LLM篇(2):不止是LoRA:企业级大模型微调的“炼金术”与“避坑指南”
导语:从“玄学炼丹”到“科学工程”
在之前的《RAG》篇章中,我们已经掌握了驾驭大模型所需的全套“外骨骼”——从RAG的检索增强,到Agent的智能编排。现在,我们终于要触及那个最令人兴奋,也最容易“翻车”的核心环节:微调 (Fine-tuning)。
每个工程师的心中,都藏着一个“炼金术士”的梦想:用自己领域的少量数据,点石成金,将一个通用的Llama 3或Qwen模型,转化为一个精通本行业务、说话风格独一无二的“专属AI大脑”。
然而,现实往往是残酷的:
- 你耗费数千美元的GPU时常,用上万条业务数据进行微调,结果模型的性能不升反降,甚至开始“胡言乱语”。
- 你尝试了开源社区最火的LoRA脚本,但面对r, alpha, target_modules这些“神秘咒语”般的参数,只能靠“玄学”调参,结果时好时坏。
- 你发现微调后的模型学会了回答新问题,却忘记了如何进行基本的数学计算,出现了所谓的“灾难性遗忘”。
微调,不应是一场结果未知的“玄学炼丹”,而应是一门严谨、可控、可预测的“科学工程”。
本篇,我们将彻底撕开微调的神秘面纱。我们将扮演一名“模型外科医生”和“数据炼金术士”,系统性地解构企业级大模型微调的全流程。我们将:
- 正本清源: 明确微调“塑造行为”而非“灌输知识”的战略定位。
- 深入骨髓: 不止是LoRA,我们将深入剖析LoRA、AdaLoRA、DoRA、QLoRA等前沿PEFT方法的数学原理与适用场景。
- 点石成金: 提供一套高质量微调数据的“炼金术”——从自动化质量扫描到“买、造、采”的系统性方法论。
- 超越当下: 探讨多任务微调和持续学习等更高级的微调范式,以及微调背后深刻的伦理与商业影响。
这篇文章,旨在为你提供一份从“入门”到“精通”的企业级微调“实战圣经”。让我们开始这场从“炼丹”到“工程”的认知升级。
第一部分:微调的战略定位——“塑造行为”而非“灌输知识”
在开始任何微调项目前,必须回答一个根本性问题:我为什么需要微调? 错误的定位,是导致90%微调项目失败的根源。

1.1 微调的“能”与“不能”
- 微调擅长做什么?——塑造行为 (Behavior Shaping)
- 风格适应 (Style Adaptation): 让模型学会用特定的语气、格式、角色进行对话。例如,扮演一个严谨的法律助手,或一个风趣的营销文案写手。
- 指令遵循 (Instruction Following): 让模型更好地理解并遵循特定领域的复杂指令。例如,学会按你公司独有的JSON格式输出结果。
- 特定技能增强 (Skill Enhancement): 增强模型在特定任务上的表现,如代码翻译(从Python到Java)、特定领域的文本摘要等。
- 微调不擅长做什么?——灌输知识 (Knowledge Infusion)
- 根本原因: 大模型的知识,绝大部分存储在其预训练阶段学习到的数千亿个参数中。微调(尤其是参数高效微调PEFT)只改动了其中极小一部分参数,试图通过这种方式注入大量新的、模型从未见过的世界知识(如一个全新的医学领域),是极其低效且容易导致灾难性遗忘 (Catastrophic Forgetting) 的。
- 正确的做法: 对于知识密集型的任务,RAG(检索增强生成)永远是第一选择。通过RAG将相关知识作为上下文喂给模型,远比试图将知识“塞进”模型参数中更可靠、更具可解释性。
架构师的决断: 在启动一个项目时,必须进行“RAG vs. 微调”的灵魂拷问。
- 问题是知识驱动的(需要外部信息才能回答)?→ 优先考虑RAG。
- 问题是技能/风格驱动的(模型知道答案,但说得不好)?→ 考虑微调。
- 两者都需要?→ RAG + 微调的组合拳,用RAG提供知识,用微调塑造回答的风格和格式。
第二部分:参数高效微调 (PEFT)——不止是LoRA
对一个70B的模型进行全量微调(Full Fine-tuning),需要巨大的计算资源和显存。**参数高效微调(PEFT, Parameter-Efficient Fine-Tuning)**应运而生,其核心思想是:冻结大部分预训练模型的参数,只训练一小部分“适配器”参数。
2.1 LoRA:低秩适应的数学原理
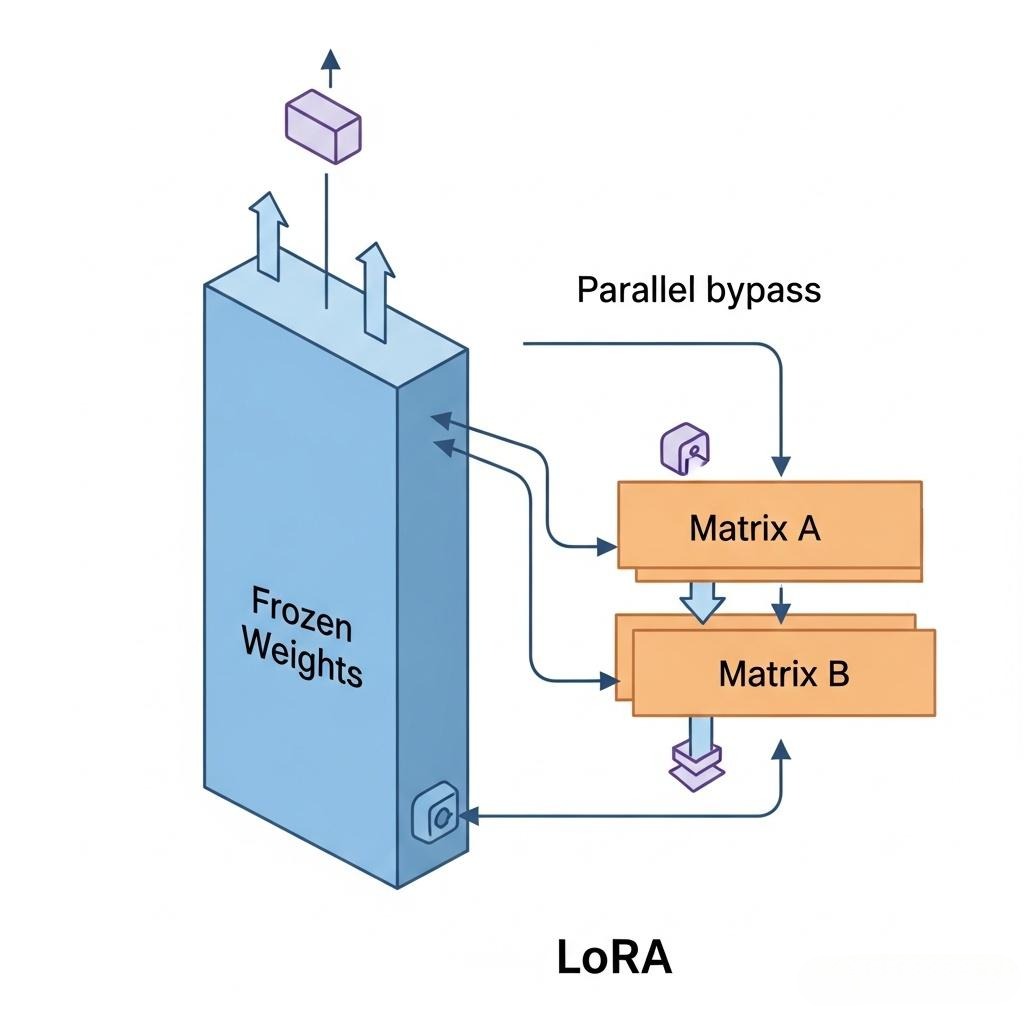
LoRA (Low-Rank Adaptation) 是目前最流行的PEFT方法。
- 核心洞察: 论文作者发现,大型语言模型在适应新任务时,其参数矩阵的**变化量(ΔW)是低秩(Low-Rank)**的。也就是说,这个巨大的变化矩阵,可以用两个小得多的矩阵相乘来近似表示。
- 数学原理:
- 一个预训练的权重矩阵 W (维度 d x k) 是被冻结的。
- 在微调时,我们不直接更新 W,而是在旁边增加两个可训练的“旁路”矩阵:A (维度 d x r) 和 B (维度 r x k),其中秩 r 远小于 d 和 k。
- 模型的前向传播变为:h = Wx + BAx。
- 训练时,只更新 A 和 B 的参数。B通常用全零初始化,A用高斯分布初始化,因此在训练开始时,BA=0,模型与原始模型完全相同。
- 核心超参数:
- r (Rank): LoRA的秩,是最关键的超参数。它控制了可训练参数的数量。r 越大,适配能力越强,但需要更多显存,也更容易过拟合。通常从8, 16, 32, 64中选择。
- lora_alpha: LoRA的缩放因子。输出的缩放比例是 alpha / r。通常将alpha设置为r的两倍,以获得更好的效果。这是一个经验性的设置。
- target_modules: 指定要应用LoRA的Transformer层。通常是q_proj, v_proj(自注意力机制中的Query和Value投影矩阵),有时也包括k_proj, o_proj, gate_proj, up_proj, down_proj。
2.2 PEFT方法大比拼:从LoRA到DoRA
LoRA并非唯一的选择,近年来涌现了大量优秀的改进方法。
| 方法 | 核心思想 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| LoRA | 低秩适应:用BA矩阵逼近权重变化ΔW。 | 简单高效,效果稳定,社区支持好。 | 秩r需要手动设置,所有适配器权重相同。 | 绝大多数SFT任务的默认首选。 |
| AdaLoRA | 动态分配秩:根据重要性动态地为不同矩阵和层分配不同的秩预算r。 | 更参数高效,能在更少的参数下达到与LoRA相当的效果。 | 算法稍复杂,训练开销略大。 | 对参数效率有极致要求,希望自动寻找最佳参数配比的场景。 |
| QLoRA | 量化+LoRA:将基座模型量化到4-bit,同时用LoRA进行微调。引入了新的量化数据类型(NF4)和双重量化。 | 极大降低显存占用,使得在单张消费级GPU上微调大模型成为可能。 | 性能略有损失(通常不大),需要支持4-bit量化的底层库。 | 显存极度受限,如在24GB的GPU上微调70B模型。 |
| DoRA | 权重分解+LoRA:将预训练权重W分解为“大小”和“方向”两部分,然后只用LoRA微调“方向”部分。 | 在相同的参数预算下,通常比LoRA性能更好,尤其是在预训练和微调任务差异较大时。 | 理论和实现更复杂,是一个较新的方法。 | 追求极致微调效果,愿意尝试SOTA新技术的场景。 |
架构师的决断:
- 新手入门/快速验证: 直接用 LoRA。
- 显存告急: 毫不犹豫选择 QLoRA。
- 追求更高性能,且不惧复杂性: 尝试 DoRA。
- 希望自动优化参数: 探索 AdaLoRA。
第三部分:高质量微调数据的“炼金术”
数据是微调的燃料,其质量直接决定了“炼金”的成败。 低质量、低多样性的数据,只会炼出“废铁”。
3.1 数据质量的自动化扫描:在训练前发现问题
在投入昂贵的GPU时常前,先用脚本对你的数据集进行一次“体检”。
- 核心扫描指标:
- 指令/响应长度分布: instruction或output是否过长或过短?过长的序列会消耗大量显存。
- 语言多样性: 数据是否只集中在几种语言?
- 指令复杂度: 使用动词-名词对来衡量指令的复杂度。例如,“解释”、“总结”比“列出”更复杂。你的数据集是否只包含简单的指令?
- 数据重复度: 使用n-gram重叠度或MinHash等方法,检查数据集中是否存在大量高度重复的样本。
- 敏感信息泄露: 使用正则表达式或NER工具,扫描数据中是否包含手机号、邮箱、身份证号等PII(个人身份信息)。
- 自动化脚本示例(Python伪代码):
1 | import pandas as pd |
3.2 数据来源的“炼金术”:买、造、采
- “买” - 采购高质量的商业数据集:
- 优点: 质量高,多样性好,省时省力。
- 缺点: 昂贵。
- 适用场景: 资金雄厚、对数据质量要求极高的企业。
2.“造” - 利用更强的LLM生成合成数据:
- 方法: 设计精巧的Prompt,让GPT-4或Claude 3 Opus等顶级模型,根据你的需求,生成大量的“指令-响应”对。
- 优点: 速度快,可控性强,可以定向生成特定领域、特定风格的数据。
- 缺点/风险:
- 多样性受限: 生成的数据可能风格单一,缺乏真实世界的多样性。
- 错误放大: 如果教师模型本身有错误,这些错误会被复制到学生模型中。
- 伦理与商业争议: 这正是**“污染开源模型生态”**的核心争议点。你用闭源的、强大的商业模型API生成的数据,去微调一个开源模型,然后发布或用于商业用途。这是否违反了API提供商的服务条款?这种“近亲繁殖”是否会让整个AI生态的基因多样性下降,最终导致所有模型都变得越来越像?这是一个没有简单答案的、深刻的行业性问题。
3.“采” - 从真实业务场景中挖掘和提炼:
- 来源:
- 客服对话记录: 提炼出用户的真实问题和金牌客服的优质回答。
- 内部文档/Wiki: 将文档的章节标题作为instruction,章节内容作为output,构建摘要或问答数据。
- 代码库: 提取函数签名和Docstring,构建代码生成或解释数据。
- 优点: 与业务场景最贴合,能解决真实问题。
- 缺点: 数据清洗和标注工作量大,且可能涉及隐私和合规问题。
第四部分:超越SFT:更高级的微调范式与“避坑指南”
4.1 更高级的微调范式
- 多任务微调 (Multi-task Fine-tuning):
- 思想: 与其在一个任务上微调,不如将多个不同但相关的任务(如文本摘要、代码生成、情感分析)的数据混合在一起进行微调。
- 优点:
- 提升泛化能力: 迫使模型学习到更通用的、跨任务的底层能力。
- 防止过拟合: 多样化的任务使得模型更难在任何一个单一任务上过拟合。
- 效率: 训练一个多任务模型,比为每个任务单独训练一个模型更高效。
- 持续学习 (Continual Learning / Lifelong Learning):
- 问题: 当有新的数据或新的任务到来时,我们如何更新模型,而又不让它忘记旧的知识?这就是灾难性遗忘问题。
- 解决方案(研究前沿):
- 弹性权重巩固 (Elastic Weight Consolidation, EWC): 在训练新任务时,对那些被认为对旧任务很重要的参数,施加一个惩罚,使其变化得更慢。
- 经验回放 (Experience Replay): 在训练新任务时,随机地混入一小部分旧任务的数据,让模型“温故而知新”。
4.2 训练过程中的“避坑指南”
- 灾难性遗忘的对抗:
- 原因: 微调过程中的梯度下降,会无差别地修改所有可训练参数,可能会破坏预训练阶段学到的通用知识。
- LoRA的天然优势: PEFT方法(如LoRA)本身在一定程度上就能缓解这个问题,因为它只更新了旁路参数,主干权重被冻结。
- 主动策略: 采用“经验回放”,在你的领域微调数据中,混入少量(如5-10%)通用的、高质量的SFT数据。
- 过拟合 (Overfitting):
- 表现: 模型在验证集上表现很好,但在面对真实、未见过的问题时,表现很差。
- 解决方案:
- 增加数据多样性: 永远是最好的方法。
- 降低r值: 减少可训练参数的数量。
- 使用更早的检查点 (Early Stopping): 监控验证集上的损失,当损失不再下降甚至开始上升时,就停止训练。
结语:微调——从“炼金术士”到“系统工程师”
在本篇中,我们完成了一次对企业级大模型微调的深度解剖。我们不再将微调视为一场充满玄学的“炼丹”,而是将其重构为一个严谨、科学的系统工程。
- 我们正本清源,确立了微调“塑造行为”的战略定位,并将其与RAG进行清晰的界定。
- 我们深入骨髓,不止步于LoRA,而是系统性地对比了AdaLoRA、QLoRA、DoRA等前沿PEFT方法的原理与权衡,并提供了清晰的选型决策框架。
- 我们点石成金,建立了一套从自动化数据质量扫描到“买、造、采”结合的高质量数据炼金术,并深刻反思了“合成数据”背后的伦理与商业困境。
- 我们超越当下,探讨了多任务微调和持续学习等更高级的范式,并为灾难性遗忘、过拟合等常见“坑”提供了可行的“避坑指南”。
掌握微调,意味着我们作为架构师,终于获得了**“定制”AI核心大脑的能力。我们不再是被动的使用者,而是能够根据业务需求,主动塑造模型行为的“系统工程师”**。
至此,我们已经深入探索了模型生命周期中最重要的几个阶段。然而,一个训练好、微调好、对齐好的模型文件,距离在生产环境中提供高并发、低延迟的服务,还有一座巨大的“工程鸿沟”需要跨越。
在下一篇章 《为模型注入“灵魂”:深度解析RLHF、RLAIF与DPO,构建更安全、更有用的AI》 中,我们将直面这个终极的“灵魂拷问”。我们将深入大模型生命周期中最深邃、也最关键的一环——对齐(Alignment)。我们将系统性地解剖经典的RLHF、探索前沿的RLAIF、并拥抱优雅的DPO,去理解如何为一个强大的智能体,注入“有用、诚实、无害”的核心价值观。
这将是一场关于压榨硬件极限、追求极致性能的硬核之战。


