的功能。
- Follower的检查:Follower收到AppendEntries RPC后,会进行一个一致性检查:RPC中携带的前一个日志条目的index和term,是否与自己本地日志中对应位置的index和term匹配?
- 如果匹配,Follower就接受并追加新的日志条目。
- 如果不匹配,Follower会拒绝,并告知Leader自己不匹配的位置。Leader会递减要发送的日志索引,直到找到匹配点,然后用自己的日志覆盖Follower的冲突日志。
- 提交(Commit):
- 当Leader发现,某个日志条目已经被成功复制到了超过半数的节点上时,它就认为这个条目是“可提交的(Committed)”。
- 然后,Leader会将这个条目应用到自己的状态机中,并将结果返回给客户端。
- 在下一次的AppendEntries RPC中,Leader会通知所有Follower,哪些日志条目已经被提交了。Follower收到通知后,也将这些条目应用到自己的状态机中。
Raft的安全性(Safety)保证:
Raft通过两个核心规则,来保证不会选出“错误”的Leader,也不会提交“错误”的日志:
- 选举限制:一个候选人,只有当它的日志包含了所有已提交的日志条目时,它才有资格当选为Leader。这是通过在投票时,比较候选人和投票者日志的“新旧程度”(比较最后一个条目的Term和index)来实现的。
- 提交规则:Leader只能提交自己当前任期内的日志条目。它不能直接提交过去任期的日志。过去任期的日志,是通过提交当前任期的新日志时,“顺便”被间接提交的。
3.4 Paxos vs. Raft:一场哲学上的对决
| 特性 | Paxos (Multi-Paxos) | Raft |
|---|---|---|
| 核心哲学 | 极致的灵活性和去中心化。允许“并发”的Leader选举。 | 极致的可理解性。强调“强Leader”,一切以Leader为中心。 |
| 领导者 | Leader是“第一提议者”,权威相对较弱。 | Leader是绝对的独裁者。数据流只能从Leader到Follower。 |
| 选举 | 可以并发进行,可能导致活锁。 | 同一任期,只有一个选举获胜者。随机超时避免冲突。 |
| 日志 | 允许日志中存在“空洞”。 | 强制要求日志是连续的、匹配的。 |
| 工业界 | 理论基石,但直接实现者少。 | 事实上的工业标准。 |
深刻洞察:Raft的成功,是工程思维对纯粹理论思维的一次伟大胜利。它证明了,一个好的算法,不仅要“正确”,更要“易于人类理解和实现”。
第四章:ZooKeeper的ZAB协议——Raft的“孪生兄弟”
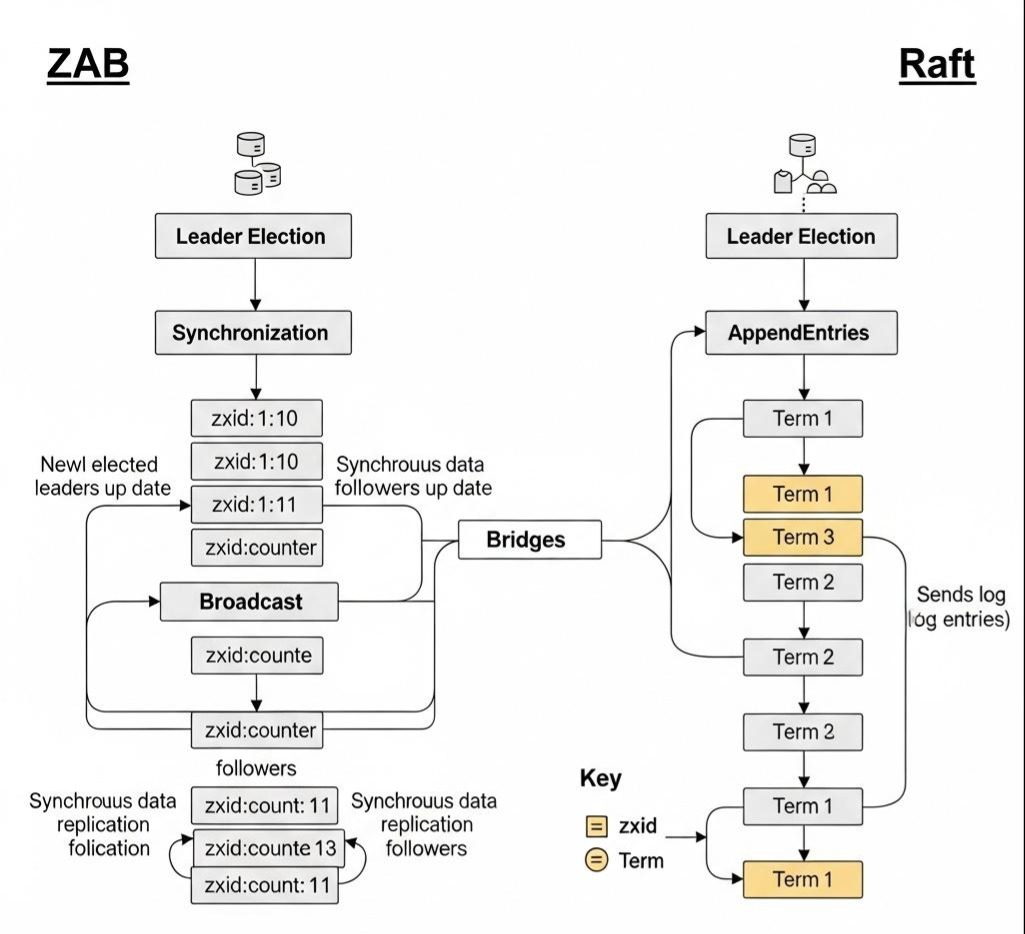
在Raft诞生之前,分布式协调领域事实上的霸主是ZooKeeper。它使用的共识协议,叫做ZAB(ZooKeeper Atomic Broadcast)。有趣的是,ZAB协议的思想,与Raft惊人地相似,可以看作是Raft的“异父异母的孪生兄弟”。
- 相似之处:
- 都强调唯一的、强的Leader。
- 都将过程分为Leader选举和**数据同步(原子广播)**两个阶段。
- 都使用**任期(Epoch in ZAB)**作为逻辑时钟。
- 都要求新选举出的Leader,必须包含所有已提交的日志。
- 主要不同点:
- 事务ID(zxid):ZAB的日志条目ID(zxid)是一个64位的数字,高32位是epoch(任期),低32位是该任期内的计数器。这使得zxid本身就包含了任期信息。
- 同步阶段:ZAB在选举出新Leader后,会进入一个明确的“同步(Synchronization)”阶段,确保所有Follower都与Leader的日志同步到某个点,然后才能开始接收新的请求。Raft则将同步过程,巧妙地融合在了常规的AppendEntries RPC中。
- 设计目标:ZAB是为ZooKeeper这个特定的“主备模式”的原子广播场景而设计的。而Raft,则被设计成一个更通用的、可被复用的共识算法模块。
第五章:共识算法的现实世界——从Etcd到TiKV
理论的最终价值,在于它如何改变现实世界。共识算法,正是现代分布式系统的“龙骨”。

- Etcd (Used by Kubernetes):
- Kubernetes的所有集群状态(Pod, Service, Deployment的定义和状态),都存储在Etcd中。Etcd的可靠性,直接决定了整个K8s集群的可靠性。
- Etcd内部,正是使用了Raft协议,来保证其多个节点之间数据的高度一致性。当你用kubectl apply创建一个Pod时,这个Pod的YAML描述,就是作为一个“值”,通过Raft协议,被写入到Etcd集群中。
- Consul:
- 一个流行的服务发现和配置中心。它同样使用Raft协议,来维护服务列表和配置信息的一致性。
- TiKV (Used by TiDB):
- 正如我们在上一篇所学,TiDB的存储层TiKV,将数据切分成一个个Region。每一个Region的多个副本,都构成了一个独立的Raft Group。
- 一个大规模的TiDB集群中,可能同时运行着成千上万个Raft实例,每一个都在为自己那一小片数据的“共识”,独立地工作着。这是一种将共识算法“规模化”应用的典范。
- 其他:从CockroachDB, InfluxDB Enterprise, 到NATS Streaming,无数成功的分布式项目背后,都有着Raft协议的身影。
架构师的启示:
当你进行技术选型,选择一个分布式数据库、消息队列或注册中心时,你必须问一个问题:“它的底层,采用了什么样的共识机制?”
- 如果是Raft或Paxos,你可以相信它能提供**强一致性(CP)**的保证。
- 如果是Gossip或其他最终一致性协议,那么它提供的是**高可用性(AP)**的保证。这个根本性的差异,将直接决定了它是否适合你的业务场景。
结语:从“神谕”到“宪法”,共识的普世之光
我们完成了一次穿越分布式系统思想史核心的艰难旅程。从拜占庭将军的困境,我们理解了共识的本质;在Paxos的数学迷宫中,我们瞥见了逻辑的极致之美;在Raft的清晰设计里,我们感受到了工程的智慧之光。
共识算法,就像是为混乱的分布式世界,制定的一部“宪法”。它用严谨的、无可辩驳的规则,定义了节点之间如何沟通、如何决策、如何选举、如何更替。正是在这部“宪法”的保障之下,我们才得以在不可靠的硬件和网络之上,构建出可靠的、宏伟的、可信赖的分布式应用。
作为架构师,理解这部“宪法”,是你从一个“服务的使用者”,蜕变为一个“系统的创造者”的成人礼。它赋予你一种全新的、底层的视角,去审视你所构建和使用的每一个分布式系统,让你能洞察其行为的根源,预测其能力的边界。

