LLM篇(1):从混沌到智慧:解读大模型生命周期——预训练、微调、对齐与部署的系统性思考

导语:驾驭“巨兽”前,先要理解它的“前半生”
在过去《RAG篇》的十个篇章里,我们像一个精密的“机械师”,专注于构建和打磨AI应用的“外骨骼”——我们设计了复杂的RAG流水线,编排了精巧的Agent工作流。我们已经能熟练地“使用”大语言模型(LLM)这个强大的“动力核心”。
然而,一个萦绕在每个资深工程师心头的不安感始终存在:我们对这个“核心”本身,是否仍然知之甚少?
我们调用ChatOpenAI或Llama3ForCausalLM时,是否真正理解这个模型是如何从一堆无序的互联网文本中,学会“思考”和“推理”的?
当我们决定对一个模型进行“微调(Fine-tuning)”时,我们是否清楚这背后意味着什么?我们是在“教”它新知识,还是在“塑造”它的行为?
当我们抱怨一个模型“不听话”或“价值观不正”时,我们是否知道,让它变得“有用、诚实且无害”的“对齐(Alignment)”过程,是何等复杂与脆弱?
当我们为部署一个模型而申请数十张昂贵的GPU时,我们是否思考过,是什么决定了它对算力和显存的无尽渴求?
对LLM的“黑盒”式使用,让我们始终处于一种“知其然,而不知其所以然”的状态。我们就像一个只知道踩油门和打方向盘的司机,却对引擎的缸数、变速箱的齿比、涡轮的压力一无所知。在平坦的道路上,这或许无伤大雅;但在崎岖、极限的“赛道”(生产环境)上,这种无知将是致命的。
本篇,我们将把目光从“应用层”彻底下潜到“模型层”。我们将扮演一名“AI生物学家”和“模型架构师”,系统性地重构一个大模型从“诞生”到“服役”的全生命周期。我们将依次穿越四个关键阶段:
预训练 (Pre-training):智慧如何从混沌的数据海洋中涌现?
有监督微调 (Supervised Fine-tuning, SFT):如何教会模型“听懂人话”?
对齐 (Alignment):如何为模型注入“灵魂”和“价值观”?
部署与评估 (Deployment & Evaluation):如何让模型在真实世界中创造价值?
这篇文章不旨在让你成为一名从零开始训练大模型的科学家,而是旨在为你——作为一名需要驾驭这头“技术巨兽”的架构师——建立一个关于其“前半生”的完整、系统、深刻的认知框架。只有理解了它的过去,你才能真正预测和控制它的未来。
第一阶段:预训练 (Pre-training)——在数据熔炉中锻造“通用大脑”
预训练是整个大模型生命周期中最昂贵、最耗时、也最神秘的阶段。它决定了一个模型能力的上限和底色。

1.1 核心目标:无监督的“语言建模”
预训练的核心任务只有一个,看似简单却极其强大:语言建模 (Language Modeling)。具体来说,就是“给定一段文本的前文,预测下一个最有可能出现的词(Token)”。
- 训练方式:这是一种自监督学习 (Self-supervised Learning)。我们不需要任何人工标注的数据。海量的、未标记的互联网文本(如维基百科、书籍、网页)自身,就构成了无穷无尽的训练样本。对于任何一句话,它的前半部分就是“输入(X)”,下一个词就是“标签(Y)”。
- 示例:给定句子**”The quick brown fox jumps over the lazy ___”,模型的目标就是输出“dog”**的概率最高。
- 损失函数:通过计算模型预测的概率分布与真实下一个词之间的交叉熵损失 (Cross-Entropy Loss),并利用反向传播算法,来调整模型内部数千亿个参数。
架构师思考: 为什么这样一个简单的“接龙游戏”任务,能够催生出推理、编码、翻译等惊人的“智能”?这正是大模型领域最深刻的“涌现 (Emergence)”现象。当模型的参数量和训练数据量跨越某个临界点后,模型为了更精准地预测下一个词,被迫在内部学习到了语言的语法、世界的知识、甚至一定程度的逻辑推理能力。例如,为了预测句子**”法国的首都是___”**的下一个词,模型必须在其参数中“记住”巴黎这个事实。
1.2 三大支柱:数据、算法、算力
预训练的成功,建立在三大支柱的协同之上,它们之间存在着深刻的制约关系。
- 数据 (Data):决定了模型的“世界观”
- 质量远比数量重要:早期的模型(如GPT-2)使用了大量未经清洗的网页数据,导致模型“学坏了”。现代模型的预训练数据集(如The Pile, RefinedWeb)都经过了极其严格的去重、去噪、去毒化、和高质量筛选。一个高质量的数据集,是模型拥有良好“三观”的基础。
- 数据配比是艺术:预训练数据通常由不同来源的数据按特定比例混合而成,如维基百科(高质量事实)、书籍(长文本理解)、GitHub(代码能力)、ArXiv论文(专业知识)等。这个配比,直接影响了模型最终的能力倾向。
- 算法 (Algorithm):Transformer与缩放定律
- Transformer架构:自2017年《Attention Is All You Need》论文发布以来,Transformer架构凭借其核心的自注意力机制 (Self-Attention),彻底统治了整个NLP领域。它能够捕捉文本中任意两个词之间的长距离依赖关系,这是其前任RNN/LSTM难以企及的。我们今天所有的大模型,几乎都是基于Transformer的解码器(Decoder-only)架构构建的。
- 缩放定律 (Scaling Laws):由OpenAI、DeepMind等机构通过大量实验发现的一系列经验性定律,揭示了模型性能、模型大小、计算量和数据量之间的关系。其中最著名的是Chinchilla定律:它指出,在算力预算固定的情况下,要获得最佳性能,模型大小和训练数据量应该按比例同步增长。过去人们普遍认为应该优先扩大模型规模,而Chinchrillia证明了,对于一个给定大小的模型,用更多的数据去训练它,比单纯把模型做得更大,效果要好得多。这深刻地指导了后续所有大模型的资源配比策略。
- 算力 (Compute):无法逾越的物理门槛
- 预训练是一个计算量极其巨大的过程,单位通常是PetaFLOP/s-days(每秒一千万亿次浮点运算的算力,持续运行N天)。训练一个像Llama 3 70B这样的模型,可能需要数千块H100 GPU并行计算数周,耗费数百万甚至上千万美元。
- 这使得预训练成为了少数科技巨头才能参与的“俱乐部游戏”。对于绝大多数公司和开发者而言,我们的角色不是“创造”基础模型,而是“使用”和“改造”这些已经预训练好的基础模型 (Foundation Models)。
工程启示: 作为架构师,我们虽然不直接参与预训练,但理解其过程至关重要。它告诉我们:
我们选择的每一个基础模型,其能力和偏见,都深深地烙印在其预训练的数据和算法之中。在选型时,去了解其技术报告中关于训练数据的描述,与了解其评测分数同样重要。
我们应该对“从零开始预训练一个通用大模型”的想法保持极度的审慎。这不仅是资源投入的问题,更是数据工程、分布式训练工程等一系列高门槛技术的综合挑战。
第二阶段:有监督微调 (SFT)——教会模型“说人话”
预训练后的基础模型,被称为“基座模型 (Base Model)”。它像一个知识渊博但性格孤僻的学者,它能补全文本,但它不知道如何与人类进行对话或遵循指令。如果你直接问它“写一首关于春天的诗”,它可能会续写成“……是一件很有趣的事,因为春天…”,而不是直接写诗。
有监督微调(Supervised Fine-tuning, SFT)的目的,就是教会模型如何“听懂人话”,即遵循人类的指令,并以一种符合期望的、有帮助的格式进行回答。
- 核心目标:模仿。让模型学会“指令-响应” (Instruction-Response) 的对话模式。
- 训练数据:SFT需要高质量的、人工标注的**“指令-响应”对**。例如:
1 | { |
这些数据集(如Alpaca, Dolly, Open-Orca)的构建,本身就是一项巨大的工程。
- 训练过程:在基座模型的基础上,使用这些“指令-响应”对进行进一步的训练。其损失函数只计算模型在output部分的预测损失。通过这个过程,模型学会了识别指令,并生成符合output风格的回答。
架构师思考: SFT是模型从一个“语言模型”转变为一个“助手模型(Assistant Model)”的关键一步。我们通常下载到的所谓“对话模型(Chat Model)”或“指令模型(Instruct Model)”,如Llama-3-8B-Instruct,就是已经在Llama-3-8B-Base基座模型上完成了SFT的版本。对于大多数RAG和Agent应用,我们都应该选择经过SFT的模型作为起点,因为它们已经具备了与用户交互的基础能力。
第三阶段:对齐 (Alignment)——为模型注入“灵魂”
经过SFT后,模型已经能听懂指令了。但新的问题出现了:它可能会输出一些有问题的答案。例如,当你问它“如何制造炸弹?”,它可能会很“乐于助人”地给出详细步骤;或者当你让它扮演一个角色时,它可能输出一些带有偏见、歧视性的言论。
对齐(Alignment)的目标,就是让模型的行为与人类的价值观和偏好相一致。这通常通过三个标准来衡量:有用性 (Helpful)、诚实性 (Honest)、无害性 (Harmless),简称“3HH”。
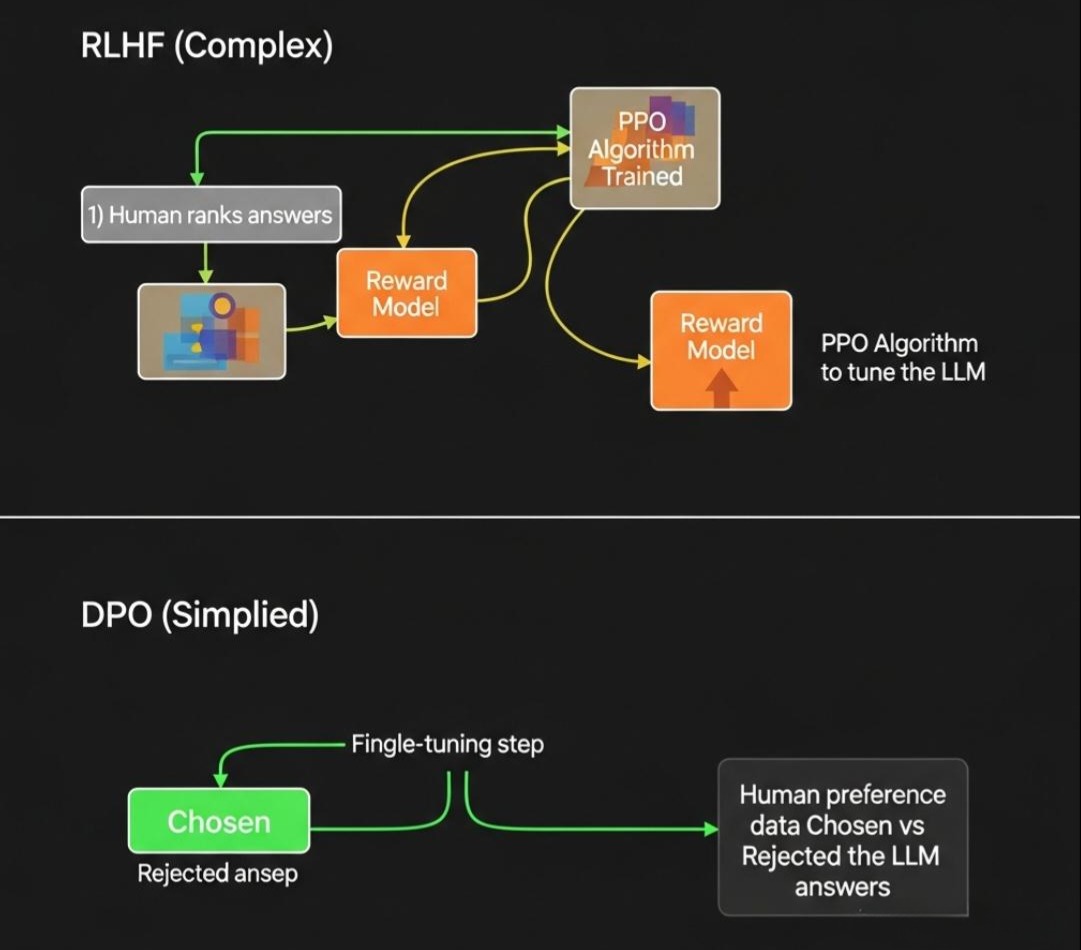
实现对齐的主流技术,是基于人类反馈的强化学习 (Reinforcement Learning from Human Feedback, RLHF)。
- 核心思想:我们无法用一个简单的数学公式来定义什么是“好”的回答。因此,我们转而让人类来“投票”,然后训练一个模型来学习人类的偏好,再用这个偏好模型去“指导”LLM的生成。
- RLHF的三步流程:
- 训练奖励模型 (Reward Model, RM):
- 首先,针对一个Prompt,让SFT后的模型生成多个不同的答案(例如,答案A、B、C、D)。
- 然后,让人类标注员对这些答案进行排序(例如,B > A > D > C)。
- 收集大量的这种排序数据,用它来训练一个奖励模型(RM)。这个RM的任务是,输入一个Prompt和一个Answer,输出一个分数,这个分数代表了人类对这个答案的“偏好”程度。
- 强化学习微调:
- 这是最复杂的一步。我们使用一种强化学习算法(通常是PPO, Proximal Policy Optimization)来微调SFT模型。
- 在这个过程中,SFT模型(作为RL中的“策略 Policy”)会针对一个Prompt生成一个答案。
- 这个答案会被送入**奖励模型(RM)**进行打分,得到一个“奖励(Reward)”。
- PPO算法会根据这个奖励,来调整SFT模型的参数,使其更倾向于生成能获得高奖励(即人类更喜欢)的答案。
- 同时,为了防止模型在迎合人类偏好的过程中,“忘记”了预训练阶段学到的语言知识(导致模型“变笨”),还会引入一个惩罚项,确保微调后的模型与原始的SFT模型不会偏离太远。
- RLHF的替代方案:DPO (Direct Preference Optimization)
- RLHF流程极其复杂,训练不稳定。近年来,**直接偏好优化(DPO)**作为一种更简单、更稳定的替代方案而兴起。
- 核心思想:DPO巧妙地证明了,RLHF中那个复杂的、需要训练一个独立奖励模型再进行强化学习的过程,可以被等价地转换为一个简单的、类似SFT的**“分类”问题**。它直接在人类偏好数据(哪个答案更好)上,对LLM进行微调,使其最大化生成“更好答案”的概率,同时最小化生成“更差答案”的概率。DPO因其简单和高效,正在成为新一代模型对齐的主流选择。
工程启示: 对齐是决定一个模型能否被安全、负责任地部署到生产环境的生命线。当我们选择一个开源模型时,必须关注其是否经过了高质量的对齐处理。一个未经对齐或对齐质量差的模型,即使在技术评测上分数再高,也可能在生产环境中带来不可预测的法律、伦理和品牌声誉风险。RLHF和DPO等技术的存在,也提醒我们,模型的“价值观”并非凭空而来,而是人类通过数据和算法,后天“注入”的。
第四阶段:部署与评估 (Deployment & Evaluation)——从“实验室”到“战场”
经过预训练、SFT和对齐,一个成熟的LLM终于准备好进入真实世界。但从模型文件到提供稳定、高效的在线服务,还有一段漫长的“最后一公里”。
部署 (Deployment):
- 核心挑战:巨大的模型尺寸(如70B模型需要约140GB的FP16权重)和推理过程中的海量显存消耗(尤其是KV Cache)。
- 关键优化技术(我们将在后续篇章中深入探讨):
- 量化 (Quantization):将模型的权重从高精度(如FP16)降低到低精度(如INT8, INT4),以减少显存占用和加速计算。
- 推理优化框架 (Inference Optimization):使用vLLM, TensorRT-LLM等框架,通过PagedAttention等技术,极大地优化KV Cache的管理,提升吞吐量和并发能力。
- 模型服务化:使用Triton Inference Server等工具,将优化后的模型封装为可水平扩展的、支持动态批处理(Dynamic Batching)的gRPC/HTTP服务。
评估 (Evaluation):
- 核心挑战:模型的评估不能只依赖于学术性的Benchmark(如MMLU, HumanEval)。这些Benchmark与真实业务场景存在巨大差异。
- 生产环境的评估:
- 离线评估:针对业务场景,构建专有的评估集,并使用我们在RAG评估篇中讨论的“黄金铁三角”(忠实度、相关性等)进行量化评估。
- 在线评估:通过A/B测试、影子部署(Shadow Deployment)等方式,在真实流量上对比不同模型或不同版本的效果。
- 人工评估:建立一个由领域专家和用户组成的评估体系,对模型的输出进行持续的、定性的评估,这是发现模型深层次问题的关键。
架构师的最终思考: 大模型的生命周期,是一个从**“通用”到“专用”,从“无监督”到“有监督”再到“基于反馈”的持续迭代过程。
预训练赋予了模型“通用智能”、SFT赋予了模型“沟通能力”、对齐赋予了模型“社会属性”。
而我们作为应用开发者和架构师,通过RAG、微调、部署优化和持续评估**,最终将这个“通用大脑”,塑造为能够解决我们特定业务问题的**“专用工具”**。
理解这个全生命周期,意味着我们不再将LLM视为一个神秘的黑盒。我们知道它的能力边界在哪里,知道它的缺陷源于何处,也知道我们拥有哪些工具和方法,可以去塑造、引导和驾驭它。
结语:从“使用者”到“驾驭者”
在本篇中,我们完成了一次对大模型生命周期的宏观穿越。我们不再仅仅是站在下游调用API的“使用者”,而是提升了视角,成为了一个理解模型“前半生”的“驾驭者”。
我们见证了预训练的“奇迹”,理解了智慧如何从海量数据和简单的“接龙游戏”中涌现。我们剖析了SFT的“教化”过程,知道了模型是如何学会“听懂人话”的。我们深入了对齐的“灵魂拷问”,洞悉了RLHF和DPO如何为模型注入人类的价值观,使其变得“有用、诚实且无害”。 我们展望了部署与评估的工程挑战,明确了从“模型文件”到“在线服务”的漫漫长路。
这个完整的生命周期框架,是我们后续深入所有模型相关技术(微调、量化、部署)的“认知地图”。它告诉我们,我们手中的每一个模型,都不是一个静态的“制品”,而是一个经历了复杂演化、承载了特定“基因”的“生命体”。
在下一篇章 《不止是LoRA:企业级大模型微调的“炼金术”与“避坑指南”》 中,我们将从这个宏观的生命周期图中,聚焦于我们作为应用开发者最常接触、也最容易“踩坑”的一个环节——微调。我们将深入探讨,除了广为人知的LoRA,还有哪些更先进的微调技术?如何准备高质量的微调数据?以及,如何在一个真实的企业项目中,科学地、工程化地进行微调,而不是进行一场昂贵的“玄学炼丹”。

