Agent篇(2):Agent的“熔断降级”:在LLM频繁异常的时代,如何构建高可用的AI软件系统
导语:当“天才大脑”开始“间歇性失忆”
让我们回到那个刚刚被我们精心重构的、闪闪发光的AI微服务集群。Inference-Service在GPU上风驰电掣,Knowledge-Service稳定地提供着数据,Agent-Orchestrator有条不紊地编排着一切。你感觉自己构建了一座坚不可摧的“数字堡垒”。
然而,当真实的、混乱的生产环境流量洪峰般涌来时,这座“堡垒”的裂痕开始显现:
- 场景一:API风暴。你依赖的某个外部LLM提供商(如OpenAI、Anthropic)的API突然开始超时或返回503 Service Unavailable。由于你的Inference-Service对它进行了同步调用且没有任何保护,一个请求的阻塞迅速导致所有工作线程被占满,整个Inference-Service雪崩,进而引发上游Agent-Orchestrator的大规模超时,最终整个系统瘫痪。
- 场景二:“自嗨式循环”。一个设计不佳的Agent,在处理一个边界问题时,陷入了致命的逻辑循环。它开始疯狂地、无休止地调用RAG-Tool和Web-Search-Tool,在短短几分钟内就耗尽了你一个月的API调用预算,并产生了天量的垃圾日志,淹没了你的监控系统。
- 场景三:非预期输出。某个微调过的模型,在面对一个从未见过的输入时,突然返回了一个格式错误的JSON,或是一段包含乱码的文本。这个“毒丸”被下游服务接收后,引发了空指针或解析异常,导致整个处理链路中断,用户看到的是一个冰冷的“系统内部错误”。
你痛苦地意识到,构建一个分布式AI系统,你面对的敌人是双重的:既有传统分布式系统都会遇到的网络不可靠、服务会宕机等“经典之敌”;更有LLM时代独有的、全新的**“概率性之敌”**——模型的输出本质上是随机的,API的性能是波动的,Agent的行为是不可完全预测的。
在这个充满不确定性的新世界里,传统的、基于“一切都会按预期工作”的“快乐路径编程(Happy Path Programming)”思想,已经彻底破产。一个没有为“异常”而设计的系统,其宿命必然是在第一次“意外”来临时就粉身碎骨。
本篇,我们将为我们的AI微服务系统注入**“反脆弱”的基因。我们将扮演一名“可靠性工程师(SRE)”,将那些在Netflix、阿里巴巴等互联网巨头身经百战的高可用设计模式**,应用于LLM应用的独特挑战中。我们将深入探讨:
- 隔离与限流:如何通过线程池隔离、信号量等机制,防止单个“慢”依赖拖垮整个系统。
- 熔断与降级:如何实现智能的熔断器(Circuit Breaker),在依赖项持续失败时快速失败,并提供优雅的**降级(Fallback)**方案。
- 超时与重试:如何设计科学的**超时与重试(Timeout & Retry)**策略,在瞬时网络抖动和长期服务不可用之间做出明智的权衡。
这篇文章将是你构建生产级、高可用AI系统的“生存手册”。它将教会你如何从一个乐观的“建设者”,转变为一个拥抱失败、敬畏异常的、成熟的系统架构师。
第一部分:隔离的艺术——防止“一颗老鼠屎坏了一锅汤”
在微服务架构中,最大的风险之一就是“级联故障(Cascading Failure)”。对一个外部服务的缓慢或失败的调用,可能会耗尽调用方的资源(如线程池),使其无法再响应其他请求,从而引发雪崩。隔离是防止这种情况的第一道防线。

1.1 核心思想:为不同的依赖分配独立的“救生艇”
想象一下你的Agent-Orchestrator服务,它可能需要同时调用Inference-Service、Knowledge-Service和一些外部的第三方API。这就像一艘大船要派出三艘小艇去执行不同任务。
- 错误的做法:所有调用共享同一个主线程池。如果派往Inference-Service的小艇(调用线程)因为对方港口拥堵而全部被困住,那么即使Knowledge-Service的港口畅通无阻,大船也再也派不出新的小艇去执行其他任务了。
- 正确的做法:为对每个不同服务的调用,都分配一个独立的、有容量上限的线程池。这就是**“舱壁隔离(Bulkhead)”模式。Inference-Service的调用线程池满了,只会影响到新的对Inference-Service的调用,而不会影响到对Knowledge-Service**的调用。
1.2 Java实战:使用Resilience4j实现舱壁隔离
Resilience4j是Java生态中实现高可用设计模式的事实标准。它提供了强大的Bulkhead模块。
- 添加依赖:
1 | <dependency> |
- 配置文件 (application.yml):
1 | resilience4j.bulkhead: |
- 在代码中应用:
1 | // 在LlmClient中应用Bulkhead |
架构师思考: 隔离是一种**“防御性”**的设计。它承认了“不是所有依赖都是平等的”这一事实。对于那些核心的、延迟敏感的、或不稳定的依赖,进行资源隔离,是一种成本极低但收益巨大的可靠性投资。它无法让失败的服务恢复,但能确保系统的“大多数功能”在局部故障时依然可用。
第二部分:熔断与降级——从“执着等待”到“优雅放弃”
隔离解决了资源耗尽的问题,但它无法解决“无意义的等待”。如果Inference-Service已经连续失败了10次,我们为什么还要让第11个请求去徒劳地尝试,并为此等待一个完整的超时周期?
**熔断器(Circuit Breaker)**模式,正是为了解决这个问题而生。

2.1 核心思想:模拟电路中的“保险丝”
熔断器的行为就像一个电路保险丝,它具有三种状态:
- 闭合 (CLOSED):正常状态,所有请求都可以通过。熔断器在后台默默地统计失败率。
- 打开 (OPEN):当失败率(或慢调用率)在一定时间窗口内超过预设阈值时,熔断器“跳闸”,进入打开状态。在此状态下,所有后续的请求都会被立即拒绝(Fast-fail),而不会去真正调用那个已经出现问题的下游服务。同时,启动一个“冷却计时器”。
- 半开 (HALF_OPEN):当冷却时间结束后,熔断器进入半开状态。它会小心翼翼地放行一小部分(如10个)“探测”请求。
- 如果这些探测请求成功了,熔断器就认为下游服务已经恢复,于是自动切换回闭合状态。
- 如果这些探测请求依然失败,熔断器就认为下游服务还未恢复,于是立即切回到打开状态,并开始新一轮的冷却计时。
2.2 Java实战:Resilience4j的Circuit Breaker
- 配置文件 (application.yml):
1 | resilience4j.circuitbreaker: |
- 在代码中应用(可以与Bulkhead叠加):
1 |
|
2.3 降级(Fallback)的艺术:不只是返回错误信息
熔断后的降级,是体现系统“智能”和“韧性”的关键。除了返回一句冰冷的“服务不可用”,我们还有更优雅的选择。
- 模型降级:当对GPT-4的调用熔断时,自动降级到调用一个更便宜、更稳定但能力稍弱的模型,如GPT-3.5-turbo或一个私有化部署的开源模型。这保证了核心功能的“降级可用”。
- 缓存降级:如果AI服务不可用,尝试从缓存中查找与用户查询相似的、历史上的成功回答。
- 规则降级:对于某些特定任务(如FAQ),如果RAG失败,可以回退到一个基于关键词匹配或规则引擎的简单问答系统。
- 功能屏蔽:对于非核心的AI功能(如“文本润色”),在依赖的服务熔断后,可以直接在UI上暂时屏蔽该功能入口。
架构师思考: 熔断器是一种**“保护性”和“自愈性”的机制。它保护了调用方不被拖垮(快速失败),也保护了下游服务不被失败的请求“洪峰”压垮(给其恢复的时间)。而降级策略的设计,则是一个产品和技术的综合决策**,它体现了你对业务核心价值的理解——在最坏的情况下,应该优先保住哪些功能,以及如何以最低的成本提供一个“虽不完美但可接受”的替代方案。
第三部分:超时与重试——在“瞬时抖动”与“持久故障”间舞蹈
网络是不可靠的。一个请求可能会因为瞬时的网络抖动而超时。简单地将所有超时都视为失败,太过“脆弱”。**重试(Retry)**机制,就是为了应对这种“瞬时性”故障。
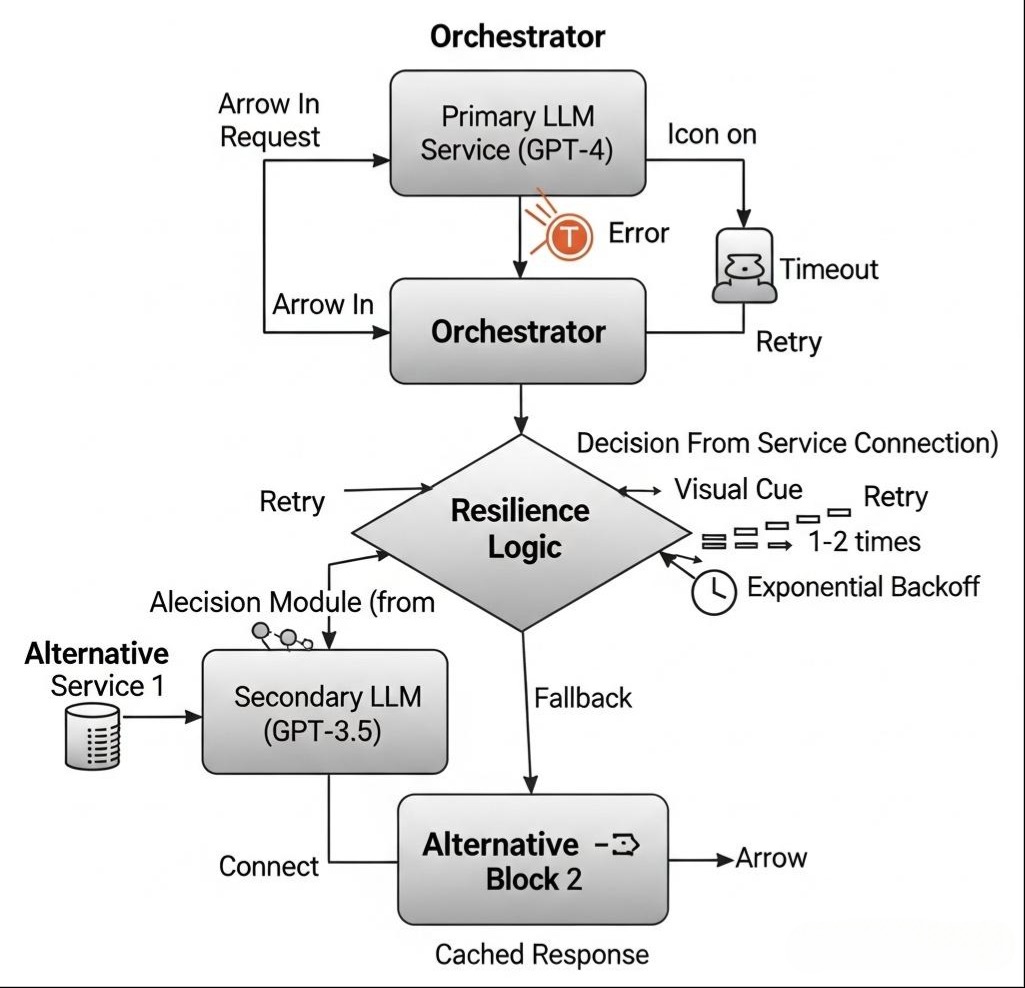
3.1 核心思想:不是简单的“再试一次”
一个设计糟糕的重试机制,可能会在下游服务已经过载时,通过疯狂重试而“火上浇油”,造成“重试风暴”。科学的重试策略,必须包含以下要素:
- 重试的条件:不是所有错误都应该重试。对于4xx(客户端错误,如参数错误)就不应重试。只应对那些可能是瞬时性的错误进行重试,如5xx(服务器错误)、网络连接超时、读取超时等。
- 退避策略 (Backoff Strategy):两次重试之间应该有间隔,且间隔最好是递增的。最常用的是指数退避(Exponential Backoff),例如,第一次重试等待100ms,第二次等待200ms,第三次等待400ms… 这给了下游服务喘息和恢复的时间。可以再加入一些随机抖动(Jitter),以避免在同一时刻产生大量的重试请求。
- 重试次数上限:必须设置一个合理的重试次数上限(如3次)。超过上限后,就必须承认失败,并将控制权交给熔断器或降级逻辑。
3.2 Java实战:Resilience4j的Retry
- 配置文件 (application.yml):
1 | resilience4j.retry: |
- 在代码中应用:@Retry注解可以和其他注解完美叠加。Resilience4j的注解执行顺序通常是:Retry -> CircuitBreaker -> Bulkhead。
1 |
|
架构师的最终权衡:超时与重试的设计,是在“快速响应”与“容忍抖动”之间的精妙平衡。
- 超时时间设得太短,会导致网络稍有波动就触发重试或失败,系统过于敏感。
- 超时时间设得太长,又会占用线程资源,降低系统吞吐量。
一个常见的最佳实践是:将单次调用的超时时间设置得相对严格(例如,对于LLM推理,可能是2-5秒),然后配合一个带有指数退避的、次数有限的重试策略。这使得系统既能快速响应真正的慢调用,又能优雅地处理掉瞬时的网络抖M动。
结语:拥抱失败,为不确定性而设计
在本篇中,我们为我们那套精密的、分布式的AI微服务系统,注入了至关重要的**“免疫系统”**。我们不再是一个对未来盲目乐观的“理想主义者”,而是一个敬畏现实、拥抱失败的“现实主义工程师”。
- 我们通过隔离(Bulkhead),学会了为系统的关键依赖构建“防火舱”,防止故障的蔓延。
- 我们通过熔断(Circuit Breaker),掌握了在依赖持续失败时“快速失败”并提供优雅降级的能力,实现了系统的自我保护和部分可用。
- 我们通过科学的**超时与重试(Timeout & Retry)**策略,学会在“瞬时抖动”和“持久故障”之间做出明智的、带有退避和抖动的舞蹈。
这些源于经典分布式系统设计的“古老智慧”,在充满不确定性的LLM时代,不仅没有过时,反而因为模型和API的“概率性”,而变得前所未有的重要。为不确定性而设计,为失败而设计,这应成为每一个AI系统架构师刻在骨子里的核心原则。
至此,我们的系统不仅“功能强大”,而且“体格健壮”。但是,当系统高速运转时,我们如何知道它内部发生了什么?当Agent的一个决策导致了非预期的结果时,我们如何像看“行车记录仪”一样,回溯它的每一步思考?
在下一篇章 《AI应用的可观测性(Observability):如何为你的Agent系统装上“黑匣子”》 中,我们将为我们的AI系统装上“眼睛”和“耳朵”。我们将深入探讨**日志(Logging)、指标(Metrics)和追踪(Tracing)**这三大支柱,如何应用于AI应用的独特场景,并学习使用LangSmith等前沿工具,来构建一个能够洞察Agent“内心世界”的、强大的可观测性平台。敬请期待!

