Agent篇(5):思维的链条:从 ReAct 到 Plan-and-Solve —— 深度解构 Agent 的“推理引擎”
导语:当“行动派”遇到“迷宫”
设想这样一个场景:你命令你的 Agent “帮我把这台 Linux 服务器上的所有 .log 文件打包压缩,上传到 S3,然后删除原文件。”
这是一个典型的、不可逆的序列任务。
如果你的 Agent 是一个鲁莽的“行动派”(System 1),它可能看完指令就直接执行 rm -rf *.log,然后再去想怎么打包,结果发现文件没了。
如果你的 Agent 是一个成熟的“规划派”(System 2),它的大脑里应该瞬间浮现出一张流程图:
find查找文件(确认目标存在)。tar打包压缩(创建副本)。aws s3 cp上传(备份)。check校验上传成功(验证)。rm删除原文件(清理)。
这个将抽象目标拆解为具体行动序列的过程,就是规划(Planning)。
在 Agent 领域,规划算法的优劣,直接决定了它是能独立解决问题的“智能体”,还是一个只会瞎忙活的“人工智障”。
本章,我们将深入 Agent 的大脑皮层,拆解两种最核心的规划引擎:ReAct(边走边看)和 Plan-and-Solve(运筹帷幄)。
第一部分:概念对齐:微观推理 vs 宏观架构
在深入代码之前,作为架构师,我们必须先厘清几个极易混淆的术语:CoT、ToT、ReAct、Plan-and-Solve。它们都属于“规划”的范畴,但层级不同。
你可以把它们想象成**“内功”与“招式”**的区别:
1.1 微观层:思维的内功 (Prompting Strategy)
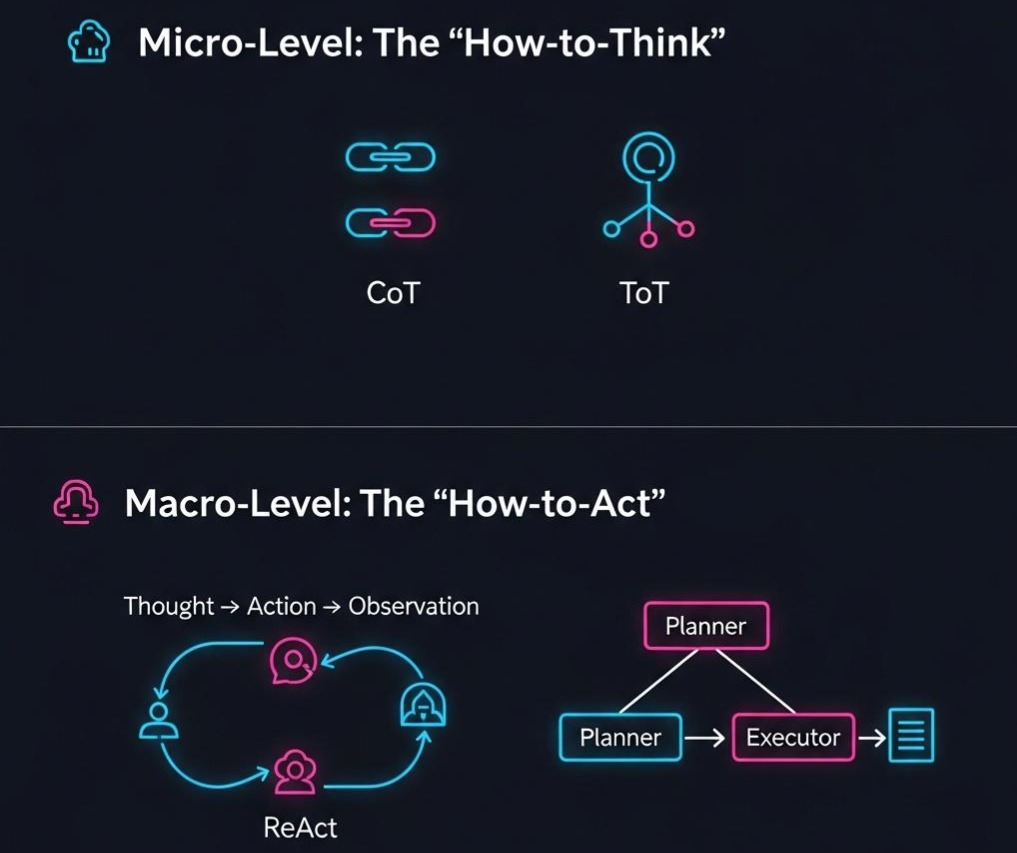
这层只发生在 LLM 内部,不涉及工具调用,关注的是**“如何生成高质量的思考文本”**。
CoT (Chain of Thought, 思维链):
- 定义: 强迫模型在给出答案前,先写出线性推理步骤。
- 例子: “A是1,B是2,所以A+B=3。”
- 本质: 线性思考。用更多的 Token 换取逻辑准确性。
ToT (Tree of Thoughts, 思维树):
- 定义: 强迫模型生成多个可能的推理分支,并进行自我评估和回溯。
- 例子: “方案A风险高,方案B成本高,方案C最稳妥,我选C。”
- 本质: 搜索算法 (BFS/DFS)。在生成层面进行探索和剪枝。
1.2 宏观层:行动的招式 (Agent Architecture)
这层发生在 LLM 与环境(Tools)之间,关注的是**“如何组织思考与行动的循环”**。
ReAct (Reasoning + Acting):
- 定义: “思考-行动”的单步循环。
- 逻辑: Thought (基于 CoT) -> Action (调工具) -> Observation (看结果) -> Repeat。
- 关系: ReAct 依赖 CoT 来生成 Thought。它是 CoT 在工具使用场景下的应用。
Plan-and-Solve (Planner + Executor):
- 定义: “先计划-后执行”的分层架构。
- 逻辑: Planner 生成完整清单 (可能用到 ToT) -> Executor 逐项执行 -> Planner 根据反馈重规划。
- 关系: 它是比 ReAct 更高级的架构,适合解决 ReAct 容易“迷路”的长任务。
一句话总结:
CoT 和 ToT 是模型脑子里的“想法”(如何想得更对);
ReAct 和 Plan-and-Solve 是模型手脚上的“行动模式”(如何干得更稳)。
第二部分:ReAct 范式——“摸着石头过河”
ReAct (Reasoning + Acting) 是目前最流行、最通用的 Agent 规划模式(也是 LangChain Agent 的默认模式)。它的核心哲学是:交替进行思考和行动。
2.1 ReAct 的基本循环 (The Loop)
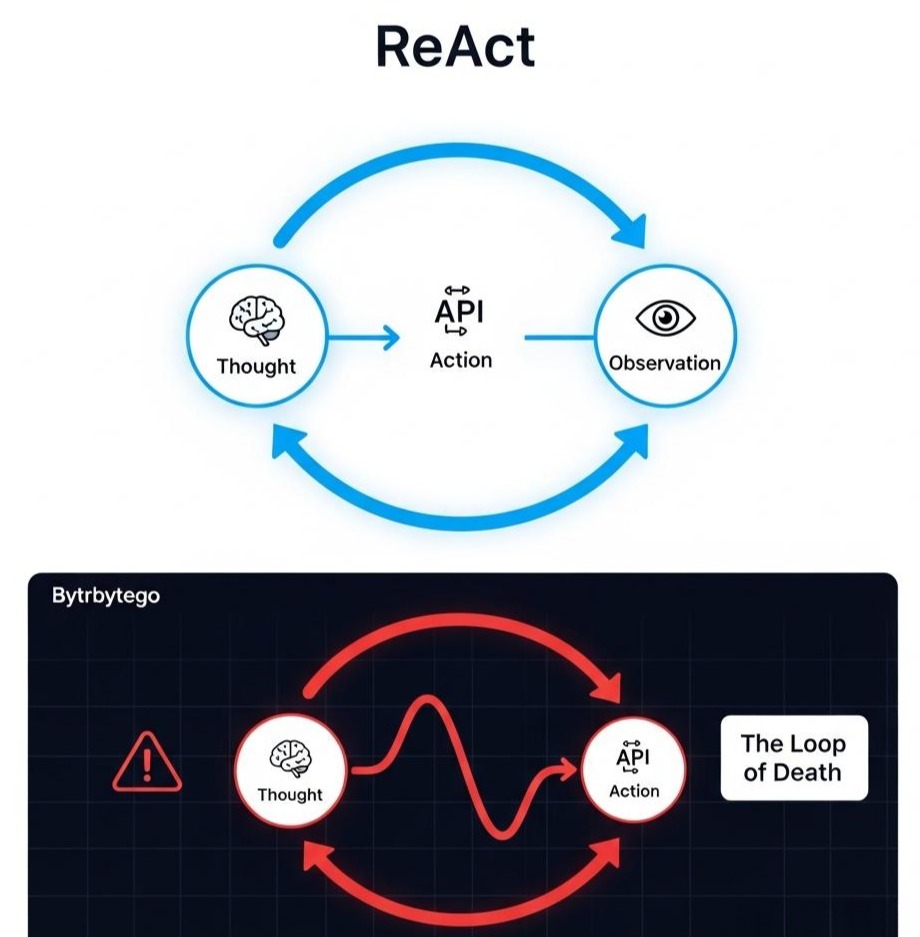
ReAct 并不预先生成完整的计划,而是像一个在迷宫中探险的人:走一步,看一眼,想一下,再走下一步。
它的 Prompt 结构强制模型遵循以下格式:
- Thought (思考): 我现在的情况是什么?下一步该做什么?
- Action (行动): 调用具体的工具(如
search,shell)。 - Observation (观察): 工具返回的真实结果。
- … (重复上述过程) …
- Final Answer (回答): 任务完成,输出结果。
2.2 源码级解构:ReAct 为何有效?
让我们看一个 ReAct Agent 处理“查询苹果公司股价并计算市值”的真实 Trace:
1 | User: 苹果现在的市值是多少? |
架构师洞察:
ReAct 的本质是一个状态机。Observation是状态机的输入,Thought是状态转移逻辑,Action是副作用。这种模式极其适合探索性任务(Exploratory Tasks),即你不知道第一步的结果是什么,必须等做完第一步才能决定第二步。
2.3 ReAct 的阿喀琉斯之踵:死循环 (The Loop of Death)
然而,ReAct 有一个致命弱点:它容易陷入局部最优的死循环。
社死现场:
Thought: 我需要查找 X。
Action: Search(X)
Observation: 未找到结果。
Thought: 我没找到 X,我必须查找 X。
Action: Search(X)
Observation: 未找到结果。
… (无限循环)
工程解法:
我们需要在 ReAct 循环中注入**“元认知(Meta-Cognition)”**。
- 最大步数熔断(Max Steps): 这是一个兜底策略(如
max_iterations=10)。 - 刮刮乐策略(Scratchpad Truncation): 随着循环进行,Prompt 会越来越长。我们需要动态地对之前的
Observation进行摘要,防止 Context 爆掉。 - 重复检测(Loop Detection): 在代码层记录最近 3 次的 Action。如果发现
Action[t] == Action[t-1],强制在 System Prompt 中注入一条系统级警告:“系统检测到你在重复执行相同的动作。请尝试改变搜索关键词,或者放弃当前路径。”
第三部分:Plan-and-Solve 范式——“运筹帷幄之中”
对于简单的搜索任务,ReAct 很好用。但对于复杂的、长链路的任务(如“写一个游戏”),ReAct 往往会“走着走着就忘了要去哪”。
这时候,我们需要 Plan-and-Solve (P&S) 模式。它的核心哲学是:先制定完整的计划,再逐一执行。
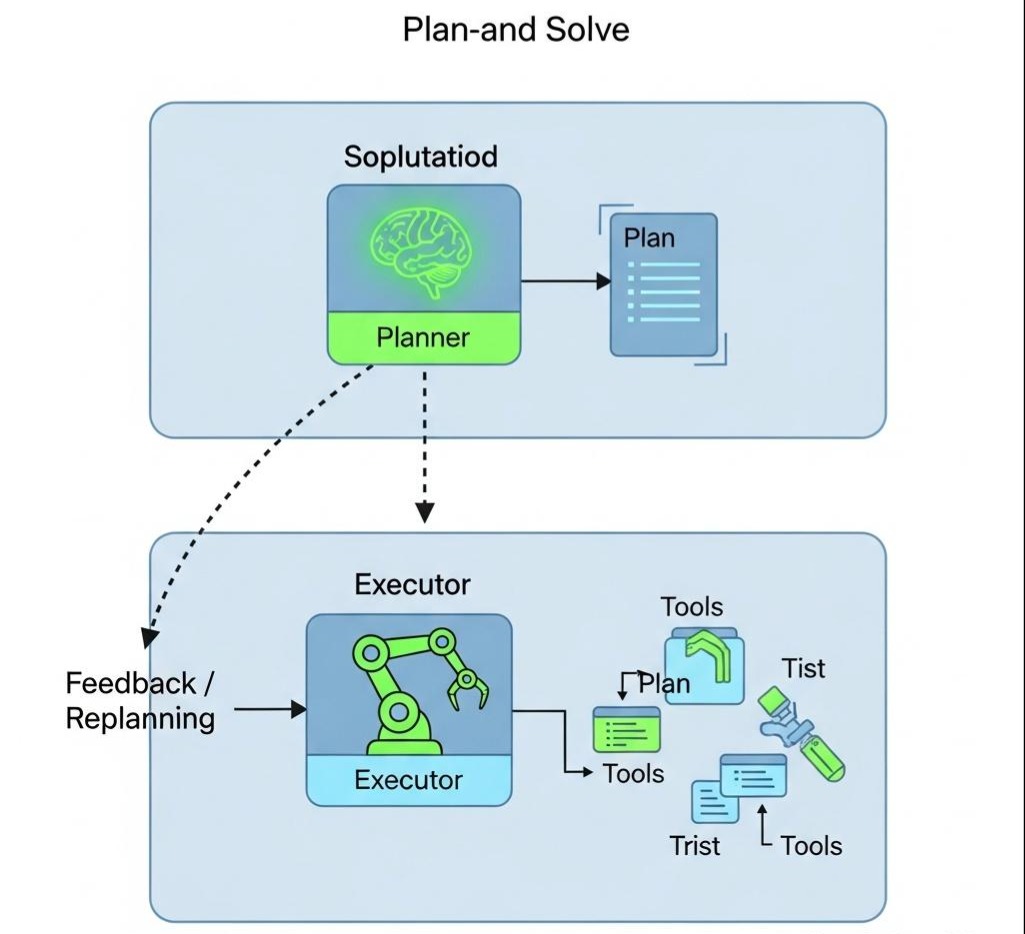
3.1 架构拆解:Planner 与 Executor
P&S 将 Agent 拆分为两个独立的角色(甚至可以是两个不同的模型):
- Planner (规划者): 负责 System 2 的慢思考。它不执行任何工具,只负责生成一个 DAG(有向无环图) 或 Todo List。
- 输出示例:
["1. 搜索2023年财报", "2. 提取净利润数据", "3. 计算同比增长率", "4. 生成图表"]
- Executor (执行者): 负责 System 1 的快执行。它拿着 Planner 给的清单,一项一项地去调工具执行。
3.2 动态重规划 (Dynamic Replanning)
P&S 最性感的地方在于重规划。计划不是一成不变的。
流程逻辑:
- Planner 生成初始计划
[A, B, C, D]。 - Executor 执行 A,成功。
- Executor 执行 B,失败(例如工具报错“数据不存在”)。
- Executor 将失败信息反馈给 Planner。
- Planner 被唤醒:“任务 B 失败了,看来原来的计划行不通。基于现在的观察,我需要修改后续计划。”
- Planner 生成新计划
[B', C, D]。 - Executor 继续执行 B’。
这种**“计划 -> 执行 -> 遇到障碍 -> 重规划”**的闭环,是 Agent 解决复杂现实问题的核心能力。
第四部分:Java 工程实战——实现一个 P&S Agent
理论之后,我们用 Java 代码来实现一个简易的 Plan-and-Solve 架构。我们将定义两个核心 Prompt 和一个主控循环。
4.1 数据结构定义
1 | // 计划中的单一步骤 |
4.2 Planner 的 Prompt 设计
这是 Planner 的灵魂。我们需要教会它如何生成和修改计划。
1 | String plannerPrompt = """ |
4.3 主控循环 (The Orchestrator)
1 | public void runAgent(String userGoal) { |
第五部分:架构师的权衡——选 ReAct 还是 P&S?
作为架构师,你不应该盲目追求复杂的架构。何时用 ReAct,何时用 P&S?这里有一份决策指南:
| 维度 | ReAct 范式 | Plan-and-Solve 范式 |
|---|---|---|
| 适用场景 | 探索性任务:比如“随便逛逛网页看看有什么新闻”。你需要边看边决定下一步。 | 目标明确的复杂任务:比如“写代码”、“数据分析”、“写长文章”。步骤清晰,依赖明确。 |
| Token 消耗 | 中等:每次只思考一步。 | 较高:每次重规划都需要读取整个计划列表。 |
| 延迟 | 低:单步执行快。 | 高:规划阶段耗时较长。 |
| 鲁棒性 | 低:容易陷入局部死循环,容易跑题。 | 高:有全局视图,始终盯着最终目标(Final Goal)。 |
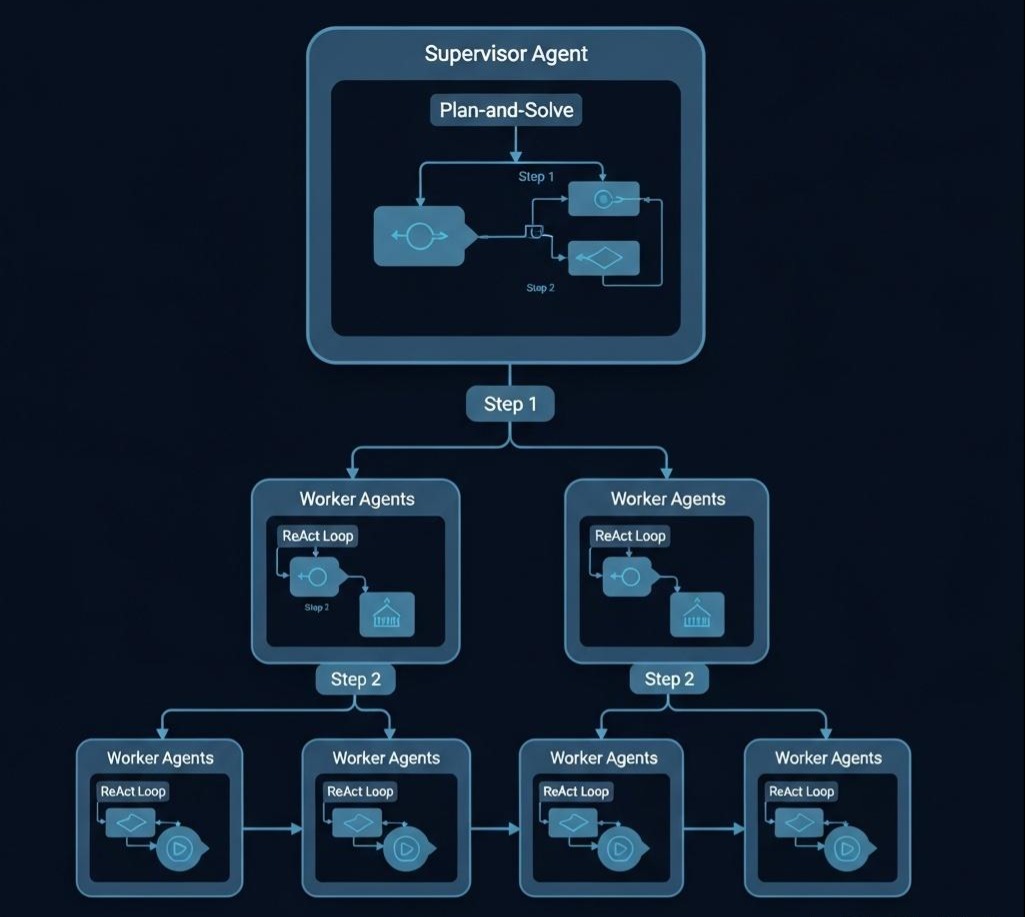
最佳实践:混合架构
在企业级应用(如 LangGraph)中,我们通常采用分层架构:
- 顶层(Supervisor): 使用 Plan-and-Solve 模式,负责宏观规划(Step 1, Step 2…)。
- 底层(Worker): 每一个 Step 的具体执行(如“去搜索一下”),交给一个微型的 ReAct Agent 去完成。
这样既保证了宏观方向不跑偏,又保证了微观执行的灵活性。
结语:从“想”到“做”
本章我们深入解构了 Agent 的“推理引擎”。
- ReAct 赋予了 Agent 探索未知的能力,像一个勇敢的探险家。
- Plan-and-Solve 赋予了 Agent 运筹帷幄的能力,像一个严谨的工程师。
掌握了规划,你的 Agent 已经知道**“该做什么”(What to do)以及“先做什么后做什么”(When to do)。**
但是,知道做什么还不够,它必须能够真正地“做到”。这就需要它能够精准地操纵工具,与物理世界进行交互。
在 ReAct 的 Action 步骤中,Agent 会输出 Tool_Search(query="...")。
但是,这个工具到底是怎么定义的?Agent 怎么知道有哪些工具可用?如何防止 Agent 调用工具时参数填错?
在下一篇章 《Agent的手与脚:从 Function Calling 到 MCP 协议与 Computer Use》 中,我们将深入工具层。我们将从最基础的 JSON Schema 讲起,一路演进到 Anthropic 最新的 MCP (Model Context Protocol) 、Skills标准,看 AI 如何像人类一样使用计算机。
敬请期待。

