Agent篇(7):赋予 AI 自省能力:Reflexion (反思) 模式与 Actor-Critic 架构
导语:撞了南墙不回头的“死脑筋”
让我们回到上一章那个刚刚学会使用 MCP 工具查天气的 Agent。它现在手脚麻利,连接了全球气象站。
此刻,你给它出了个刁钻的难题:“帮我查查 Moon(月球) 的天气。”
Agent 接收指令,逻辑严密地制定了计划,自信地调用了 MCP 工具:get_weather(city="Moon")。
MCP Server 诚实地报错: Error 400: 'Moon' is not a valid city on Earth.
此刻,一个普通的 ReAct Agent(无反思能力)会怎么做?
它会陷入一种令架构师抓狂的**“死脑筋循环”**:
- Round 1:
- Thought: 嗯?报错了?可能是网络波动,或者是 API 没响应。我应该重试。
- Action:
get_weather(city="Moon") - Observation:
Error 400... - Round 2:
- Thought: 还是报错?那我试试把首字母小写,可能 API 对大小写敏感。
- Action:
get_weather(city="moon") - Observation:
Error 400... - Round 3:
- Thought: 还是不行?那我试试加个空格,或者换个参数顺序。
- Action:
get_weather(city="Moon ") - Observation:
Error 400...
… (直到 $50 的 Token 耗尽,任务因 MaxIterationsExceeded 而崩溃)
服务没挂,逻辑也没错,但 Agent 就是“蠢”死了。
它表现出一种**“执着的愚蠢”。它只知道“往前冲”(执行 Action),不知道“停下来看看脚下的路”**(分析 Feedback)。它缺乏一种人类最宝贵的品质——反思(Reflection)。
真正的智能体,应该在看到 Error 400 的瞬间,停下来思考:
- “报错信息说 Moon 不是地球上的城市。”
- “这意味着我调用的这个工具根本不支持地外行星。”
- “我不能再重试了。我应该告诉用户我查不了,或者尝试去调用 NASA 的接口。”
本章,我们将给 Agent 装上一面“镜子”,让它学会自省、自责、自修正。我们将从理论到代码,构建一个具备闭环纠错能力的高级智能系统。
第一部分:第一性原理——从“开环”到“闭环”的控制论跃迁
在控制理论(Control Theory)中,系统分为开环和闭环两类。理解这个区别,是理解 Agent 自省架构的物理学基石。
1.1 开环系统 (Open-Loop System):ReAct 的局限
目前的 ReAct 架构大多是开环的:Input -> LLM -> Tool -> Output
- 特征: 单向流动,一条道走到黑。
- 缺陷: 它假设“预测即正确”。如果 Output 是错的(比如代码跑不通,或者逻辑有漏洞),流程就直接结束了,用户只能收到一个错误结果。它没有**“纠偏机制”**。
1.2 闭环系统 (Closed-Loop System):引入负反馈
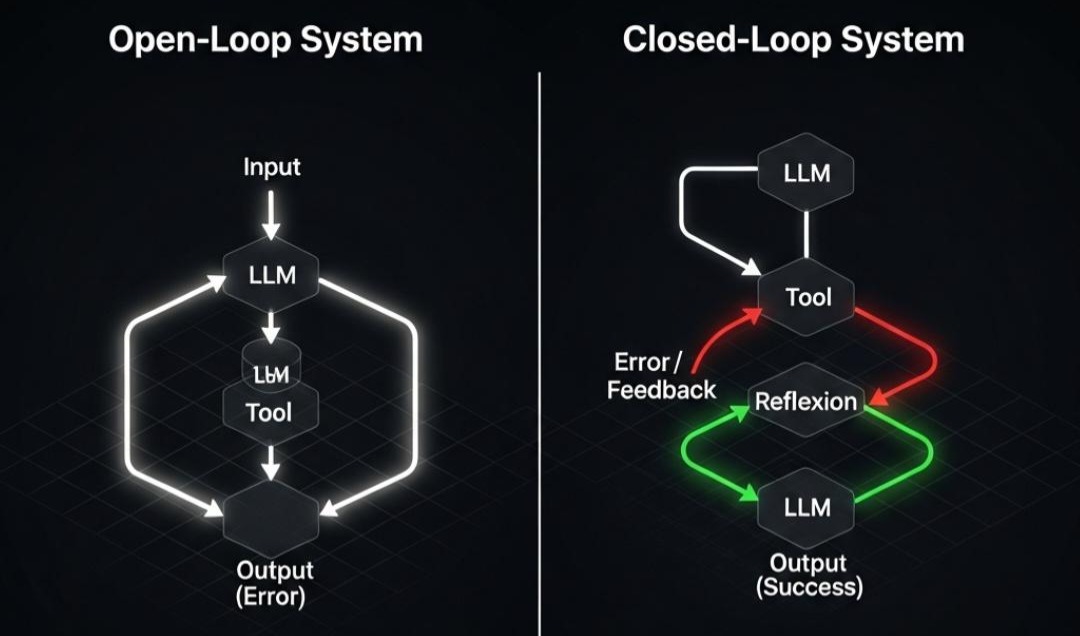
反思架构的核心是引入反馈回路 (Feedback Loop):Input -> LLM -> Tool -> Error/Feedback -> Reflexion -> Retry -> Output
架构师洞察:
在这个闭环中,错误(Error)不再是流程的终点,而是新一轮尝试的起点(Context)。*
我们通过将“错误日志”和“反思建议”喂回给模型,通过 *In-Context Learning(上下文学习),让模型在不更新权重(Weights)的情况下,实现了行为的“梯度下降”。
1.3 错误分类学 (Taxonomy of Errors)
并不是所有的错误都值得反思。架构师需要对错误进行精细的分类处理:
- 幻觉错误 (Hallucination Errors):
- 现象:调用了不存在的工具,或捏造了参数。
- 反思策略:查阅工具文档(Schema),修正参数。
- 逻辑错误 (Reasoning Errors):
- 现象:代码语法正确,但算法写错了(如排序算法写反了)。
- 反思策略:需要 Test Case 介入,对比预期输出与实际输出。
- 环境错误 (Environment Errors):
- 现象:API 超时,数据库连接失败。
- 反思策略:这不是模型的错。不需要反思,只需要 Exponential Backoff 重试。
第二部分:架构解构——Reflexion 模式
2023 年提出的 Reflexion 框架,是目前实现 Agent 自省的工业标准。它不是单纯的重试,而是**“带着记忆重试”**。
2.1 核心组件三元组

一个完整的 Reflexion 系统由三个角色组成:
- Actor (执行者): 负责写代码、调工具。它是干活的苦力,注重执行力。
- Evaluator (评估者): 负责给结果打分。它是一把尺子。可以是单元测试、编译器,也可以是另一个 LLM。
- Self-Reflector (反思者): 负责分析“为什么错了”并生成“改进建议”。它是导师,注重逻辑归因。
2.2 显微镜下的数据流:一次“写代码”的自救之旅
让我们通过一个**“Python 爬虫编写”**的场景,看看 Reflexion 是如何挽救一个必死的任务的。
Round 1: 盲目尝试 (The Naive Attempt)
- Actor: 接收任务“写一个爬取网页标题的脚本”。
- Action: 生成代码
import requests; from bs4 import BeautifulSoup... - Evaluator (沙箱): 运行代码 -> 报错
ModuleNotFoundError: No module named 'bs4'。 - 状态: 任务失败。如果是普通 Agent,这里就结束了。
Round 2: 触发反思 (The Reflection)
- Self-Reflector (介入):
- Input: 看到报错信息
ModuleNotFoundError。 - Thinking (归因): “Actor 使用了
BeautifulSoup库,但沙箱环境中没有预装这个库。直接 import 导致了失败。” - Advice (输出建议): “在下一次尝试中,请先执行
pip install beautifulsoup4,或者改用 Python 内置的re模块来解析,以避免依赖问题。” - Memory Update: 将这条 Advice 写入 Short-term Memory (Scratchpad)。
Round 3: 带着记忆重试 (The Correction)
- Actor: 再次被唤醒。
- 关键点: 它的 Short-term Memory 里现在多了一段 Reflector 的建议。
- Thought: “我看到了之前的教训,环境里没有 bs4。为了稳妥,我决定用正则解析。”
- Action: 生成了基于
re模块的新代码。 - Evaluator: 运行成功!输出标题。
2.3 长期记忆联动:让教训永存
Reflexion 不应止步于当前任务。
如果下周用户又让它写爬虫,它难道还要再犯一次错吗?
结合 Ch20 的 MemGPT: Reflector 应该将这条高价值的经验(“沙箱不支持 bs4”)写入 Long-term Memory。下次 Actor 启动时,直接从长期记忆中检索到这条规则,实现跨任务的进化。
第三部分:工程落地——Actor-Critic 双流架构
在企业级实战中,我们不能指望同一个 Prompt 既能干活又能找茬。这会陷入“思维盲区”。我们采用 Actor-Critic 模式,将“生成”和“批判”解耦。
3.1 角色分工与模型选型
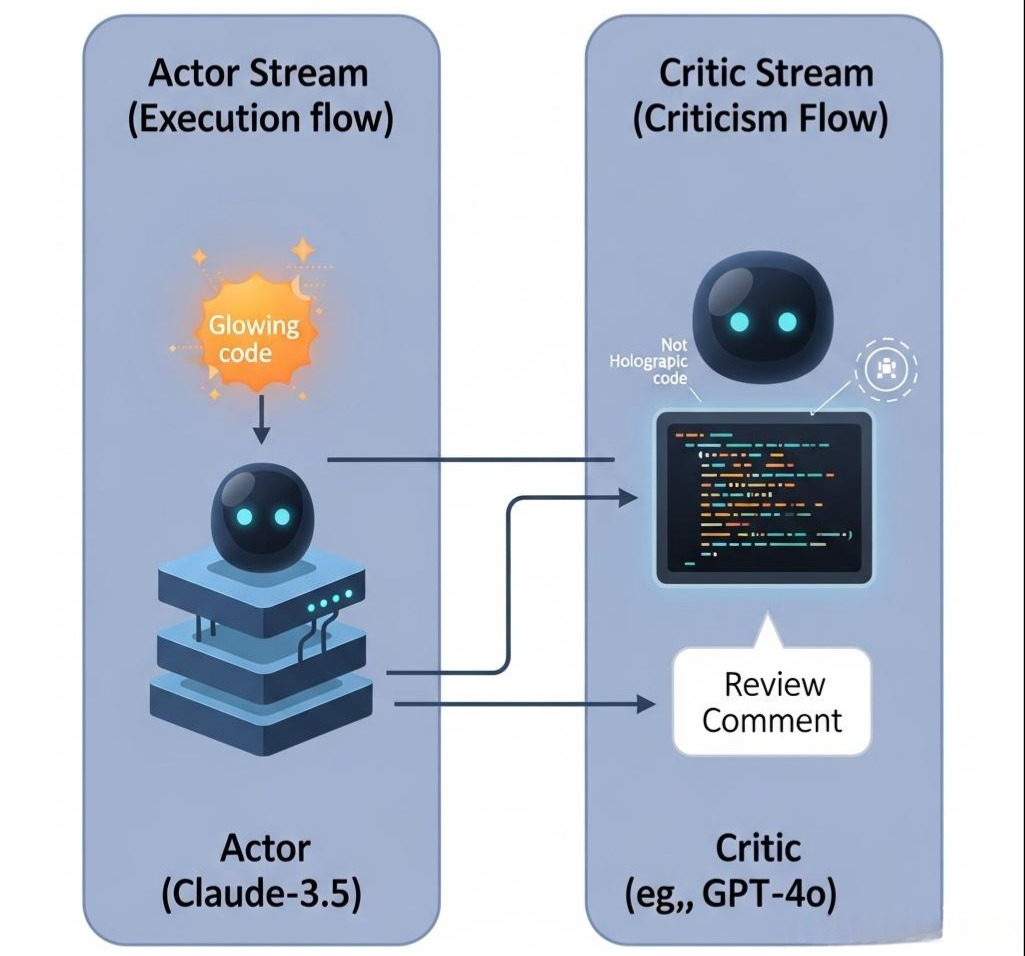
- Actor (执行者):
- 模型选型:
Claude-3.5-Sonnet或GPT-4o。 - 特点: 代码生成能力强,指令遵循能力强。
- Critic (批评家):
- 模型选型:
GPT-4o或微调过的Llama-3-70B。 - 特点: 逻辑推理强,擅长发现 Corner Case。
- Prompt 策略: 给它看代码,但不让它写代码,只让它写 Review Comments。
3.2 Java 代码实战:构建反思循环
我们将使用 Java (Spring Boot + Spring AI) 构建一个带有反思机制的 Code Agent。
Step 1: 定义状态 (State Definition)
我们需要一个 POJO 对象来在 Actor 和 Critic 之间传递信息。
1 |
|
Step 2: Actor 逻辑 (The Doer)
1 |
|
Step 3: Critic 逻辑 (The Judge)
1 |
|
Step 4: 主控循环 (The Orchestrator)
1 |
|
第四部分:架构师的深度思考与权衡

4.1 反思的边界:何时停止思考?
反思虽好,但不能贪杯。如果设计不当,Agent 会陷入**“过度反思”**的死循环(Over-correction)。
- 陷阱:反思退化 (Reflection Degeneration)
Critic 每次都说“代码风格不好”,Actor 改了风格;Critic 又说“逻辑不对”,Actor 改了逻辑;Critic 又说“风格还是不好”… 两个模型在那里反复横跳,浪费 Token。 - 熔断机制 (Circuit Breaker):
- Hard Limit: 必须设置最大重试次数(如 3 次)。事不过三。
- MD5 Check: 如果 Actor 这一轮生成的代码和上一轮一模一样,说明它根本没听进去,或者改不动了,立即熔断。
- Human Handoff: 熔断后,抛出
NeedHumanInterventionException,将当前 Context 转交给人工界面。
4.2 成本权衡 (The Cost of Intelligence)
Reflexion 架构使得一次任务可能需要调用 3-4 次 LLM,且 Context 越来越长。
- Token 消耗: 是普通 ReAct 的 3-5 倍。
- 延迟: 显著增加。
- 决策模型:
- 对于低风险任务(如闲聊、生成文案):使用 ReAct,追求速度。
- 对于高风险任务(如写 SQL、写代码、操作数据库):必须使用 Reflexion,追求准确率(Pass@1 is not enough)。
4.3 Human-in-the-Loop (HITL) 的结合
最强大的 Critic 其实是人类。
在 Actor 生成代码后,Critic 反思前,可以插入一个 Human Node。
- 人类看到代码,评论一句:“这里逻辑不对,应该用递归。”
- 这句话作为最权威的 Reflection 注入 Memory。
- Actor 立即遵旨修改。
这是人机协同进化的最佳实践。
结语:从“单点智能”到“系统智能”
人类之所以智慧,不在于不犯错,而在于犯错后能反思,并避免重蹈覆辙。
本章我们通过 Reflexion 模式,给 Agent 装上了这个极其宝贵的品质。
现在,让我们回顾一下我们的 Agent 进化之路:
- Ch21 (规划): 它有了大脑,知道该做什么(Plan)。
- Ch22 (工具): 它有了手脚,知道怎么做(Act)。
- Ch23 (反思): 它有了良知,知道做错了怎么改(Reflect)。
这三个章节,构建了一个完美的**“单体智能(Individual Intelligence)”**。
但是,在现实的企业级应用中,业务流程往往极其复杂,仅仅靠一个“全能”的单体 Agent 在那里死循环反思,是搞不定的。
- 你需要先做需求分析(Intent Router)。
- 然后根据情况,分发给“写代码 Agent”或“写文档 Agent”(Branching)。
- 最后还需要由“人工审批节点”进行把关(Human-in-the-Loop)。
我们需要将这些单体的能力,拆解为一个个节点(Node),并用**代码(Code)将它们串联成一条精密的流水线。我们不能让 LLM 决定一切,我们要用流工程(Flow Engineering)**来掌控一切

