Agent篇(4):记忆的持久化:从“金鱼效应”到MemGPT的操作系统隐喻
导语:只有七秒记忆的“天才”
让我们回到上一章那个刚刚学会了“三思而后行”(ToT)和“使用标准化工具”(MCP)的 Agent。它现在逻辑严密,手脚麻利,仿佛一位无所不能的超级员工。
你兴奋地开始与它进行长期的项目协作:
Day 1 (周一):
你: “你好,我是架构师 Alex。我们正在开发一个高并发交易系统,核心约束是:必须使用 Java 21 虚拟线程,数据库限定为 PostgreSQL。”
Agent: “收到,Alex。已将技术栈约束写入记忆:Java 21 (Virtual Threads), PostgreSQL。”
一切看起来很完美。Agent 在随后的两天里表现出色,每一行代码都严丝合缝。
Day 3 (周三):
项目进入深水区,你下达了新指令。
你: “帮我写一个订单存储模块,要求高吞吐。”
Agent: “没问题。这是为您生成的基于 Python FastAPI 和 MongoDB 的存储模块…”
那一刻,你的血压上来了。
你愤怒地质问:“我周一不是强调过 Java 和 PG 吗?”
Agent 一脸无辜(因为它真的不知道):“抱歉,作为一个 AI 助手,我没有接收到相关上下文…”
这就是**“金鱼效应”。**
**无论你的模型推理能力(System 2)有多强,只要它的上下文窗口(Context Window)**被填满,最早的、往往也是最重要的系统指令(System Constraints)和用户偏好(User Profile),就会像流沙一样被挤出,消失在虚空中。
在《Agent篇2》中,我们解决了“物理健壮性”;在《Agent篇3》中,我们解决了“逻辑有效性”。
而本章,我们要解决的是“时间连续性”。
如果没有一套持久的、可自我更新的记忆系统,你的 Agent 永远只是一个**“无状态的过客”,而不是一个“有状态的伙伴”**。
第一部分:第一性原理——直面物理缺陷与技术迷思
在设计记忆系统前,架构师必须透过现象看本质,直面 LLM 在物理层面的局限性。

1.1 冯·诺依曼瓶颈:有限的 RAM vs 无限的 Disk
我们将 Agent 的运作机制映射到计算机体系结构中:
- CPU(模型): 计算速度极快,负责处理信息,但本身不存储状态(Stateless)。
- RAM(上下文窗口): 速度快,是 CPU 直接工作的区域。但它容量有限(如 128k),且易失(会话结束即清空)。
- Disk(外部存储): 也就是我们的向量数据库、SQL 数据库。容量无限,但速度慢,CPU 无法直接读取,必须经过 I/O 加载到 RAM。
核心矛盾:
现实世界的任务产生的信息量(Disk 级),远远超过了 LLM 单次推理所能容纳的上下文窗口(RAM 级)。Agent 的记忆设计,本质上就是解决**“如何将无限的 Disk 信息,精准地调度到有限的 RAM 中”**的问题。
1.2 “大海捞针”的迷思:为什么 100万 Context 救不了你?
随着 Gemini 2.5 Pro 等支持 1M/2M Token 的模型出现,很多开发者产生了一种惰性思维:“只要窗口足够大,把所有历史记录都塞进去不就行了?”
架构师的回答是:绝对不行。
- Lost in the Middle(迷失中间): 斯坦福大学的研究表明,当 Context 极长时,模型对文档中间部分信息的注意力会呈“U型曲线”显著下降。关键约束如果被埋在百万 Token 的中间,模型根本“看不见”。
- 成本与延迟(Cost & Latency): 每次请求都携带 100万 Token?这将导致首字延迟(TTFT)达到数十秒,且推理成本将是一个天文数字。
- 噪声干扰(Attention Dilution): 注意力机制是稀缺资源。塞入的垃圾信息越多,模型的推理智商(IQ)就越低。这就好比让你在嘈杂的菜市场解微积分。
因此,Agent 记忆设计的本质,不是“扩大内存”,而是设计一套高效的“虚拟内存管理系统(Virtual Memory Management)”。
1.3 RAG 的局限:为什么它不是记忆?
很多人认为 RAG(检索增强生成)就是记忆。这是一个巨大的误区。
传统的 Naive RAG 只是“只读存储器”,它解决不了“状态更新”的问题。
- 场景:
- 周一存入: “我喜欢吃辣。”(写入向量库)
- 周二存入: “我最近胃痛,医生说别吃辣了。”(写入向量库)
- 周三检索: RAG 根据“口味”检索,把这两句话同时塞给 LLM。
- LLM 困惑: “既喜欢吃辣又不能吃辣,我该怎么办?”
RAG 缺乏的是“覆盖(Overwrite)”和“遗忘(Forget)”机制。 真正的记忆系统,必须具备一致性(Consistency)。
第二部分:架构演进——MemGPT 与操作系统隐喻
2023 年,MemGPT 的论文横空出世,它彻底改变了 Agent 记忆的设计范式。它的核心思想非常激进:Agent 就是操作系统。

2.1 从“被动检索”到“主动管理”
- 旧范式(RAG): 记忆管理是代码逻辑(Python/Java)写死的。检索 -> 拼接 -> 生成。Agent 是被动的接受者。
- 新范式(MemGPT): 记忆管理是Agent 的工具。Agent 拥有“读写”自己记忆的 API。它自己决定什么时候翻看历史,什么时候把重要信息记在小本本上。
2.2 记忆的分层架构(Hierarchical Memory)
基于 OS 隐喻,我们构建企业级的三层记忆架构:
第一层:感知记忆 (Sensory Memory) —— I/O 缓冲
- 定义: 原始的输入流。用户发的每一句话,工具返回的每一个 JSON(可能几千行)。
- 作用: 它是瞬时的。我们需要通过 Parser 进行清洗,提取关键信息进入下一层,防止无关的“噪声”污染 RAM。
第二层:短期/工作记忆 (Working Memory) —— 上下文窗口 (RAM)
这是 LLM 当前时刻“眼中”看到的 Prompt。它包含两个关键区域:
- Scratchpad(草稿纸): 当前的推理链(ToT)、待办事项。
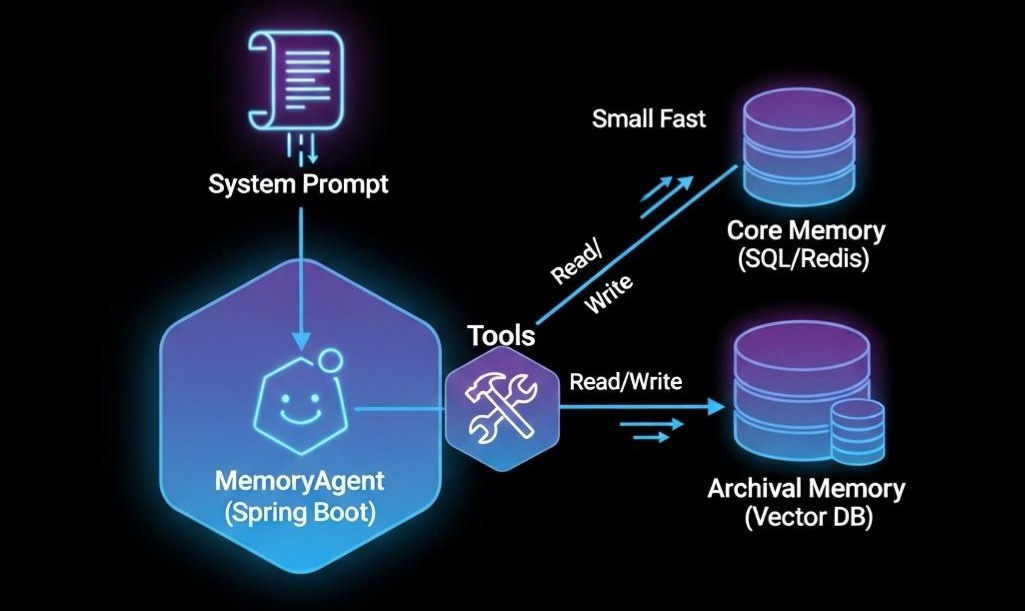
- Core Memory(核心内存): 这是 MemGPT 的精髓。它是常驻在 System Prompt 中的一段 JSON 数据,永远不会被挤出。
- 存储内容: 用户的核心画像(User Profile)、当前的最高指令(System Instructions)。
第三层:长期记忆 (Long-term Memory) —— 外部存储 (Disk)
当信息从 RAM 中被驱逐(Eviction)时,它们去哪了?进入长期记忆。
它细分为两类:
- 情景记忆 (Episodic Memory): “我经历过什么”。即历史对话流水。依靠时间向量检索。
- 语义记忆 (Semantic Memory): “我知道什么”。即事实性知识库。依靠知识图谱或结构化 SQL。
第三部分:深度解构——MemGPT 的操作系统隐喻与逻辑流转
MemGPT 是理解现代 Agent 记忆架构的“圣经”。但要真正掌握它,我们不能止步于概念,必须深入其逻辑内核。我们需要像调试 Linux 内核一样,去追踪 Agent 内部的每一次“内存缺页中断”和“系统调用”。
3.1 核心隐喻:Agent 即操作系统 (Agent as OS)
在传统视角下,LLM 是被动的文本生成器。但在 MemGPT 架构下,LLM 被重新定义为操作系统的主控 CPU。
- Context Window = RAM (主存):这是 CPU (LLM) 唯一能“直接看到”的数据区域。它是昂贵的、易失的。
- External Storage = Disk (磁盘):这是向量数据库 (Vector DB) 和关系型数据库 (SQL)。它是廉价的、持久的、无限的。
- Function Calling = System Call (系统调用):这是 CPU 管理数据的唯一手段。Agent 不再是被动等待数据喂入,而是可以通过
syscall主动地将数据从 DiskLoad进 RAM,或者将 RAM 中的重要信息Save回 Disk。
架构师洞察:
这意味着,Agent 的行为模式从 Stateless (无状态) 变成了 Stateful (有状态)。每一次对话,不仅是生成回复,更是对系统状态的一次潜在Mutation (变更)。
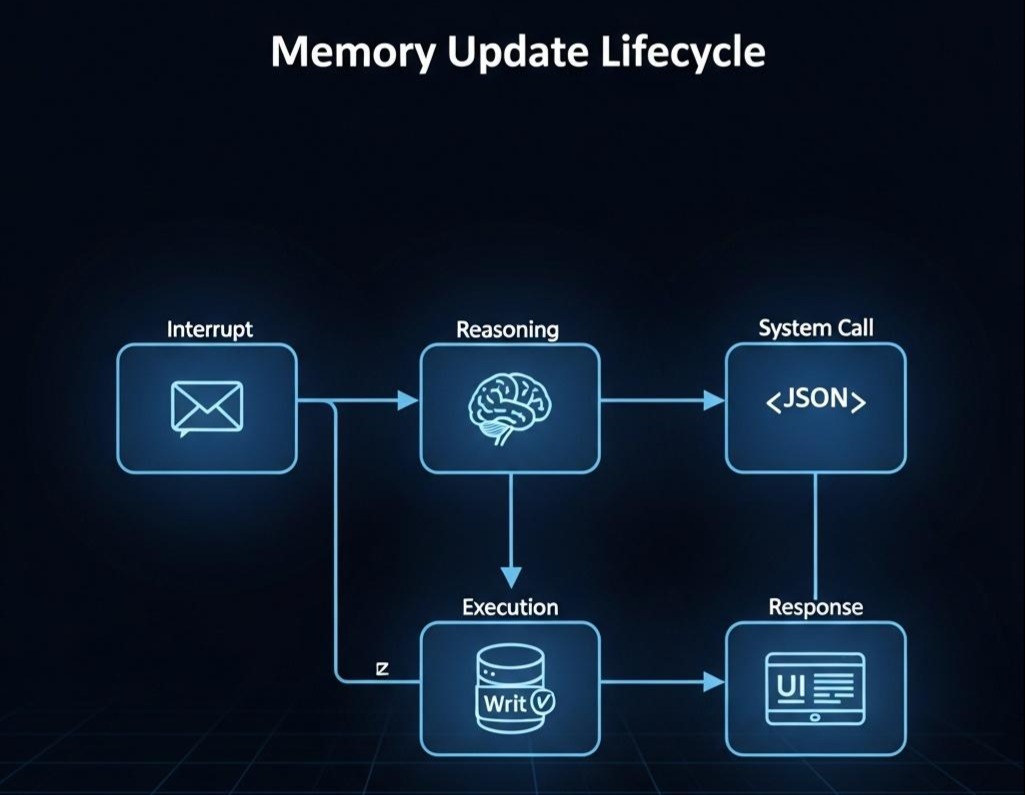
3.2 逻辑流转:记忆的生命周期 (The Lifecycle of Memory)
让我们通过一个微观的显微镜,逐帧分析当用户说出一句话时,Agent 内部发生了什么。
场景:技术栈变更
用户指令: “以后别用 Java 了,项目统一改用 Go 语言。”
阶段一:中断与感知 (Interrupt & Perception)
用户输入进入系统。此时,System Prompt 已经预加载了当前的 Core Memory(例如:{"tech_stack": "Java"})。
Agent 的 CPU (LLM) 读取输入,结合 Core Memory,产生认知冲突。
阶段二:思考与决策 (Reasoning & Decision)
Agent 进行 System 2 的慢思考(Thought):
- 分析:用户发出了明确的偏好变更指令。
- 比对:当前 RAM 中的 Core Memory 显示技术栈是 Java。
- 判断:这是一条高优先级的系统指令,必须持久化,且需要覆盖旧值。
- 决策:我不能只回复“好的”,我必须发起写操作。
阶段三:系统调用 (System Call)
Agent 生成一个特殊的 Tool Call 结构体(Action):
1 | JSON |
注意:此时 Agent 并没有生成回复给用户的文本,它正在全神贯注地操作内存。
阶段四:执行与回调 (Execution & Callback)
- Runtime 拦截:Agent 框架(如 LangGraph)拦截到这个 Tool Call。
- DB 操作:后台代码执行 SQL/NoSQL 更新,将数据库中的字段修改为
Go。 - Observation 返回:系统向 Agent 返回操作结果:“Success. Memory updated.”。
阶段五:重绘与响应 (Re-render & Response)
这是最关键的一步。系统清空当前的 Context,并基于最新的数据库状态重新渲染 System Prompt。
此时,Prompt 中的 Core Memory 区域已经变了:{"tech_stack": "Go"}。
Agent 基于这个新的世界观,生成最终回复:
“明白。已更新项目配置,后续所有代码将严格使用 Go 语言编写。”
第四部分:工程实战——Java 代码落地与中文 Prompt 设计
作为 Java 架构师,我们需要将上述理念落地为 Spring Boot 代码。我们将构建一个名为 MemoryAgent 的微服务。
4.1 定义记忆的 Schema (Java Record)
首先,定义 Agent 的“脑结构”。这不是杂乱的 String,而是强类型的对象。
1 | Java |
4.2 定义记忆管理工具 (Spring AI Implementation)
我们将利用 Spring AI (或 LangChain4j) 的注解,定义 Agent 可调用的“系统级函数”。
1 | Java |
4.3 注入灵魂:中文 System Prompt 设计
这是让 Java 代码拥有智能的“最后一公里”。我们需要编写一份极具约束力的中文 System Prompt。
Prompt 模板设计:
1 | text |
4.4 架构师笔记:Prompt 设计的玄机
仔细观察上面的 Prompt,你会发现几个精心设计的**“心理暗示”**:
- 身份赋予:明确告诉它“你不仅仅是聊天机器人”,而是“记忆管理员”。这激发了模型维护状态的主动性(Agency)。
- 可视化锚点:使用
{{ core_memory_json }}这种占位符,让模型直观地看到自己的“脑容量”是有限的,从而暗示它要珍惜 Core Memory 的空间。 - 操作优先级:明确指令“优先调用工具,不要直接回复”。这是为了防止模型“嘴上说记住了,身体却很诚实地什么都没做”。
通过这一套 Java 代码 + 中文 Prompt的组合拳,我们成功地将 MemGPT 的高深理论,降维打击成了可落地的工程实践。
4.5 架构师的启示
- 一致性优先: Agent 的记忆不是简单的日志堆积,而是状态管理。必须像设计数据库事务一样设计记忆更新,确保 Core Memory 与 Archival Memory 的数据一致性。
- 遗忘的艺术: 伟大的系统不是记得所有事,而是知道该忘掉什么。架构师需要设计**“记忆衰减算法”**,让很久未被访问且不重要的
Archival Memory逐渐淡出(降低检索权重),甚至被物理删除。 - 隐私与边界: 既然 Agent 能“写”记忆,它会不会把敏感信息(如密码)误写入 Vector DB?必须在 Tool Layer 增加PII(敏感信息)过滤器。
结语:赋予机器“连续的自我”
至此,通过 MemGPT 的操作系统隐喻和分层记忆架构,我们成功赋予了 Agent 一个**“长期的、连贯的自我”**。
现在的 Agent,像一个拥有无限书架的**“博学家”**。
- 它记得你三个月前的项目约束(Core Memory)。
- 它能瞬间翻阅数万条历史对话(Archival Memory)。
- 它还能主动更新自己的认知(Memory Tools)。
但是,拥有“记忆”并不等于拥有“能力”。
这就好比一个图书管理员,他背下了所有的编程书籍,但他能写出一个复杂的贪吃蛇游戏吗?不一定。
因为**“记住知识”(Memory)和“解决问题”**(Reasoning & Planning)是完全不同的两个维度。
- 当你面对一个复杂任务(比如“分析财报并写代码画图”)时,光有记忆是不够的。
- 你需要知道先做什么,后做什么。
- 你需要知道第一步失败了,第二步该怎么调整。
这种将抽象目标拆解为具体行动序列的能力,就是 Agent 的大脑——规划(Planning)。
目前,我们的 Agent 只是一个**“记忆超群的静态智者”**。在下一篇章 《思维的链条:从 ReAct 到 Plan-and-Solve —— 深度解构 Agent 的“推理引擎”》 中,我们将让这位智者动起来。我们将探讨它如何利用 CoT(思维链) 进行深度思考,如何利用 ReAct 范式与世界交互,以及在面对超长任务时,如何利用 Plan-and-Solve 进行运筹帷幄的宏观规划。
敬请期待。

