Agent篇(1):从单体到微服务:LLM应用的服务化架构演进之路
导语:当你的“瑞士军刀”,变成了一块无法维护的“巨石”
让我们从一个令许多AI项目负责人既骄傲又痛苦的场景开始:
经过数月的努力,你的团队终于打造出了一个功能极其强大的AI应用。它不再是简单的问答机器人,而是一个集成了高级RAG(稠密、稀疏、图检索)、多工具Agent、意图路由、多模态理解等多种能力的“瑞士军刀”。在Jupyter Notebook或一个单一的Python/Java应用里,它表现完美,惊艳了所有人。
于是,你自豪地将这个“All-in-One”的应用部署上线。然而,随着用户量的增长和业务需求的变化,这把曾经引以为傲的“瑞士军刀”,却迅速变成了一块沉重、僵硬、无法维护的“单体巨石(Monolithic Application)”:
- 牵一发而动全身:你想升级一下RAG中的Embedding模型,却发现需要对整个几十万行代码的应用进行完整的回归测试,因为你无法确定这个改动是否会影响到Agent的工具调用逻辑。
- 资源利用的“木桶效应”:推理服务(Inference)需要昂贵的GPU资源且对延迟敏感,而文档解析(Parsing)和RAG索引构建(Indexing)是CPU密集型且可异步执行的长任务。将它们部署在一起,导致GPU在大部分时间里处于空闲状态,而CPU却在文档处理高峰期不堪重负,造成了巨大的资源浪费。
- 技术栈的“枷锁”:你的RAG检索部分,用Java和Elasticsearch实现性能最佳;你的推理服务,用Python和vLLM/TensorRT-LLM才能达到极致性能;你的Agent逻辑,可能用LangGraph这样的Python框架来编排最灵活。但在一个单体应用中,你被迫要在一种技术栈里“削足适履”,无法为每个组件选择最优的工具。
- 扩展性的“一刀切”:用户查询量激增,你发现系统的瓶颈在于推理服务的并发能力。但在单体架构下,你唯一的选择是复制整个庞大的应用实例,这不仅启动缓慢,而且将那些并不需要扩展的模块(如批处理的索引服务)也一并复制了,成本高昂且效率低下。
这就是AI应用在走向成熟过程中必然会遇到的**“单体之墙”**。我们用最前沿的AI技术,却构建了一个最古典的、笨重的软件架构。
本篇,我们将借鉴过去二十年里,整个软件行业从“巨石”走向“微服务”的宝贵经验,并将其与LLM应用的独特挑战相结合。我们将扮演一名**“AI系统架构师”,为我们日渐臃肿的AI应用,进行一次彻底的服务化重构**。我们将探讨:
- 为何拆分? LLM应用的哪些特性,使其天然适合微服务架构?
- 如何拆分? 遵循什么样的原则,才能将一个复杂的AI工作流,拆解成一组高内聚、低耦合的服务?
- 如何协同? 拆分后的服务之间,如何通过API网关、消息队列等机制进行高效、可靠的通信与协同?
这是一次将前沿AI能力,用成熟、经典的软件工程思想进行“约束”和“规范”的旅程。它将帮助你构建一个不仅“聪明”,而且**“健壮”、“可扩展”、“易于维护”**的生产级AI系统。
第一部分:必然之路——为何LLM应用天然适合微服务?
将一个复杂的系统拆分为微服务,并非“为了拆而拆”的技术炫耀,而是由系统本身的内在特性所决定的。LLM应用在以下几个方面,与微服务思想不谋而合。
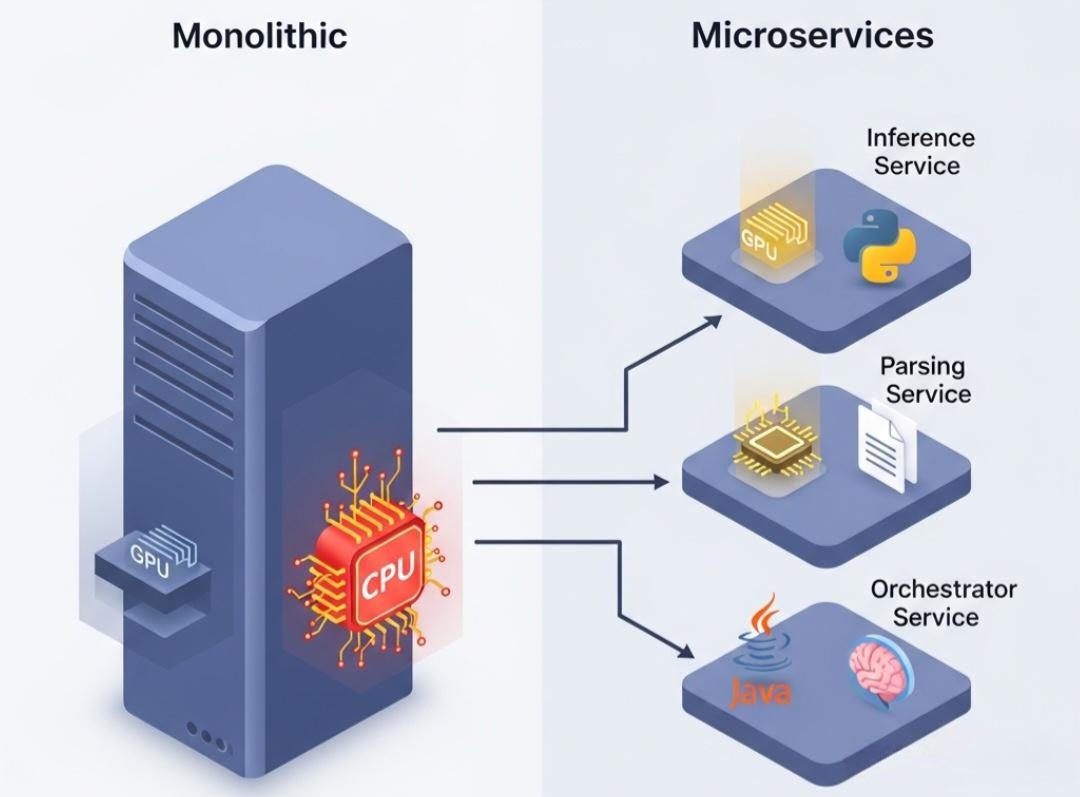
1.1 异构的计算资源需求 (Heterogeneous Resource Needs)
一个典型的、复杂的AI工作流,其不同阶段对计算资源的需求截然不同,这与传统的Web应用(通常是统一的CPU密集型)有着根本区别。
GPU密集型、低延迟敏感:
- 模型推理 (Inference):这是最典型的场景。需要昂贵的、带有大量HBM的GPU,且必须保证p99延迟在秒级以内。
- Embedding计算:无论是索引还是查询,都需要GPU进行向量化。
- 重排序 (Re-ranking):交叉编码器模型是计算密集型的。
CPU密集型、长耗时、可异步:
- 文档解析与预处理 (Parsing & Pre-processing):OCR、复杂PDF的版式分析、文本清洗等,是纯粹的CPU密集型任务,且一个大文档可能需要几分钟才能处理完。
- RAG索引构建 (Indexing):当新文档入库时,对其进行分块、向量化并写入数据库,这是一个典型的、可以离线异步执行的批处理任务。
内存密集型或I/O密集型:
- Agent逻辑与状态管理:Agent的编排逻辑本身计算量不大,但可能需要频繁读写外部状态存储(如Redis)或调用外部API。
单体架构的矛盾: 在单体架构中,所有这些需求被强行捆绑在一起。你为了满足推理的GPU需求,而为一个主要执行CPU任务的节点也配备了昂贵的GPU,造成了“资源的错配与浪费”。
微服务的解决方案: 将不同资源需求的功能拆分为独立的服务,并为它们量身定做部署环境。
- Inference-Service 部署在带有H100的GPU节点上。
- Parsing-Service 和 Indexing-Service 部署在成本低廉、高CPU配比的普通云服务器实例上,并通过弹性伸缩(Autoscaling)来应对批处理高峰。
- Agent-Orchestrator-Service 部署在轻量级的容器中,专注于逻辑编排。
1.2 异构的技术栈优势 (Polyglot Technology Stack)
AI领域的技术栈正在以惊人的速度演进,且不同语言生态各有其不可替代的优势。
Python生态:拥有无可争议的王者地位。
- 推理优化:vLLM, TensorRT-LLM 等SOTA推理框架,目前只有Python接口。
- AI框架:LangChain, LlamaIndex, LangGraph 提供了最前沿、最灵活的AI应用构建能力。
- 模型与算法:几乎所有的模型和算法实现,都首先在Python中出现。
Java生态:在构建大规模、高并发、稳定的企业级后端服务方面,拥有深厚的积累。
- 工程化与稳定性:成熟的Spring生态、强大的类型系统、丰富的中间件支持(数据库、消息队列、分布式事务),使得构建健壮、可维护的后台服务成为其强项。
- 高性能I/O:Netty等框架提供了极致的网络I/O性能。
- 大数据生态:与Spark, Flink, Kafka等大数据组件的集成非常成熟。
单体架构的矛盾: 在单体架构中,你被迫做出一个痛苦的“二选一”。选择Python,你可能要忍受其在构建高并发后端服务方面的不足;选择Java,你又无法直接利用到Python生态中最前沿的AI推理和编排框架。
微服务的解决方案: “用最合适的工具做最合适的事”。
- 用Python和vLLM构建Inference-Service,将其性能压榨到极致。
- 用Java和Spring Boot构建Agent-Orchestrator-Service,负责核心的业务逻辑、用户管理、API鉴权,并与其他企业内部系统进行集成。
- 用Python和LangGraph构建一个Planning-Service,专门负责复杂的任务规划。
- 这些服务之间通过语言无关的协议(如RESTful API或gRPC)进行通信。
1.3 独立的部署与扩展需求 (Independent Scalability)
- 单体架构的矛盾:当用户查询量激增,系统的瓶颈在于Inference-Service的并发能力时,你唯一的选择是复制整个庞大的应用实例。这不仅启动缓慢,而且将那些并不需要扩展的模块(如批处理的索引服务)也一并复制了,成本高昂且效率低下。
- 微服务的解决方案:按需、独立地扩展。你可以为一个Inference-Service配置一个包含10个GPU节点的集群,而为Parsing-Service只配置一个可以根据CPU负载自动伸缩的容器组。这种精细化的资源管理,是实现成本效益的关键。
第二部分:拆分的艺术——LLM应用的微服务设计原则
理解了“为何拆分”,下一步就是“如何拆分”。一个好的拆分方案,应该遵循高内聚、低耦合的经典原则。
2.1 按“能力”而非“流程”进行拆分
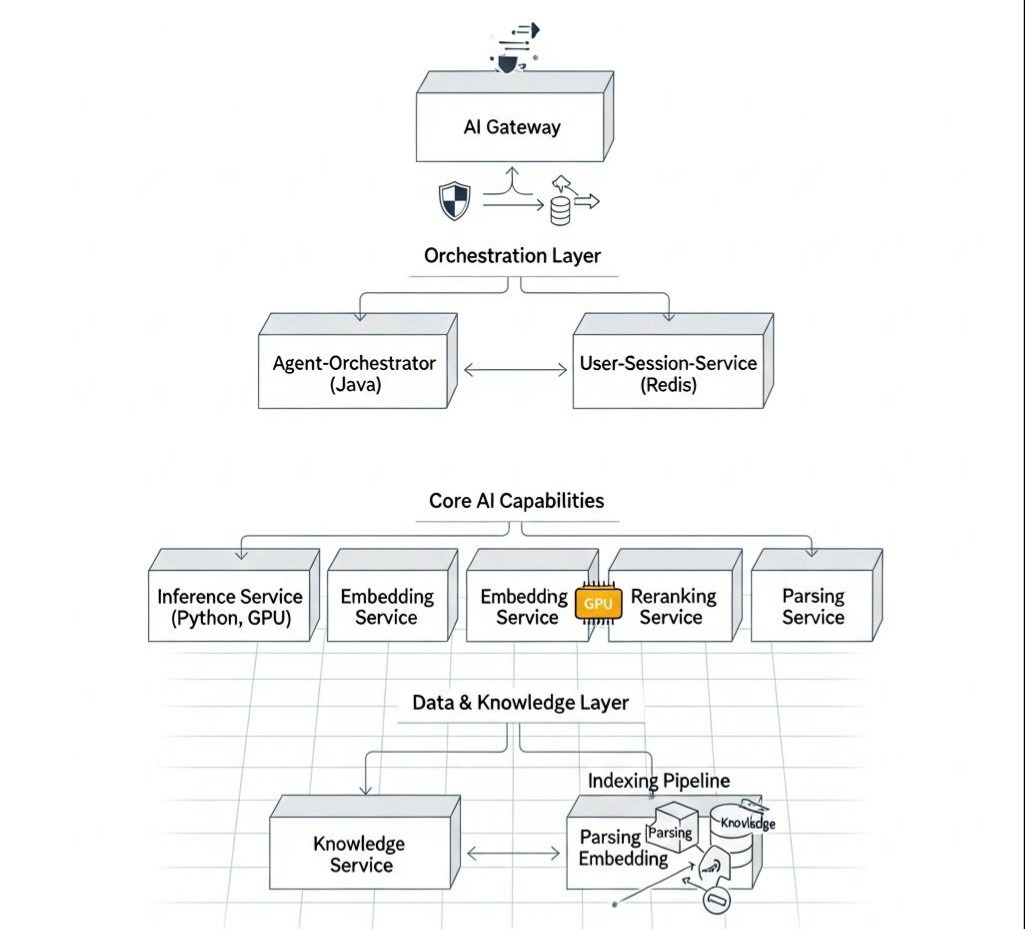
一个常见的错误是按照一个线性的RAG流程来拆分服务,例如Parsing-Service -> Embedding-Service -> Retrieval-Service -> Generation-Service。这种拆分方式导致了严重的“链式调用”,任何一个环节的故障都会导致整个流程中断,耦合度极高。
更优的拆分原则是**按“核心能力”或“限界上下文(Bounded Context)”**进行拆分。
一个推荐的、可作为起点的微服务架构蓝图如下:
- AI应用网关 (AI Gateway)
- 职责:作为所有AI能力的统一入口。负责API鉴权、请求路由、速率限制、日志记录、结果缓存。它是整个系统的“门面”和“交通警察”。
- 技术选型:Spring Cloud Gateway, Kong, Apisix等。
- 编排与业务层 (Orchestration & Business Layer)
- Agent-Orchestrator-Service (Java):这是核心的业务逻辑服务。它负责处理用户请求,调用AI网关获取各种AI能力,编排复杂的Agent工作流,并与用户数据库、订单系统等内部业务系统交互。
- User-Session-Service (Java):负责管理用户的对话历史和状态,通常使用Redis等内存数据库。
- 核心AI能力层 (Core AI Capabilities) - 通常由Python实现
- Inference-Service:提供纯粹的模型推理能力。其API接口应极其简单,如POST /generate,输入是一个Prompt,输出是生成的文本。内部可以封装vLLM或TensorRT-LLM。
- Embedding-Service:提供文本或图像的向量化能力。API接口如POST /embed。
- Reranking-Service:提供重排序能力。
- Parsing-Service:提供文档解析(如OCR)能力。这是一个典型的CPU密集型、可异步调用的服务。
- 数据与知识层 (Data & Knowledge Layer)
- Knowledge-Service (Java):封装对底层异构知识库(Milvus, ES, Neo4j)的访问。它向上层提供统一的、业务化的检索接口,如searchByHybrid(query),而将具体的数据库查询逻辑封装在内部。这实现了业务逻辑与数据存储的解耦。
- Indexing-Pipeline-Service (Java/Python):一个异步的、基于消息驱动的批处理服务。它负责监听新文档上传的事件,然后依次调用Parsing-Service, Embedding-Service,最终将处理好的数据写入Knowledge-Service。
2.2 服务间的“沟通”:同步 vs. 异步
拆分后的服务如何协同工作?我们需要在同步调用和异步通信之间做出明智的选择。

- 同步调用 (Synchronous Communication):使用RESTful API或gRPC。
- 适用场景:对于那些需要立即得到结果的、低延迟的请求-响应交互。例如,Agent-Orchestrator对Inference-Service的调用。
- Java实战:使用WebClient进行服务间调用
1 | // 在Agent-Orchestrator-Service中调用Inference-Service |
- 异步通信 (Asynchronous Communication):使用消息队列(Message Queue),如RabbitMQ, Kafka。
- 适用场景:对于那些耗时长、不需要立即返回结果、且允许最终一致性的任务。这能极大地提高系统的吞吐量和鲁棒性。
- 典型应用:索引流水线
- 用户通过前端上传一个PDF文件,请求被Agent-Orchestrator-Service接收。
- Agent-Orchestrator不直接处理,而是向Kafka的一个主题(如document.uploaded)发送一条消息,消息体包含文档的存储路径和元数据。然后立即向用户返回“文件上传成功,正在处理中”。
- Indexing-Pipeline-Service作为一个消费者,监听这个主题。收到消息后,它开始执行漫长的解析、向量化、入库流程。
- 处理完成后,它可以再向另一个主题(如document.indexed.success)发送一条通知消息。
架构师思考: 同步与异步的选择,是微服务架构设计的核心权衡之一。过度使用同步调用会导致紧耦合和“链式故障”,而过度使用异步则会增加系统的复杂性和数据一致性的挑战。一个好的设计,应该是以异步和事件驱动为“主动脉”,以必要的、有超时和熔断保护的同步调用为“毛细血管”。
结语:从“造轮子”到“造流水线”
在本篇中,我们完成了一次从AI应用开发者到AI系统架构师的视角转变。我们不再纠结于某个具体算法的实现,而是站在更高的维度,思考如何将各种异构的AI能力,组织成一个健壮、可扩展、可维护的分布式系统。
我们深刻理解了LLM应用在计算资源、技术栈和扩展性上的异构特性,这使其成为应用微服务架构的“天选之子”。
我们绘制了一幅清晰的、按“能力”拆分的微服务蓝图,并明确了Inference-Service, Knowledge-Service, Agent-Orchestrator等核心服务各自的职责与技术选型。
我们探讨了如何通过API网关进行统一治理,以及如何通过**同步(REST/gRPC)和异步(消息队列)**两种模式,实现服务间的高效协同与解耦。
从单体到微服务,我们的角色也发生了转变:我们不再是那个亲自打磨每一个“零件(AI能力)”的工匠,而是成为了设计和搭建**“现代化生产流水线”**的总工程师。我们的目标,是让每个“工位(微服务)”都能使用最专业的工具,独立地、高效地完成自己的任务,并通过一个设计精良的“传送带(通信机制)”,共同创造出最终的价值。
然而,一个分布式的系统,也带来了新的挑战。当Inference-Service突然宕机,当网络发生抖动,当某个Agent陷入死循环时,我们的“流水线”会因此全线崩溃吗?
在下一篇章 《Agent的“熔断降级”:在LLM频繁异常的时代,如何构建高可用的AI软件系统》 中,我们将为我们这套精密的微服务系统,注入“免疫力”。我们将学习如何应用熔断器、降级、超时、重试等经典的分布式系统高可用技术,来应对LLM和网络带来的不确定性,构建一个真正能在“惊涛骇浪”中稳定航行的AI系统。

