LLM篇(4):解构模型推理的“速度与激情”——从vLLM到TensorRT-LLM的极限优化
导语:你的LLM服务,为何在“黎明之前”就已崩溃?
让我们从一个令无数AI工程师心碎的场景开始:
你和团队历经数月,成功地训练或微调了一个表现卓越的大模型。在本地单次运行时,它能在几秒内生成惊艳的答案。你们满怀信心地将其封装成一个API服务,并部署到了昂贵的A100/H100服务器上。
上线之初,一切安好。然而,当并发请求从1增加到10,再到50时,灾难发生了:
- 延迟急剧飙升:原本秒级的响应,变成了令人无法忍受的几十秒甚至几分钟。
- 吞吐量断崖式下跌:整个系统的QPS(每秒查询数)低得可怜,一块价值连城的GPU,其利用率甚至不足20%。
- 显存频繁OOM(Out of Memory):仅仅几十个并发请求,就轻易地撑爆了80GB的HBM显存,服务频繁崩溃重启。
你陷入了深深的自我怀疑。你明明拥有了世界上最强大的“F1赛车引擎”(LLM on H100),为什么在真实的“赛道”(生产环境)上,它的表现却像一辆“老年代步车”?问题出在哪里?
这就是LLM推理部署中最残酷的现实:一个未经优化的推理服务,其性能表现与模型的理论计算能力之间,存在着一个数量级的鸿沟。 这个鸿沟的根源,并非模型本身,而是由Transformer架构独特的“自回归(Autoregressive)”生成方式,以及其对海量显存的贪婪渴求所决定的。
本篇,我们将深入模型生命周期的最后、也是最考验工程“硬实力”的一环——部署与推理优化。我们将扮演一名“GPU性能分析师”和“底层优化工程师”,直面LLM推理的三大“性能杀手”:显存瓶颈、计算效率低下、调度策略原始。我们将:
- 深入第一性原理:从Transformer的KV Cache机制入手,剖析LLM推理为何在内存管理上如此“反常规”。
- 解构核心优化技术:系统性地拆解**PagedAttention、算子融合(Kernel Fusion)、量化(Quantization)、投机性解码(Speculative Decoding)**等一系列“黑魔法”背后的技术细节。
- 上演“三国杀”:对业界最主流的三大推理框架——vLLM、TensorRT-LLM、CTranslate2/FasterTransformer——进行一场从架构设计到性能表现的深度横评,并给出明确的选型指南。
这篇文章将不再停留在“如何使用”的表层,而是要带你潜入推理优化的“深水区”,理解其背后的数学、硬件与系统设计的精髓。这将是一场关于压榨硬件极限、追求极致性能的硬核之战,也是你从一个“模型使用者”蜕变为“高性能AI系统架构师”的必经之路。
第一部分:性能的“原罪”——Transformer自回归推理的内在瓶颈
要优化一个系统,必先深刻理解其瓶颈。LLM推理的性能问题,根植于其独特的“自回归”生成机制和巨大的内存消耗。
1.1 自回归生成:一个无法并行的“串行魔咒”

与一次性输出所有结果的“编码器”模型(如BERT)不同,LLM(通常是解码器架构)生成文本的方式是**“一个词一个词地往外蹦”**。
- Prompt处理阶段(Prefill/Processing Phase):模型首先并行地处理整个输入的Prompt,计算出其注意力权重等。这个阶段是**计算密集型 (Compute-bound)**的,可以充分利用GPU的并行计算能力。
- 解码阶段 (Decoding/Generation Phase):从第一个生成的Token开始,后续每一个Token的生成,都依赖于它前面所有已生成的Token。即,要生成第i+1个Token,必须先将第i个Token作为输入,送回模型进行一次前向传播。这个过程本质上是一个巨大的串行循环。
- 瓶颈转变:在解码阶段,每次只处理一个Token,计算量很小,GPU的大量计算单元处于空闲状态。此时,性能的瓶颈从“计算”瞬间转移到了**“内存带宽” (Memory-bound)**。模型的权重参数(几百GB)需要在GPU的HBM(高带宽内存)和SRAM(片上缓存)之间进行大量的、重复的数据搬运。
架构师思考:
这个“Prefill计算密集 -> Decoding内存密集”的两阶段特性,是LLM推理优化的核心挑战之一。一个优秀的推理系统,必须能够高效地处理这两种截然不同的负载模式。
1.2 KV Cache:一把加速的“双刃剑”
为了避免在生成每个新Token时,都重新计算前面所有Token的注意力信息,Transformer架构引入了KV Cache机制。
- 工作原理:在注意力机制中,每个Token都会生成一个Query (Q)、一个Key (K) 和一个Value (V) 向量。在计算第i+1个Token的注意力时,它只需要用自己的Q向量,去和前面i个Token的所有K和V向量进行计算。KV Cache就是将这i个Token的K和V向量缓存在GPU显存中,避免重复计算。
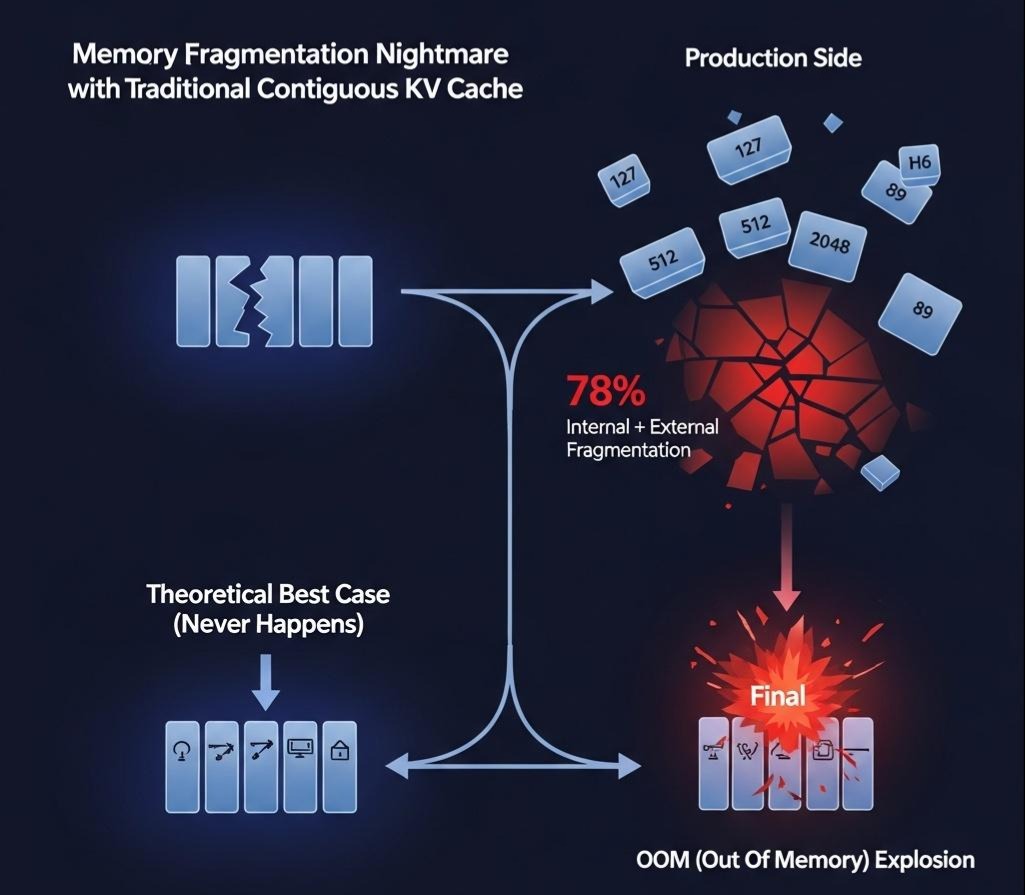
- 带来的问题:显存的“无底洞”
- 巨大的空间消耗:KV Cache的大小与**批次大小(Batch Size)和序列长度(Sequence Length)**成正比。其计算公式为:
2 * num_layers * num_heads * head_dim * batch_size * sequence_length。对于一个像Llama-70B这样的大模型,一个包含2048个Token的序列,其KV Cache的大小就可能达到数GB。 - 动态变化与内存碎片:更致命的是,每个请求的序列长度都在动态增长,导致KV Cache的大小也在不断变化。传统的内存管理方式(如PyTorch的reserve)会为每个请求预留一个能容纳其最大可能序列长度的连续内存块。
- 内部碎片:如果一个请求只生成了100个Token,但系统为它预留了2048个Token的内存空间,那么剩余的1948个Token的显存空间就被浪费了,这就是内部碎片。
- 外部碎片:当大量请求结束,释放了大小不一的内存块后,整个显存空间会变得像“瑞士奶酪”一样千疮百孔。即使总的剩余显存很大,也可能因为找不到一块足够大的连续内存块来服务一个新的长序列请求,而导致OOM。
工程启示:
KV Cache的管理效率,是决定LLM推理服务吞吐量的核心命门。 传统的内存管理方式,导致了高达60%-80%的显存被浪费在内存碎片上。谁能解决这个问题,谁就能在同样的硬件上,将服务吞吐量提升数倍。这正是vLLM等现代推理框架要解决的核心问题。
第二部分:核心优化技术深潜——现代推理框架的“秘密武器”
为了攻克上述瓶颈,业界发展出了一系列精巧的优化技术。
2.1 PagedAttention:vLLM的“核武器”
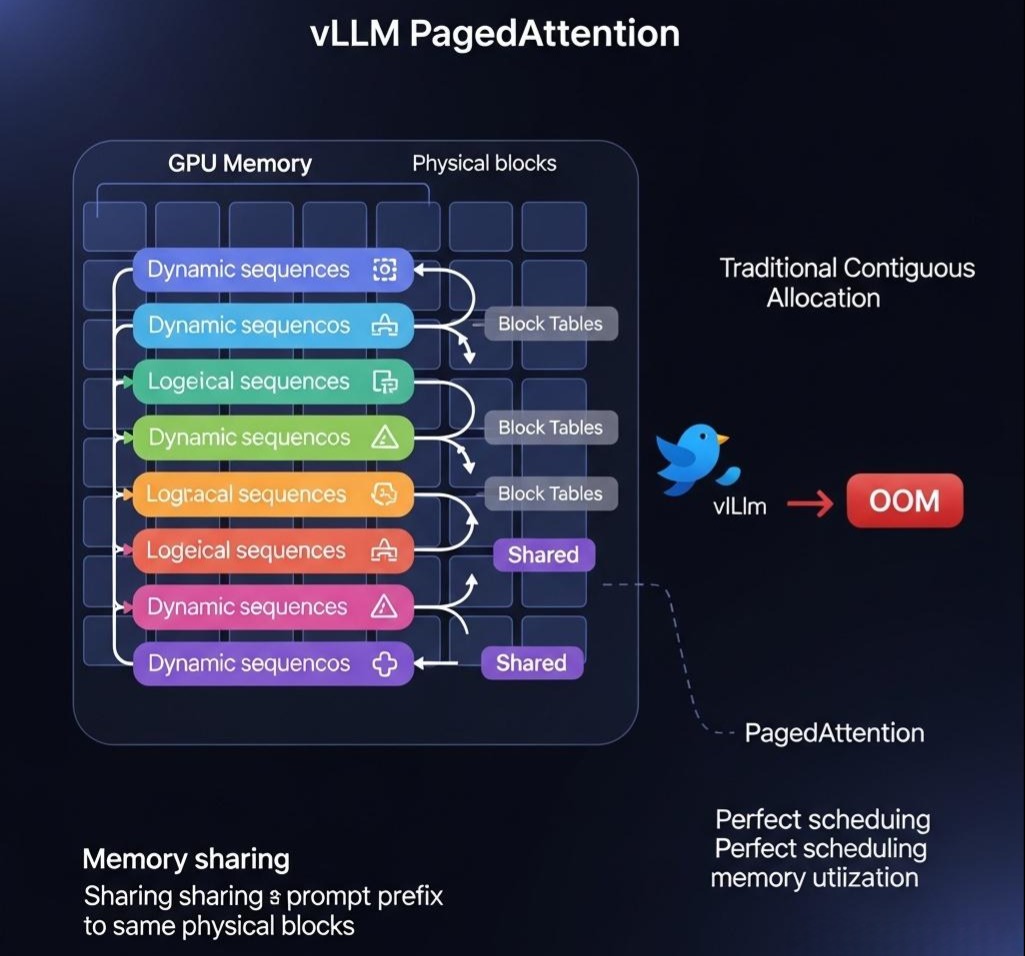
PagedAttention是vLLM框架的灵魂,它借鉴了操作系统中经典的**虚拟内存和分页(Paging)**思想,从根本上解决了KV Cache的内存碎片问题。
- 核心思想:不再为KV Cache分配巨大的、连续的内存块。而是将其分割成固定大小的、非连续的“物理块”(Physical Blocks)。
- 工作原理:
- Block Table:vLLM为每个请求维护一个“块表(Block Table)”,这个表记录了该请求的逻辑Token序列,映射到了哪些物理Block上。这就像操作系统中的页表。
- 按需分配:当请求的序列长度增长时,vLLM只需按需为其分配新的物理Block,并更新块表即可。这些Block在物理上可以是不连续的。
- 注意力计算修改:PagedAttention的核心,是修改了注意力计算的CUDA Kernel。这个新的Kernel能够直接读取Block Table,并从不连续的物理Block中,高效地抓取(Gather)所需的K和V向量,来完成注意力计算。
- 带来的革命性优势:
- 接近零的内部碎片:内存按块分配,浪费极小。
- 高效的内存共享:对于多个请求共享同一段前缀的场景(如Beam Search、并行采样),只需让它们的块表指向同一个物理Block即可,实现了显存的极致复用。
- 灵活的调度:由于内存管理变得高效,vllm可以实现更灵活、更高效的持续批处理(Continuous Batching)。当一个批次中的某个请求完成时,可以立刻将一个新的等待请求加入到批次中,而无需等待整个批次全部完成。这极大地提升了GPU的利用率。
架构师洞察:
PagedAttention是近年来LLM推理领域最重要的算法创新之一。它将一个看似纯粹的硬件/内存管理问题,通过巧妙的算法和底层Kernel的修改,转化为了一个系统级的、数量级的性能提升。这体现了顶级的系统设计思维:深入瓶颈的第一性原理,并从最底层进行重塑。
2.2 算子融合 (Kernel Fusion):减少GPU的“上下文切换”
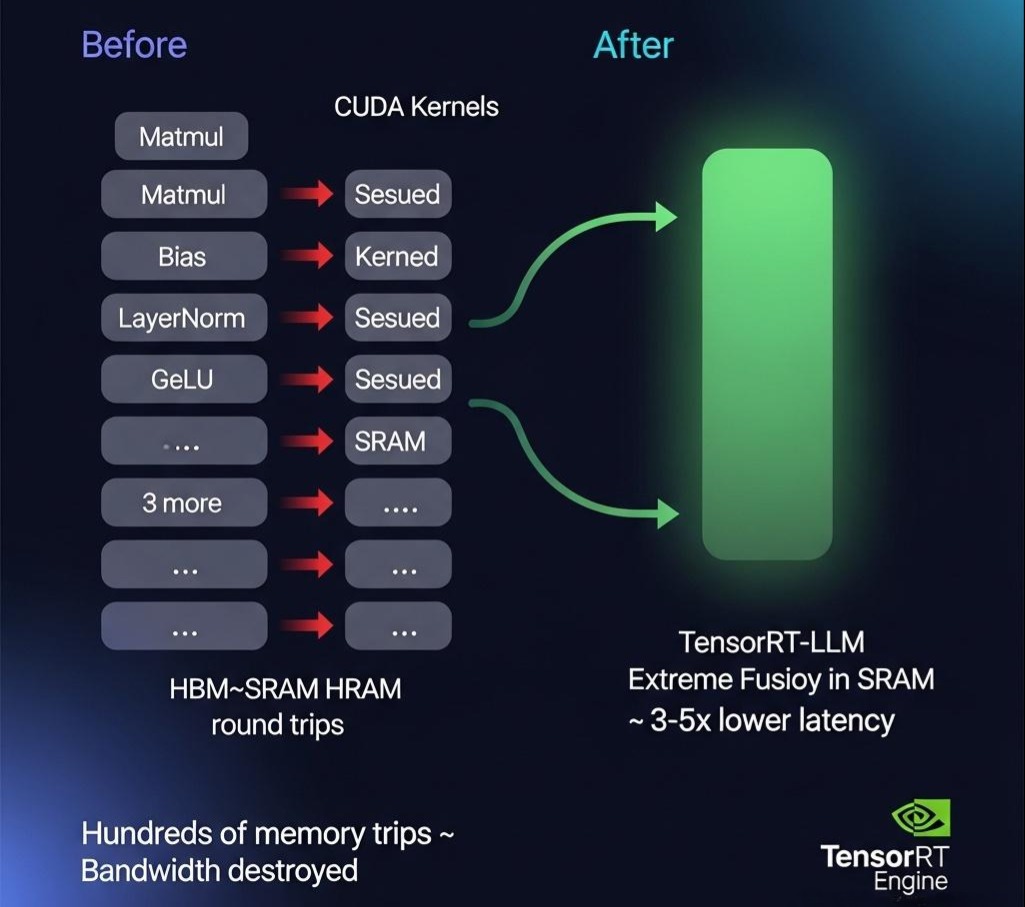
- 核心思想:LLM的计算流程中,包含了大量的、独立的计算操作(如矩阵乘、加法、激活函数等)。每次操作都需要启动一个独立的CUDA Kernel。Kernel的启动和终止本身是有开销的,并且每次操作都需要将数据从GPU的全局内存(HBM)读到计算单元的缓存(SRAM)中,再写回。这个过程的瓶颈往往在内存带宽,而非计算本身。算子融合就是将多个连续的、可以合并的计算操作,融合成一个单一的、更复杂的CUDA Kernel。
- 示例:
Matmul -> Bias Add -> ReLU这三个操作,可以被融合成一个FusedMatmulBiasReLUKernel。 - 优点:
- 减少Kernel启动开销。
- 减少内存读写:中间结果(如Matmul的输出)可以直接保留在高速的SRAM中,供下一步(Bias Add)使用,而无需写回慢速的HBM,极大地缓解了内存带宽瓶颈。
- 实现者:TensorRT-LLM 和 DeepSpeed Inference 等框架,都依赖于强大的图编译器,能够自动地分析计算图,并进行最大程度的算子融合。
2.3 量化 (Quantization):用“精度”换“速度”的艺术

- 核心思想:将模型权重和/或激活值,从高精度的浮点数(如FP16,16位)表示,转换为低精度的整数(如INT8, INT4)表示。
- 带来的好处:
- 减少模型大小和显存占用:INT8量化可以直接将模型大小减半,INT4量化则可以减少75%。
- 加速计算:现代GPU对低精度整数运算有专门的硬件支持(如Tensor Cores),其计算速度远超浮点运算。
- 降低内存带宽压力:搬运的数据量变得更小。
- 关键技术与权衡:
- PTQ (Post-Training Quantization):在模型训练后进行量化。它简单快速,但可能会有较大的精度损失。
- SmoothQuant:一种先进的PTQ技术,它通过在数学上“平滑”激活值的分布,使得量化过程中的误差更小。
- AWQ (Activation-aware Weight Quantization):它观察到,模型中并非所有权重都同等重要。它通过保护那些对模型性能影响最大的“显著权重”不被量化或以更高精度量化,来最小化精度损失。
- QAT (Quantization-Aware Training):在训练(或微调)过程中就引入模拟的量化操作,让模型“学会”适应低精度表示。效果最好,但需要额外的训练过程。
- W4A16 vs. W8A8:W4代表权重用4位整数,A16代表激活值依然用16位浮点数。这是一种常见的、在性能和精度之间取得良好平衡的策略。而W8A8则对权重和激活值都进行8位量化,加速效果更著,但精度损失风险也更大。
2.4 投机性解码 (Speculative Decoding):让“小模型”为“大模型”开路
- 核心思想:利用一个小得多的、但速度极快的“草稿模型(Draft Model)”,来并行地预测接下来k个Token。然后,再让原始的、强大的“验证模型(Verification Model)”一次性地、并行地验证这k个预测是否正确。
- 工作流程:
- 草稿模型(如一个1.3B的模型)一口气生成5个Token的草稿:A, B, C, D, E。
- 验证模型(如一个70B的模型)并行地、一次性地验证这5个草稿。它会判断:给定Prompt,生成A是否正确?给定Prompt+A,生成B是否正确?以此类推。
- 如果前3个草稿A, B, C都验证通过,但第4个D验证失败,那么系统就直接接受A, B, C,并让验证模型自己生成正确的第4个Token D’。
- 然后,再从D’开始,重复这个过程。
- 性能提升:在理想情况下(草稿模型的预测大部分正确),系统可以用一次大模型的并行计算,换来多次串行的解码步骤,从而将解码速度提升2-3倍。
架构师思考:
这四大优化技术,分别从内存管理、计算效率、模型压缩、解码算法四个完全不同的维度,向LLM推理的性能瓶瓶颈发起了总攻。一个顶级的推理框架,必然是这些技术的集大成者。
第三部分:推理框架的“三国杀”——vLLM vs. TensorRT-LLM vs. CTranslate2
理解了核心技术后,我们终于可以来审视市面上的主流推理框架,并做出明智的选型。
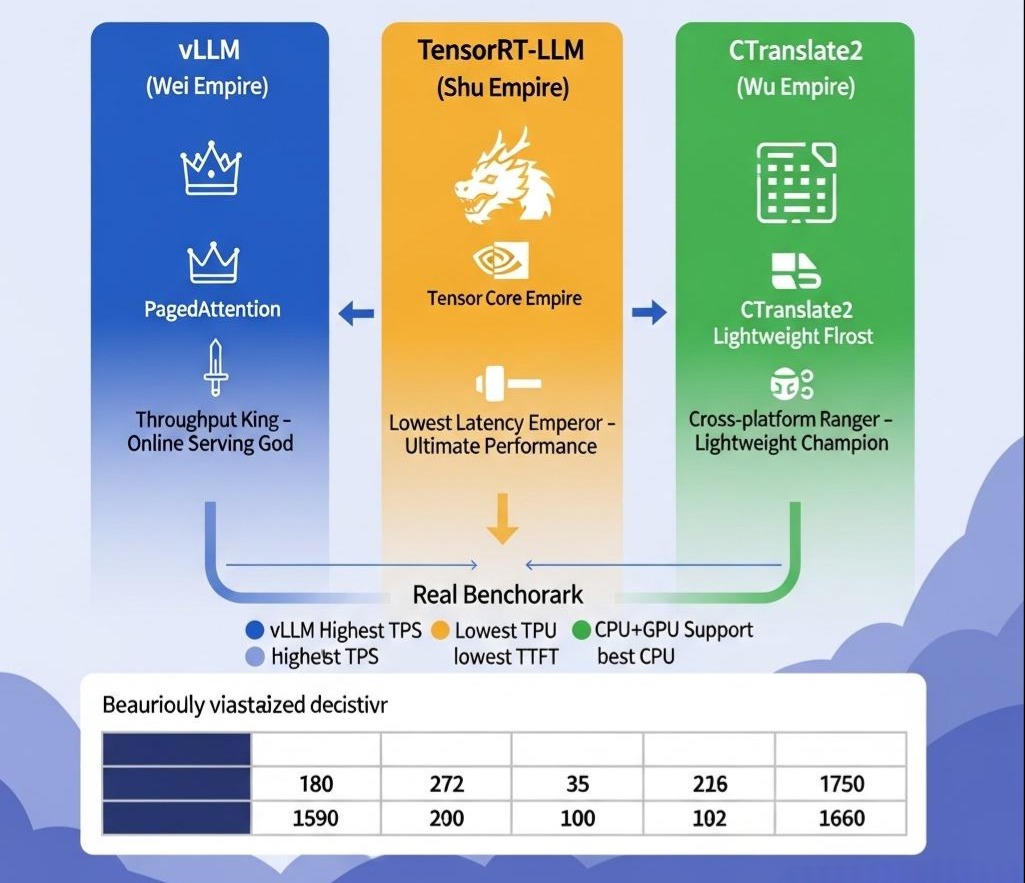
3.1 vLLM:易用性与高性能的王者
- 核心武器:PagedAttention。vLLM的灵魂就是PagedAttention,它带来了极高的吞吐量和GPU利用率,尤其擅长处理大量并发的、序列长度动态变化的在线服务场景。
- 优点:
- 极高的吞吐量:通过PagedAttention和Continuous Batching,其吞吐量通常是标准HuggingFace实现的数倍甚至数十倍。
- 易用性:提供了与HuggingFace transformers库高度兼容的API,迁移成本极低。你通常只需改几行代码,就能享受到巨大的性能提升。
- 生态活跃:作为目前最受欢迎的推理框架之一,社区活跃,迭代迅速。
- 缺点:
- 优化相对单一:其核心优势主要来自内存管理。在纯粹的单次计算速度上,它可能不如经过深度算子融合的框架。
- 硬件支持:主要针对NVIDIA GPU优化。
- Java生态集成:vLLM提供了与OpenAI兼容的API Server。在Java中,最简单的集成方式就是将Python的vLLM服务启动,然后通过HTTP客户端调用其API。
1 | // 使用WebClient调用vLLM的OpenAI-compatible API |
3.2 TensorRT-LLM:NVIDIA的“官方屠龙刀”,追求极致性能
- 核心武器:深度算子融合 和 极致硬件优化。作为NVIDIA的“亲儿子”,TensorRT-LLM能够利用TensorRT这个强大的图编译器,将LLM的计算图优化到极致,并针对NVIDIA的每一代GPU硬件(如Tensor Cores, Hopper架构特性)进行压榨式的优化。
- 优点:
- 最低的延迟:在单次请求或小批量请求的场景下,TensorRT-LLM通常能提供最低的推理延迟。
- 全面的优化技术:它几乎集成了所有已知的优化技术,包括In-flight Batching(类似Continuous Batching)、PagedAttention(虽然是后来加入的)、各种量化方案、算子融合等。
- 性能可预测:由于模型在编译后基本固化,其性能表现非常稳定和可预测。
- 缺点:
- 复杂的工作流:使用TensorRT-LLM需要一个“编译”步骤。你需要先将你的模型(如HuggingFace格式)编译成一个TensorRT引擎(.engine文件)。这个过程本身就比较复杂,且编译出的引擎与特定的GPU型号和TensorRT版本绑定,不具备可移植性。
- 易用性较差:相比vLLM,其API和部署流程更繁琐,学习曲线更陡峭。
- 适用场景:对延迟有极致要求的场景(如实时对话、游戏AI),或者在模型和硬件环境都非常固定的情况下,追求最高吞吐量的离线批处理任务。
3.3 CTranslate2 / FasterTransformer:轻量级、跨平台的“游骑兵”
- 核心武器:轻量化 和 跨平台CPU/GPU支持。它们是由学术界和开发者社区驱动的轻量级推理引擎。
- 优点:
- 轻量:库本身非常小,依赖少,易于集成到各种应用中。
- 跨平台:不仅支持NVIDIA GPU,还对CPU(使用Intel MKL等库)进行了深度优化,在CPU上的推理性能非常出色。
- 速度快:对于中小型模型,其性能非常有竞争力,有时甚至能超过更复杂的框架。
- 缺点:
- 功能相对有限:对Continuous Batching、PagedAttention等高级特性的支持不如vLLM或TensorRT-LLM完善。
- 生态和社区:相比前两者,社区规模和迭代速度较慢。
- 适用场景:需要在CPU上进行推理的场景、资源受限的边缘设备、或对中小型模型进行快速部署。
架构师选型决策矩阵
| 维度 / 框架 | vLLM | TensorRT-LLM | CTranslate2 |
|---|---|---|---|
| 核心优势 | 高吞吐量 (在线服务) | 低延迟 (极致性能) | 轻量、跨平台 (CPU/GPU) |
| 易用性 | ★★★★★ (极高) | ★★☆☆☆ (复杂) | ★★★★☆ (较高) |
| 部署流程 | 简单 (纯Python) | 复杂 (编译+部署) | 简单 (C++/Python) |
| 关键技术 | PagedAttention | 算子融合、硬件优化 | 高效的C++实现 |
| 最佳适用场景 | 高并发在线API服务 | 对延迟极度敏感的应用 | CPU推理、边缘部署、中小型模型 |
结语:没有“银弹”,只有最适合你的“武器”
在本篇万字长文的深度探索中,我们完成了一次对LLM推理优化领域的极限深潜。我们不再满足于表面的API调用,而是深入到了性能瓶颈的“第一性原理”。
- 我们剖析了自回归生成和KV Cache这枚“双刃剑”是如何从根本上决定了LLM推理的性能宿命。
- 我们系统性地解构了PagedAttention、算子融合、量化、投机性解码这四大“秘密武器”,理解了它们是如何从内存、计算、模型压缩和算法层面,向性能瓶颈发起总攻。
- 我们上演了一场vLLM、TensorRT-LLM和CTranslate2的“三国杀”,为你提供了一份清晰的、基于场景和权衡的架构选型指南。
推理优化,是AI工程“深水区”中最硬核、也最见功底的一环。它是一场在算法、软件和硬件三者交界处的“极限舞蹈”,要求架构师具备跨越多个技术栈的系统性视野。掌握它,意味着你真正拥有了将强大的AI模型,转化为可靠、高效、可盈利的商业服务的能力。
至此,我们已经系统性地走完了“应用层(RAG/Agent)”和“模型层(生命周期/优化)”的核心技术图谱。一个完整的AI系统蓝图已经呼之欲出。
在下一篇章 《多模态的“融合之道”:从CLIP到LLaVA-NeXT,构建能“看”会“听”的下一代AI》 中,我们将把我们的视野,从纯粹的“文本世界”,扩展到更广阔、更精彩的多模态世界。我们将探索,当LLM拥有了“眼睛”(视觉)和“耳朵”(语音)之后,会爆发出怎样惊人的新能力?CLIP、BLIP、LLaVA这些令人眼花缭乱的模型背后,其统一的架构思想又是什么?这将是一次通往更通用人工智能(AGI)的激动人心的旅程。


