百万架构师成长之路(6):流量调度艺术:从LVS的内核魔术到Service Mesh的宇宙哲学
导语:你的系统“动脉”,决定了你的业务“脉搏”
想象一下,你精心设计的分布式系统,就像一座由无数功能各异的建筑(微服务)构成的繁华都市。这座都市的“GDP”(业务吞吐量)、“应急响应能力”(故障恢复)和“市民幸福指数”(用户体验),最终都取决于一个看不见、摸不着,却无处不在的核心基础设施——城市的智能交通调度系统。这个系统,在我们的世界里,叫做负载均衡。
对于许多开发者而言,负载均衡是一个熟悉的陌生人。我们知道Nginx的upstream,知道云厂商的SLB,我们知道它能“分发流量”。但这种认知,如同只知道方向盘可以控制方向,却对发动机的缸数、变速箱的齿比、悬挂的调校一无所知。当“交通拥堵”(性能瓶颈)、“连环追尾”(雪崩效应)、“道路塌陷”(节点故障)发生时,我们便会束手无策。
对流量调度的认知深度,直接定义了你作为架构师,对整个分布式系统“宏观调控”能力的上限。 它早已超越了“运维”的范畴,成为了架构设计、服务治理、弹性伸缩、混沌工程乃至成本控制的交叉核心。
为什么在内核层做负载均衡(LVS)会比在应用层(Nginx)快一个数量级?这背后隐藏着怎样的操作系统“诡计”?
从集中式API网关,到去中心化的Service Mesh,这场架构的“权力转移”,其背后驱动的根本矛盾是什么?
当我们在谈论“智能路由”、“流量染色”、“故障注入”时,我们到底在谈论一种技术,还是一种关于系统确定性与混沌可控性的哲学?
本篇,我们将开启一次负载均衡技术的“时空穿越”。我们将从最古老的DNS开始,手持“放大镜”潜入Linux内核,解剖LVS/IPVS的转发魔术;然后上浮到应用层,领略Nginx/OpenResty如何用“绣花针”编织七层世界的无限可能;接着,我们将视野拉高到全球,探寻GSLB如何扮演“上帝之手”,进行跨地域的流量乾坤大挪移;最后,我们将进入云原生时代的“量子领域”——Service Mesh,看Istio是如何将流量的法则,写入到宇宙的基本粒子(Sidecar)之中。
这不仅是一次技术的巡礼,更是一场关于“控制与失控、集中与分散、静态与动态”的架构思想进化史诗。
第一章:DNS负载均衡——古老、简单,却充满“谎言”的“第一跳”
在任何用户请求能够一窥你数据中心门楣之前,它都必须经过一个古老而神圣的仪式——DNS查询。这个诞生于上世纪80年代的“互联网通讯录”,在今天依然是我们进行最粗粒度负载均衡的第一站,也是最容易被误解的一站。
1.1 A记录的“轮询”幻术与“缓存”之殇
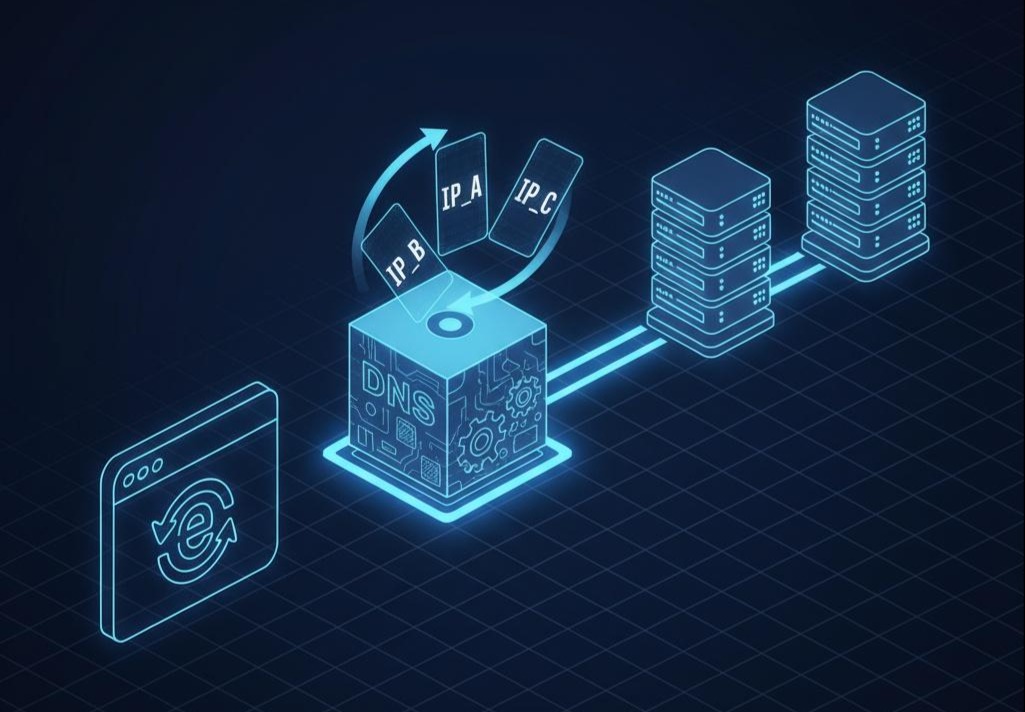
DNS负载均衡的原理,朴素得近乎简陋。你只需为你希望进行负载均衡的域名(如**http://api.myapp.com),在DNS服务商那里配置多条A记录**,分别指向你不同服务器的公网IP。
- 幻术的施展:当一个用户的Local DNS服务器来请求**http://api.myapp.com的IP时,权威DNS服务器会像一个机械的发牌员,进行轮询(Round-Robin),依次返回IP_A**, IP_B, IP_C…。从宏观概率上看,流量似乎被“均分”了。
- “谎言”的根源——健康检查的缺位:这个幻术的第一个致命缺陷,是它建立在一个脆弱的假设之上:所有IP都是健康的。DNS服务器本身,并不知道IP_A背后的那台服务器是否早已内核崩溃。它只是一个忠实的“记录员”,而不是一个聪明的“侦探”。当它把一个已经失效的IP返回给用户时,它就撒下了第一个“谎言”。
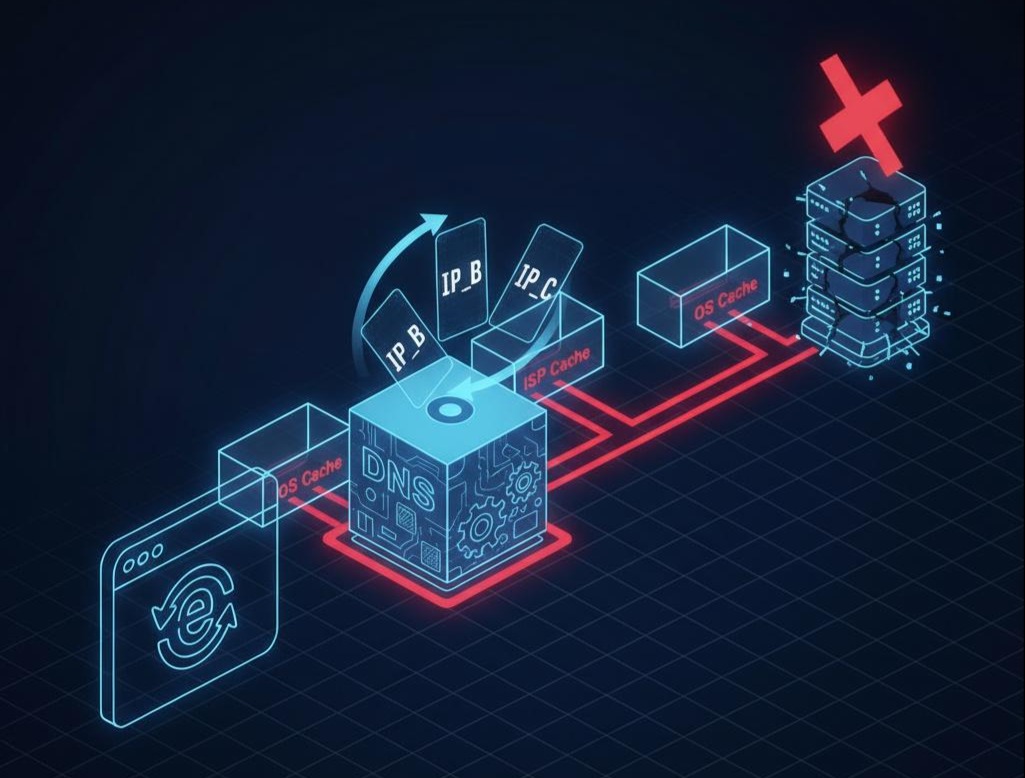
- “谎言”的传播——失控的缓存:比撒谎更可怕的,是这个谎言会像病毒一样被缓存。DNS系统为了效率,设计了一套层层缓存的机制。你的解析结果,会被ISP的DNS服务器、公共DNS(如8.8.8.8)、公司的网关、甚至你自己的操作系统和浏览器缓存起来。
灵魂拷问:我们在DNS记录里设置的那个TTL(Time-to-Live),比如60秒,真的意味着60秒后缓存就一定失效吗?
残酷的真相:不是。 TTL仅仅是一个“建议”。很多不规范的DNS服务器或客户端,可能会无视这个建议,缓存更长的时间。这意味着,当你发现IP_A故障,并火速从DNS记录中删除它时,你其实只是阻止了未来的解析请求拿到这个坏IP。对于那些已经缓存了它的海量用户而言,在他们的缓存过期前(这个时间你无法控制),IP_A就是他们唯一认定的“真理”。这种故障切换的“非确定性延迟”,在严肃的生产环境中是不可接受的。
架构师的启示:
DNS负载均衡,因其“高延迟、难控制、弱健康检查”的原罪,绝对不能作为服务高可用的核心依赖。它更像是一个粗略的“区域向导”,而不是一个精准的“门牌号”。它的最佳定位是:
- GSLB(全局负载均衡)的底层载体:将用户引导到离他最近的、健康的区域入口。
- CDN内容分发:将用户对静态资源的请求,解析到离他最近的CDN边缘节点。
第二章:四层负载均衡——内核世界的“手术刀”式转发
当流量穿越了DNS的迷雾,抵达你数据中心的“大门”(物理网关)时,它将遇到第一个真正意义上的、高性能的“交通枢纽”——四层负载均衡器。这里的“四层”,指的是OSI七层模型中的传输层,它只关心IP地址和TCP/UDP端口号。
四层负载均衡器像一个埋头工作的、不苟言笑的外科医生。它不对TCP连接做任何“情感交流”(不关心HTTP内容),它只做一件事:打开IP包这个“信封”,看一眼收件地址(目标IP:Port),然后根据预设的规则,快速地将这个信封,转发给后端某个真实服务器(Real Server, RS)。它的座右铭是:快,就完事了。
2.1 LVS/IPVS:Linux内核中的“流量魔术师”
LVS(Linux Virtual Server)是这个领域的无冕之王。它不是一个用户态的软件,而是直接构建在Linux内核网络协议栈中的一个模块,其核心是IPVS。这种“出身”决定了它的性能是碾压级的,因为它避免了用户态和内核态之间昂贵的上下文切换和数据拷贝。
灵魂拷问:对了,那么为什么一次用户态/内核态的切换会如此昂贵?
答案:
未来的架构师们在学习并发编程这门知识初始时,就被灌输了一种思想:重量级锁,比如synchronized会在线程竞争失败以后,导致线程的上下文切换。尤其是在进入Block之后,线程会由用户态转换到内核态,然后等到下次竞争,还需要再从内核态转到用户态,线程状态的记录和恢复有着一定的性能消耗。
这个用户态/内核态的切换涉及到CPU特权级的改变、寄存器状态的保存与恢复、内存映射的切换等一系列“重操作”。一个高性能的网络程序,其性能优化的核心,就是想尽一切办法,减少这种切换的次数。LVS从设计之初,就站在了性能的制高点。
LVS的三种核心转发模式:一场关于“转发效率”与“部署复杂度”的权衡

- NAT (Network Address Translation) - “全职网关”模式
- 原理:
- 请求(Client -> LVS -> RS):LVS收到请求包,在内核的PREROUTING钩子处,通过DNAT(目标地址转换),将包的目标IP从VIP修改为选定的RS_IP。
- 响应(RS -> LVS -> Client):RS处理完,响应包的目标IP是客户端IP,源IP是自己的RS_IP。它必须把包发回给LVS。LVS在POSTROUTING钩子处,通过SNAT(源地址转换),再将包的源IP从RS_IP修改回VIP。
- 权衡:
- 优点:配置最简单,RS无需任何特殊配置。
- 代价:LVS成为了性能的绝对瓶颈。 所有的进出流量都必须经过它进行地址转换,其吞吐能力受限于LVS自身的网卡带宽和CPU处理能力。
- DR (Direct Routing) - “三角传输”的艺术
- 原理:这是LVS性能最高、也是应用最广的模式,其思想堪称天才。
- 请求(Client -> LVS -> RS):LVS收到请求包。这次,它在内核协议栈的更底层进行操作。它不修改IP地址,而是直接修改以太网帧的目标MAC地址,将其改为选定的RS的MAC地址,然后将数据帧在二层网络上广播出去。
- 响应(RS -> Client):RS的网卡收到这个数据帧后,发现MAC地址是自己的,就会接收。然后它向上一层(IP层)递交,IP层一看,目标IP(VIP)也是自己(通过特殊配置,见下文),于是正常处理。处理完毕后,RS直接构建响应包(源IP是VIP,目标IP是客户端IP),通过自己的默认网关,直接发回给客户端,完全绕过了LVS。
- 配置的“魔法”:为了让RS能合法地处理目标IP是VIP的包,所有RS都需要在自己的lo回环网卡上配置这个VIP,并抑制ARP响应,确保在网络中,只有LVS会应答对VIP的ARP请求。
- 权衡:
- 优点:性能登峰造极。 LVS只处理请求流量(通常数据量较小),几乎无瓶颈。响应流量(通常数据量较大,如视频、网页)由RS集群直接返回。
- 代价:配置相对复杂,且**要求LVS和所有RS必须在同一个VLAN(二层网络)**内。
- TUN (IP Tunneling) - “跨越山海”的隧道
- 原理:为了解决DR模式的VLAN限制,TUN模式引入了IP隧道技术。LVS将原始的请求包,作为“货物”,封装在一个新的IP包(源IP是LVS,目标IP是RS)的“集装箱”里,再发给RS。RS收到后“拆箱”,处理完再直接响应给客户端。
- 权衡:
- 优点:可以实现跨地域、跨VLAN的负载均衡。
- 代价:有额外的IP头开销,性能略低于DR模式。
架构师的启示:

四层负载均衡,是构建大规模、高可用系统时,不可或缺的第一道防线。它就像机场的“安检口”,负责快速地将海量的人流(连接),分流到不同的登机口(七层网关集群)。
- 它的核心价值是“性能”和“高可用”。通过LVS+Keepalived,可以构建主备高可用的、能抗住千万并发连接的超高性能入口。
- 它的局限性在于“无知”。它不理解上层业务,无法进行精细化控制。因此,永远不要试图用一个四层负载均衡器,去直接代理你的微服务集群。它的正确位置,是在所有七层网关(如Nginx集群)的前面。
第三章:七层负载均衡——应用世界的“中央情报局”
当流量经过四层负载均衡这道“安检门”,来到“登机口”时,它将遇到一个更聪明的角色——七层负载均衡器。这里的“七层”,指的是OSI模型中的应用层。
与四层负载均衡器这个“沉默的搬运工”不同,七层负载均衡器是一个“语言学家”和“情报分析师”。它会与客户端建立完整的TCP连接,然后彻底地解析应用层协议报文(如HTTP/1.1, HTTP/2, gRPC)。因为它看懂了请求的全部内容——从HTTP方法、URL路径,到Header、Cookie,再到Body里的JSON——所以,它可以扮演一个“中央情报局”的角色,做出极其精细和智能的决策。
3.1 Nginx/OpenResty:编织流量的无限可能
Nginx,以其事件驱动(epoll)的异步非阻塞架构,成为了这个领域的绝对王者。而OpenResty,通过将LuaJIT嵌入Nginx,更是将这种能力推向了极致。它允许我们用几行Lua代码,去动态地、编程化地干预Nginx处理请求的每一个阶段,实现任何天马行空的流量控制逻辑。

七层负载均衡的核心能力:一场“精细化控制”的军备竞赛
- 基于内容的路由 (Content-based Routing):这是最基本,也是最重要的能力。
- 宏观路由:按Host头,将**http://a.myapp.com和http://b.myapp.com**的流量,路由到完全不同的后端集群。
- 微观路由:按Path,将**/api/users路由到用户服务,/api/orders**路由到订单服务。
- 条件路由:
- IF ($http_user_agent ~ “Mobile”) { proxy_pass http://mobile_backend; }* (如果User-Agent包含Mobile,则路由到移动端后端)
- IF ($cookie_version = “v2”) { proxy_pass http://new_version_backend; } (如果Cookie中version=v2,则路由到新版本后端)
- 高级发布策略:在生产环境“拆弹”的艺术
- 蓝绿发布:在Nginx中准备两套upstream配置,一套blue,一套green。通过一条include指令的切换和nginx -s reload,可以在毫秒级内,将100%的流量从旧环境无缝切换到新环境。
- 金丝雀发布/灰度发布:这是对系统最有挑战、也最有价值的发布方式。
- 基于权重:Nginx原生的split_clients模块,可以按IP哈希等方式,将1%的流量,稳定地切分到新版本。
- 基于内容:通过Lua脚本,我们可以实现更复杂的逻辑,比如“对于内部员工(通过特定Header识别),或者用户ID尾号为8的用户,将他们路由到金丝-雀版本。”
- SSL卸载与协议转换:
- SSL卸载:将消耗大量CPU资源的TLS加解密工作,集中在Nginx这一层完成。后端服务可以卸下重负,只处理纯粹的HTTP请求。
- 协议“翻译官”:对外,Nginx可以用HTTP/2或HTTP/3(QUIC)来与现代浏览器交互,提升前端体验;对内,它可以将这些请求,“翻译”成后端服务只支持的HTTP/1.1协议。
- 安全屏障与“门卫”:
- API认证与鉴权:通过auth_request模块或Lua脚本,可以在Nginx层,对所有进入的API请求,进行统一的Token校验、签名验证、权限检查,将非法请求在第一时间拦截。
- 速率限制(Rate Limiting):Nginx的limit_req模块,可以基于IP、Server、URI等维度,进行精细的请求速率限制,是防止API被滥用和DDoS攻击的第一道防线。
3.2 全局负载均衡 (GSLB):DNS的“超级进化体”
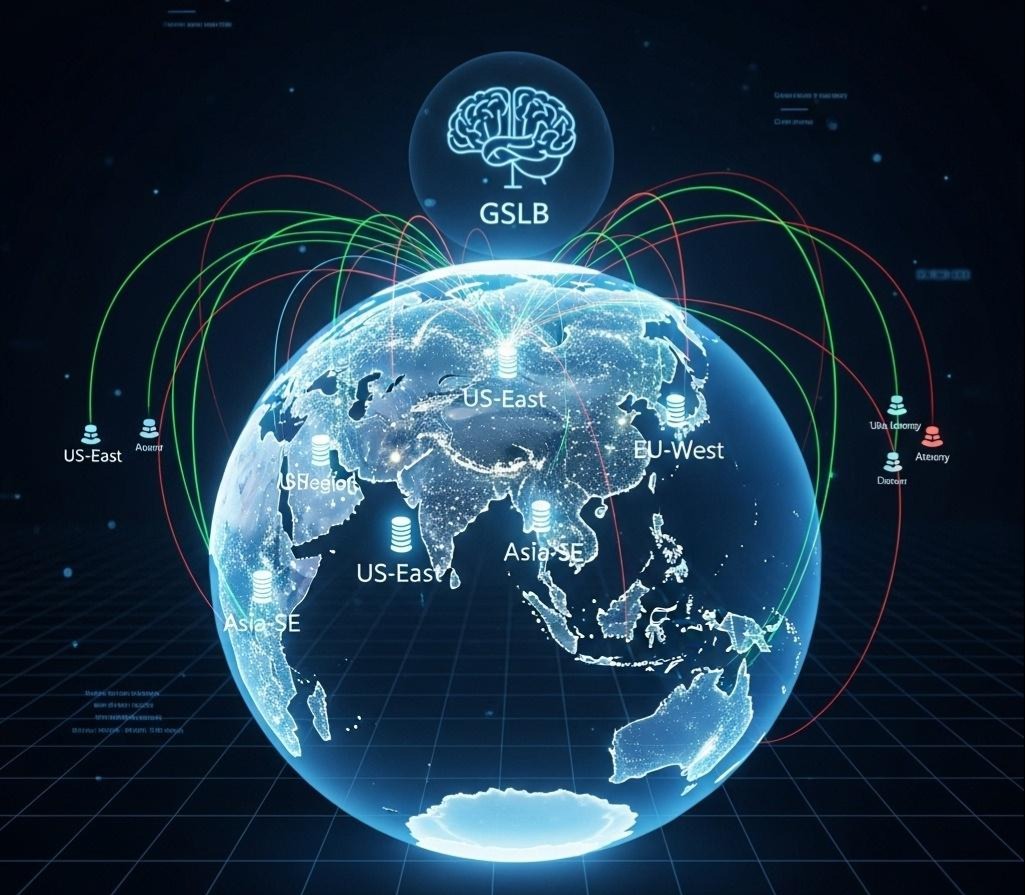
在第二章,我们指出了原生DNS的种种弊端。GSLB,就是为了治愈这些弊端而生的“智能DNS”。
灵魂拷问:GSLB和普通的DNS负载均衡,其根本区别是什么?
答案:
决策依据的“实时性”和“丰富度”。
普通DNS的决策依据,是静态的、预配置的A记录列表。而GSLB的决策依据,是动态的、实时的、多维度的数据:
- 用户来源(GeoIP):它能精确到国家、省份甚至城市级别,知道用户从哪里来。
- 节点健康状况:它会像一个勤奋的护士,从全球部署的探测点,以秒级的频率,去探测你所有数据中心的可用性(TCP探测、HTTP探测)。
- 网络质量:它能实时测量从不同区域到你各个数据中心的网络延迟(RTT)和丢包率。
- 节点负载:一些高级的GSLB,还可以与你的监控系统联动,获取数据中心的实时负载信息。
GSLB的决策过程:
当一个解析请求到达GSLB时,它会瞬间完成一次复杂的“计算”:“对于这个来自‘巴西圣保罗’的用户,考虑到‘美国东部’数据中心目前延迟最低、负载最轻,且健康状况良好,因此,我应该返回‘美东’数据中心的入口VIP。”
架构师的启示:
七层负载均衡,是你作为架构师,施展“微观调控”艺术的核心舞台。
- 它是你系统架构的“门面”。API网关的设计、路由规则的划分,直接反映了你对业务领域边界的理解。
- 它是你发布流程和质量保障的“总开关”。能否安全、平滑地进行灰度发布,是衡量一个团队工程能力成熟度的重要标志。
- GSLB是你构建“多活”容灾架构的基石。没有GSLB的智能流量调度,跨地域多活就是一句空话。
第四章:Service Mesh的黎明——从“交通枢纽”到“神经网络”的范式革命

到目前为止,我们讨论的所有负载均衡方案——无论是四层的LVS还是七层的Nginx——都有一个共同的基因:它们都是集中式的。流量像汇入江河的溪流,必须先经过一个庞大的、集中的“代理集群(Proxy Cluster)”,才能被分发到最终的目的地。这种模式,我们称之为**南北向流量(North-South Traffic)**管理,即处理从外部用户到数据中心内部的流量。它就像一个城市的“中央火车站”和“机场”,宏伟、高效,但也笨重。
然而,在微服务架构的“城市”内部,还存在着一种规模更大、复杂度指数级增长的流量——服务与服务之间的调用,我们称之为东西向流量(East-West Traffic)。这种流量,如同城市内部密如蛛网的街道、小巷和毛细血管。试图用一个“中央火车站”的模式,去精细化地管理每一条小巷的交通,显然是荒谬的。
4.1 “胖SDK”的“黄金年代”与“沉重枷锁”
在Service Mesh出现之前,我们是如何管理这片混沌的东西向流量的呢?答案是“智能客户端(Smart Client)”,或者说,“胖SDK”。
以Spring Cloud为代表的框架,就是这种模式的巅峰之作。我们将服务发现、客户端负载均衡(Ribbon)、熔断(Hystrix)、限流、分布式追踪等所有服务治理逻辑,都封装在一个功能强大的公共SDK(spring-cloud-starter-*)中,由所有业务微服务去依赖和集成。
“黄金年代”的辉煌:
在以Java为单一技术栈的时代,这套方案非常成功。它为开发者提供了开箱即 Strada 的、与业务代码高度集成的服务治理能力。
“沉重枷锁”的显现:
随着业务的发展和团队的扩大,这套模式的“原罪”开始暴露无遗:
- 治理逻辑与业务逻辑的“致命耦合”:
- 服务治理的逻辑,被“编译”进了业务应用的代码之中。这意味着,治理策略的任何一次微小的升级——比如,将熔断的超时时间从1秒改为800毫秒——都需要所有依赖该SDK的微服务,修改代码、重新编译、完整测试、打包发布。在一个拥有数百个微服务的组织里,这无异于一场协调的噩梦。
- 技术栈的“语言监狱”:
- 你为Java团队打造了一套完美的Spring Cloud全家桶。但现在,AI团队想用Python,大数据团队想用Go,前端团队想用Node.js。你怎么办?为每一种语言,都重新实现一套功能对等的、复杂的、且需要长期维护的SDK吗?这几乎是不可能的。胖SDK模式,成为了扼杀技术异构和创新的“监狱”。
- 升级的“雪崩效应”:
- 当SDK本身需要升级一个存在安全漏洞的底层依赖时(比如log4j),你需要推动全公司几百个服务,在限定时间内完成升级。这不仅仅是技术问题,更是巨大的组织协调和沟通成本问题。
灵魂拷问:这场混乱的根源是什么?
答案:我们将应用业务逻辑(处理订单、管理用户)和网络通信逻辑(如何找到服务、如何重试、如何熔断),这两个不同生命周期、不同关注点的东西,错误地耦合在了同一个运行时进程里。
4.2 Service Mesh的“创世”思想:控制权的分离与下沉
Service Mesh(服务网格)的诞生,源于一个颠覆性的、如同“政变”般的思想:
我们必须将负责网络通信和治理的逻辑,从业务应用的进程中彻底剥离出来,将其作为一个独立的、通用的“边车代理(Sidecar Proxy)”,与业务应用部署在一起。业务应用,应该回归其本质,只关心业务逻辑,对网络通信的复杂性“一无所知”。
这,就是控制权的分离与下沉。
- 架构的“政变”:
- 数据平面(Data Plane):由一系列轻量级的、高性能的Sidecar Proxy组成。在Kubernetes的世界里,这通常意味着在一个Pod里,除了你的业务容器(Application Container),还会有一个代理容器(Proxy Container)。这个Proxy(最著名的是Envoy),会通过iptables等内核机制,“透明地劫持”业务容器的所有进出网络流量。业务应用本身,对此完全无感知。它以为自己在直接和另一个服务通信,但实际上,所有的通信都被Sidecar接管了。
- 控制平面(Control Plane):一个集中的、拥有“上帝视角”的管理组件(如Istio)。它不处理任何业务流量,它的唯一职责,就是动态地向整个网格中的所有Sidecar Proxy,下发配置和策略。它就像一个“神经网络的大脑”。
这个架构,带来了什么革命性的改变?
- 治理与业务的彻底解耦:现在,你想修改全局的重试策略,你只需要在控制平面(Istio)修改一条YAML规则。这个规则会被动态地、在几秒钟内,下发到所有的Sidecar上生效。业务应用的代码,一行都不需要动。
- 语言的“解放”:因为Sidecar是独立的进程,它可以用最高性能的语言(如C++)来实现。无论你的业务应用是用Java, Go, Python, Ruby还是汇编语言写的,只要它会发网络请求,它就能被无缝地、平等地纳入到服务网格的治理体系中。技术异构的“语言监狱”被彻底打破。
- 基础设施的“标准化”:服务治理的能力,从一个需要应用去“集成”的库(Library),下沉为了一个应用可以“使用”的基础设施(Infrastructure)。这就像是从“自己发电”进化到了“使用电网”。
第五章:Istio的流量宇宙——在“量子”层面操控数据流
如果说Service Mesh是一种思想,那么Istio就是这种思想目前最强大、最成熟的实现。它为我们提供了一套“流量编程”的API,让我们能够以前所未有的精细度和动态性,去操控服务之间的流量。
让我们通过Istio的几个核心资源对象,来感受这种“量子操控”的力量。
5.1 核心资源:VirtualService, DestinationRule, Gateway
- Gateway:它定义了服务网格的入口,即南北向流量的接入点。你可以定义哪些Host和Port可以被外界访问。
- VirtualService:这是Istio流量路由的核心。它定义了“当一个请求发送给某个服务时,应该如何处理它”。它将请求的“路由规则”与后端的“真实工作负载”解耦开来。
- DestinationRule:它定义了“当流量已经被路由到某个特定服务时,这个服务的不同版本(子集)应该如何被对待”。它主要负责定义负载均衡策略、连接池大小、异常点检测等。
一个典型的灰度发布场景:
假设我们有一个reviews服务,它有两个版本:v1(稳定版)和v2(新功能版)。
第一步:定义子集 (DestinationRule)
1 | apiVersion: networking.istio.io/v1alpha3 |
这个规则告诉Istio:“对于reviews这个服务,存在两个叫做v1和v2的子集。凡是Pod标签为version: v1的,就属于v1子集。”
第二步:定义路由规则 (VirtualService)
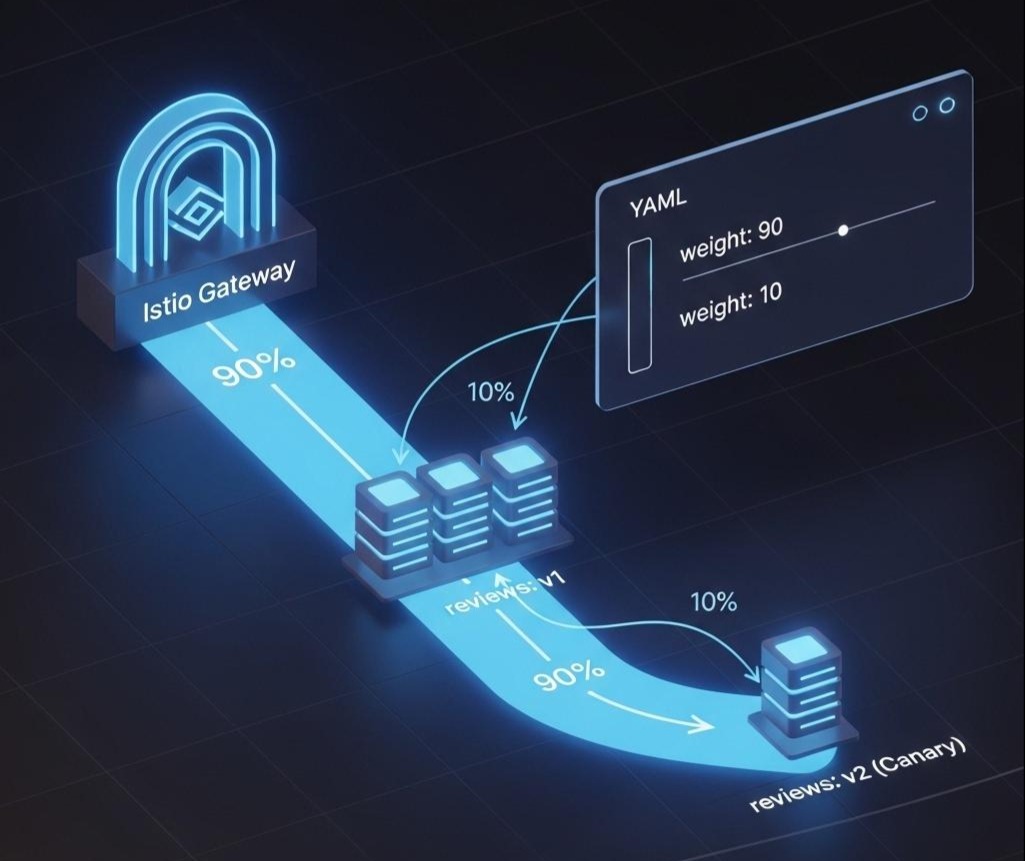
场景A:90/10的权重路由
1 | apiVersion: networking.istio.io/v1alpha3 |
这条规则将90%到reviews服务的流量,发给v1子集;10%发给v2子集。
场景B:基于Header的精准路由(流量染色/泳道隔离)
1 | apiVersion: networking.istio.io/v1alpha3 |
这条规则的含义是:“如果一个HTTP请求的Header中,end-user的值正好是jason,那么就把这个请求路由到v2版本。对于所有其他请求,全部路由到v1版本。”
深刻洞察:看到了吗?通过这样声明式的API,我们可以实现逻辑上的“测试环境”与“生产环境”的共存与隔离。测试人员(如jason)在生产环境中,可以完整地体验由所有新版本服务(reviews:v2, ratings:v2…)构成的“测试泳道”,而普通用户的流量,则完全不受影响。这种能力,对于需要快速迭代和验证的复杂系统来说,是革命性的。
5.2 故障注入:在生产环境“主动引爆”的混沌艺术

服务治理的另一大核心,是提升系统的弹性(Resilience)。但如何验证你的熔断、重试、超时策略是有效的?传统的做法是在测试环境中模拟。而Istio,则允许你在生产环境中,安全地、外科手术刀般地,进行故障注入。
示例:为ratings服务,对来自jason的请求,注入5秒的延迟
1 | apiVersion: networking.istio.io/v1alpha3 |
通过应用这条规则,你可以精确地测试:当ratings服务出现5秒延迟时,调用它的reviews服务,是否能正确地触发超时机制?
架构师的启示:
Service Mesh,特别是Istio,为我们提供了一套前所未有的、强大的系统行为编程接口。
- 它将流量治理,从一种“静态的、配置性的”工作,转变为一种“动态的、策略性的、可编程的”艺术。
- 它赋予了我们定义和验证系统“确定性”行为的能力。我们可以通过故障注入,主动地去探索系统在混沌状态下的“行为边界”,从而构建出真正有弹性的“反脆弱”系统。
结语:从“交通管制”到“宇宙法则”,流量调度的终极哲学
我们完成了一次穿越二十年技术时空的流量调度史诗之旅。从DNS的“公告板”,到LVS的“二层交换机”,再到Nginx的“中央情报局”,最后到Service Mesh的“分布式神经网络”,我们看到了一条清晰的、不可逆转的进化脉络:
控制粒度:从 IP -> URI -> Header -> 整个调用链的上下文,控制的“像素”越来越精细。
控制平面:从 静态文件 -> 集中式API -> 声明式的、动态下发的控制平面,策略的“大脑”越来越智能。
数据平面:从 集中式代理 -> 去中心化的Sidecar,执行策略的“手脚”越来越贴近“神经末梢”。
核心哲学:从单纯的“负载均衡”,进化到“流量路由”,再升华到“流量治理”,最终抵达了“系统行为编程”的全新境界。
作为架构师,理解这条进化之路,意味着你获得了在不同时代、不同场景下,为你的系统选择最合适“交通法则”的能力。
在构建宏观的、需要极致性能的系统入口时,LVS+Nginx的经典组合依然熠熠生辉。
在构建全球化的、需要低延迟和高可用性的服务时,GSLB是你手中不可或缺的“世界地图”。
而当你踏入微服务的“深水区”,面对数十上百个服务的复杂调用网络,面对多语言异构的“巴别塔”时,Service Mesh将不再是“可选项”,而是构建下一代云原生应用的“必需品”。
流量,是分布式系统的血液。而你,作为架构师,已经从一个路口指挥交通的“交警”,成长为那个能够为整个交通系统“立法”,并能预见和控制混沌的“系统立法者”。
至此,本系列的六篇深度技术长文已全部完成。我们从思维、底层、数据、共识,一路走到了流量。这趟旅程,构建了现代架构师所需的核心“硬技能”版图。

