LLM篇(5):多模态的“融合之道”:从CLIP到LLaVA-NeXT,构建能“看”会“听”的下一代AI
导语:当AI走出“柏拉图的洞穴”
在过去的十几个篇章里,我们投入了巨大的精力,去构建和优化一个基于纯文本的智能系统。我们的RAG能检索海量文档,我们的Agent能调用API和编写代码。我们似乎已经打造了一个极其强大的“语言大脑”。
然而,这个大脑,却像一个生活在柏拉图“洞穴”中的囚徒。它所有的知识和推理,都来自于墙壁上的“文本影子”,它从未真正“看见”过真实的世界。
想象一下这些场景:
- 你向你的AI助手上传了一张产品设计草图,问道:“这个UI布局是否符合我们的设计规范?右下角的按钮颜色能否更醒目一些?”
- 在智能客服中,一个用户发来一张设备故障的截图,上面有清晰的错误代码,并问道:“这个红色的报错是什么意思?我该怎么办?”
- 在自动驾驶的研发中,系统需要根据车载摄像头捕捉到的实时街景,理解并用自然语言描述:“前方路口有一辆正在左转的卡车,且有行人在人行道上等待,存在潜在风险。”
面对这些充满了视觉信息的任务,我们之前构建的、强大的纯文本RAG和Agent系统,瞬间变得无能为力。它们是“文盲”,更是“睁眼瞎”。
这就是纯文本模型的根本局限:人类的知识和经验,绝大部分是以非文本的形式存在的。 图像、视频、音频、图表……这些丰富的、多维度的信息,构成了我们认知世界的基石。一个无法理解这些信息的AI,其智能注定是片面的、残缺的。
本篇,我们将带领AI走出“柏拉图的洞穴”,赋予它“眼睛”和“耳朵”。我们将深入探索**多模态大模型(Large Multimodal Models, LMMs)**的“融合之道”。我们将:
- 追本溯源:从CLIP的革命性思想出发,理解它是如何打通“视觉”与“语言”两大模态,构建起一座“语义之桥”的。
- 解构架构演进:系统性地梳理LMM从**“连接主义”(如BLIP、Flamingo)到“端到端原生”**(如LLaVA、IDEFICS)的两大技术流派和其背后的设计哲学。
- 深入前沿:剖析以LLaVA-NeXT和Google Gemini为代表的最新模型,看它们是如何在分辨率、长视频理解等“硬骨头”问题上取得突破的。
- 探索应用:探讨如何将这些强大的多模态能力,与我们已经掌握的RAG和Agent范式相结合,构建出真正能“看懂世界”的下一代AI应用。
这是一次从“单一模态”到“多维感知”的认知升级,也是我们通往更通用人工智能(AGI)的必经之路。让我们开始学习如何构建一个既能“读万卷书”,又能“行万里路”的AI。
第一部分:CLIP的“创世纪”——构建视觉与语言的“罗塞塔石碑”
在探讨任何现代LMM之前,我们都必须回到梦开始的地方——OpenAI在2021年发布的**CLIP (Contrastive Language-Image Pre-training)**模型。CLIP的出现,其重要性不亚于Transformer之于NLP。它从根本上解决了多模态领域最核心的问题:如何让机器知道一张图片和一句话说的是同一件事?
1.1 CLIP之前的困境:分离的世界
在CLIP之前,视觉和语言模型生活在两个平行的宇宙里。
- 计算机视觉(CV):主流范式是“有监督分类”。你需要为ImageNet这样的数据集,人工标注数百万张图片,告诉模型“这张是猫”、“那张是狗”。这种方法扩展性极差,模型只能识别它见过的、有限的类别。
- 自然语言处理(NLP):正在经历Transformer带来的革命,但它处理的只是文本。
如何将两者连接起来?当时的尝试大多笨拙且低效。
1.2 CLIP的革命性思想:对比学习与“零样本”识别
CLIP的作者们提出了一个石破天惊的想法:与其教模型识别固定的类别,不如直接在互联网上那数以亿计的“图片-文本”对上,学习它们之间的对应关系。
核心思想:对比学习 (Contrastive Learning)
- 数据:从互联网上收集了4亿个高质量的
(image, text)对。这里的text是与图片相关的自然语言描述。 - 双编码器架构 (Dual-Encoder Architecture):
- 一个图像编码器 (Image Encoder),如ResNet或Vision Transformer (ViT),负责将输入的图片编码成一个向量
I_vec。 - 一个文本编码器 (Text Encoder),如Transformer,负责将输入的文本编码成一个向量
T_vec。
- 训练目标:拉近正例,推远负例:
- 在一个批次(Batch)中,假设有N个图片-文本对。那么,就有N个“正例”(匹配的图片和文本)和
N^2 - N个“负例”(不匹配的图片和文本)。 - CLIP的训练目标非常简单:通过调整两个编码器的参数,使得正例对的向量
(I_vec_i, T_vec_i)在向量空间中的余弦相似度尽可能高,而负例对的向量(I_vec_i, T_vec_j)(其中i≠j)的余弦相似度尽可能低。
这个过程,就像是为视觉和语言这两个原本使用不同“语言”的世界,构建了一块“罗塞塔石碑”。经过训练后,一张关于“猫”的图片,和一句话“a photo of a cat”,会被映射到向量空间中非常相近的位置。
带来的魔法:零样本识别 (Zero-shot Recognition)
CLIP的训练方式,赋予了它前所未有的“零样本”识别能力。如果你想判断一张图片里是什么,你不再需要一个预先训练好的分类器。你只需要:
- 将待识别的图片输入图像编码器,得到图片向量
I_test。 - 构造一组候选的文本描述,如 “a photo of a dog”, “a photo of a cat”, “a photo of a car”…
- 将这些文本描述分别输入文本编码器,得到一组文本向量
T_dog,T_cat,T_car… - 计算
I_test与哪一个文本向量的余弦相似度最高,那么图片的内容就是那个文本所描述的东西。
这意味着,你可以用任意的自然语言描述,来对图片进行“开放世界”的分类,而无需任何额外的训练!
架构师洞察:
CLIP的诞生,是多模态领域的“寒武纪大爆发”的起点。它提供了一种统一的、可扩展的、语义丰富的方式来表示和关联图像与文本。后续几乎所有的多模态大模型,其视觉理解部分,都或多或少地建立在CLIP或其变体所奠定的“视觉-语言联合嵌入空间”这一基石之上。理解CLIP,是理解所有LMMs的钥匙。
第二部分:LMM的架构演进——两大流派的“融合之战”
在CLIP打通了视觉和语言的“任督二脉”之后,如何将这种多模态理解能力与强大的LLM的生成和推理能力结合起来,成为了新的焦点。业界逐渐演化出两大技术流派。

2.1 流派一:“连接主义”——用“胶水”粘合专家
这一流派的核心思想是保持预训练的视觉模型和LLM的独立与冻结,只在它们之间训练一个轻量级的“连接模块(Connector)”,充当“翻译官”或“胶水”。
- 代表模型:Flamingo (DeepMind), BLIP-2 (Salesforce)。
以BLIP-2为例的架构剖析:
- 冻结的图像编码器:通常是一个预训练好的ViT(源自CLIP或类似模型),负责将输入图像转换为一系列视觉特征向量。
- 冻结的LLM:通常是一个开源的、经过指令微调的LLM(如OPT, Flan-T5)。
- 核心创新:Q-Former (Querying Transformer):
- Q-Former是BLIP-2的灵魂,它是一个轻量级的、可训练的“连接模块”。
- 作用:它的作用是,接收来自LLM的“问题”(以一组可学习的Query向量的形式),然后去“审问”冻结的图像编码器输出的、冗长的视觉特征,并从中提取出与问题最相关的、一小部分(例如32个)精炼的视觉特征。
- 本质:Q-Former就像一个高效的**“视觉信息摘要器”**。它避免了将海量的原始视觉特征直接硬塞给LLM,而是进行了一次智能的、与任务相关的“信息过滤”。
4.** 训练过程**:在训练BLIP-2时,图像编码器和LLM的参数是完全冻结的,只训练Q-Former和连接LLM的线性层。这使得训练成本极低,速度极快。
架构师思考:
连接主义”流派是一种极其务实和高效的工程方案。它最大限度地复用了社区已经存在的、强大的单一模态模型,避免了昂贵的端到端训练。其缺点在于,“胶水”模块的表达能力有限,可能会成为信息传递的瓶颈,导致视觉信息在传递给LLM的过程中有所损失。
2.2 流派二:“端到端原生”——迈向真正的多模态统一
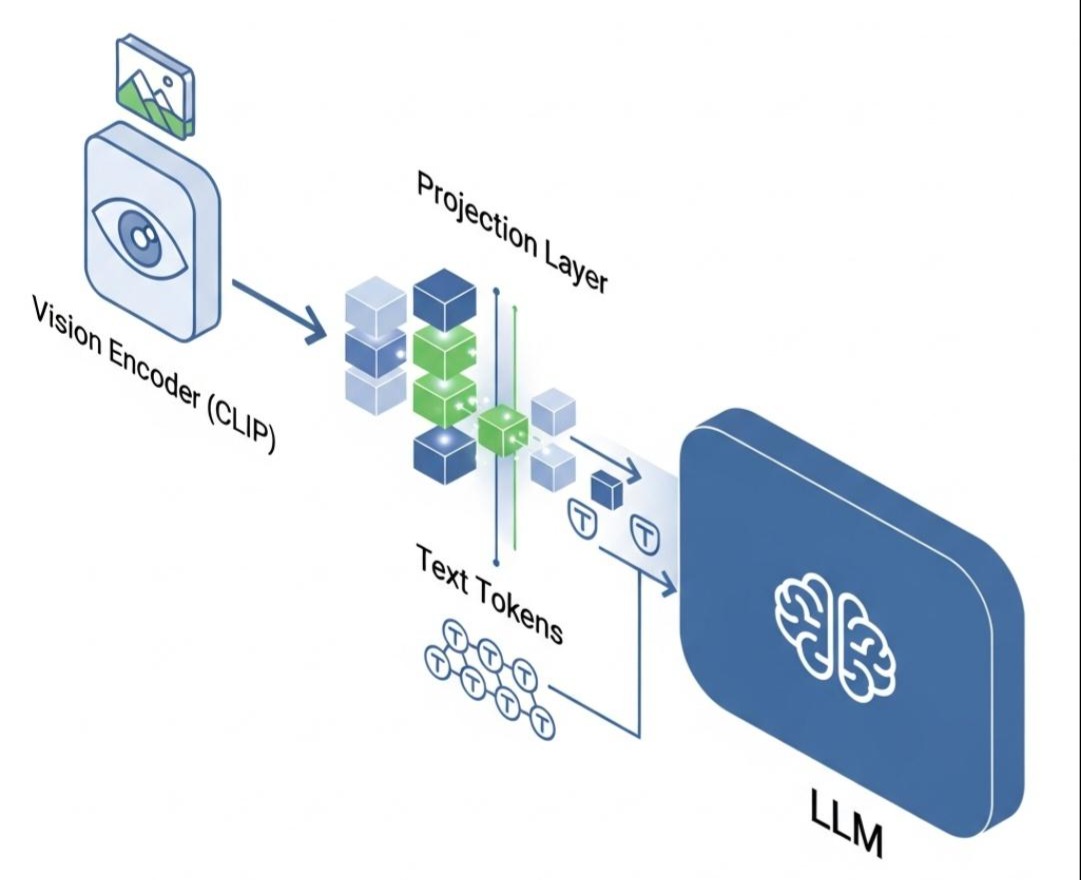
这一流派的目标更宏大:将视觉特征直接“注入”到LLM的词向量空间中,让LLM从一开始就能像处理文本Token一样,无缝地处理视觉Token。
- 代表模型:LLaVA (Large Language and Vision Assistant), IDEFICS, LLaVA-NeXT。
以LLaVA为例的架构剖析:
- 视觉编码器:同样,使用一个预训练好的、冻结的CLIP ViT来提取图像特征。
- 投影层 (Projection Layer):这是LLaVA的核心创新。它是一个简单的、可训练的线性层(或一个小的MLP)。它的唯一作用,是将视觉编码器输出的视觉特征向量,从CLIP的视觉向量空间,**线性投影(转换)**到LLM的词嵌入向量空间。
- LLM:一个开源的LLM(如Vicuna, Llama)。
训练过程(两阶段):
- 第一阶段:特征对齐训练。冻结视觉编码器和LLM,只训练投影层。使用大量的“图像-文本标题”对数据,目标是让投影后的视觉向量,能够让LLM生成对应的文本标题。这一步是为了让投影层学会如何进行“空间翻译”。
- 第二阶段:端到端微调。将投影层也冻结,然后在一个包含复杂的多模态指令对话的数据集上,对LLM本身进行微调。在这一步,LLM学会了如何理解和响应那些包含了视觉Token的、图文并茂的指令。
Java实战中的多模态RAG思考

将LMMs应用于RAG,可以构建出强大的“多模态知识库”。例如,我们可以构建一个“看图说话”的RAG系统。
1 | // Java中构建多模态RAG的概念性流程 |
架构师洞察:
“端到端原生”流派,代表了通往真正统一的多模态模型的方向。它使得LLM能够以一种更底层、更无缝的方式处理视觉信息,理论上能实现更深度的图文融合与推理。LLaVA的成功证明了,通过简单的线性投影和后续的指令微调,就能以相对较低的成本,“唤醒”LLM潜在的多模态能力。
第三部分:前沿的突破——更高分辨率、更长视频与世界的交互
在LLaVA等模型奠定了基础之后,LMMs的研究正在向着更具挑战性的“硬骨头”问题迈进。
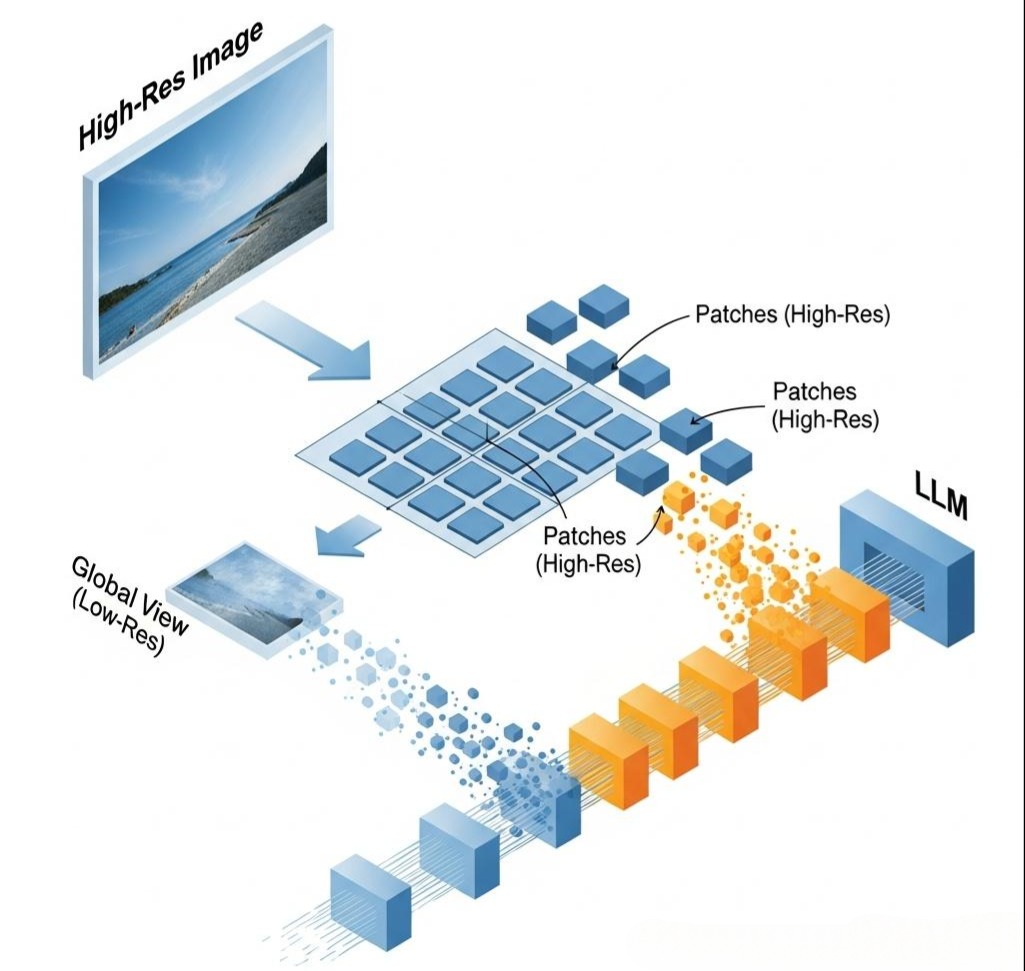
3.1 LLaVA-NeXT:拥抱更高分辨率与更强世界知识
- 核心痛点:早期的LLaVA等模型,为了控制计算成本,通常将输入图像缩放到一个很低的分辨率(如224x224或336x336)。这导致模型无法看清图像中的微小细节(如文档中的小字、远处的物体)。
- LLaVA-NeXT的解决方案:
- 动态高分辨率处理:它借鉴了“切片再拼接”的思想。对于一张高分辨率图像,它首先以低分辨率处理整个图像以获得全局理解,然后将图像切分成多个更高分辨率的“补丁(Patches)”,分别处理这些补丁以捕捉细节,最后将全局和局部的视觉Token一起送入LLM。
- 更强的视觉编码器和LLM:使用了更强大的、经过优化的CLIP变体,以及更强大的LLM基座(如Llama 3的变体)。
- 更丰富的训练数据:在训练中加入了大量的文档、图表、代码截图等数据,显著提升了其在专业领域的“识图”能力。
3.2 Google Gemini & GPT-4V:原生多模态的王者
- 核心区别:与LLaVA等“开源拼接”的路线不同,像Gemini和GPT-4V这样的闭源模型,被认为是**“从零开始原生多模态训练”**的。
- 架构猜想:它们很可能在一个巨大的、交错的图文数据流上进行联合预训练。这意味着,它们的LLM在预训练阶段,就已经见过了大量的视觉Token,视觉和语言的融合是“与生俱来”的,而不是后天“嫁接”的。这使得它们在处理复杂的、需要深度图文交错推理的任务上,表现出压倒性的优势。
3.3 迈向视频与音频:时序维度的扩展

- 视频理解:最直接的方法是将视频视为一系列的图像帧(Frames)。
- 简单方法:均匀采样或关键帧提取,然后将这些帧作为独立的图片送入LMM。缺点是丢失了时序信息。
- 高级方法:修改视觉编码器,使其能够处理一个帧的序列(例如,使用3D CNN或在Transformer中加入时间维度的注意力),从而理解动作和变化。
- 音频理解:
- 传统方法:先使用一个**ASR (Automatic Speech Recognition)**模型(如Whisper)将音频转为文本,再送入LLM。这是目前最成熟、最可靠的方案。
- 原生方法:将音频波形通过一个音频编码器(如Wav2Vec 2.0)转换为“音频Token”,然后像处理视觉Token一样,将其与文本Token一起送入LLM。这使得模型能直接感知到音频中的情感、语调等非文本信息。
结语:从“看图说话”到“感知世界”
在本篇中,我们完成了一次从纯文本到多模态世界的认知跨越。我们不再将AI视为一个只能处理抽象符号的“洞穴囚徒”。
- 我们追溯了CLIP的“创世纪”,理解了它是如何通过对比学习,为视觉和语言两大模态构建了一座统一的“语义之桥”。
- 我们解构了LMM架构演进的两大流派:以BLIP-2为代表的、务实的**“连接主义”,和以LLaVA为代表的、通往未来的“端到端原生”**。
- 我们展望了以LLaVA-NeXT和Gemini为代表的前沿模型,是如何在更高分辨率、更长时序、更多模态的道路上,不断拓展AI“感知”能力的边界。
多模态能力的引入,为我们之前构建的RAG和Agent系统,开启了无限的可能性。我们的RAG可以检索图片和视频,我们的Agent可以看懂UI截图并执行操作。AI正在从一个“语言模型”,真正进化为一个**“世界模型(World Model)”**的雏形。
然而,随着能力的增强,系统的复杂性也在急剧增加。一个包含了多种模型、多种工具、复杂流程的AI应用,其架构该如何设计?如何保证其可靠性、可维护性和可扩展性?
在下一篇章 《从单体到微服务:LLM应用的服务化架构演进之路》 中,我们将把目光重新拉回到宏观的系统工程。我们将探讨,当我们的AI应用从一个简单的“单体脚本”成长为一个复杂的“巨石应用”后,如何借鉴经典的微服务思想,对其进行服务化拆分和架构重构,以应对生产环境对高可用、高并发的严苛要求。这将是一场将AI能力“产品化”的硬核工程实践。


