Agent篇(12):控制流层 (Layer 4) —— 编织迷宫:用图论与 DSL 驯服混沌
导语:脱轨的列车
1 | 如果你做过早期的 Agent 开发(比如 AutoGPT),你一定见过这种令人绝望的日志: |
等等!我们的目标不是“做红烧肉”吗?为什么跑去买手机了?
这就是 Loop of Doom (厄运循环)。
当我们将“下一步做什么”的权力完全交给 LLM 时,它就像一辆没有铁轨的列车,虽然动力强劲(L2/L3 能力强),但随时可能冲出悬崖。
在企业级生产环境中,我们不能容忍这种随机性。我们需要铁轨,需要信号灯,需要调度中心。
欢迎来到 L4 控制流层 (Control Flow Layer)。
在这里,我们的格言是:铁轨(流程骨架)必须是 Java 写的(确定性),只有车厢里的货物(数据处理)可以是 AI 做的(概率性)。
第一部分:第一性原理——DAG vs Cyclic Graph
在工作流引擎的世界里,存在两派哲学:
- DAG (有向无环图): 传统的 Airflow、Oozie。流程只能一直向前走,不能回头。
- 局限: 无法表达“如果不满意就重写”这种 Agent 最核心的**迭代(Iterative)**逻辑。
2.** Cyclic Graph (有环图):** 这里的图允许边指向它的上游节点。
- 必然性: Agent 的本质就是感知 -> 决策 -> 行动 -> 再次感知的循环。
L4 层的核心架构: 我们要构建一个状态机 (State Machine),而不是一条流水线。每个 Node 只是图中的一个顶点(Vertex),而 Edge(边)则是由业务逻辑定义的跳转规则。
第二部分:路由 (Router) —— 流程的分岔口
这是 L4 最基础的组件。它决定了数据流向左还是向右。
2.1 痛点:把 if-else 写在 Prompt 里
新手喜欢让 LLM 决定一切:
Prompt: “如果是退款,请调用退款接口;如果是投诉,请转人工…”
这在简单场景下管用,但在复杂场景下,LLM 经常会忘记规则,或者幻觉出一个不存在的分支。
2.2 演进:代码级路由
我们将决策逻辑从 Prompt 中剥离,回归 Java 代码。L2 层的 Classifier 算子只负责输出 Intent.REFUND,而 L4 层的 Router 负责根据这个 Enum 进行物理跳转。

核心代码实现:
1 | public class RouterNode implements Node<WorkflowContext, String> { |
魔鬼细节:
除了基于意图的路由,更高级的是基于语义相似度的路由 (Semantic Router)。
例如,计算用户 Query 与 100 个标准 FAQ 的向量余弦相似度。如果 max_score > 0.9,直接跳转到“FAQ 回答节点”,跳过昂贵的 GPT-4 生成。这是 L4 层帮企业省钱的关键策略。
第三部分:循环 (Loop) —— 容错与优化的引擎
没有循环,就没有智能。
人类写文章也是:写草稿 -> 读一遍 -> 修改 -> 再读 -> 定稿。这个过程就是 Loop。

3.1 场景:基于反馈的自我修正
我们在 L2 层提到过 JSON 修复循环。在 L4 层,我们要把这个模式泛化。
架构设计:
- Node A (Generator): 生成初稿。
- Node B (Evaluator): 一个专门的 Validator 算子,检查初稿质量(如:是否包含违禁词?字数是否达标?)。
Pass: 跳转到 Node C (End)。
Fail: 将错误意见注入 Context,跳转回 Node A。
3.** Circuit Breaker (熔断器):** 必须设置 max_loops = 3。否则 LLM 可能会陷入死循环,直到烧光你的 Token。
Java 引擎调度逻辑(简化版):
1 | public class GraphExecutor { |
第四部分:并发 (Parallelism) —— Map-Reduce 模式
单个 LLM 太慢?那就让十个 LLM 一起干活。
4.1 场景:长文档分块总结
你需要总结一份 1000 页的财报。即使 Context 够大,准确率也会下降(Lost in the Middle 现象)。
4.2 演进:扇出 (Fan-out) 与 扇入 (Fan-in)
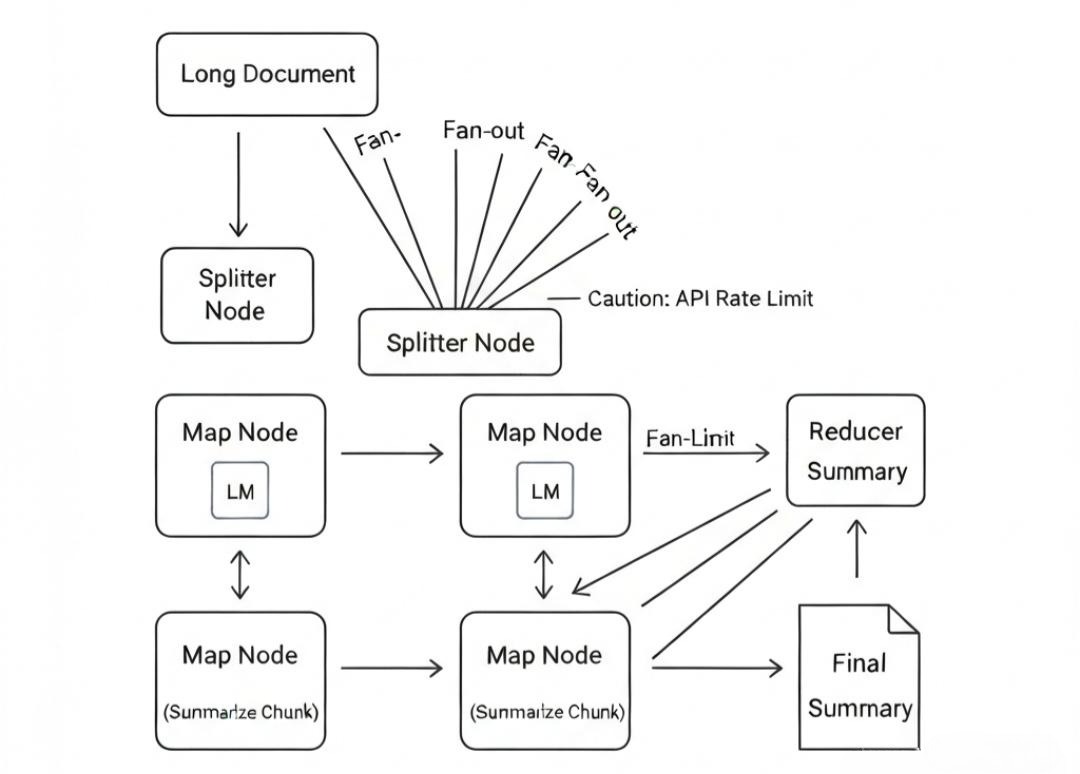
架构设计:
- Splitter Node: 将长文本切分为 10 个 Chunk。
- Map Node (Parallel): 启动 10 个并行的 LLM 线程,同时对每个 Chunk 做摘要。
- Reducer Node: 等待这 10 个线程全部结束,将 10 段小摘要拼接起来,再做一次“总摘要”。
Java 并发实现:
1 | public class MapReduceNode implements Node<WorkflowContext, Void> { |
架构师启示:
L4 层的并发控制必须极其小心。LLM 的 API 通常有 Rate Limit (速率限制)。如果你瞬间并发 100 个请求,OpenAI 会直接给你返回 429 Too Many Requests。
因此,底层的 executorService 必须配置信号量 (Semaphore) 或 令牌桶算法 来做限流。
第五部分:图即代码 (Graph as Code) —— DSL 的设计
如果每次调整流程都要改 Java 代码,那就太慢了。我们需要一种领域特定语言 (DSL) 来描述这张图。
5.1 JSON/YAML 定义
一个典型的 L4 流程定义应该长这样:
1 | nodes: |
5.2 引擎解析

我们需要编写一个 GraphLoader,将这个 YAML 配置文件解析为内存中的 Node 对象图。这使得业务人员(或者未来的 AI 架构师)可以通过拖拽 UI 生成 YAML,从而动态编排业务。
架构师的权衡 (The Architect’s Trade-off)
- 复杂度 vs 可维护性:
引入 Loop 和 Parallel 后,调试变得极其困难。如果流程卡在第 5 次循环,你怎么知道是因为 AI 每次都改不对,还是 Validator 逻辑太严苛?
- 权衡: 必须引入 Step-wise Tracing (步进式追踪)。每一个 Step 的输入、输出、耗时都必须记录在案。
2.** 死锁与竞态:**
在 Map-Reduce 模式中,如果多个分支试图修改同一个 Context 变量(如 ctx.set("status", "done")),会发生什么?
- 权衡: L4 层必须实施 Context Isolation (上下文隔离)。子分支只能写入自己的局部变量,只有在 Reduce 阶段才允许合并回主干。
结语:机器的韵律
至此,我们已经不再是在写脚本了,我们是在设计生命周期。
通过 L4 层,我们将孤立的 L1 代码、L2 算子、L3 工具,编织成了一张有节奏、有律动、可自我修复的网。
它能判断方向(Router),能自我反省(Loop),能三头六臂(Parallel)。
但这台机器目前还是**“瞬时”的。
当服务器重启,或者流程需要等待用户审批三天时,在这个内存里运行的 while 循环会断掉,Context 会消失。
我们如何让这个流程跨越时间的河流?如何实现“周五下班暂停,下周一上班继续”?
The Next Step:
在下一章 《L6 状态管理层:穿越时间 —— 持久化机制、状态机与时间旅行调试》 中(注:按我们之前的约定,L6 提前到这里讲),我们将深入分布式系统的深水区。
我们将讨论如何将内存中的图状态序列化 (Serialize)** 到数据库,如何实现Checkpointer (检查点),以及如何构建一个让开发者惊掉下巴的**“时间旅行调试器”**。
准备好,我们要冻结时间了。

