RAG的终结与Content Engineering的局限:从Claude Code逆向工程视角构建下一代企业级上下文工程实践
引言:RAG的“中年危机”与AI的“记忆困境”
在大型语言模型(LLM)的浪潮之巅,检索增强生成(RAG)无疑是那颗最耀眼的明星。它如同一座桥梁,巧妙地连接了LLM强大的生成能力与外部海量的私有知识,让企业AI应用的落地从“不可能”变成了“触手可及”。我们都曾为它首次准确回答出内部文档问题的那个瞬间而欢呼,仿佛手握开启企业智能化大门的钥匙。
然而,随着蜜月期的结束,我们开始触碰到RAG看似坚固的“天花板”。当对话从三五轮走向数十轮,当问题从“XX是什么”演变为“对比A和B,评估C,并预测D”,我们引以为傲的RAG系统开始显露出疲态,仿佛陷入了一场“中年危机”:
它健忘,反复询问我们早已确认过的事实,像一个只有七秒记忆的数字金鱼。
它混乱,在多个信息源面前手足无措,把A文档的结论张冠李戴到B文档上。
它脆弱,偶尔一次的“幻觉”会像病毒一样污染后续的整个对话,让我们在演示的关键时刻颜面尽失。
我们尝试用更长的上下文窗口、更精巧的滑动策略、更智能的摘要技术来“缝补”这个系统,但收效甚微。这些都只是治标不治本的“止痛药”,因为我们面临的并非简单的技术瓶颈,而是一个深刻的范式困境:我们一直在构建一个“信息检索器”,却期望它能表现得像一个“认知伙伴”。
问题的根源,在于我们对“上下文(Context)”的理解过于肤浅。在主流RAG架构中,上下文是一个扁平的、无序的、混杂着历史对话、检索片段和用户指令的“文本大杂烩”。我们天真地以为,只要把所有东西都塞给LLM,它就能奇迹般地梳理出头绪。
但真正的智能并非如此运作。人类的认知,依赖于一个结构化的、动态的、经过验证的记忆系统。我们能清晰地区分“昨晚确认的事实”、“今天听到的传闻”和“我此刻的目标”。正是这种结构化的记忆,支撑着我们进行复杂的推理和长期的规划。
就在我们为RAG的记忆困境一筹莫展之际,Anthropic的Claude Code如一道闪电划破夜空。表面上,它是一个强大的编程助手,但其背后所蕴含的,是一套我们前所未见的、精密如瑞士钟表的**上下文工程(Context Engineering)**哲学。它不再被动地“管理”上下文,而是主动地“构建”和“塑造”上下文,将其从一滩死水变成了一个生生不息的活体。
本文,将是一次深入Claude Code灵魂的逆向工程之旅。我们将系统性地拆解其设计哲学,然后提炼出一套名为“**认知型RAG”(Cognitive RAG, C-RAG)**的全新架构范式。这不仅仅是一次技术升级,更是一场思维革命。我们将探讨如何为我们的AI系统注入真正的“长期记忆”、严谨的“逻辑推理”和宝贵的“自我修正”能力。
RAG的简单时代或许已经过去,但一个全新的、以“认知”为核心的时代,正当开启。
第一章:主流RAG的阿喀琉斯之踵——四大“原罪”
在批判一个范式之前,我们必须充分理解它的贡献与局限。主流RAG架构,通常由“检索-增强-生成”三步曲构成,其简洁的设计使其得以快速普及。但正是这种简洁,埋下了四大难以根治的“原罪”。
1. 原罪一:上下文的“扁平化”——当所有信息都装在一个篮子里

想象一下,你正在准备一场重要的考试,你把教科书、课堂笔记、模拟试题、同学的闲聊记录……所有东西都撕碎,然后混在一个巨大的麻袋里。每次需要复习时,你就从麻袋里随机抓取一把纸片来阅读。这听起来荒谬,但这正是我们对待LLM的方式。
在典型的RAG流程中,我们构建的Prompt大致如下:
1 | <历史对话> |
在这个“扁平化”的上下文中,LLM面临着巨大的认知挑战:
- 信息等权: “A是B”这个可能经过多轮确认的事实,与“文档2”中一个可能过时的研究观点,在格式上没有任何区别。LLM无法判断哪个信息更可靠。
- 来源混淆: 当多个文档块被注入时,模型很容易混淆信息来源,导致“A文档的数据,B文档的结论”这种典型的张冠李戴式错误。
- 目标模糊: 模型的注意力被大量无关的历史对话和冗余的文档细节稀释,难以聚焦于当前用户的核心意图。
这种将不同性质、不同可信度、不同时效性的信息不加区分地“糊”在一起的做法,是导致RAG系统回答不稳定、逻辑不清晰的根本原因。
2. 原罪二:记忆的“挥发性”——滑动窗口下的数字遗忘症
随着摩尔定律在LLM领域的“暴力”体现,上下文窗口从几千Token飙升至数百万。我们曾以为“无限上下文”将一劳永逸地解决记忆问题。但现实给了我们沉重一击。
首先,成本与延迟是无法逾越的大山。将数百万Token的完整对话历史在每次交互时都提交给API,不仅会带来高昂的费用,还会导致用户无法忍受的响应延迟。
其次,也是更致命的,是**“大海捞针”**问题。Google在Gemini 1.5的技术报告中坦诚,即使在百万级上下文中,模型在信息检索任务中的表现也并非完美,且在长上下文的中间部分容易出现“注意力凹陷”。当上下文过长时,LLM的注意力资源被稀释,关键信息如同沉入海底的针,难以被有效利用。
于是,我们退而求其次,采用了**滑动窗口(Sliding Window)和摘要(Summarization)**作为折中方案。
- 滑动窗口: 简单粗暴地保留最近的K轮对话。这无异于一种制度化的“健忘症”。当对话深入到第K+1轮时,第一轮中可能与用户共同确立的核心目标或关键假设,就被无情地抛弃了。
- 摘要: 调用LLM将旧对话总结成一段话。这看似智能,实则充满了信息损失的风险。一个高度技术性的对话,其摘要很可能丢失关键的术语、代码片段或微妙的逻辑转折。摘要本身也可能引入新的幻觉。
挥发性的记忆,让RAG系统永远无法建立一个稳定、可靠的长期认知基础,注定了它只能是一个“一问一答”的短时工具,而非能够持续协作的伙伴。
3. 原罪三:逻辑的“线性”——无法规划的“单细胞生物”
主流RAG的流程是线性的、僵化的:Query -> Retrieve -> Augment -> Generate。这个流程像一个单细胞生物,只能对外界的刺激做出单一的、固定的反应。
然而,人类解决问题的过程是非线性的、规划性的。面对一个复杂任务,如“对比我们公司Q1和Q2两个季度的销售报告,找出主力产品销售额变化的主要原因,并评估对下季度库存策略的影响”,我们绝不会把两份几百页的报告从头到尾读一遍,然后期望大脑能“灵光一闪”得出答案。
我们会这样做:
- 分解 (Decomposition): 将大问题分解成一系列子问题。
- Task 1: 找出Q1的主力产品及其销售额。
- Task 2: 找出Q2的主力产品及其销售额。
- Task 3: 计算并对比销售额变化。
- Task 4: 结合市场活动、竞品动态等信息,分析变化原因。
- Task 5: 基于原因,提出库存建议。
- 定向执行 (Directed Execution): 针对每个子任务,我们只查找与之相关的特定信息。
- 整合 (Synthesis): 将所有子任务的结论,像拼图一样组合起来,形成最终的、逻辑严谨的答案。
而线性的RAG架构,面对这样的复杂问题时,只会茫然地将“销售报告”、“主力产品”、“库存策略”等关键词扔给向量数据库,抓取一堆相关的但未经组织的文本块,然后把这个“信息炸弹”抛给LLM。结果往往是逻辑混乱、避重就轻、甚至完全偏离主题的答案。
这种“思维上”的懒惰,是RAG无法从“信息搬运工”晋升为“问题解决者”的根本原因。
4. 原罪四:事实的“放任”——零校验下的幻觉放大器
RAG被誉为缓解LLM幻觉的“良药”,因为它为生成提供了事实依据。但这只说对了一半。RAG在抑制“无中生有”型幻觉方面确实有效,但它对更隐蔽的**“扭曲事实”**型幻觉却无能为力,甚至会成为其放大器。
当LLM接触到检索的文档块时,它可能:
- 过度引申: 原文说“A可能导致B”,模型在回答时却简化为“A导致B”。
- 错误组合: 将文档A的因和文档B的果错误地拼接在一起。
- 断章取义: 忽略了原文中关键的限制性条件或背景。
在主流RAG中,我们对LLM的输出是**“照单全收”**的。我们缺乏一个机制,去验证模型生成的每一句话,是否真的被它所引用的原文忠实地支持。
更糟糕的是,当这种经过扭曲的“伪事实”被作为答案返回给用户,并被存入下一轮的“历史对话”中时,**上下文中毒(Context Poisoning)**就发生了。这个“伪事实”会在后续的交互中被反复引用,成为构建更多错误结论的“基石”,导致整个对话的认知框架走向崩溃。
对事实的放任,是悬在所有RAG系统头上的达摩克利斯之剑,让我们的系统始终在“可靠”与“不可靠”的边缘摇摆。
第二章:Claude Code的启示录——上下文工程的四根支柱
面对上述四大“原罪”,我们需要的不是更好的“膏药”,而是一场彻底的“外科手术”。Claude Code的逆向工程分析,为我们揭示了这场手术的四项核心原则,它们共同构成了其上下文工程的坚固支柱。
支柱一:结构化记忆核心 (Contextual Memory Core)——为AI构建一个“海马体”

Claude Code的第一项革命,就是彻底抛弃了“扁平化”的上下文。它的上下文不是一个字符串,而是一个结构化的、多模块的对象,我们可以称之为“上下文记忆核心”(CMC)。
根据逆向分析,这个CMC至少包含以下几个功能区:
- 身份与指令区 (Profile & Directives): 存储系统角色、行为准则、可用工具等静态但至关重要的信息。这确保了AI在任何时候都不会“迷失自我”。
- 事实账本 (Fact Ledger): 这是皇冠上的明珠。它是一个只存放经过验证的事实的数据库。任何信息,只有在经过严格的内部校验、确认其有可靠来源支持后,才有资格进入这个“账本”。这从根本上解决了信息等权和来源混淆的问题,为所有后续推理提供了坚实的、不可动摇的地基。
- 会话摘要 (Session Summary): 它不是简单的流水账,而是由专门的压缩模型生成的、包含用户意图演变、关键决策点、待办任务的结构化“会议纪要”。这为长对话提供了高信息密度的叙事背景。
- 工作台 (Working Bench): 一个用于处理当前回合所有临时信息的“沙盒”。用户的新问题、本轮检索到的文档块、模型的初步想法,都先放在这里。这里的信息是“未经证实的”,只有经过处理和验证,其精华才会被提炼并“晋升”到事实账本或会话摘要中。
启示: 上下文不应是输入的堆砌,而应是内部状态的反映。通过构建一个结构化的CMC,我们让AI拥有了区分事实、假设、指令和瞬时信息的能力,这是迈向真正认知的第一步。
支柱二:事件驱动的上下文编排器 (Event-Driven Context Orchestrator)——AI的“中枢神经系统”

Claude Code的第二项革命,是用事件驱动的状态机取代了线性的处理流程。用户的每一个动作(输入、点击)、系统的每一次操作(工具调用、文件读写)、甚至内部状态的变化(内存压力),都会触发一个“事件”。
一个中央“编排器”负责监听这些事件,并根据当前的状态,动态地决定下一步该做什么,以及如何为下一步操作“量身定制”上下文。
一个简化的交互流程对比:
- 传统RAG (线性):
- 收到用户问题。
- 固定执行:检索文档 -> 组合Prompt -> 生成答案。
- 无论问题是什么,流程一成不变。
- Claude Code (事件驱动):
EVENT: USER_INPUT_RECEIVED->STATE: ANALYZING_QUERY。- 编排器分析查询,发现信息冲突 ->
EVENT: CONFLICT_DETECTED->STATE: REQUESTING_CLARIFICATION。 - 编排器构建一个用于“提问澄清”的Prompt,而不是“回答问题”的Prompt。
EVENT: USER_CLARIFICATION_RECEIVED->STATE: RESUMING_SYNTHESIS。- 编排器根据用户的澄清,重新组织资料,继续生成答案。
启示: 智能不应是僵化的流程,而应是动态的响应。通过引入事件驱动的编排器,我们让AI系统从一个只会走直线的“机器人”,变成了一个能够根据环境变化和内部状态,灵活调整自身行为的“有机体”。
支柱三:分层Agent任务分解器 (Hierarchical Agent Task Decomposer)——赋予AI“额叶皮层”
面对复杂问题,Claude Code的第三项革命是引入了分层Agent协作的模式,这与人类大脑的额叶皮层功能高度相似,负责规划、决策和协调。
其核心是“分治-合成”(Divide-and-Conquer-and-Synthesize)的思想:
- 调度员Agent (Dispatcher): 接收用户的复杂请求。它的唯一工作不是回答问题,而是分析问题并制定一个详细的、有依赖关系的子任务计划。
- 专家Agent (Specialist): 调度员根据计划,为每个子任务动态地创建临时的、轻量级的专家Agent。最关键的是,每个专家Agent都在一个完全隔离的上下文中运行。它只能访问与自己任务严格相关的、最少必要的信息。这从根本上杜绝了信息交叉污染。
- 合成器Agent (Synthesizer): 当所有专家Agent完成任务后,一个专门的“合成器Agent”被激活。它的任务是阅读所有专家的结构化输出,解决它们之间的细微冲突,并根据用户的最终目标,将这些独立的“知识积木”整合
成一篇逻辑连贯、结构完整的最终报告。
启示: 复杂性不应被硬扛,而应被优雅地化解。通过引入任务分解和分层Agent协作,我们为AI系统安装了一个“规划大脑”,使其能够将无法一口吞下的“巨象”,分解成可以轻松咀嚼的“肉块”,从而极大地提升了处理复杂分析和推理任务的能力。
支柱四:事实校验与校正循环 (Fact-Checking & Correction Loop)——AI的“免疫系统”
Claude Code的第四项,也是最能体现其严谨性的革命,是建立了一个严格的、闭环的“事实校验与校正”机制。
这个机制贯穿于系统的每一次信息生成过程:
- 生成并引用 (Generate with Citation): 通过指令约束,强制模型在生成任何事实性陈述时,必须附带一个指向其信息来源(如特定文档的特定片段)的精确引用。
- 自动化验证 (Automated Verification): 在将答案呈现给用户之前,一个内部的“校验器”模块会自动启动。它会逐一检查每一条带引用的陈述,并程序化地(例如通过调用NLI模型)判断该陈述是否被其引用的原文忠实地支持(Entailment)。
- 校正与巩固 (Correction & Consolidation):
- 如果验证结果是**“支持”**,该陈述就被认为是可靠的。这个经过验证的陈述,现在有资格被提炼成一个“事实”,并被写入“事实账本”,完成一次记忆的巩固。
- 如果验证结果是**“矛盾”或“中立”,系统会进入一个校正循环:或者要求模型基于原文重写,或者直接向用户坦诚信息的模糊性。**
- 这个闭环确保了只有经过验证的、高质量的信息才能进入系统的长期记忆库。
启示: 可靠性不应是期望,而应是设计。通过建立一个严格的校验与校正循环,我们为AI系统构建了一个强大的“免疫系统”。它能主动识别并剔除“幻觉”和“伪事实”这些有害的“病原体”,确保了系统知识体系的纯净和健康,并使其能够随着时间的推移,通过不断的学习和验证,变得越来越可靠。
第三章:构建认知型RAG(C-RAG)——可落地的工程蓝图
现在,基于前两章的内容我们对Claude Code的先进思想有了大致的了解,是时候将这些思想转化为一个具体、可实施的架构蓝图了。我们称之为认知型RAG(Cognitive RAG, C-RAG)。这不仅是一个技术方案,更是一个全新的产品哲学。
C-RAG架构总览
C-RAG的核心,是一个以**“上下文记忆核心”(CMC)为中心,由“事件驱动编排器”调度的,包含“分层Agent任务分解器”和“事实校验循环”**的闭环智能系统。
本章将详细阐述C-RAG架构的四大核心组件,并通过清晰的数据结构定义和工作流图解,展示这个“认知系统”的每一个齿轮是如何精密啮合的。
组件一: 放弃过去那种将所有信息混为一谈的“流水账”式上下文,为每个用户会话建立一个结构化、可长期维护的“认知大脑”。它由三部分组成:事实账本、会话摘要
目标: 放弃过去那种将所有信息混为一谈的“流水账”式上下文,为每个用户会话建立一个结构化、可长期维护的“认知大脑”。它的组主要有三部分组成:身份指令、事实账本、会话摘要
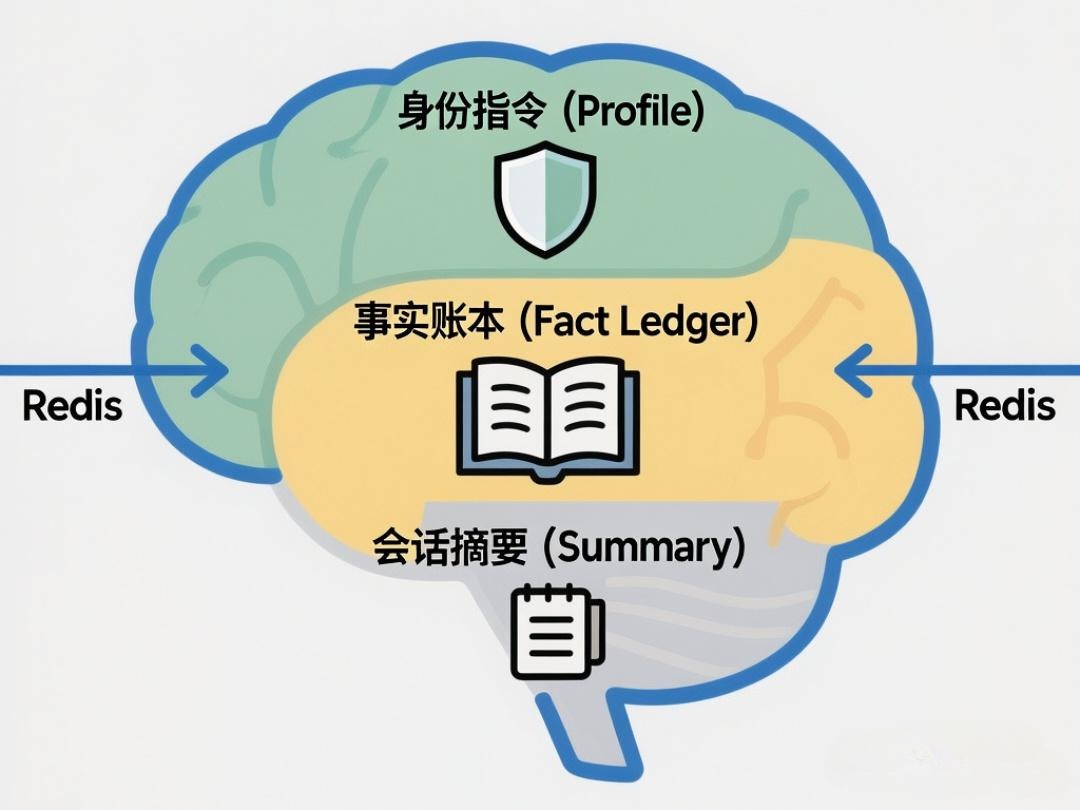
技术实现:
这个“大脑”在技术上是一个可序列化的对象(例如,一个Java/Python类实例),并以JSON格式持久化到Redis中。你的服务端在处理每个用户请求时,都必须先从Redis加载这个对象到内存,并在处理结束后将更新后的对象写回Redis。
CMC对象的核心字段详解 (JSON结构定义):
1 | // Redis Key: "session:<session_id>" |
关联第四章:
session_summary和fact_ledger则是**Prompt 1(任务分类)和Prompt 2(复杂任务分解)**的关键输入。
session_summary摘要来源:后台任务实现,见上述Json注释
fact_ledger事实来源:后续组件四校验后数据,见上述Json注释
组件二:事件驱动编排器 - 系统的中枢神经
目标: 将你的服务端程序,或者说Agent从一个只会“一条路走到黑”的线性管道,升级为一个能根据情况做出不同反应的“智能调度中心”。
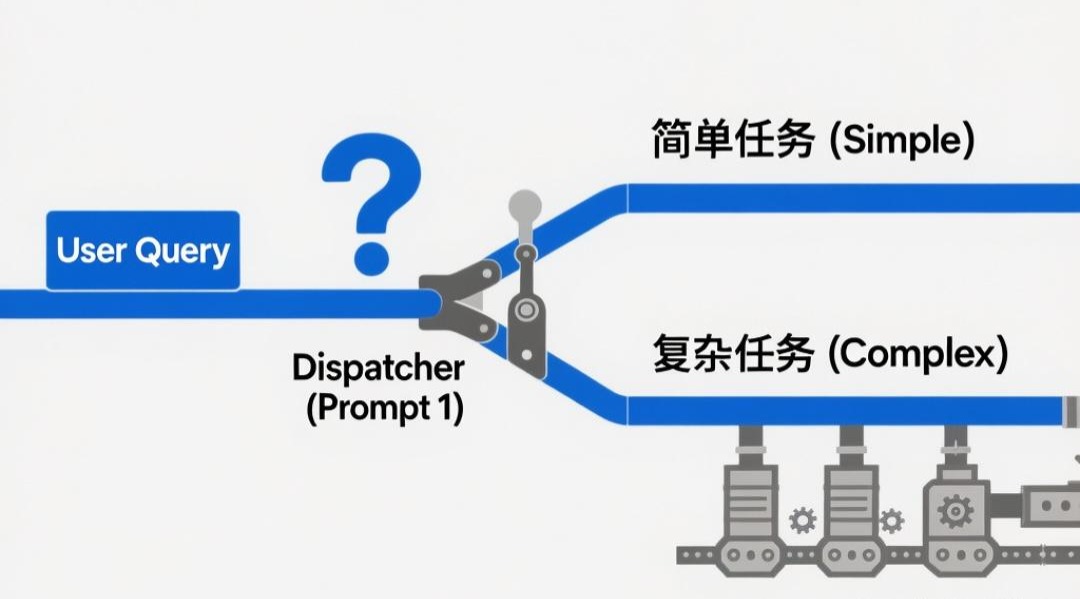
技术实现:
在服务端代码中中实现一个主控流程,该流程的核心是一个状态机。
接收用户请求,结合CMS核心中的session_summary摘要数据内部决策(调用章节四的Prompt 1(任务分类))的结果,进行任务分类(SIMPLE/COMPLEX)。
这个编排器是整个系统的“大脑皮层”,负责接收信息、做出判断并指挥后续行动,它的核心决策依据来源于第四章的Prompt 1。
组件三:分层Agent执行器 - 系统的专家团队
目标: 优雅地处理那些需要多步骤、多角度分析的复杂问题,避免将“信息炸弹”直接丢给LLM。

技术实现:
- 如果是“简单任务流水线”,则直接根据问题Embedding进行向量库事实文档检索,生成草稿后交由【组件四】处理。
- 而“复杂任务流水线”的核心,则是由一系列相互协作的模块构成,其行为由第四章的Prompt 2、Prompt 3和Prompt 4精确指导。
“复杂任务流水线”工作流图解:
- [任务分解模块: Decomposer]
- 触发: 编排器决策为
COMPLEX后启动。 - 动作: 调用主LLM,使用Prompt 2 (任务分解Prompt)。
- 输入:
user_query: 用户的复杂问题。CMC.fact_ledger: 当前已知的全部事实,帮助LLM避免规划重复任务。- 输出: 一个结构化的
planJSON对象,包含带有依赖关系的sub_tasks列表。
1 | { "sub_tasks": [ |
- [任务执行引擎: Executor]
- 触发: 接收到
plan后启动。 - 动作: 这是一个循环调度器,它遍历
sub_tasks列表,并根据dependencies决定执行顺序。它会维护一个临时的completed_tasksMap,用于存放已完成子任务的结果。对于每一个待执行的子任务,它会: - 对于
dependencies为空的任务 (数据提取类): - 输入:
sub_task.description: (string) 子任务描述,如“查找特斯拉Q1财报的销售额”。- 执行流程:
- 将
sub_task.description作为query,执行常规RAG流程:对query进行Embedding,然后检索Milvus向量库,获取相关的原始文档片段retrieved_docs。 - 调用主LLM,使用Prompt 3 (可验证生成Prompt)。此时,Prompt 3的
<newly_retrieved_documents>部分被填入retrieved_docs。 - 输出:
task_result: (string) 一个带引用的陈述句,如"特斯拉2023年Q1的总收入为233亿美元。[cite: doc, TSLA_Q1_23.pdf, 4]"。将该
task_result存入completed_tasksMap,键为任务ID (e.g.,{1: "..."})对于
dependencies不为空的任务 (数据加工/分析类):输入:
sub_task.description: (string) 子任务描述,如“对比Q1和Q2的销售额”。dependent_results: (list of strings) 从completed_tasksMap中获取的所有前置任务的结果。执行流程:
- 不访问Milvus向量库,因为所需信息已在前置任务结果中。
- 调用主LLM,同样使用Prompt 3 (可验证生成Prompt)。此时,Prompt 3的
<established_facts>部分被填入dependent_results(这些结果被视为当前步骤可信赖的“事实”)。 - 输出:
task_result: (string) 一个基于输入进行分析后、带引用的新陈述,如"对比两个季度,Q2收入高于Q1。[cite: fact, task_1_result, null][cite: fact, task_2_result, null]"。- 将新结果也存入
completed_tasksMap。
- [最终合成模块: Synthesizer]
- 触发: 所有子任务执行完毕后。
- 动作: 调用主LLM,使用Prompt 4 (最终合成Prompt)。
- 输入:
completed_tasks: (Map) 包含所有子任务ID、描述和结果的完整集合。original_complex_query: 用户的原始复杂问题。- 输出:
final_draft_answer(一份逻辑连贯、带引用的最终报告草稿)。
- [转交]
- 将
final_draft_answer转交给**【组件四:事实校验与记忆循环】**进行最终的审查与记忆。
组件四:事实校验与记忆循环 - 系统的免疫与成长系统
目标: 确保系统输出的每一条信息的可靠性,并实现知识的持续、准确积累。这是将系统从“概率性”变为“确定性”的关键。
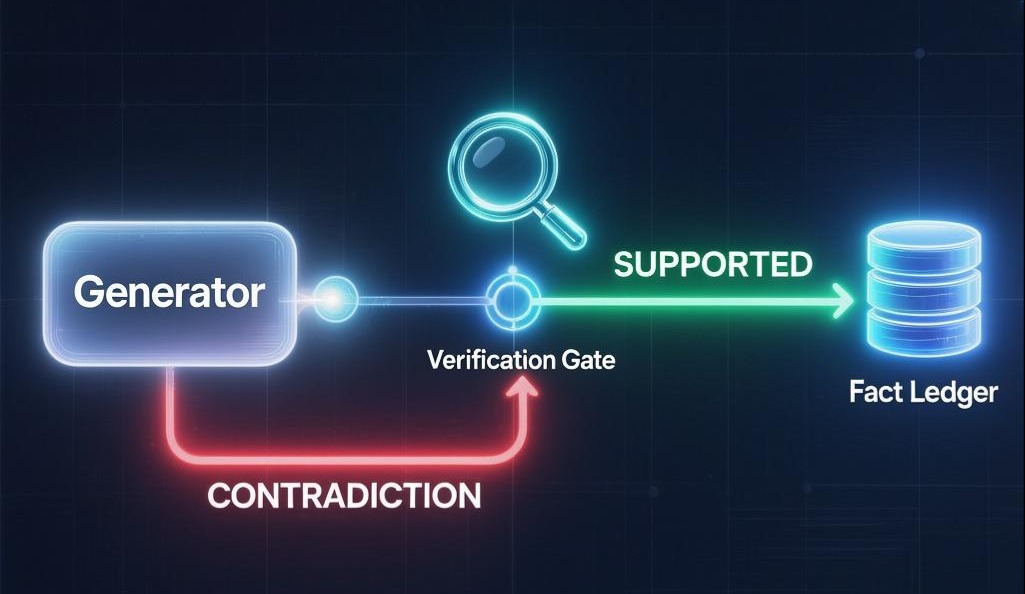
技术实现:
这是所有流水线(无论简单还是复杂)的最后一步,也是一个独立于LLM对话能力的、偏向程序化的质量保证模块。它的行为由第四章的Prompt 3中强制输出的引用格式所驱动。
“校验与记忆”流程图解:
- [输入]
draft_answer: (string) 任何一个生成模块产出的带引用的答案草稿(例如,来自简单任务的直接生成,或来自复杂任务的final_draft_answer)。
- [校验模块: Verifier]
- 动作:
a. 解析: 服务端程序用正则表达式解析出草稿中的所有[陈述, 引用]对。
b. 溯源: 根据“引用”信息(例如[cite: doc, TSLA_Q3_23.pdf, 8]或[cite: fact, fact-uuid-001, null]),找到对应的“原文”(可能来自Milvus的文档块,或来自CMC.fact_ledger)。
c. 验证: 调用一个验证函数verify(statement, original_text)。此函数内部可调用独立的NLI(自然语言推断)模型,或使用LLM自身进行验证,例如向LLM发送如下请求:text
<背景原文> </背景原文> <待验证陈述> </待验证陈述> <指令> 背景原文是否支持待验证陈述?请只回答 “支持”、”矛盾” 或 “无关”。 </指令>
- 输出: 一个验证结果列表,如
[{statement: "...", source_ref: "...", status: "SUPPORTED"}, ...]。
- [记忆模块: Memorizer]
- 动作:
a. 遍历验证结果列表。
b. 对于每一个status为"SUPPORTED"且在CMC.fact_ledger中尚不存在的新陈述,将其转换成一个标准的Fact JSON对象(如组件一中定义的结构),并赋予一个新的唯一ID。
c. 将这些新的Fact对象写入到内存中的CMC.fact_ledger里。
- [最终响应与持久化]
- 响应: 服务端程序根据
Verifier的验证结果,对draft_answer进行清理和格式化(例如,只保留被"SUPPORTED"的句子,并美化引用格式),形成最终的final_answer,发送给前端。 - 持久化: 服务端程序将更新后的整个CMC对象(现已包含新记忆的事实)序列化为JSON,并写回Redis。这个写回操作,正式完成了“记忆循环”的闭环。它确保了本次交互中经过验证的新知识,能够被下一次用户提问时所用,从而实现系统的持续学习和成长。
通过这四大组件的精密协作,C-RAG系统将一个简单的用户问题,转化为了一次严谨、可靠、且能促进系统成长的智能交互。下一章,我们将深入探讨驱动这一切的核心——Prompt工程的设计细节。
第四章:C-RAG的灵魂——精确制导的Prompt工程
如果说C-RAG的四大组件是系统的骨架和器官,那么本章要介绍的Prompt工程就是流淌其中的血液和神经信号。正是这些精心设计的、面向不同任务的“沟通协议”,才使得各个智能模块能够准确无误地执行其特定职责。
本章将详细呈现四个核心LLM调用场景的完整Prompt模板,并提供极其详尽的字段注释,以揭示其背后的设计思想。

Prompt 1: 调度员决策Prompt (Dispatcher Prompt)
目标:
这是整个流程的第一个、也是最关键的决策点。它的任务不是回答问题,而是对用户请求的性质进行快速、准确的分类,判断它是“简单查询”还是“复杂分析”。这个决策将决定系统接下来走哪条完全不同的处理流水线。
调用时机:
在你的服务端程序接收到用户请求,并加载完CMC(上下文记忆核心)之后立即调用。
使用的LLM:
推荐使用快速、廉价的小型模型,因为这个任务对推理深度要求不高,但对响应速度要求很高。
完整Prompt模板:
1 | <!-- |
Prompt 2: 任务分解Prompt (Decomposition Prompt)
目标:
当一个任务被调度员判定为COMPLEX后,这个Prompt被用来将这个宏大、模糊的用户请求,转化为一个结构化的、计算机可以理解和执行的、带有依赖关系的任务计划。LLM在此处扮演的是“项目经理”的角色。
调用时机:
在调度员决策返回"COMPLEX"之后,由服务端程序中的任务分解模块调用。
使用的LLM:
推荐使用能力较强的主力模型,因为任务分解需要较强的逻辑推理和规划能力。
完整Prompt模板:
1 | <!-- |
Prompt 3: 可验证生成Prompt (Verifiable Generation Prompt)
目标:
这是所有答案生成环节(无论是SIMPLE任务的直接生成,还是COMPLEX任务的子任务生成)的核心Prompt。它的目标是约束LLM的输出,使其不仅仅是生成一个答案,而是生成一个“可被程序验证的”答案草稿。
调用时机:
在信息收集完成之后,准备调用LLM生成最终内容时。
使用的LLM:
必须使用能力最强的主力模型,因为它需要同时处理信息整合、内容生成和遵循复杂格式指令的能力。
完整Prompt模板:
1 | <!-- |
Prompt 4: 最终合成Prompt (Final Synthesis Prompt)
目标:
在COMPLEX任务的所有子任务都执行完毕后,这个Prompt负责将所有经过验证的、结构化的中间成果,整合成一篇逻辑连贯、行文流畅的最终报告。LLM在此处扮演的是“总编辑”的角色。
调用时机:COMPLEX流程的最后一步,在所有子任务结果都收集齐之后。
使用的LLM:
同样需要使用能力最强的主力模型,因为它需要优秀的篇章组织和语言润色能力。
完整Prompt模板:
1 | <!-- |
通过这套精心设计的Prompt矩阵,我们为C-RAG系统的每一个智能模块都提供了清晰的“操作手册”,确保了整个复杂流程能够稳定、可靠、高效地运行。
总结: 将一切串联起来
现在,我们可以清晰地看到,C-RAG系统是如何通过这四大组件的协同工作,将一个简单的用户问题,转化为一次严谨、可靠、且能促进系统成长的智能交互:
- CMC 提供了稳定、结构化的大脑。
- 编排器 扮演了灵活的中枢神经,决定了思考的路径。
- 分层Agent执行器 组建了一支专家团队,以应对最艰巨的挑战。
- 校验与记忆循环 则是这个大脑的免疫系统和学习机制,确保其健康和持续成长。
这个蓝图虽然比传统RAG复杂,但它用架构的严谨性,换取了系统在可靠性、智能度、和长期价值上的指数级提升。

