Agent篇(3):从System 1直觉到System 2逻辑——认知架构与工具协议的演进
导语:当“健壮的身体”囚禁了“混乱的大脑”
此刻,让我们回到上一章那座刚刚被“熔断器”和“隔离舱”武装到牙齿的 AI 微服务堡垒。
你的监控大屏一片祥和:Kubernetes 的 Pod 全绿,P99 延迟稳定,所有外部 API 的超时都被完美拦截。现在的系统,就像一位练就了“金钟罩”的武林高手,任凭外界风吹雨打,依然保持着 HTTP 200 OK 的微笑。
你满怀信心地在演示会上敲下回车,下达了一个复杂指令:“调研 2024 年生成式 AI 的投资趋势,并生成一份 PDF 报告。”
然而,诡异的一幕发生了。
没有报错,没有异常,没有熔断。但后台的日志却像中了邪一样,开始滚动一段不知疲倦的、荒诞的咒语:
1 | [09:00:01] [Planner] 思考:我需要搜索数据 -> Action: Search("AI Investment") |
服务没有挂,但任务挂了。
这是一个比“服务雪崩”更令人绝望的“社死现场”:逻辑雪崩(Logical Avalanche)。
你的 Agent 拥有无穷的算力(健壮的身体),却在一个简单的思维死胡同里反复撞墙(混乱的大脑)。它像一个患了短期记忆丧失症的巨人,每一拳都打得有力,却招招打在空气上。
这一刻,残酷的工程真理浮出水面:第 上一章中的 SRE 治理只能保证系统的“可用性(Availability)”,而只有本章的认知架构,才能保证系统的“有效性(Validity)”。
如果不给这个概率性的“随机数生成器”装上逻辑的枷锁,我们构建的就不是智能体,而是昂贵的工业垃圾。
本章,我们将从流量治理跃升至**“思维治理”。看一看如何通过规划算法与下一代协议**,一步步驯服 LLM 那狂野而随机的灵魂。
第一部分:第一性原理——System 2 的工程化重构
在动手写任何代码之前,架构师必须回答一个灵魂拷问:如果 LLM 已经足够聪明(如 GPT-4 或 Claude 3.5 Sonnet),我们为什么还需要复杂的 Agent 架构?直接把 Prompt 扔给模型不就行了吗?
要回答这个问题,我们需要深入认知心理学与计算机科学的交叉点。
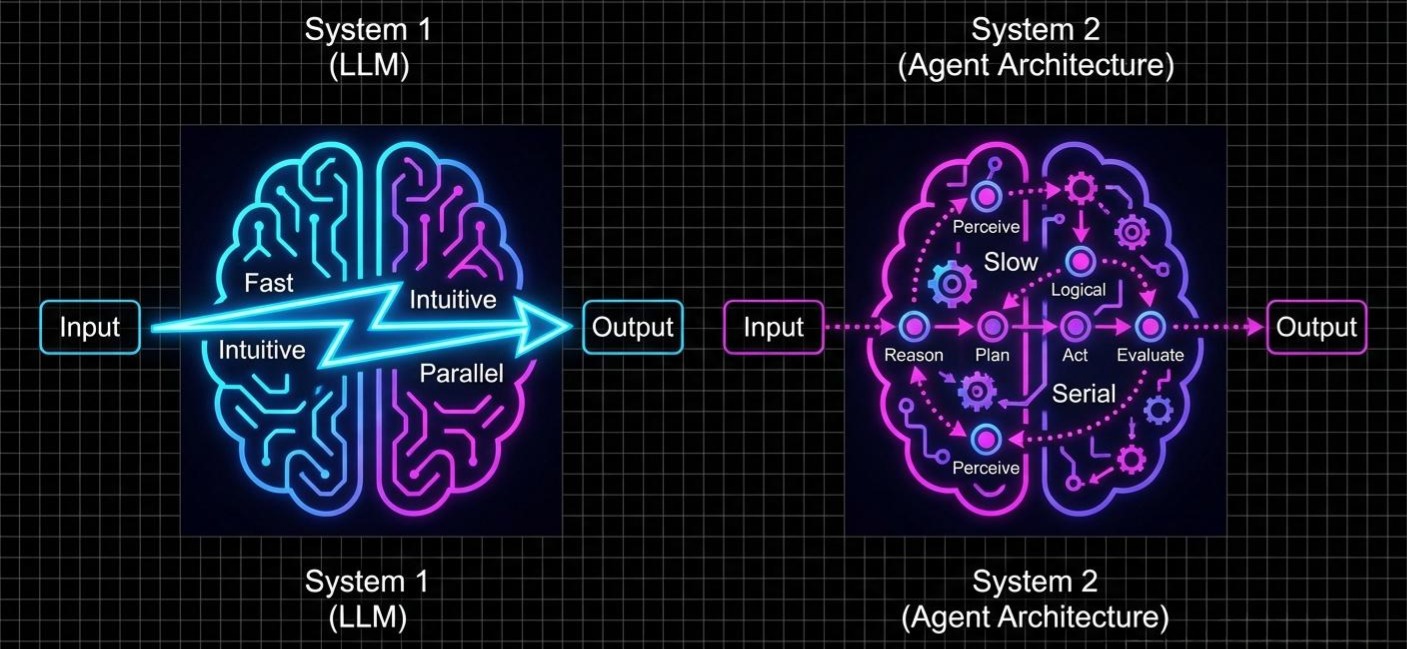
1.1 认知的双重性:System 1 与 System 2
诺贝尔经济学奖得主丹尼尔·卡尼曼在《思考,快与慢》中提出的理论,是理解 Agent 架构的基石:
- System 1(快思考): 直觉的、自动的、无意识的。例如:看到一张愤怒的脸,立刻意识到危险;或者脱口而出“2+2=4”。它是并行的,低能耗的。
- System 2(慢思考): 逻辑的、受控的、耗能的。例如:计算“17 × 24”;或者规划一次跨国旅行的行程。它是串行的,高能耗的。
从计算机科学的角度看,LLM 本质上是一个极致的 System 1 引擎。
无论它的参数量达到了多少万亿,其底层的生成机制依然是自回归的 Next Token Prediction。它生成的每一个 Token,都是基于前文的统计学直觉。它没有原生的“暂停键”,没有“回溯机制”,更没有“草稿纸”来暂存复杂的中间推理结果。
让一个纯粹的 System 1 模型去执行需要严密逻辑链条的长程任务(Long-horizon Task),就像让一个凭借直觉反应的短跑运动员去解微积分方程——它会利用概率模拟出“像推理”的文本,但那不是真正的推理。
1.2 架构的定义:外挂的 System 2
如果 LLM 是 System 1,那么Agent 架构设计的本质,就是通过工程手段,在 LLM 之外强行“外挂”一个 System 2。
2023年,OpenAI 的 Lilian Weng 提出的架构蓝图(Agent = LLM + Planning + Memory + Tools)确立了工业标准。这不仅仅是一张图,它是对 System 2 功能的逆向工程:
- System 2 需要逻辑推演 -> 架构提供 Planning (CoT/ToT)。
- System 2 需要与物理世界交互 -> 架构提供 Tool Protocols (MCP)。
- System 2 需要工作记忆 -> 架构提供 Memory Management。
接下来,我们将深入解构其中的核心组件。
第二部分:规划(Planning)——对抗熵增的逆向工程
核心矛盾: LLM 的贪婪生成(Greedy Generation)特性导致其在长任务中容易“短视”和“跑题”。我们需要一种机制,强制模型从“直觉反应”切换到“逻辑推演”。
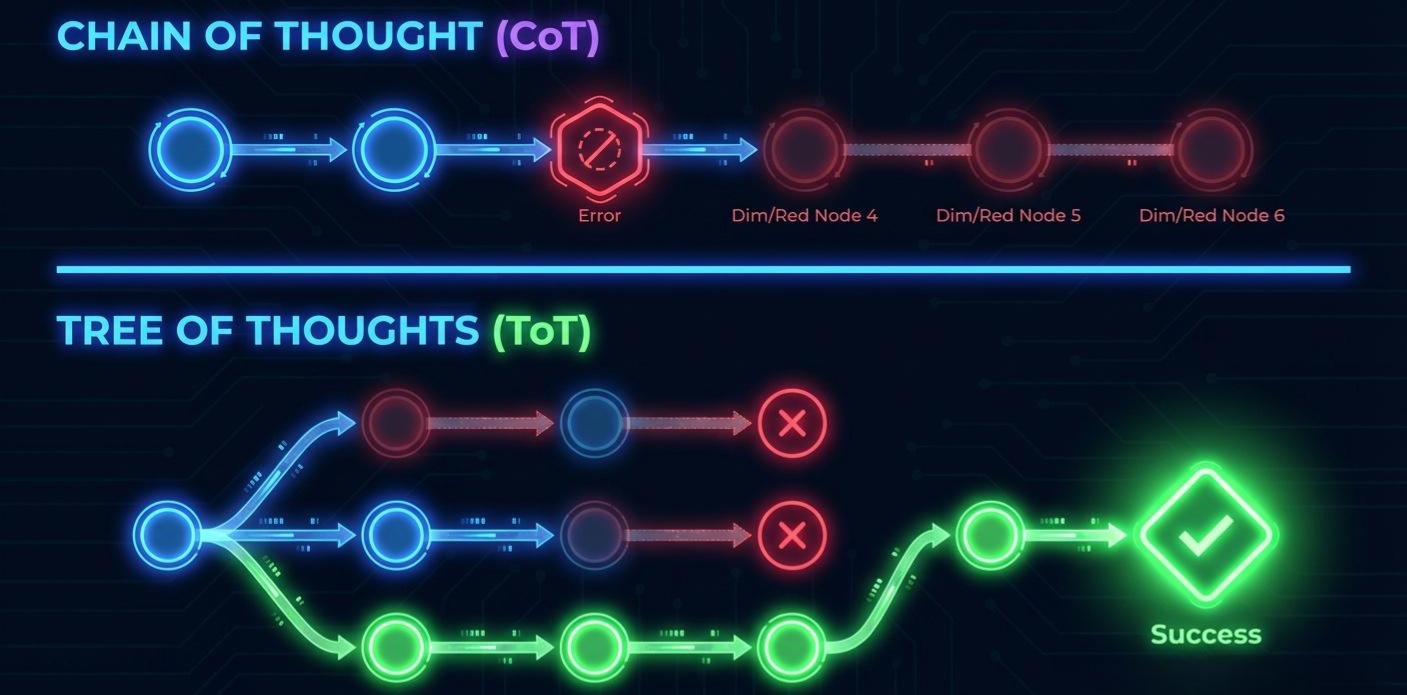
2.1 思维链 (CoT):以“计算”换“智能”
很多人误以为 CoT (Chain of Thought) 仅仅是一种 Prompt 技巧(”Let’s think step by step”)。但在架构师眼中,CoT 是一种**“时间换空间”**的计算策略。
2.1.1 原理与局限
LLM 的 Transformer 架构在生成每一个 Token 时,计算深度是固定的。对于复杂逻辑(如多位乘法),模型无法在生成答案的那一瞬间完成所有计算。
CoT 的本质是开辟了额外的“计算暂存区”。模型生成的每一个中间 Token(Thought),都会作为下一次预测的 Context。这相当于让模型有了“草稿纸”。
直观例子:
- **Standard Prompt:**问:23 * 18 等于多少?
答:400。(System 1 直觉猜测,错误) - **CoT Prompt:**问:23 * 18 等于多少?请逐步计算。
答:20 * 18 = 360,3 * 18 = 54,360 + 54 = 414。答案是 414。(System 2 逐步推演,正确)
2.1.2 架构师笔记
CoT 虽然有效,但它是线性的。它假设推理是一条笔直的大道。一旦中间某一步走错了(比如 318 算成了 50),后续所有的推理都会基于这个错误的基础(Error Propagation),导致“一本正经地胡说八道”。*
2.2 思维树 (ToT):搜索算法的复活
为了解决 CoT 的线性缺陷,我们需要引入 Tree of Thoughts (ToT)。这不仅是 Prompt 的升级,更是经典计算机搜索算法(BFS/DFS)在 LLM 上的复活。
ToT 承认模型可能会犯错,因此它要求模型在每一步都探索多种可能性,并进行自我评估。
2.2.1 实战解析:24点游戏
假设任务是:“用 4, 9, 10, 13 算 24 点。”
如果用 CoT,模型可能尝试一种组合 (13-9)*4... 发现不行就卡住了。
但在 ToT 架构中,过程如下:
- 分解(Decomposition): 架构将任务拆解为 3 个步骤。
- 生成(Generation):
- 分支 A: 4 + 9 = 13 (剩余 10, 13, 13)
- 分支 B: 13 - 10 = 3 (剩余 4, 9, 3)
- 分支 C: 10 - 4 = 6 (剩余 9, 13, 6)
- 评估(Evaluation):
- 架构引入一个“裁判节点”(可以是另一个 Prompt),给这三个分支打分。
- 裁判判定:分支 B (剩余 4, 9, 3) 似乎最有希望,因为 9-3=6, 4*6=24。
- 裁判判定:分支 A 看起来很难凑出 24。
2.** 扩展与回溯(Search & Backtrack):**
- 优先沿着分支 B 继续生成。
- 如果分支 B 走不通,回滚状态,尝试分支 C。
2.2.2 架构意义
ToT 将 LLM 降级为一个“选项生成器”和“局部评估器”,而将**“控制流”的权力交还给了经典的搜索算法(Python /Java代码实现)。**
**这使得 Agent 具备了探索(Exploration)和回溯(Backtracking)**的能力,这是解决复杂编码、数学证明或创意写作任务的关键。
第三部分:工具(Tools)——从“连接”到“流程”的协议演进
核心矛盾: LLM 存在“幻觉”与“离身性”(Disembodiment)。它无法感知物理世界,也没有企业内部的知识。
这是 Agent 领域演进最快、也最混乱的战场。我们将见证从“混乱”到“标准”,再到“专家”的三次跃迁。

3.1 阶段一:Function Calling 的巴别塔(2023)
OpenAI 推出的 Function Calling 确实是一个里程碑,它让模型学会了输出 JSON。但随着企业内部 Agent 数量的激增,我们陷入了 “n × m” 的适配地狱。
- 场景: 你有 10 个不同的 Agent(客服、财务、HR…),它们都需要调用“查询员工信息”这个工具。
- 痛点: 你需要在 10 个 Agent 的代码里,重复编写 10 次工具定义的 JSON Schema。如果“查询员工信息”的 API 变了,你需要去修改 10 个地方。
- 结果: 工具的定义与 Agent 的逻辑紧密耦合,维护成本极高,且缺乏统一的安全标准。
3.2 阶段二:统一的时代——MCP(模型上下文协议)的宏伟蓝图
面对 Function Calling 带来的混乱,Anthropic 在 2024 年提出了一个极具野心的解决方案——模型上下文协议(Model Context Protocol, MCP)。
MCP 的目标,是成为**“AI 工具世界的 USB-C 接口”**,彻底解决标准化、扩展性和发现性的问题。
3.2.1 核心逻辑:从“自带说明书”到“在线下载驱动”
MCP 的革命性在于解耦。它将“工具的定义”从 Agent 代码中剥离出来,放入一个标准的 Web 服务中。
- 过去(Function Calling): 每次调用,你都必须把厚厚的说明书(JSON 定义)塞进 Context 发给 LLM。
- 现在(MCP): 工具提供者搭建一个遵循 MCP 规范的 Server,并暴露一个清单文件(mcp.json)。这就像一个“驱动程序下载页面”。
Agent 只需要知道这个 URL,就可以像电脑安装打印机驱动一样,瞬间“了解”这个工具的所有功能。
3.2.2 实战演练:用 MCP 重构“天气查询”工具
让我们看看之前的天气查询工具,在 MCP 的世界里会是什么样子。
第一步:搭建 MCP 服务器(提供驱动)
你需要一个 Web 服务,对外暴露两个端点:
GET /mcp.json: 驱动清单。GET /v1/weather: 实际功能接口。
1 | Python |
第二步:AI 应用连接(即插即用)
在 Agent 的配置中,你只需要添加一行:USE_TOOL: https://api.myweather.com/mcp.json
交互流程:
- 发现: Agent 启动,访问 URL,读取清单,瞬间理解了工具用法。
- 调用: 用户问“巴黎天气”,Agent 自动向
/v1/weather发起标准 HTTP 请求。 - 解耦: 以后天气服务的 API 怎么变,只需要修改 MCP Server 的清单,所有连接它的 Agent 都会自动同步更新,无需修改 Agent 代码。
3.3 阶段三:注入灵魂——Anthropic Skills 与“专家手艺”
MCP 完美解决了**“连接”的问题,但一个新的、更深层次的问题浮现出来:“流程”的问题**。
局限性(The “How-To” Gap):
MCP 给了 AI 一套完整的厨具(工具)和食材(数据)。但如果你想让它做一道工序复杂的“佛跳墙”,它就傻眼了。
- 它知道怎么调用
query_db()(原子操作)。 - 但它不知道企业内部的“家规”:比如“制作周报 PPT,必须先查 A 表,再查 B 表,用公司专用模板,颜色只能用 #345C7D…”。
这些复杂的、多步骤的、包含特定规则的SOP(标准作业程序),是 MCP 承载不了的。如果把这些 SOP 全部塞进 System Prompt,Context Window 会瞬间爆炸。
于是,Skills (技能) 应运而生。如果说 MCP 是手脚,Skills 就是**“肌肉记忆”**。
3.3.1 核心原理:“渐进式披露”的上下文魔术
Skills 的核心思想是**“SOP 的按需加载”**。这是一种极高明的上下文管理策略。
- 只看目录(轻量级索引): 对话开始时,Agent 不读任何技能的详情,只快速扫描所有技能的“一句话简介”。这几乎不占 Token。
- 按需翻页(动态加载): 当用户的请求(如“做个PPT”)与目录匹配时,系统在那一刻,才会将该技能的完整说明书(
SKILL.md)动态注入到当前的对话上下文中。 - 成为专家(专家级执行): 此时,Agent 的上下文中充满了该任务的详细步骤、规则和最佳实践。它瞬间从一个“通才”变身为“PPT 制作专家”。
3.3.2 实战演练:定义一个“企业级 PPT 制作” Skill
一个 Skill 本质上是一个结构化的文件夹。
1 | text |
SKILL.md (灵魂说明书):
这不仅是 Prompt,而是给 System 2 看的执行剧本。
1 | Markdown |
架构师启示:
MCP + Skills = 完美的工具链。
- MCP 负责标准化的“硬连接”**(API、数据库),解决了 “How to Call”。
- Skills 负责私有化的“软知识”**(流程、规范),解决了 “How to Do”。
这种组合,让 Agent 既能连接万物,又能像公司老员工一样“懂规矩”,同时还极大地节省了 Token 成本。
第四部分:演进的终局——从循环到有向图(Graph)
至此,我们有了强大的大脑(ToT 规划)和灵巧的手脚(MCP/Skills)。但如果简单地把它们堆砌在一起,系统依然是脆弱的。我们需要一种机制将它们串联起来。
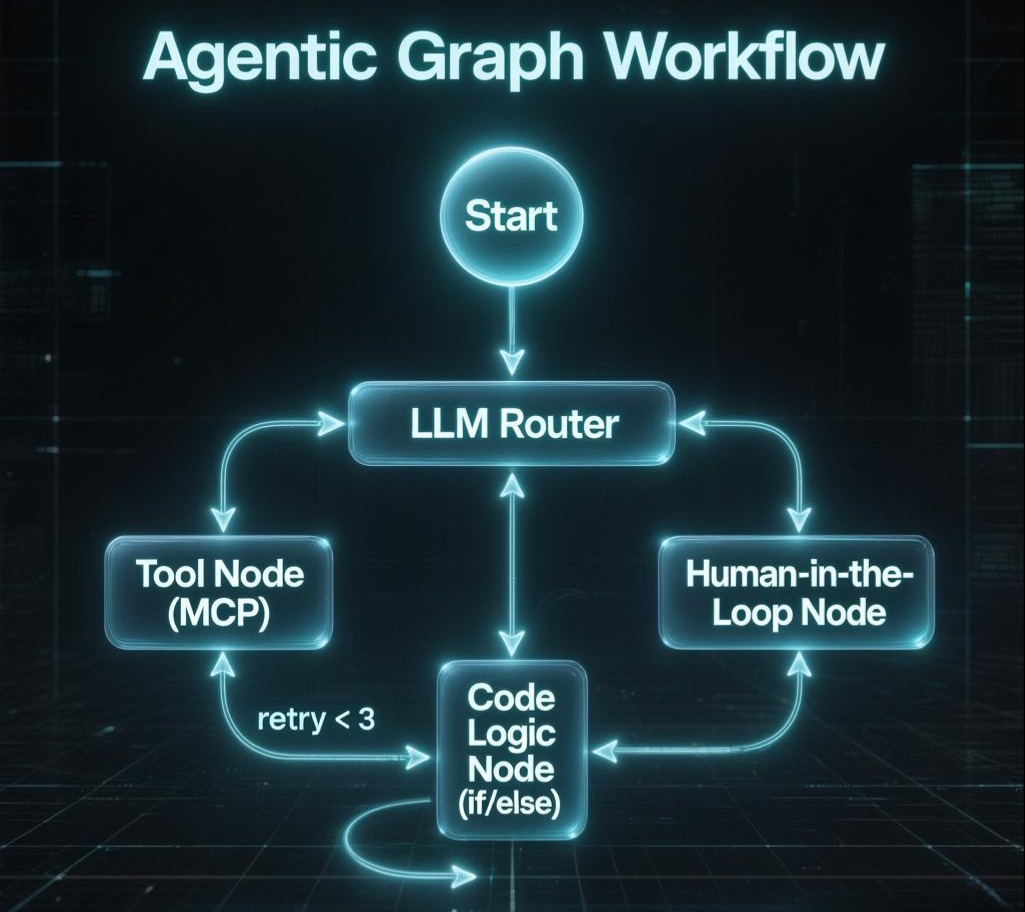
4.1 告别 While(True) 与 Chain
- While 循环(AutoGPT): 极易发散,不仅没有刹车,连方向盘都不稳。
- Chain(LangChain Legacy): 也就是 ReAct。它虽然引入了
Thought -> Action的检查点,但本质上还是线性的。它难以处理复杂的非线性逻辑(如:并行执行三个任务,或者 A 失败了重试 B)。
4.2 拥抱 Graph (Agentic Workflow)
这是 2025 年的架构终局。我们不再构建“通用的单体 Agent”,而是构建**“由 LLM 驱动的状态机(State Machine)”**。
我们将 Agent 拆解为图(Graph)中的节点,并利用上一章中提到的 SRE 思想进行编排:
- Router Node (LLM): 负责意图识别,决定激活哪个 Skill。
- Tool Node (MCP): 执行具体的动作。
- Logic Node (Code): 这里的代码不再是 AI 写的,而是工程师写的确定性逻辑。例如:
if retry_count > 3 then goto Human_Approval_Node。
通过这种方式,我们将**“控制流”的权力从概率性的模型手中收回,交还给了确定性的代码;而只将“语义处理”**的权力留给模型。
结语:为“大脑”建立秩序
在上一章节中,我们通过 SRE 手段(熔断、隔离)解决了外部依赖的不确定性;在这一章,我们通过认知架构的重构,开始着手解决 LLM 内部推理的不确定性。
- 我们用 ToT(思维树) 赋予了 System 1 深度思考和回溯的能力,让它学会了“三思而后行”。
- 我们用 MCP(协议) 解决了工具连接的标准化难题,打破了 Function Calling 的巴别塔。
- 我们用 Skills(技能) 解决了复杂流程知识的注入难题,实现了上下文的高效利用。
现在的 Agent,不仅身体强壮,而且头脑清晰,手脚灵活,且懂规矩。
然而,这座完美的机器还有一个核心的动力源尚未解决:记忆。
Agent 做出的每一个英明决策(Planning),每一道精准的工序(Skills),都依赖于它能从历史和知识库中提取出正确的信息。
- 如果 RAG 检索出来的知识是过时的、冲突的,推理的基础就会崩塌。
- 如果 Context Window 被无关的噪声填满,模型的智商就会直线下降。
在 System 2 的架构中,记忆(Memory)不仅仅是简单的向量检索。它涉及到操作系统级别的**“缺页中断”、“分层存储”**。
在下一篇章 《记忆的持久化——MemGPT原理与分层记忆设计》 中,我们将潜入 Agent 的海马体,去解决那个困扰所有 LLM 应用的终极难题:如何让 AI 拥有近乎无限且精准的长期记忆?
我们,下一章见。

