百万架构师成长之路(7):缓存架构的极限:从CPU L1到CDN的多级缓存宇宙
导语:性能的“银弹”,还是复杂性的“地狱之门”?
在软件工程的世界里,如果说有什么技术能被冠以“银弹”之名,那无疑是缓存(Cache)。它如同一个神奇的“时间加速器”,能够将毫秒级的数据库查询、秒级的文件读取,瞬间压缩到微秒甚至纳秒级别。从CPU的L1 Cache,到操作系统的Page Cache,再到我们熟知的Redis、Memcached,乃至CDN的边缘节点,整个现代计算机体系,就是一座建立在多级缓存之上的宏伟金字塔。
我们热爱缓存,因为它能以相对较低的成本,换来用户体验和系统吞吐量的巨大提升。然而,正如物理学中的“能量守恒定律”,缓存带来的每一分性能收益,都必须用另一种代价去偿还。这个代价,就是系统复杂性的指数级增长。
你引入了缓存,就要面对“数据一致性”这个永恒的梦魇:缓存的数据和源数据不一致了怎么办?
你依赖缓存,就要防范“缓存雪崩/击穿/穿透”带来的毁灭性打击:当缓存集体失效时,你的后端系统能否扛住瞬间涌入的流量洪峰?
你享受缓存带来的高速,就要解决“热点Key”这个烫手山芋:当千万级别的请求同时涌向一个Key时,你的缓存系统本身会不会成为新的瓶颈?
对缓存的认知深度,决定了你的系统性能优化的“天花板”。 一个初级工程师,可能会把缓存看作是一个简单的SET/GET工具;而一个卓越的架构师,则必须将缓存视为一个涉及数据生命周期管理、一致性模型权衡、故障模式分析、成本效益计算的复杂分布式系统。
本篇,就是你穿越整个“多级缓存宇宙”的星图。我们将从缓存最核心的读写模式出发,深入探讨数据一致性的破解之道。然后,我们将聚焦于分布式缓存的“珠穆朗玛峰”——热点Key问题,并给出工业级的解决方案。最后,我们将手持“显微镜”,潜入Redis的源码世界,解剖其内部数据结构的精妙设计(SDS, ZipList, SkipList),并洞察其从单线程到多线程的演进之路。
这不仅是一次技术的深度解析,更是一场关于“快与慢、新与旧、得与失”的架构哲学思辨。
第一章:缓存的读写模式——构建你与数据源的“契约”
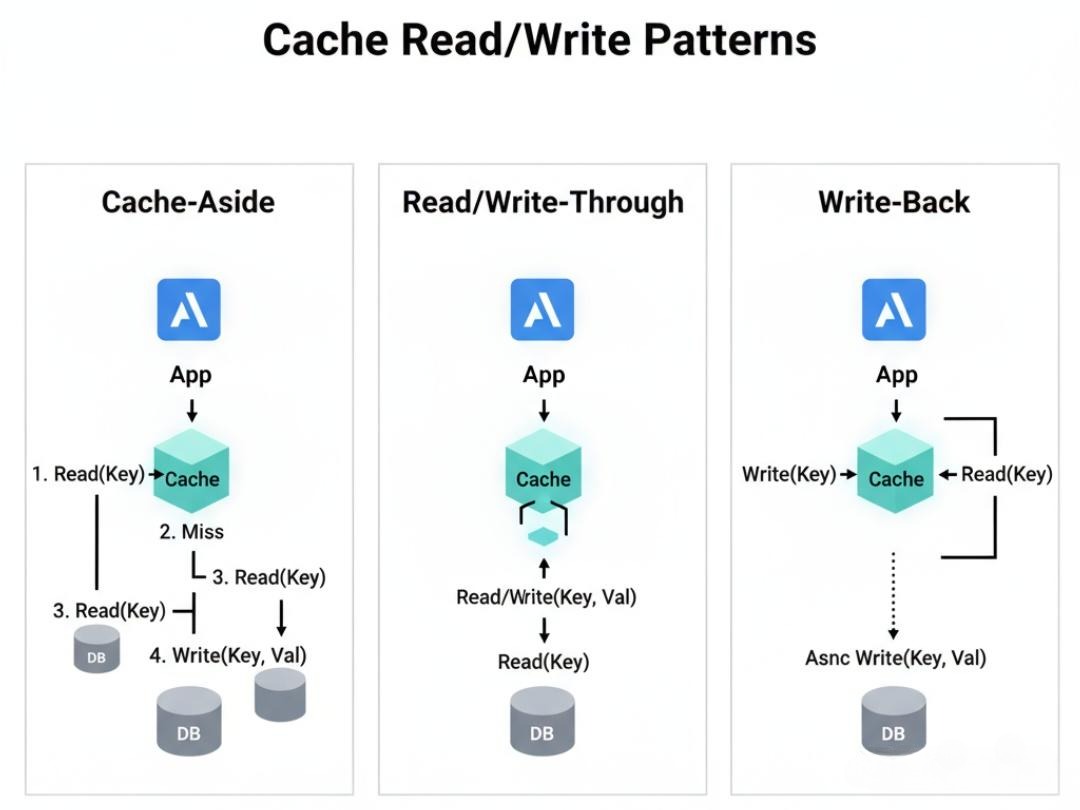
在引入缓存之前,你必须回答一个最基本的问题:你的应用程序,应该如何与缓存以及后端数据源(如数据库)进行交互? 不同的交互模式,定义了不同的“契约”,也决定了不同的性能、一致性和代码复杂度。
1.1 Cache-Aside Pattern(旁路缓存模式)——自由,但需要自律
这是我们最常用,也是最直观的一种模式。它的核心思想是:应用程序完全掌控缓存和数据源的交互逻辑。
- 读流程(Read Path):
a. 应用先从缓存中读取数据。
b. 如果缓存命中(Hit),则直接返回数据。
c. 如果缓存未命中(Miss),则由应用去数据库中读取数据。
d. 读取成功后,应用再将数据写入缓存,并返回给调用方。 - 写流程(Write Path):
a. 应用先更新数据库。
b. 然后,直接让缓存失效(DELETE the cache key)。
灵魂拷问一:为什么写操作是“删除缓存”,而不是“更新缓存”?
这是一个经典的面试题,背后隐藏着深刻的权衡。
- 更新缓存的问题(Cache Update):
a. 懒加载与资源浪费:如果你更新了一个缓存,但这个缓存数据在它的生命周期内,再也没有被读取过,那么这次CPU和网络开销就浪费了。而“删除缓存”+“懒加载”(下次读取时再写入)的模式,确保了只有被需要的数据才会被加载到缓存中。
b. 并发更新下的“脏数据”:想象一个并发场景: - 线程A发起一个写操作(比如,将值从1改为2)。
- 线程B也发起一个写操作(将值从2改为3)。
- 由于网络延迟等原因,线程B先完成了数据库更新(值为3),然后更新了缓存(值为3)。
- 紧接着,线程A完成了数据库更新(值为2),然后它也去更新了缓存(值为2)。
- 结果:数据库里的值是正确的(3),但缓存里的值却是旧的、错误的(2)!数据出现了不一致。
- 删除缓存的优势(Cache Invalidation):
- 简单、低成本:删除操作是幂等的,且开销远小于序列化和写入一个复杂的对象。
- 相对安全:它能极大地降低上述并发更新导致脏数据的概率。
灵魂拷问二:“先更新数据库,再删除缓存”这个顺序,有没有问题?
有!在极端的并发场景下,依然可能出现数据不一致。

- 场景复现:
a. 线程A发起一个读请求,缓存未命中。
b. 线程A去数据库读取了旧值(比如1)。
c. 此时,线程B发起一个写请求,更新数据库为新值(2),并删除了缓存。
d. 线程A此时拿着它之前读到的旧值(1),又写入了缓存。 - 结果:数据库里的值是新的(2),但缓存里的值却是旧的(1)!
这个问题发生的概率极低,因为它要求在一次数据库的读操作和缓存的写操作之间,发生一次完整的写操作(DB更新+Cache删除)。在大多数场景下,我们可以容忍这种短暂的不一致。但如果业务对一致性有更高要求,该如何解决呢?
1.1.1 解决方案:延迟双删(Delay Double Deletion)
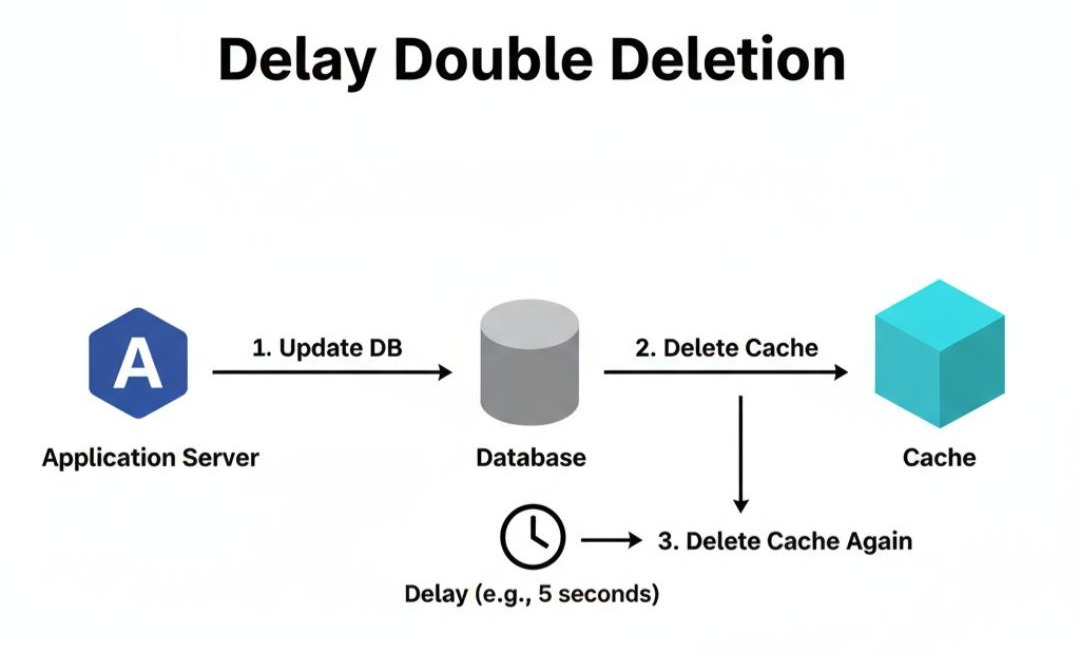
这是一种为了解决上述极端并发问题的“补丁”方案。
- 操作流程:
- 先更新数据库。
- 再删除缓存。
- 休眠一段时间(例如500ms,这个时间要大于一次“读数据库+写缓存”的平均耗时)。
- 再次删除缓存。
- 原理剖析:
第二步的删除,是为了尽快让后续的读请求能够读到新数据。而第四步的“再次删除”,则是为了兜底。
在上面的异常场景中,当线程A最终将旧数据(1)写入缓存后,线程B的延迟删除操作会确保这个脏数据被再次清除。这样,下一次读请求就会从数据库加载最新的数据(2),保证了最终一致性。 - 权衡分析:
- 优点:实现简单,能有效解决并发场景下的脏数据问题。
- 缺点:
- 性能开销:写操作的耗时至少增加了“休眠”的时间,降低了吞吐量。
- “休眠”时长难定:这个时长是一个经验值,无法100%保证覆盖所有慢查询。如果设置太长,影响性能;设置太短,可能依然无法解决问题。
- 可用性风险:如果第二次删除失败(例如服务重启),依然会存在脏数据。
架构师的启示:延迟双删是一个简单有效的“妥协”方案,但并不完美。对于一致性要求极高的场景,更可靠的方式是采用**订阅数据库变更日志(CDC)**的方案(我们将在第二章详细讨论),它能从根本上解耦业务逻辑和缓存维护。
1.2 Read/Write-Through Pattern(读/写穿透模式)——缓存的“全权代理”
在这种模式下,应用程序不再直接与数据源交互,而是将缓存视为唯一的数据源。由缓存服务自身,来负责与后端数据源的同步。
- 读流程(Read-Through):
a. 应用向缓存请求数据。
b. 如果缓存命中,直接返回。
c. 如果缓存未命中,由缓存服务自己去调用后端数据源加载数据,加载成功后,写入自身,再返回给应用。 - 整个过程,对应用来说是同步的、透明的。
- 写流程(Write-Through):
a. 应用向缓存写入数据。
b. 缓存服务收到写入请求后,首先同步地将数据写入到后端数据源。
c. 数据源写入成功后,缓存服务再更新自身的缓存。
d. 最后,向应用返回成功。
权衡分析:
- 优点:
- 逻辑简单:应用层的代码变得非常干净,因为它只需要和缓存打交道。
- 强一致性:由于写操作是同步的,可以保证缓存和数据库之间的数据一致性。
- 缺点:
- 性能损耗:每次写操作,都必须等待后端数据源写入完成,这使得写入性能受到了数据库的限制,缓存的“高速写入”优势没有完全发挥。
- 实现复杂:它要求缓存服务本身(或其客户端库)支持与特定数据源的集成,通用性较差。
1.3 Write-Back Pattern(回写模式)——性能的“极限冲刺”
这是性能最高,但一致性最弱、风险也最高的一种模式。它在计算机的CPU Cache、操作系统的文件系统中被广泛使用。
- 工作流程:
a. 所有读写操作,都只和缓存交互。
b. 当有写入操作时,数据只写入缓存,并将该缓存块标记为“脏(Dirty)”,然后立即向应用返回成功。
c. 缓存服务会异步地、批量地,在未来的某个时间点(比如,每隔一段时间,或者当脏数据积累到一定量时),将这些“脏”数据,一次性地“刷(Flush)”回后端数据源。
权衡分析:
- 优点:
- 极致的读写性能:因为所有操作都在内存中完成,几乎没有I/O等待。它能轻松地应对海量的写入洪峰。
- 缺点:
- 数据丢失风险:如果缓存服务在“刷盘”之前宕机,那么那些还未持久化的“脏”数据,将永久丢失。
- 一致性弱:数据在写入缓存和写入数据库之间,存在较长的时间窗口,不一致性是常态。
架构师的启示:
选择哪种缓存模式,不是一个技术问题,而是一个业务决策。你必须深刻理解你的业务场景,对性能、一致性、成本、可用性这几个维度进行权衡。
- 对于绝大多数互联网应用(读多写少,能容忍短暂不一致),Cache-Aside是最灵活、最通用的选择。
- 对于需要强一致性,且写入性能要求不高的场景(如配置数据),Write-Through可以简化应用逻辑。
- 对于那些可以容忍数据丢失,但对写入吞吐量要求极高的场景(如日志记录、计数器),Write-Back是终极的性能猛兽。
第二章:数据一致性与缓存灾难防御
引入缓存后,我们实际上是在系统中创建了数据的“副本”。如何维护副本与源数据的一-致性,以及如何防范副本失效带来的系统性风险,是所有分布式系统都必须面对的核心难题。
2.1 最终一致性与“失效策略”
对于大多数互联网场景,我们追求的并非银行级别的“强一致性”,而是“最终一致性(Eventual Consistency)”。我们容忍数据在短时间内不一致,但要求它最终能达到一致状态。
实现最终一致性的核心手段,就是缓存失效策略:
- TTL (Time-to-Live) / TTI (Time-to-Idle):
- 为每个缓存Key设置一个过期时间。这是保证最终一致性的“兜底”方案。即使前面提到的“先更新DB,后删缓存”的并发问题导致了脏数据,这个脏数据最多也只会存活一个TTL的时间。
- 选择合适的TTL:TTL的选择,是一门艺术。太短,会导致缓存频繁失效,穿透到数据库,失去缓存的意义;太长,则会增加数据不一致的风险。你需要根据业务对数据“新鲜度”的容忍度来决定。
2.主动失效(Active Invalidation):
- 就是我们前面讨论的,在数据更新时,主动去DELETE缓存。
- 更可靠的主动失效:为了解决“后删缓存”失败(比如,应用在删除缓存前崩溃)的问题,可以引入更可靠的机制,比如:
- 消息队列:将“失效缓存”这个动作,作为一个消息,发送到消息队列中。由一个独立的、可靠的消费者服务,来负责执行缓存删除。
- 订阅数据库变更日志(CDC):通过Canal等工具,订阅MySQL的binlog。当监听到数据表发生变更时,自动地去失效对应的缓存。这是目前业界最流行、最可靠的方案,它将缓存管理逻辑与业务代码彻底解耦。
2.2 缓存的经典“灾难”与防御工事
- 缓存穿透 (Cache Penetration):
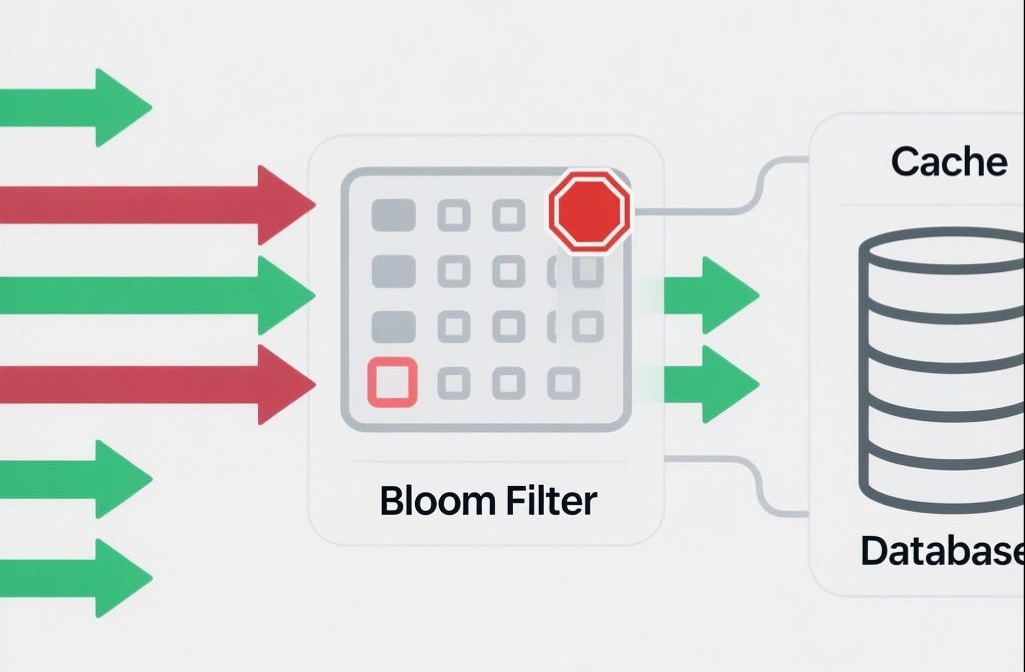
现象:攻击者或恶意用户,故意请求一个在数据库中根本不存在的数据。由于缓存中也没有,这个请求会每次都穿透到数据库,导致数据库压力剧增。
防御:
i. 接口层校验:对请求参数进行合法性校验,比如用户ID格式是否正确。
ii. 缓存空对象(Cache Nulls):当从数据库查询一个不存在的数据时,我们依然在缓存中,为这个Key缓存一个特殊的“空值”(比如一个约定的字符串”NULL”),并设置一个较短的TTL。这样,后续对这个Key的请求,就会直接命中缓存的“空值”,而不会再穿透到数据库。
iii. 布隆过滤器(Bloom Filter):在缓存之前,再加一道布隆过滤器。将所有可能存在的数据,都哈希到这个位图中。当一个请求来时,先去布隆过滤器查询。如果布隆过滤器说“一定不存在”,就直接拒绝;如果说“可能存在”,才允许它去查询缓存和数据库。缓存雪崩 (Cache Avalanche):

现象:在某个瞬间,大量的缓存Key,同时集体失效(比如,它们的TTL在同一时刻到期)。这导致海量的请求,在同一时刻,全部直接打向了数据库,如同雪崩一样,瞬间压垮数据库。
防御:
i. 过期时间加随机值:在设置TTL时,不要都设置为固定的3600秒,而是在一个基础值上,加上一个随机数(比如 3600 + random(1, 300))。这样,它们的失效时间就被“打散”了。
ii. 设置热点数据永不过期。
iii. 加锁/队列:在Cache-Aside模式的“读流程”中,当缓存未命中时,不要让所有的线程都去查数据库。可以引入一个分布式锁,只允许第一个拿到锁的线程去查询数据库和回写缓存,其他线程则等待或直接返回一个“系统繁忙”的提示。缓存击穿 (Cache Breakdown):
现象:这是“雪崩”的一个特例。指的是某一个极度热门的Key(热点Key),在它失效的瞬间,遭到了海量的并发请求。这些请求全部未命中,于是集体涌向数据库,导致数据库压力剧增。
防御:核心思想和“雪崩”中的“加锁”类似,就是防止海量并发去重建一个缓存。使用分布式锁是标准的解决方案,但这其中又分为阻塞和非阻塞两种策略,对应不同的业务取舍。
缓存击穿的防御方案详解
方案一:互斥锁(阻塞方案)
这是最经典的处理方式,确保同一时间只有一个线程去重建缓存。
- 工作流程(伪代码):
1 | function getData(key) { |
- 权衡分析:
- 优点:强一致性。一旦缓存重建完成,所有线程都能获取到最新的数据。逻辑简单直观。
- 缺点:性能较低。大量线程会因为获取不到锁而进入休眠、自旋等待,造成线程堆积和上下文切换开销,吞吐量会下降。
方案二:逻辑过期(非阻塞方案)
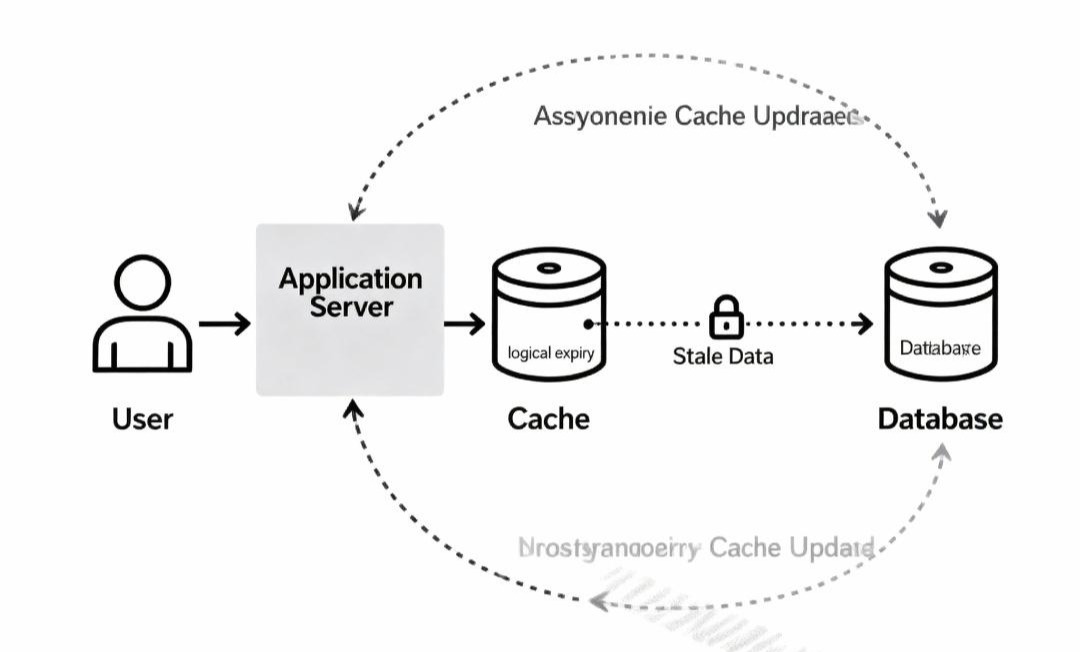
这是一种以“短暂数据不一致”换取“极致高可用”的方案,更适合对性能要求极高的场景。
- 核心思想:数据在缓存中不设置真正的物理过期时间(TTL),而是在Value中存入一个逻辑过期时间。当发现数据“逻辑过期”时,由一个线程去异步重建,其他线程立刻返回旧数据。
- 数据结构:
{ "data": "...", "expireAt": 1688888888 } - 工作流程(伪代码):
1 | function getDataWithLogicalExpire(key) { |
- 权衡分析:
- 优点:极致的性能和高可用性。请求永远不会因为等待缓存重建而阻塞,系统吞吐量极高。
- 缺点:非强一致性。在缓存重建期间,用户会访问到一段时间的旧数据。实现逻辑相对复杂,还需要考虑数据预热(冷数据第一次访问如何处理)。
第三章:热点Key问题的“攻坚战”——从“单点过热”到“分布式火焰”
前面讨论的缓存击穿,已经让我们窥见了热点Key问题的冰山一角。在一个大规模的系统中,热点Key问题,远比“单个Key失效”要复杂和凶险。它更像是一场无法预测的“森林大火”,在某个瞬间,因为一个热点事件(比如,一位明星发布了一条微博、一个爆款商品开始秒杀),千万级别的流量会瞬间聚焦到一两个Key上。
此时,你的缓存系统将面临一场严峻的考验:
- 流量集中的“单点瓶颈”:即使你的缓存集群有数百个节点,但对于一个特定的Key,根据哈希路由规则,所有请求都会被路由到同一个Redis节点上。这个节点的网卡带宽、CPU、连接数会瞬间被打满,成为整个系统的瓶颈,进而影响到该节点上的其他所有Key。
- 缓存重建的“惊群效应”:一旦这个热点Key失效,可能会有数万个Web服务器进程,在同一时刻,发起了对数据库的同一行数据的查询,并试图重建缓存。这会瞬间压垮数据库。
解决热点Key问题,需要一套立体的、多层次的防御体系。
3.1 识别与预警:战争的“情报系统”
在问题发生之前,识别出潜在的热点Key,是成功应对的第一步。
- 客户端/业务层预估:对于可预见的热点事件(如秒杀活动、计划中的营销推广),可以在业务代码中,主动识别出这些Key,并进行预热。
- 代理层实时分析:在流量的入口处(如Nginx/OpenResty层),通过Lua脚本,实时地对请求的Key进行采样和统计,当某个Key的访问频率超过阈值时,触发报警或自动的热点保护机制。
- Redis服务端监控:Redis 4.0之后提供了
HOTKEYS特性(通过修改maxmemory-policy为LFU策略开启),可以近似地统计出访问频率最高的Key。也可以通过MONITOR命令(性能损耗较大,慎用)来实时监控。 - 开源解决方案:一些开源项目,如美团的flame,字节跳动的hotkey,通过对客户端、代理层或服务端进行增强,提供了成熟的热点Key发现和解决方案。
3.2 分而治之:瓦解“单点风暴”的艺术
一旦识别出热点Key,核心的解决方案就是“分而治之”——将集中在一个Key、一个节点上的巨大流量,打散到多个Key、多个节点上去。
方案一:二级缓存(Two-Level Cache)——纵深防御
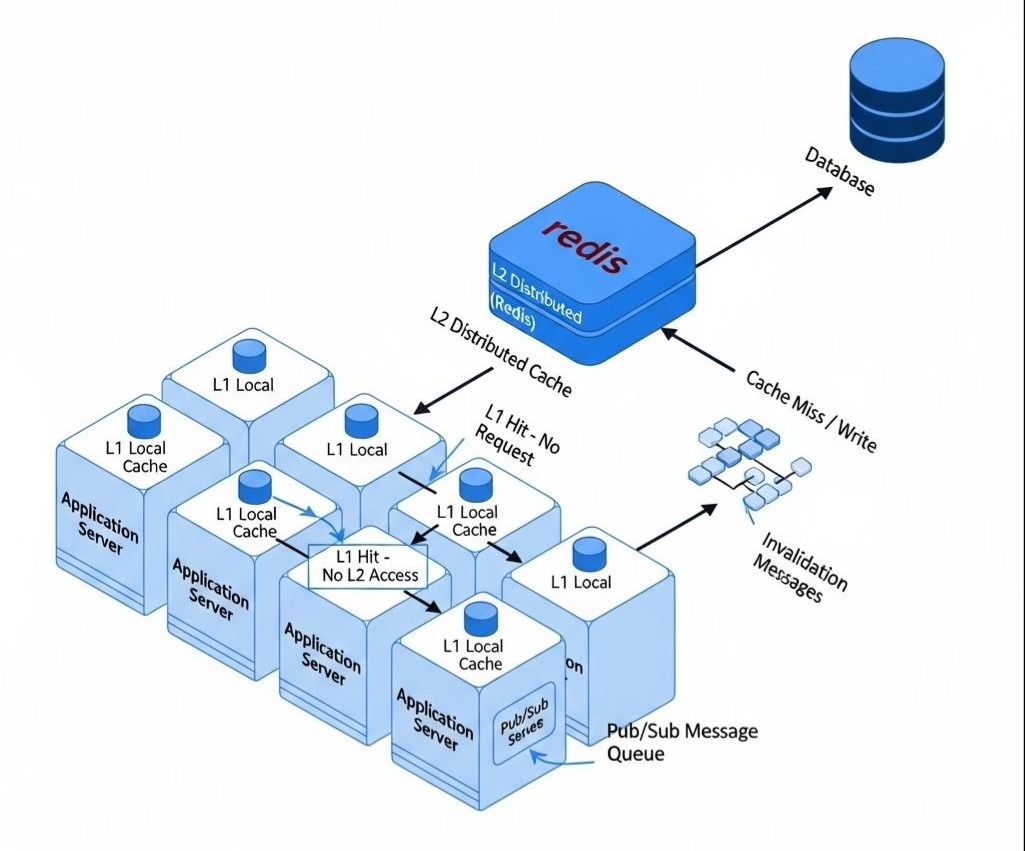
这是业界最经典、最通用的解决方案。它在原有的“集中式缓存(如Redis集群)”之前,增加了一层“本地缓存(In-Process Cache)”。
架构:
L1 Cache(一级缓存):本地缓存。部署在应用服务器(Web Server)的进程内部。可以使用高性能的本地缓存库,如Google的Guava Cache,或者更专业的Caffeine。
L2 Cache(二级缓存):分布式缓存。即我们原来的Redis集群。
读流程:
a. 应用先从自己的L1本地缓存中查找数据。
b. 如果L1命中,直接返回。绝大部分对热点Key的读请求,在这里就被终结了。
c. 如果L1未命中,再去L2分布式缓存中查找。
d. 如果L2命中,将数据返回,并写入L1本地缓存。
e. 如果L2也未命中,则回源到数据库,查询成功后,同时写入L2和L1。数据一致性挑战:
引入本地缓存后,数据一致性的问题变得更加复杂。当一个Key在数据库中被更新,并删除了L2缓存后,如何通知所有应用服务器,去失效它们各自的L1本地缓存?
解决方案:发布/订阅机制。
i. 当一个写操作删除了L2缓存后,它会额外地向一个消息总线(如Redis的Pub/Sub, RocketMQ, Kafka)发布一条“缓存失效”的消息,消息内容就是被删除的Key。
ii. 所有的应用服务器,都订阅这个消息总线。
iii. 当它们收到失效消息后,就去删除自己本地的L1缓存中对应的Key。
深刻洞察:二级缓存体系,用“增加了一层缓存”和“引入了发布订阅机制”的复杂性,换取了对读热点的极致防御能力。它将99%的读流量,“就地消化”在了应用服务器内部,极大地保护了后端的分布式缓存和数据库。
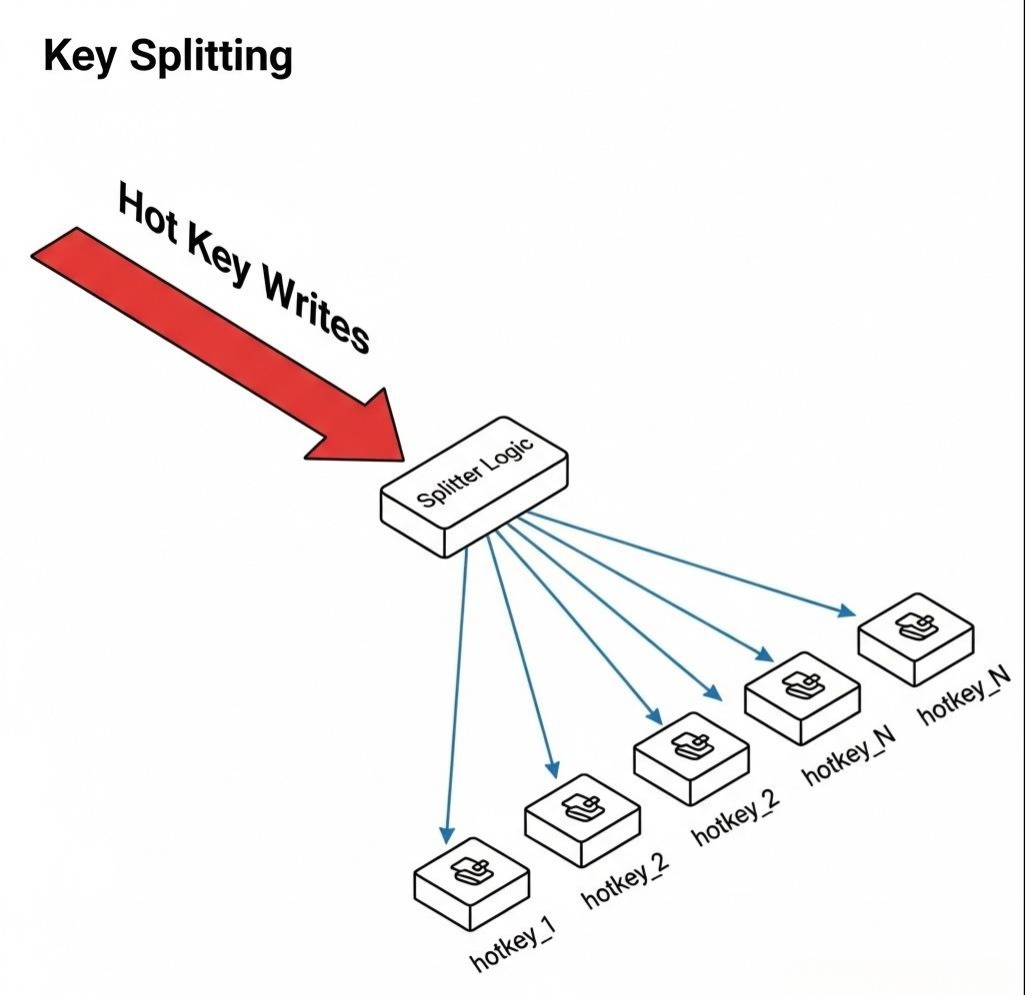
方案二:Key的“分身术”
对于写热点(比如一个秒杀商品的库存计数器),二级缓存无能为力。此时,我们需要对Key本身进行“拆分”。
- 原理:将一个热点的
hot_key,复制成多个带有不同后缀的“分身”Key,如hot_key_1,hot_key_2, …,hot_key_N。 - 写入时:随机选择一个后缀,对其中一个“分身”Key进行写入。例如,
INCR hot_key_random(1, N)。 - 读取时:需要
GET所有的“分身”Key,然后在应用层进行聚合(比如求和)。 - 权衡:
- 优点:将一个Key的写压力,成功地、均匀地分散到了N个Key上,也就可能分散到了N个不同的Redis节点上。
- 缺点:读取逻辑变得复杂,且存在短暂的数据不一致(当你聚合时,某个分身的写入可能还未完成)。
架构师的启示:
热点Key问题,没有“银弹”。它是一个典型的“权衡”问题。
- 二级缓存,是读热点的终极解决方案,但它增加了架构的复杂度和对消息总生的依赖。
- Key分身术,是写热点的有效手段,但它牺牲了读取的便利性和强一致性。
作为架构师,你需要像一个老中医一样,对你的业务流量进行“望闻问切”,识别出热点的类型(读/写)、周期性、可预测性,然后开出最对症的“药方”。
第四章:Redis的“心脏”探秘——从数据结构到线程模型
我们每天都在使用Redis,但我们真的了解它为何如此之快吗?它的快,不仅仅是因为它在内存中,更是源于其内部一系列极其精妙的、教科书般的设计。
4.1 数据结构的“空间换时间”艺术
Redis对外暴露了5种基本数据类型(String, List, Hash, Set, ZSet),但其内部实现,远比这要丰富和复杂。Redis会根据存储内容的大小和类型,动态地选择最优的底层编码方式。
SDS (Simple Dynamic String) - 简单的“不简单”字符串
为什么不用C语言原生的
char*?
i. O(1)的长度获取:C字符串获取长度需要遍历(strlen),是O(N)的。SDS在头部用一个len字段,直接记录了字符串长度,获取是O(1)的。
ii. 杜绝缓冲区溢出:SDS在头部还有一个free字段,记录了预分配的、未使用的空间。当字符串需要增长时,如果free空间足够,就无需重新分配内存,避免了内存拷贝。
iii. 二进制安全:C字符串以\0作为结尾符,无法存储包含\0的二进制数据。SDS通过len字段来判断结尾,是二进制安全的。设计哲学:典型的空间换时间。通过增加少量头部元数据,换取了操作效率和安全性的巨大提升。
ZipList (压缩列表) - 极致的空间优化
是什么:当List或Hash中的元素数量较少,且每个元素的大小也较小时,Redis会使用ZipList来存储。ZipList是一块连续的内存,它将所有元素和元数据(如前一个元素的长度、当前元素的编码和长度)紧凑地编码在一起。
优点:内存占用极低,因为它消除了大量的指针开销。
缺点:由于是连续内存,对它的任何修改,都可能引发“连锁更新”(因为修改一个元素,可能会改变它的长度,导致它后面的所有元素的“前一个元素长度”字段都需要被级联修改)。因此,它只适合“小”数据。
SkipList (跳表) - ZSet背后的“高速公路”
是什么:ZSet(有序集合)需要支持按Score的快速范围查找,也需要支持按Member的快速查找。它内部,同时使用了哈希表(保证按Member查找是O(1))和跳表(保证按Score范围查找是O(logN))。
跳表的原理:它是一种“带有多层索引的有序链表”。除了最底层的、包含所有元素的有序链表外,它还会从下往上,随机地抽出一些节点,建立更高层次的“快速通道”或“高速公路”。查找时,先在高层“高速公路”上快速前进,再逐步下沉到低层,最终精准定位。
为什么不用红黑树:跳表的实现比红黑树简单得多,且在范围查询场景下,性能与红黑树相当,甚至更好。
深刻洞察:Redis是一个对“空间”和“时间”效率,追求到极致的艺术品。它告诉我们,没有一种数据结构是万能的。卓越的设计,源于对不同场景下,数据规模和操作模式的深刻洞察,并为此选择或创造出最恰当的实现。
4.2 线程模型的演进:从“单线程”的辉煌,到“多线程”的拥抱
Redis 6.0之前的“单线程”神话:
我们常说“Redis是单线程的”,这是一个不完全准确的描述。所谓的单线程是指Redis的“网络I/O处理”和“命令执行”,是由一个主线程,在一个事件循环(Event Loop)中,串行完成的。Redis仍然有其他后台线程或进程处理如持久化、key过期删除等任务。
- 为什么快?
a. 纯内存操作:绝大部分操作都在内存中,速度极快。
b. I/O多路复用:底层使用了epoll/kqueue等高效的I/O多路复用模型,使得单个线程可以高效地处理成千上万的网络连接,而不会阻塞在某个慢速的I/O上。
c. 避免了多线程开销:完全避免了多线程场景下,锁的竞争、上下文切换等昂贵的开销。 - 单线程的瓶颈:
- 当需要处理大的数据包(请求或响应)时,单线程的网络I/O会成为瓶颈。
- 当需要执行一些耗时的命令时(如
KEYS *,SUNION),会阻塞后续所有其他命令的执行。 - 无法充分利用现代服务器的多核CPU能力。
Redis 6.0之后的“多线程”革命:
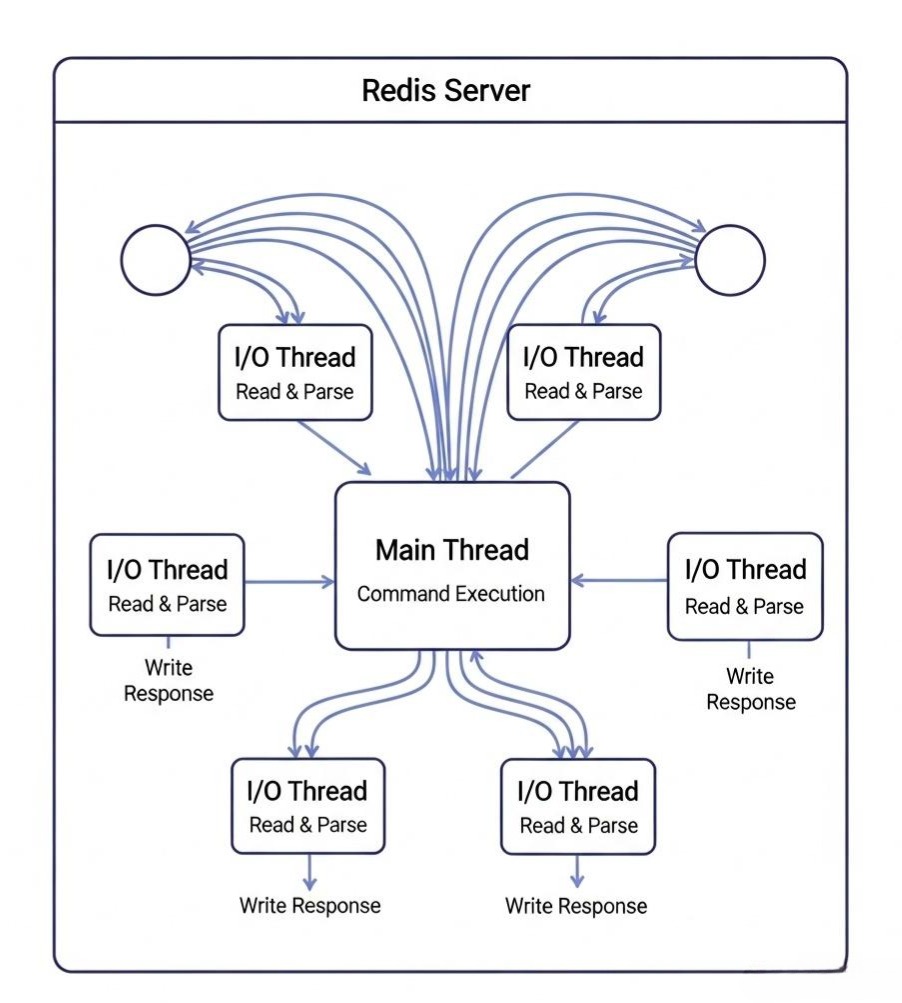
为了解决单线程的瓶颈,Redis 6.0引入了多线程I/O。
- 核心思想:将网络数据的“读写”和“解析”这个耗时的部分,交给一组I/O线程去并行处理。而**“命令的执行”,依然由主线程串行完成**。
- 工作流程:
a. 主线程负责accept新的连接。
b. 主线程将建立好的socket,公平地分发给I/O线程池。
c. I/O线程负责从socket中读取和解析客户端的命令请求,然后将解析好的命令,放入一个队列。
d. 主线程从队列中串行地取出命令,执行它。
e. 主线程将执行结果,发回给对应的I/O线程。
f. I/O线程负责将结果写回给客户端。
深刻洞察:
Redis 6.0的多线程,是一次极其克制和精准的优化。它没有将整个系统改成粗暴的多线程模型(那会破坏Redis简单的并发模型,并引入大量的锁),而是精确地将性能瓶颈点——网络I/O,剥离出来,进行了并行化处理。命令的执行依然是原子的、串行的,这保留了Redis作为“单线程”模型的所有优点。这是一种外科手术刀式的、大师级的架构演进。
结语:缓存,是架构师与“熵”的永恒战争
我们完成了这次穿越“多级缓存宇宙”的深度探索。从宏观的读写模式、一致性权衡,到中观的热点Key攻防战,再到微观的Redis源码探秘,我们看到了一条清晰的主线:
缓存的本质,是用一个“高速、小容量、昂贵”的存储,去模拟一个“低速、大容量、廉价”的存储。 这个“模拟”的过程,必然会引入不一致、不命中、易失效等一系列问题。
架构师的工作,就像是在与物理学的“熵增定律”作战。数据天然地会从“一致”走向“不一致”,系统天然地会从“有序”走向“混乱”。
你设计的缓存模式,是你与熵作战的“基本战术”。
你构建的一致性方案和灾难防御工事,是你抵御熵增的“坚固防线”。
你对底层数据结构和线程模型的深刻理解,则是你在这场战争中,能够使用的最精良的武器。
这场战争没有终点。每一个新的业务场景,每一次流量的脉冲,都是一次新的挑战。但正是通过这场永恒的战争,我们才得以在冰冷的
理定律之上,构建出温暖的、生机勃勃的、为用户带来极致体验的软件系统。

