Agent篇(8):流工程宣言:为什么 Agentic Workflow (工作流) 才是企业落地的唯一解?
导语:带着脚镣的舞者
2023 年初,当 AutoGPT 第一次在终端里自主循环起来时,全世界的开发者都以为自己触摸到了 AGI 的裙角。
那个愿景太迷人了:给 AI 一个目标,它就能自己拆解、自己执行、自己纠错、自己完成。不需要代码,不需要流程,只要一个 Prompt。
那是 AI 界的“浪漫主义时期”。我们疯狂地迷信模型的涌现能力(Emergence),认为只要模型足够大,一切逻辑问题都会迎刃而解。
然而,当这些全自动 Agent 被扔进企业的生产环境,面对真实的、复杂的、容错率极低的业务场景时,它们立刻变成了**“脱缰的野马”**。
- 不可预测的路径: 同样的输入,早上它决定查数据库,下午它决定去必应搜索。你永远不知道它下一步想干嘛。
- 不可调试的黑盒: 当它卡住时,你面对的是一个庞大的、纠缠在一起的上下文窗口。你不知道是哪句话触发了它的幻觉。
- 不可控的成本: 为了解决一个简单的逻辑死结(比如日期格式不对),它可能在后台空转 50 轮,烧掉你半个月的预算,最后告诉你“任务失败”。
企业主们痛苦地发现:我们需要智能,但我们更需要控制。
于是,Agentic Workflow(智能体工作流) 诞生了。
这听起来像是一个新词,但本质上,它是一种**“降级”,一种“无奈的妥协”**。
因为目前的 LLM 还不够聪明,不够稳定,我们不得不用代码(Code)编织一个坚固的笼子,把 LLM 关进去。
我们不再让 LLM 决定“下一步做什么”(那是 Agent 的特权),我们用代码写死“下一步必须做什么”(这是 Workflow 的铁律)。我们只允许 LLM 在我们划定的一个个小格子里,发挥它处理语义的特长。
这听起来很悲情?不。
正如 TCP/IP 协议用严格的分层约束了混乱的信号,才诞生了互联网。约束,往往是规模化的前提。
欢迎来到流工程(Flow Engineering)的时代。在这里,我们不再祈祷奇迹,我们制造秩序。
第一部分:溯本清源——Agent vs Workflow 的本质对立
在构建架构之前,我们必须先理清两个核心概念的哲学冲突。这不是咬文嚼字,而是决定技术选型的根本。
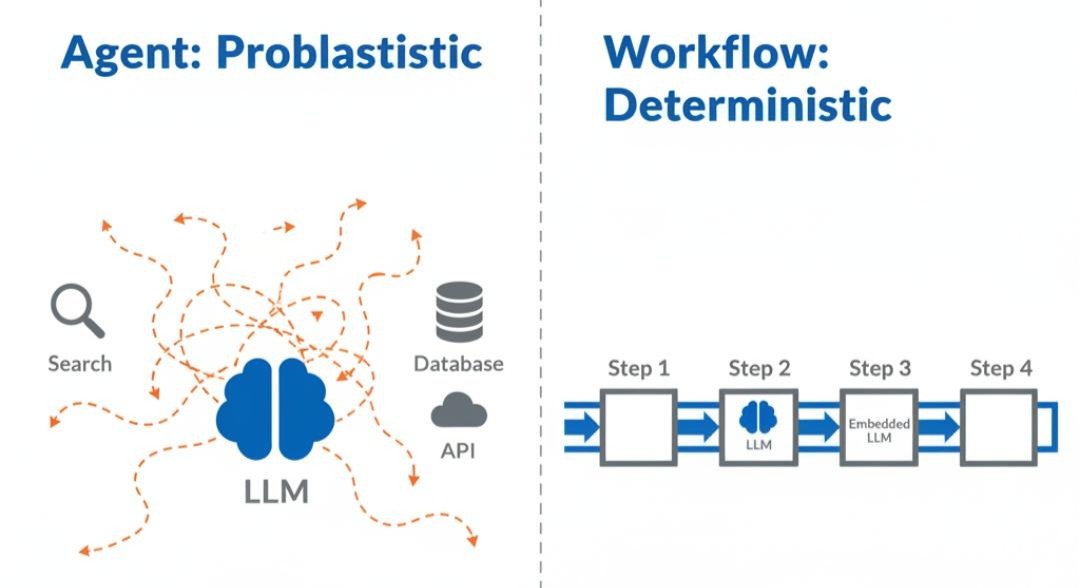
1.1 Agent:概率驱动的“随机游走” (Random Walk)
- 控制逻辑:
Next_Action = LLM(History) - 核心机制: Next Token Prediction。模型根据概率分布,预测下一步该调用什么工具。
- 隐喻: “醉汉走路”。虽然大方向可能对,但每一步都充满了随机性。在开放世界(如 Minecraft)里,这种随机性是创造力;但在银行转账系统里,这是灾难。
- 致命伤: 误差累积(Error Accumulation)。如果单步准确率是 90%,一个 10 步的任务成功率仅为 0.910≈34.8%0.910≈34.8%。这就是 AutoGPT 容易崩溃的数学原理。
1.2 Workflow:逻辑驱动的“确定性管道” (Deterministic Pipeline)
- 控制逻辑:
Next_Node = Code_Logic(Current_State) - 核心机制: State Machine (状态机)。由程序员显式定义的图(Graph)结构决定流转。
- 隐喻: “铁路轨道”。火车(数据)只能沿着铺好的铁轨(Edge)跑。到了道岔口(Router),由调度员(逻辑)决定往左还是往右。
- 核心价值: 确定性(Determinism)。无论跑多少次,流程骨架不变。LLM 只是流水线上负责“拧螺丝”的工人,无权决定流水线的走向。
架构师的洞察:
Workflow 的本质,是用确定性的控制流(Control Flow),去包裹不确定性的数据流(Data Flow)。
我们牺牲了 AI 的自主性(Agency),换取了系统的可靠性(Reliability)。
第二部分:流工程七层参考架构 (The 7-Layer Flow Engineering Model)
既然 Workflow 是一个“笼子”,那么要关住 GPT-4 这样强大的猛兽,这个笼子必须设计得极其精密。
基于企业级落地的最佳实践,我为您梳理出了**“流工程七层参考架构”**。这套架构由底向上,逐层封装,构成了现代智能系统的完整骨架。这不仅仅是一张架构图,更是一张通往 AGI 的作战地图。
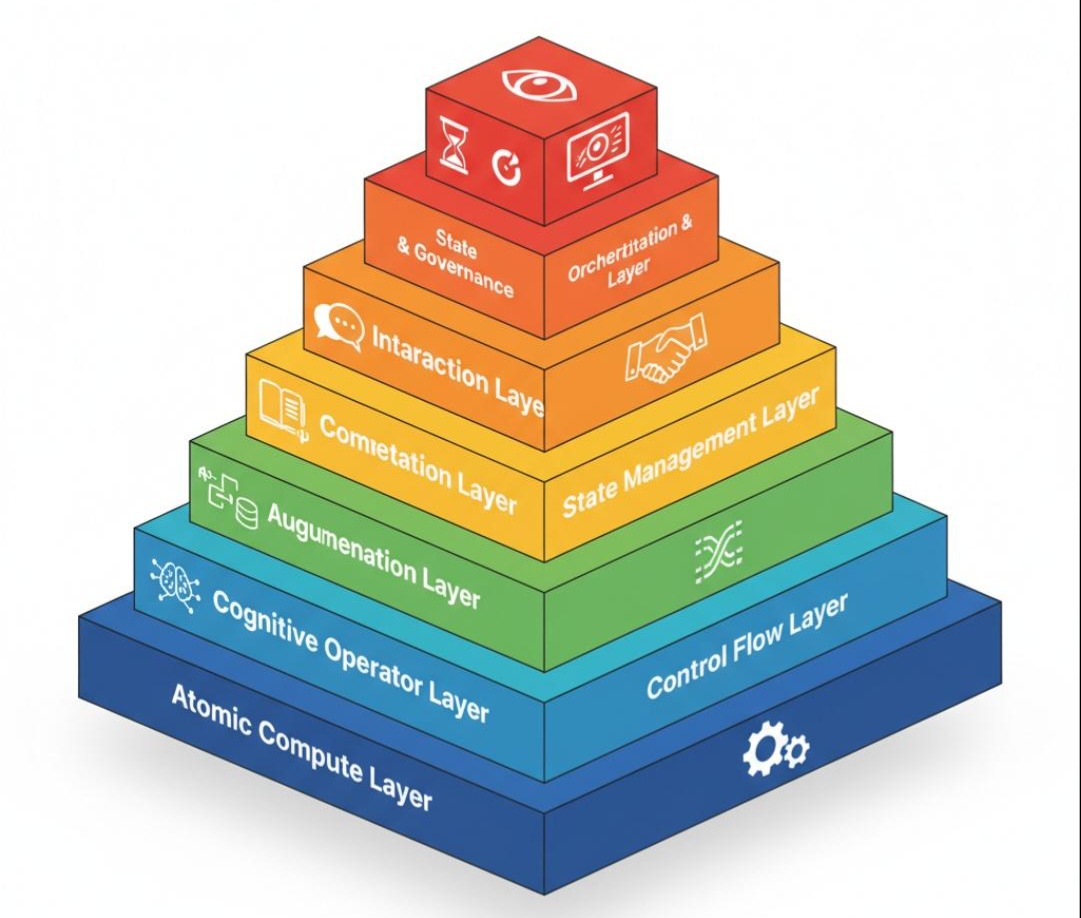
L1:原子计算层 (Atomic Compute Layer) —— “系统的基石”
这是架构的最底层,也是最容易被忽视的一层。在这一层,没有智能,只有计算。
- 定义: 执行确定性逻辑的最小单元。
- 核心组件:
- Code Node(代码节点): 执行 Python/Java 脚本。用于数据清洗、正则提取、格式转换。
- Variable Node(变量节点): 用于存储中间状态(Key-Value)。
- Expression Node(表达式节点): 用于简单的数学运算或逻辑判断(
score > 60)。 - 痛点解决: 很多初学者为了把 “2024-01-01” 转成 “Jan 1st”,竟然去调用一次 LLM。这是对算力和金钱的极大浪费。这一层告诉我们:能用代码写的,绝不用模型。
L2:智能算子层 (Cognitive Operator Layer) —— “系统的肌肉”
这一层引入了 LLM,但被限制为无状态的纯函数。
- 定义: 处理模糊语义的原子能力。
- 核心组件:
- Intent Node(意图识别): 输入用户 Query,输出分类标签(Class Label)。
- Extraction Node(信息抽取): 输入长文本,输出结构化 JSON(实体识别)。
- Generation Node(生成): 输入 Prompt,输出文本。
- 架构约束: 这一层的节点不应该做决策,它们只负责处理输入并返回输出。它们是流水线上的高级工人。
L3:增强接入层 (Augmentation Layer) —— “系统的外脑”
LLM 本身是无知的,这一层负责注入知识与工具。
- 定义: 为智能算子提供外部上下文。
- 核心组件:
- RAG Node(检索增强): 动态查库,注入 Context。这里涉及 Query Rewrite -> Retrieval -> Rerank 的完整链路。
- MCP Client(工具连接): 通过标准协议连接外部 API。
- Memory Fetcher(记忆提取): 从长期记忆中提取用户偏好。
- 关键逻辑: 这一层通常包裹在第 2 层节点的外围,形成 Pre-hook(前置增强) 机制。
L4:控制流层 (Control Flow Layer) —— “系统的脊梁”
这是 Workflow 最核心的一层。它决定了数据怎么走。
- 定义: 管理节点之间的跳转逻辑。
- 核心组件:
- Router(路由): 基于 Intent 的分流(Switch-Case)。
- Loop Controller(循环控制): 实现重试机制(Retry),并设置最大循环次数(防止死循环)。
- Parallel / Fan-out(并发): Map-Reduce 模式,同时启动多个分支处理任务。
- Aggregator(聚合): 等待所有分支完成,合并结果。
- 架构哲学: 这一层体现了**“代码治国”**的理念。所有的跳转逻辑都是显式的、可追踪的。
L5:交互协同层 (Interaction Layer) —— “系统的刹车”
AI 不应是全自动的黑盒,这一层负责人机交互 (HITL)。
- 定义: 允许人类介入流程,进行审批或修正。
- 核心组件:
- Approval Node(审批): 暂停流程,等待人工 Signal(Approve/Reject)。
- Feedback Node(反馈): 收集人工修改意见,注入 Context,指导 AI 重写。
- Input Node(补全): 当信息缺失时,反问用户,等待输入。
- 痛点解决: 解决了 Agent“闷头干错事”的风险。在高风险业务(如转账、发邮件)中,这一层是必选项。
L6:状态管理层 (State Management Layer) —— “系统的记忆”
Workflow 是有状态的 (Stateful)。
- 定义: 维护整个流程的生命周期数据。
- 核心组件:
- Global State(全局状态): 一个在所有节点间流转的共享对象(Context Object)。
- Checkpointer(检查点): 负责将状态序列化存入数据库(Redis/Postgres)。这使得 Workflow 可以“挂起”几天,甚至在服务重启后“断点续传”。
- History Tracker(历史追踪): 记录状态变更的不可变日志(Immutable Log)。
L7:编排治理层 (Orchestration & Governance Layer) —— “系统的大脑”
这是架构的顶层设计。
- 定义: 定义图谱结构,监控运行质量。
- 核心组件:
- Graph Definition(图定义): 使用 DSL(如 LangGraph, YAML)描述拓扑结构。
- Observability(可观测性): 追踪 Trace,统计 Token 消耗,可视化执行路径。
- Evaluation(评估): 建立自动化测试流水线,对产出质量进行打分。
第三部分:工程实战——一个七层架构的落地案例
理论是灰色的,而工程之树常青。
为了让大家真正理解这七层架构的威力,我们将深入一家世界 500 强企业的真实场景:构建一个自动化的“采购合同合规审核系统”。
这个系统的挑战在于:它既要处理极其复杂的非结构化文本(合同),又要遵循死板严苛的业务规则(合规),还要支持长达数天的人机协作流程。
我们将逐层解剖,看这七层架构是如何像精密齿轮一样咬合的。
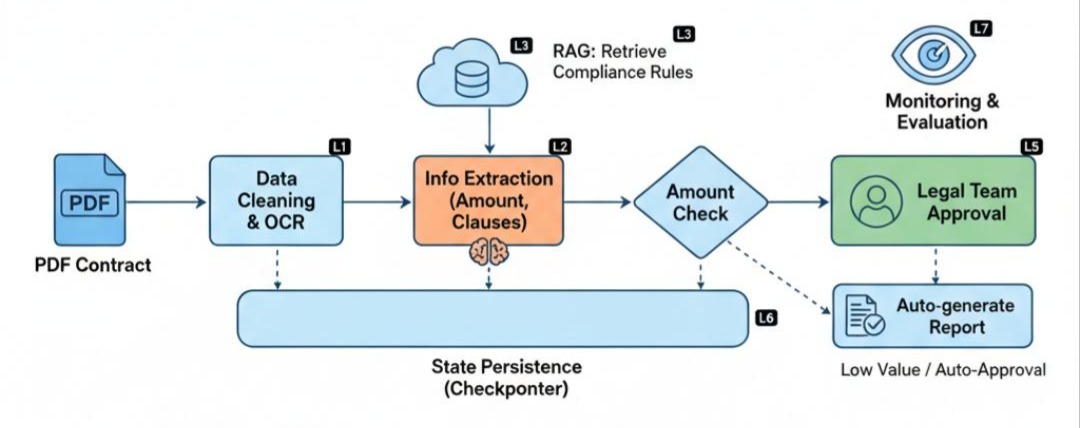
Step 1: 原子计算层 (L1) —— 脏活累活的基石
一切始于一份扫描版的 PDF 合同。
- 问题: PDF 里有大量乱码、水印、页眉页脚。如果直接扔给 LLM,不仅浪费 Token,还会干扰推理。
- 解决方案: 我们部署了一个 Code Node (Python)。
- 它调用 OCR 引擎提取文本。
- 它执行正则表达式清洗:
text = re.sub(r'\n\s*\d+\s*\n', '', text)(去除页码)。 - 它计算合同页数:
page_count = len(pdf.pages)。 - 价值: 这一层没有智能,但它保证了输入数据的纯净。垃圾进,垃圾出(GIGO),L1 层就是为了拦住垃圾。
Step 2: 智能算子层 (L2) —— 从文本到结构化数据
清洗后的文本长达 5 万字。现在需要提取核心信息。
- 设计: 我们串联了三个 Extraction Node (LLM)。
Node A: 提取基本信息(甲方、乙方、签署日期)。Node B: 提取财务条款(总金额、分期付款比例)。Node C: 提取风险条款(违约金上限、管辖法院)。- Prompt 策略: 我们强制要求 LLM 输出 JSON 格式:
{"total_amount": 100000, "penalty_rate": 0.05}。 - 价值: 这一层将模糊的自然语言,转换为了计算机可理解的结构化变量。
Step 3: 增强接入层 (L3) —— 注入“法务大脑”
LLM 虽然懂法律,但它不懂“这家公司的家规”。
- RAG Node (检索): 系统根据合同类型(如“IT采购”),去向量数据库中检索公司内部的《IT 采购合规白皮书》和《历史高风险案例》。
- Context Injection: 系统将检索到的 Top-5 关键条款(如“软件采购预付款不得超过 30%”),动态注入到 Prompt 中。
- 价值: 这一层解决了幻觉和领域知识缺失的问题,让通用大模型变身为公司内部的法务专家。
Step 4: 控制流层 (L4) —— 业务逻辑的脊梁
有了数据和规则,现在需要决策。这是 Workflow 的核心。
- Router (路由):
IF amount < 50,000: 走 Fast_Track(快速通道),直接调用 LLM 生成“审核通过”报告。IF amount > 1,000,000: 走 Committee_Review(委员会审核),触发更复杂的子流程。ELSE: 走 Standard_Review(标准流程)。- Loop Controller (循环):
- 如果在 L2 提取阶段,发现“违约金比例”缺失,流程不会继续,而是回退(Loop Back)到 L2,尝试用更强的模型(如 GPT-4)重新提取。
- 熔断: 如果重试 3 次依然失败,触发
Error_Handler,标记为“人工处理”。
Step 5. 交互协同层 (L5) —— 人类的最后一道防线
对于金额巨大的合同,AI 只能给建议,不能做决定。
- Approval Node (审批): 流程运行到这里,自动挂起 (Suspend)。
- 界面呈现: 法务专员的 OA 系统收到一条待办。界面左侧显示合同原文,右侧显示 AI 的风险提示:“注意:预付款比例 40% 超过了公司规定的 30% 红线。”
- Feedback Node (反馈): 专员点击“驳回”,并输入意见:“请采购部重新谈判付款比例。” 这条反馈被系统捕获,并作为 Context,触发 AI 自动生成一封给采购部的邮件草稿。
Step 6. 状态管理层 (L6) —— 穿越时间的记忆
这个审核流程可能持续一周。
- Checkpointer (持久化): 每当一个节点执行完毕,系统自动将当前的
Global State(包含合同内容、提取结果、审核记录)序列化并存入 Postgres 数据库。 - 断点续传: 即使在专员审批的那三天里,服务器重启了 10 次,当专员点击“提交”的那一刻,系统能准确地从数据库中恢复状态,继续执行后续的邮件发送流程。
Step 7. 编排治理层 (L7) —— 上帝视角
- Observability: 架构师通过 LangSmith 后台看到:本周共有 500 个合同流程在运行。其中
Standard_Review分支的平均耗时是 3 分钟,而Extraction_Node的 Token 消耗占了总成本的 60%。 - Evaluation: 针对 AI 的审核结果,系统每天自动抽取 10% 进行人工复核,计算出 AI 的召回率(风险点找全了吗?)和准确率(有没有瞎报警?)。
结语:从“单点突破”到“系统制胜”
通过对这个合同审核案例的深度拆解,我们看到了一个令人敬畏的工程真相:
构建一个真正的企业级智能系统,90%的工作是传统的软件工程(状态管理、控制流、持久化、人机交互),只有10%是模型调用。
流工程七层架构,正是为了管理这90%的复杂性而生。它告诉我们,AI不是魔法,它是算力;Agent不是神,它是组件。只有当我们把AI关进架构的笼子里,用代码去约束它,用状态去记忆它,它才能真正成为驱动企业运转的引擎。
蓝图已绘就,地图已展开。现在,是时候卷起袖子,去弄脏双手了。我们将从架构的最底层开始,去打磨那些看似不起眼、实则决定系统生死的“原子积木”。
The Missing Piece: 我们已经有了宏观的七层架构,但构成L1原子计算层的Code Node、Variable Node到底是什么?它们如何在Java世界中被定义和实现?
The Next Step: 在下一章 《解剖原子:用Java定义工作流的基石——代码、参数与模板节点》 中,我们将暂时忘掉LLM,深入流工程的微观世界。我们将学习如何构建一个“不含AI但极其强大”的数据预处理流水线,这将是你迈向AI架构师的第一步基本功。敬请期待。

