Agent篇(13):状态管理层 (Layer 6) —— 穿越时间:持久化机制、状态机与时间旅行调试
导语:消失的请假条
想象这样一个场景:
你的公司上线了一个“智能请假审批 Agent”。
员工小张提交了请假申请。Agent 完美地理解了意图(L2),查了年假余额(L3),并生成了审批单。
现在的流程走到了:“等待经理审批”。
经理正在开会,没看手机。
十分钟后,运维人员给服务器打了个安全补丁,重启了 JVM。
半小时后,经理打开手机,点击“同意”。
系统弹出报错:“Session Not Found”。
小张的请假流程,随着那次重启,彻底消失在了内存的虚空中。
这就是无状态 (Stateless) 架构的致命伤。
在传统的 Request-Response 模式下,任务是毫秒级的。但在 Agentic Workflow 中,一个任务(Task)的生命周期可能长达数天(等待审批)、数周(长周期调研),甚至数月。
我们需要一种魔法,能让运行中的代码**“冻结”,保存到硬盘上,然后在几天后,哪怕服务器换了一台,也能“解冻”**并继续运行,仿佛什么都没发生过。
欢迎来到 L6 状态管理层 (State Management Layer)。
在这里,我们对抗的敌人是:时间的不确定性和基础设施的脆弱性。
第一部分:第一性原理——内存的快照 (Checkpointing)

如何保存一个正在运行的 Java 程序的“灵魂”?
“灵魂”由两部分组成:
- 数据 (Data): 即
WorkflowContext里的所有变量。 - 指针 (Pointer): 即当前执行到了图中的哪一个 Node?如果是循环,现在是第几次?
1.1 核心概念:Checkpointer
我们不需要把每一行代码的状态都存下来(那是 OS 的休眠),我们只需要在关键节点(Node)执行完毕后,保存一张快照。
公式:
Statet=(NodeID,ContextVariables,ExecutionHistory)
每当 Agent 完成一步思考或行动,我们就像玩游戏存档一样,把这个 Tuple 序列化并写入数据库。
第二部分:序列化的艺术——将对象变成字节
把 String 存进数据库很简单。但如果 Context 里存了一个复杂的自定义对象 List<Employee> 甚至是一个 CompletableFuture 怎么办?
2.1 痛点:Java 序列化的坑
JDK 自带的 Serializable 是出了名的慢且不安全。
JSON (Jackson) 可读性好,但丢失了类型信息(Type Erasure)。
2.2 演进:结构化存储与 Type Handling
在企业级实战中,推荐使用 JSON + Type Hints 的策略,存储在 PostgreSQL 的 JSONB 字段或 Redis 中。
Java 核心实现:
1 | public class StateManager { |
魔鬼细节:
当你的类定义发生变化时(比如Employee类加了个字段),旧的 JSON 反序列化会报错。
架构师策略: L6 层必须引入 Schema Evolution (模式演进) 机制。或者更简单粗暴地:对于长周期的 Workflow,Context 里的数据结构必须设计为向后兼容 (Backward Compatible) 的。
第三部分:人机交互的基石——挂起 (Suspend) 与 恢复 (Resume)
有了持久化,我们终于可以实现最迷人的功能:Human-in-the-Loop (人机回环)。

3.1 场景:审批流
LLM 写好了邮件草稿,但不敢直接发。它需要跳转到一个特殊的节点:HumanApprovalNode。
3.2 架构实现:中断机制
当引擎执行到 HumanApprovalNode 时,它不会像普通节点那样立即执行。
它会抛出一个特殊的 控制流异常 (ControlFlowException):SuspendExecution。
引擎主循环(升级版):
1 | public void executeWorkflow(String threadId) { |
3.3 唤醒:异步回调
当经理点击“同意”按钮时,前端调用 API POST /workflow/{threadId}/resume。
后端收到请求后,重新触发 executeWorkflow(threadId)。
引擎会发现数据库里有一个存档,于是从 HumanApprovalNode 的下一个节点开始继续狂奔。
第四部分:上帝视角——不可变日志与时间旅行调试
如果你以为持久化只是为了“存盘”,那你就低估了 L6 的潜力。
我们将引入 Event Sourcing (事件溯源) 的思想。
4.1 痛点:不可复现的 Bug
LLM 在第 45 步的时候幻觉了。你对着最终的错误结果发呆,根本不知道是哪一步开始跑偏的。
你想复现,但重跑一次,LLM 这次又没幻觉了(概率性)。
4.2 演进:时间旅行 (Time Travel)
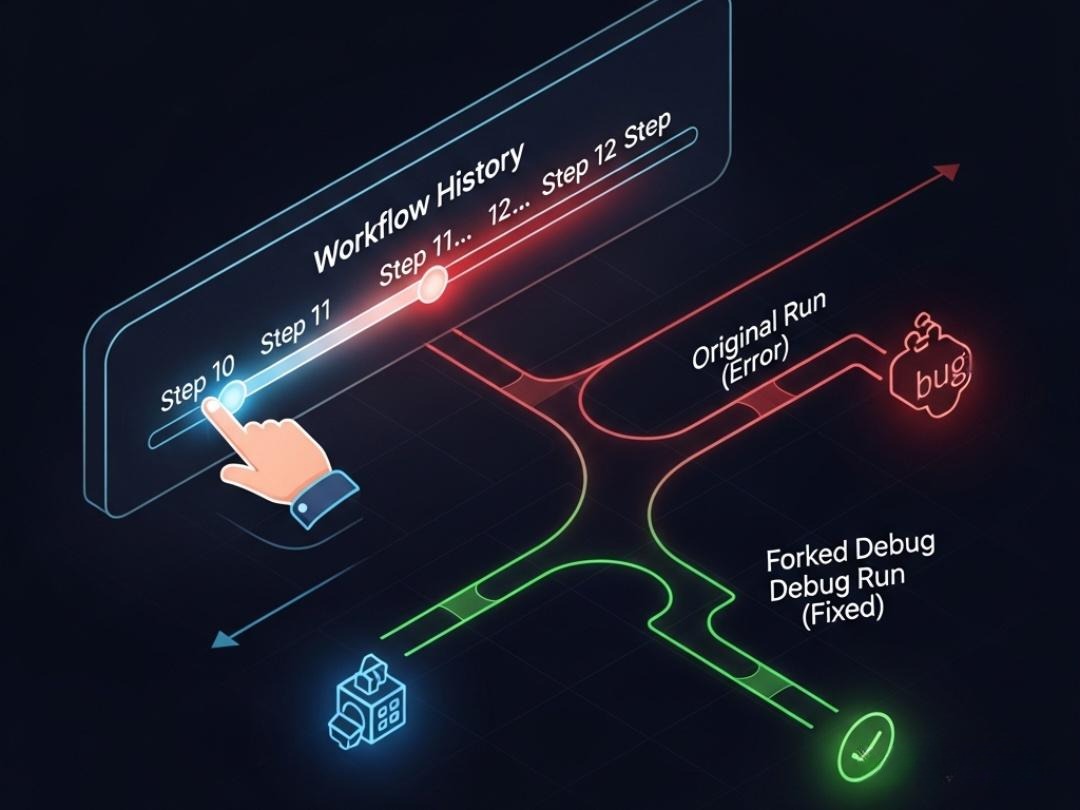
如果我们不仅仅记录“当前状态”,而是记录“每一次状态变更的快照”,会发生什么?
我们得到了一条时间轴 (Timeline)。
Debug 界面设计:
开发者的控制台有一个滑动条。
- 拖到 Step 10:看到 Context 里的
draft是 “Hello World”。 - 拖到 Step 11:看到 LLM 把
draft修改成了 “Hello AI”。
Fork (分支) 能力:
开发者发现 Step 11 是错的。他可以在 Step 10 点击 “Fork”。
系统复制当前状态,创建一个新的 thread_id。
开发者修改 Prompt,在新的分支上重新运行。
这就是 “平行宇宙” 调试法。
Java 实现思路:
不要覆盖更新 workflow_states 表。
创建一个 workflow_history 表:
1 | INSERT INTO workflow_history (thread_id, step_id, node_id, context_snapshot) ... |
每次执行完一个节点,就 Append 一条日志。
架构师的权衡 (The Architect’s Trade-off)
- 性能 vs 可靠性:
每一步都写数据库(Write-Amplification),会极大地拖慢 Workflow 的运行速度。
- 权衡: 对于纯机器执行的“快流程”,只在开始和结束时存盘。对于有人工介入的“慢流程”,每一步都存盘。或者使用 Redis 做热存储,异步刷入 PostgreSQL 做冷备份。
- 数据隐私:
Context 里可能包含用户的 PII(个人敏感信息)。把这些信息明文存入数据库合规吗?
- 权衡: L6 层必须集成 Data Encryption (数据加密)。在序列化前,自动识别敏感字段并加密;在反序列化后解密。
结语:永生的代码
至此,我们的 Agent 获得了“永生”。
它可以跨越服务器的重启,跨越网络的断连,甚至跨越数月的等待。
它拥有了记忆(History),可以回溯过去(Time Travel),也可以通过 Fork 创造平行宇宙。
我们解决了原子计算(L1)、智能算子(L2)、外部链接(L3)、逻辑编排(L4)和状态记忆(L6)。
这台机器已经极其完善了,它像一个在真空中不知疲倦运转的精密钟表。
但是,还有一个致命的问题。
它太孤独了。
现在的 Agent,就像一个被锁在地下室的天才数学家。它能解开最复杂的方程,能写出最完美的报告,但当它遇到一个模糊的条件(比如“帮我订一张性价比高的机票”)时,它只能要么瞎猜(幻觉),要么死板地抛出异常然后挂起。
它不懂得沟通。
它不知道在遇到困难时,可以给用户发一条 Slack 消息:“老板,这张票有点贵,您确定要订吗?”
它也不知道在信息缺失时,可以反问用户:“您还没告诉我您的护照号码。”
真正的智能,不仅仅是计算的能力,更是协作的能力。一个无法与人类顺畅沟通的 Agent,永远只能是一个后台进程,而成不了真正的助手。
The Next Step:
在下一章 《L5 交互协同层:人机共舞 —— 异步通信架构与 HITL 最佳实践》 中,我们将打破这层厚厚的次元壁。
我们将探讨如何设计以人为本 (Human-Centric) 的交互协议。我们将展示如何通过 Webhook、Input Request 和 Approval Flow,让冷冰冰的代码学会“说话”,学会“请示”,学会与人类在同一个频道上共舞。
准备好,我们要让这台机器开口说话了。

