Agent篇(10):智能算子层 (Layer 2) :驯服野兽:将 LLM 封装为无状态的纯函数算子
导语:午夜 12 点的 NullPointerException
每一个试图将 LLM 接入生产环境的 Java 工程师,都经历过这样一个惊心动魄的夜晚。
那是我们上线“智能客服工单系统”的第一周。架构图画得很完美:用户输入投诉 -> LLM 提取关键信息(JSON) -> Java 后端写入数据库。
我们在 Prompt 里声嘶力竭地写道:“请务必只返回 JSON 格式,不要返回任何其他废话!”
测试环境下,GPT-4 表现得像个绅士,每次都完美返回{"category": "refund", "amount": 100}。
但在午夜流量高峰,由于网络波动或模型抽风,它突然回了一句:
“Sure! Here is the JSON you requested:\n```json\n{“category”: “refund”…”
或者更糟,它为了表示礼貌,在 JSON 结尾加了一句:“Hope this helps!”
下游坚如磐石的 ObjectMapper.readValue() 瞬间抛出异常。
更可怕的是,由于没有设计重试与纠错机制,这个异常直接击穿了整个线程池。那一晚,我们看着日志里满屏的 JsonParseException,就像看着一辆辆满载货物的卡车,因为路面上的一颗石子而连环翻车。
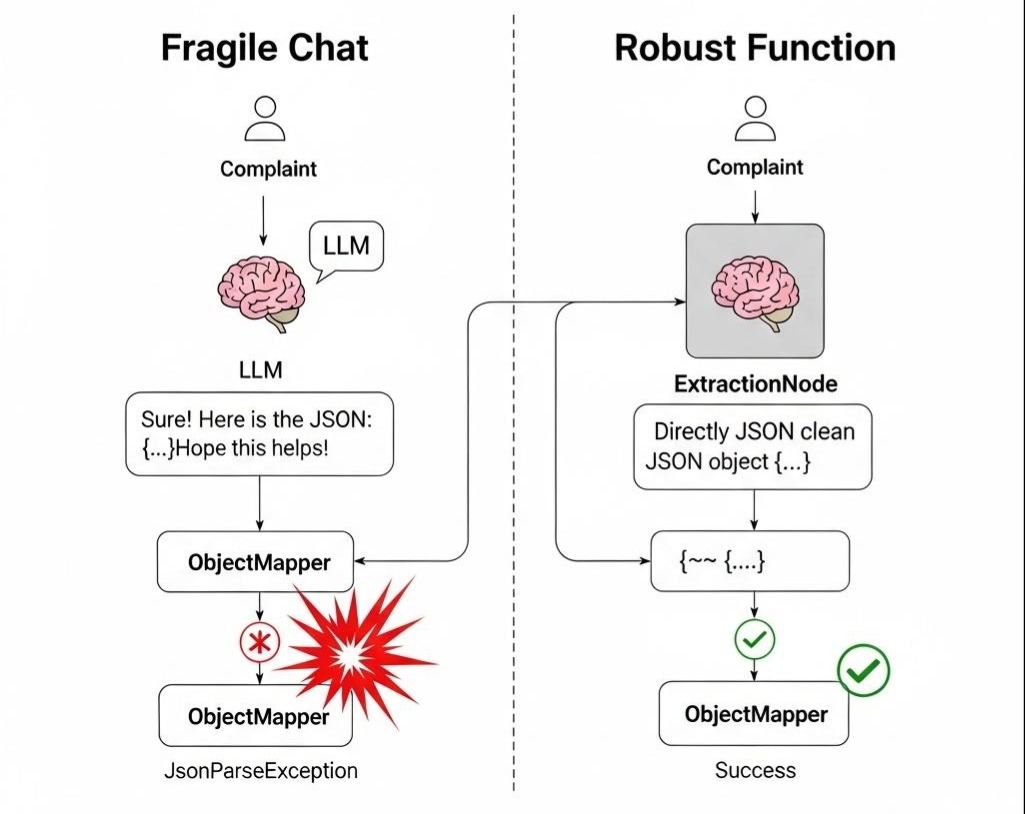
我们痛苦地意识到:如果你把 LLM 当作一个人(Chatbot)来对话,你的系统注定脆弱不堪;只有把它当作一个函数(Function)来调用,你的系统才拥有工程强度。
欢迎来到 L2 智能算子层 (Cognitive Operator Layer)。
在这里,我们的任务只有一个:在这个充满概率的量子世界里,强行制造确定性的坍缩。
第一部分:第一性原理——架构的“红线”
在深入代码之前,我们必须立下 L2 层的架构铁律。这也正是大多数 Agent 项目走向失控的起点。
1.1 纯函数 (Pure Function) 的哲学
在第一章中,我们将 L2 定义为“无状态的纯函数”。这意味着什么?
- 数学定义: f(x)=yf(x)=y。给定相同的输入 xx(Prompt + Context),必须尽可能产出相同的输出 yy(Result)。
- 工程约束:
- 无记忆(Stateless): L2 算子绝不允许私自去读写数据库,也绝不允许保留上一轮对话的历史。它只处理当下的输入。
- 无副作用(Side-effect Free): L2 算子绝不允许发邮件、改订单状态。那是 L3(工具)或 L1(代码)的事。它只负责“思考”和“转换”。
1.2 决策权的剥夺
这是最容易犯错的地方。
错误设计: 让 LLM 决定“如果是投诉,就发邮件;如果是咨询,就查库”。
正确设计: LLM 只负责输出标签 COMPLAINT 或 INQUIRY。至于“发邮件”还是“查库”,必须由 L4 控制流层的 Java 代码(Router)来决定。
为什么要剥夺 AI 的决策权?
因为 AI 是不可调试的黑盒,而代码是透明的白盒。业务流程的跳转逻辑(Business Logic)必须掌握在代码手中,而不是交给概率模型。 L2 的节点只是流水线上的高级质检员,他只负责贴标签,无权让流水线停机。
第二部分:显微镜下的分类算子 (Intent Node) —— 意图识别的工程化
让我们从最简单的场景开始:判断用户的意图。
2.1 痛点:基于 Prompt 的分类是不稳定的
你写了一个 Prompt:“如果是退款回复 A,如果是投诉回复 B。”
LLM 可能回复 “A”, “Answer: A”, “It is A”, 或者 “System A”。
你的 Java 代码里写了一堆 startsWith、contains 来清洗结果,代码脏得像下水道。
2.2 演进:Logits 约束与 Enum 映射
在工程实现上,我们不应该让 LLM 做“填空题”,而应该做“选择题”。
核心 Java 实现:
1 | // 业务意图枚举:确定性的锚点 |
第三部分:核心战役——抽取算子 (Extraction Node) 与自我修正
这是最难啃的骨头。如何让 LLM 稳定输出复杂的嵌套 JSON?

3.1 痛点:JSON 是一种脆弱的格式
少一个逗号,多一个引号,整个 Workflow 就会在反序列化阶段炸开。而且,LLM 经常会产生幻觉抽取(明明文本里没写手机号,它却编了一个)。
3.2 演进:Schema 约束与 Feedback Loop
这是 L2 层的核武器。我们不仅要利用 Function Calling,更要构建一个基于反馈的修正循环。
架构图景:LLM 生成 JSON -> Jackson 校验 -> 成功? 返回 -> 失败? 将 Exception Message 喂回 LLM 重试。
硬核代码实现:
1 | public class ExtractionNode<T> implements Node<String, T> { |
架构师启示:
这段代码展示了 L2 层的核心价值:将概率性的不确定,封装在节点内部。 对外界(L4 层)而言,ExtractionNode就是一个永远返回合法 Java Bean 的可靠函数。所有的重试、报错、纠偏,都在内部消化了。
第四部分:生成算子 (Generation Node) —— 戴着镣铐跳舞
有些场景我们需要 LLM 生成文本(如写邮件、生成报告)。这看起来最简单,但也是最容易产生幻觉 (Hallucination) 的地方。
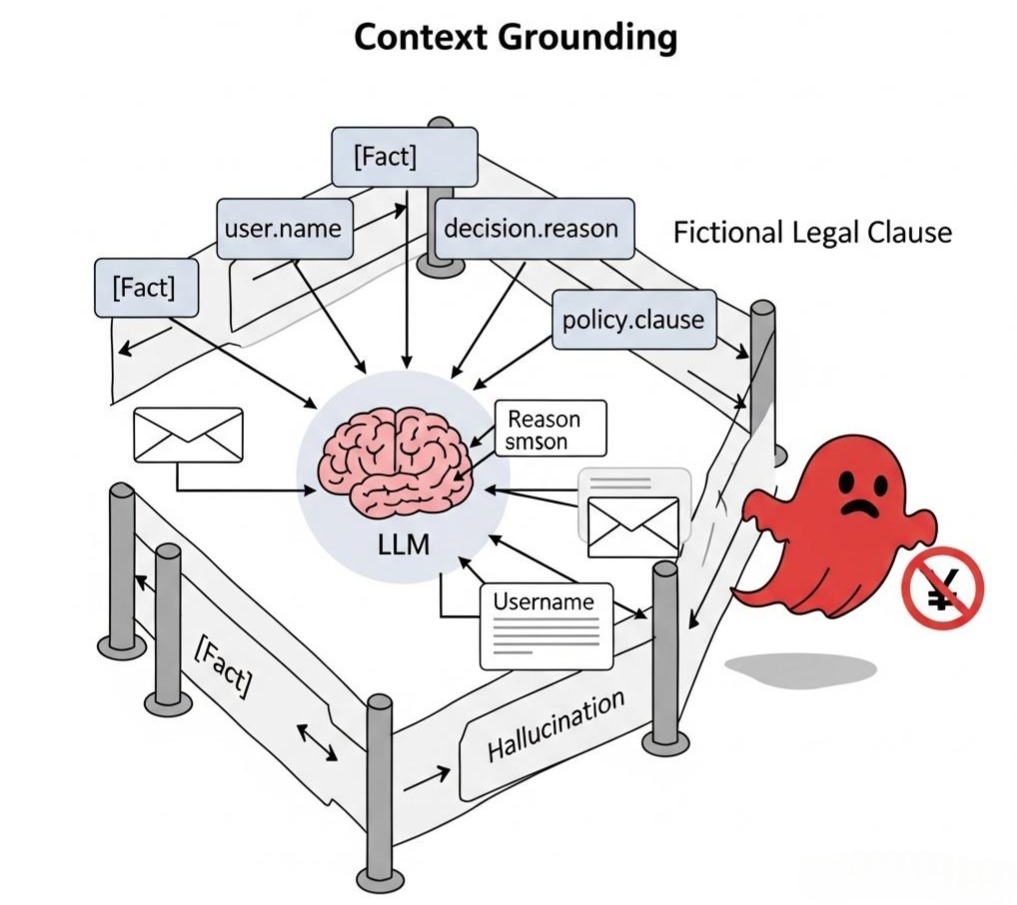
4.1 痛点:脱缰的野马
你让它写一份“拒赔邮件”,结果它自己编造了一条“根据《消费者保护法》第 200 条”——而这条法律根本不存在。
4.2 演进:Context Grounding (上下文扎根)
在 L2 层,生成算子必须遵守**“无中生有是犯罪”的原则。它只能对L1 层传入的 Context**进行修饰和润色。
Prompt Engineering as Code:
1 | String prompt = """ |
注意第 3 点。我们教给 LLM 一个**“不知道就闭嘴”的选项。**
如果检测到输出是 MISSING_INFO,L2 层节点不应该自己去查资料(违反无状态原则)。它应该诚实地将这个字符串返回给 L4 控制层。
L4 控制层看到这个返回值,会决定跳转到“人工处理分支”或者“调用搜索工具分支”。这再次印证了**“算子只产出,不决策”**的原则。
架构师的权衡 (The Architect’s Trade-off)
将 LLM 封装为 L2 算子,我们付出了什么,得到了什么?
- 延迟的代价:
一个Extractor算子可能包含“生成 -> 校验 -> 报错 -> 重试”的循环。这意味着一次 API 调用可能变成三次。
- 权衡: 在 L2 层,准确性 > 延迟。如果是实时性要求极高的场景(如自动驾驶),不要用 LLM。对于企业流程,用户宁愿等 5 秒钟得到正确结果,也不愿 1 秒钟得到一个错误结果。
- 模型的选择:
- 对于 Intent Node:推荐使用小模型(如 GPT-3.5-Turbo, Claude Haiku)。因为分类任务简单,大模型是杀鸡用牛刀。
- 对于 Extraction Node:必须使用大模型(如 GPT-4, Claude 3.5 Sonnet)。只有大模型才能理解复杂的 JSON Schema 并不折不扣地执行指令。
结语:只有一半的智商
至此,我们完成了惊险的一跃。
通过 Enum 映射、JSON 修正循环 和 Grounding 约束,我们成功地将那头不可控的野兽,驯化成了流水线上一个个听话的工人。
我们的 Workflow 现在既有 Java 的骨架(L1),又有 LLM 的肌肉(L2)。它可以读懂用户的投诉,提取出订单号,并生成一封像模像样的道歉信。
但是,它依然是无知的。
当用户问:“我的这个订单(ID: 12345)什么时候发货?”
你的 Extraction Node 完美地提取出了 order_id: 12345。
你的 Generation Node 准备好了回答模板。
但 LLM 不知道 12345 号订单的状态。 因为 LLM 的训练数据截止到 2023 年,而这个订单是 5 分钟前下的。而且,受限于 L2 层“无状态、不查库”的铁律,LLM 根本不知道这个订单号背后代表着什么。
如果此时强行生成,它只能幻觉:“亲,您的订单正在火速发往火星的路上。”
我们需要给这个大脑装上外设。我们需要打破“纯函数”的封闭,让它能查库、能搜索、能调用 API。但这项危险的权力,不能给 L2 层,必须在更外层赋予。
The Next Step:
在下一章 《L3 增强接入层:外挂大脑 —— RAG 检索增强与 MCP 工具协议的深度集成》 中,我们将赋予 LLM 访问外部世界的能力。我们将展示如何通过 RAG 注入私有知识,以及如何通过最新的 MCP (Model Context Protocol) 协议,让 Workflow 真正掌控企业的数字资产。
准备好,我们要给大脑接上互联网了。

