RAG篇(1):RAG的星辰大海——从朴素检索到Agentic范式,重构企业级RAG的七层架构
导语:AI深水区的第一个“硬骨头”——连接悖论
我们将以“系统架构师”的视角,对检索增强生成(RAG)进行一次“法医级”的解剖。我们将从信息论的哲学高度出发,重新审视RAG的本质;
我们将站在传统信息检索(IR)巨人的肩膀上,看清向量检索的“理论贫困”;
我们将系统性地追踪RAG从朴素、高级、模块化到智能体(Agentic)的四次关键架构演进,并最终提出一个用于指导工业级实践的“七层RAG架构模型”。
这不只是一份技术指南,更是一场穿越AI“连接悖论”的思想探险,它将为你构建一个全景式的认知地图,让你看清RAG的过去、现在,并预见它的未来。
先让我们从一个你或许无比熟悉的场景开始:
你,或者你团队里那个最顶尖的工程师,刚刚完成了一次令人惊叹的技术壮举。你们废寝忘食,终于将公司最新的、拥有千亿参数的大语言模型(LLM)成功部署上线。在演示会上,它对答如流,引经据典,面对各种刁钻问题都展现出惊人的“智力”,赢得了满堂喝彩。老板拍着你的肩膀,眼中闪烁着对“AI赋能业务”的无限憧憬。
然而,当最初的兴奋褪去,庆功的香槟泡沫消散,一个幽灵般的问题开始在生产环境中萦绕:
当销售团队问起“上个季度A产品的核心优势和客户反馈总结”时,这个“天才大脑”却引用了半年前的过时数据,甚至编造了几个不存在的客户案例。
当法务部门需要它“基于公司最新的合规条例,审查这份合同的风险”时,它对新条例一无所知,依旧在使用旧的法律条款进行分析。
当客服机器人接入这个模型后,面对用户的具体订单问题,它只会一遍遍地重复“作为一个AI模型,我无法访问您的个人订单信息…”
那一刻,一种深刻的荒诞感涌上心头。我们斥巨资、耗费无数算力打造的“超级大脑”,在企业最核心、最有价值的私有知识面前,竟然像一个患了失忆症的博学教授——它知道宇宙的起源,却不认识自己家门钥匙。
我们陷入了AI工程的第一个,也是最根本的**“连接悖论”**:我们拥有了史上最强大的“推理引擎”(LLM),却无法为它提供最关键的“燃料”(企业私有数据)。微调?对于每天都在产生的海量动态数据,无异于想用一根小水管填满整个太平洋,成本高昂且响应迟缓。
我们手中的“神火”,无法照亮我们自己的洞穴。这个残酷的现实,是每一个试图将AI从Demo推向产品的团队都必须跨越的“死亡谷”。
检索增强生成(RAG),正是在这片“死亡谷”中升起的第一缕曙光。它的思想朴素到近乎野蛮:不懂?就去查! 在LLM生成答案之前,先从外部知识库中检索相关信息,注入其上下文。
然而,也正因其思想的朴素,99%的RAG实践,都只是用几行样板代码,搭建了一个看似能跑通的“玩具”。这种“玩具”在真实、复杂的业务冲击下,脆弱得不堪一击。
所以,本篇开始了。准备好了吗?这场穿越AI“连接悖论”的征途,现在开始。
1. 理论寻根:站在信息论与IR巨人的肩膀上
在解剖RAG的具体形态之前,我们必须先回答一个根本问题:RAG到底是什么?从更高的视角看,它在信息世界中扮演了什么角色?
1.1 RAG的哲学本质:一种信道压缩与信源编码
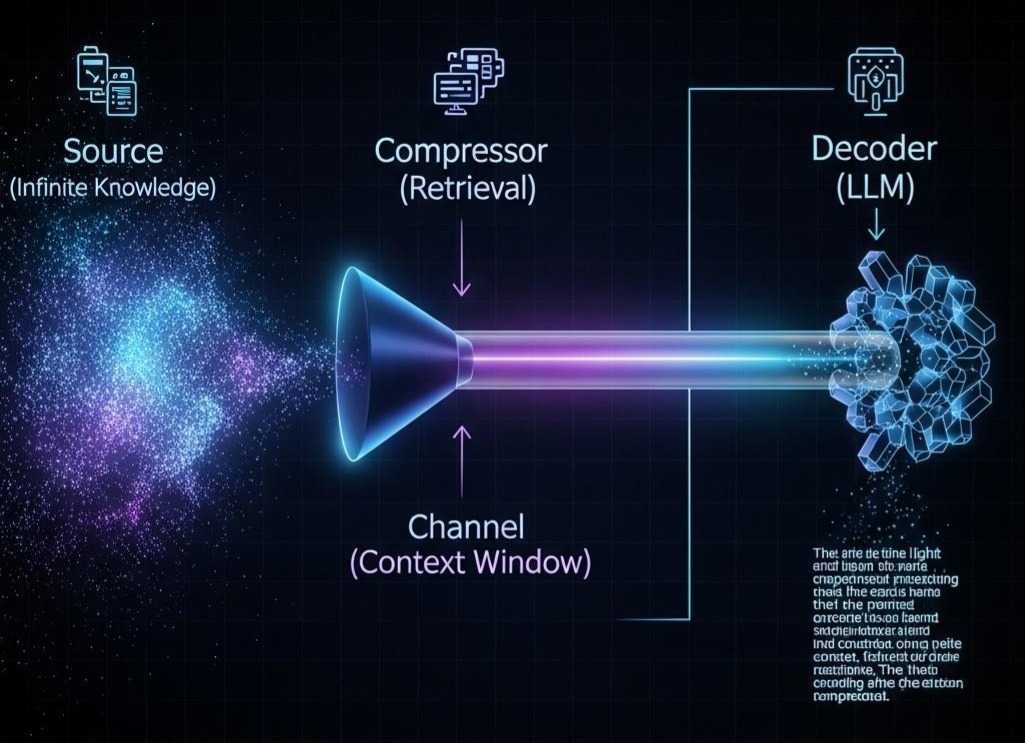
让我们站在信息论的视角。一个LLM,本质上是一个强大的解码器,它能将输入的Token序列(信宿)解码为人类可理解的、逻辑自洽的自然语言。然而,它的“信道容量”是有限的——这个信道就是它的上下文窗口(Context Window)。我们不可能将整个互联网或整个企业知识库这个无穷的“信源”一次性塞进这个有限的信道。
RAG的核心本质,就是一套“信源编码”和“信道压缩”的工程体系。
- 检索(Retrieval):这个过程扮演了**“有损压缩器”**的角色。它面对的是浩如烟海的“信源”(你的知识库),任务是根据用户的查询(Query),将最可能相关的信息从信源中“压缩”出来,形成一个极度浓缩的信息包(检索到的上下文)。这个压缩过程必然是有损的,因为我们丢弃了大量不相关或次相关的信息。
- 生成(Generation):这个过程则是**“信源解码器”**。LLM接收到这个被高度压缩过的信息包(上下文),并结合原始查询,将其“解码”成一份最终的、流畅连贯的答案。
从这个角度看,RAG系统的所有优化,无非是在围绕两件事做文章:
- 提升压缩算法的效率与精度:如何确保我们的“压缩器”(检索模块)在丢弃大量信息的同时,能最大概率地保留对解码最重要的那部分?这就是检索质量优化的核心。
- 优化编码格式以适配解码器:如何将压缩后的信息包(上下文)组织成一种“编码格式”,让“解码器”(LLM)最容易理解、最不容易误读?这就是上下文工程的核心。
这个信息论的类比,为我们提供了一个评判所有RAG技术的“黄金标准”:它是否有助于更精准地压缩信源,或者它是否让解码器的解码过程更高效?
1.2 站在巨人肩膀上:RAG与经典信息检索(IR)
当我们谈论检索时,尤其是在向量检索大行其道的今天,我们很容易忘记,信息检索(IR)是一个有着数十年历史的成熟领域。朴素RAG最大的问题之一,恰恰是它在理论上的“返祖”现象——它过于迷信“几何距离”,而忽视了经典IR的“概率思想”。
让我们回到那个奠定了现代搜索引擎基础的理论——Robertson/Spärck Jones的概率检索模型。其核心思想并非“A和B在空间中有多近”,而是:
“估算一个文档与一个给定查询相关的概率有多大?”
这个思想催生了像BM25这样的传奇算法。BM25不关心向量,它关心的是词频(TF)、逆文档频率(IDF)和文档长度。它背后是对词语信息量、文档主题区分度的深刻洞察。
相比之下,朴素RAG的“向量相似度检索”显得有些“理论贫困”。它假设“语义相似”等同于“空间邻近”,这在很多情况下是成立的,但也带来了诸多问题:
- 它无法解释“为什么”相关:向量相似度是一个黑盒的数值,而BM25的得分却可以被拆解,我们能清晰地看到是哪个关键词起到了决定性作用。
- 它对关键词的“精确匹配”无能为力:当用户需要查找一个特定的、罕见的术语或产品型号时,基于概率和统计的关键词检索往往比模糊的语义向量更可靠。
这并不是要否定向量检索,而是要强调:一个成熟的RAG系统,必须站在经典IR的巨人肩膀上。它应该将概率检索的思想(如BM25)与连接主义的表示能力(向量)结合起来,而不是用后者简单地替代前者。我们将在后续的“高级RAG”部分看到,这种融合思想正是RAG进化的关键驱动力。
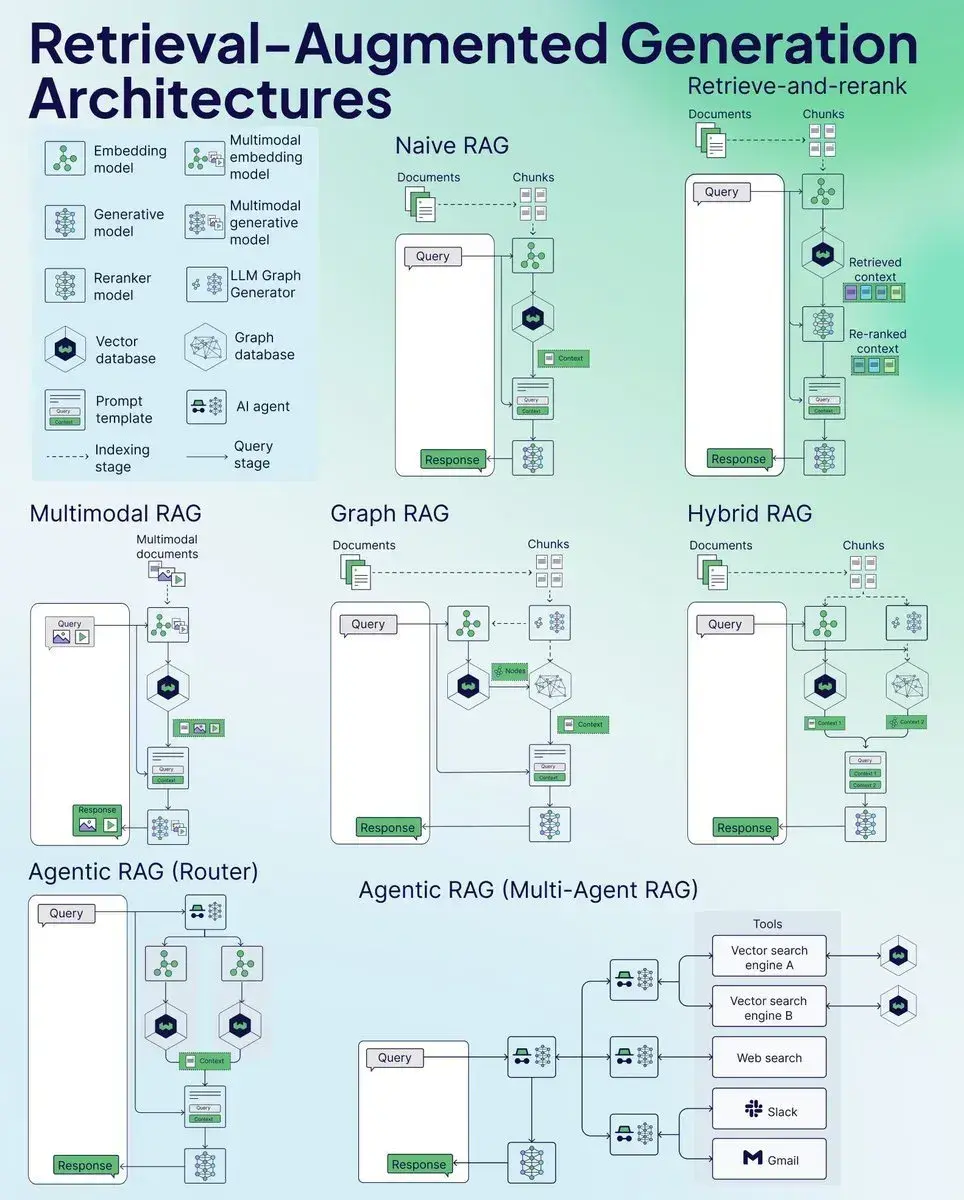
2. 初始范式——朴素RAG(Naive RAG)及其三大原罪
有了理论的铺垫,我们再来看RAG最原始的形态——朴素RAG。它是RAG概念的最直接实现,其工作流是一个僵化的、线性的三阶段过程:索引、检索、生成。

- 索引 (Indexing):将文档集合分割为独立的文本块(Chunks),通过编码模型计算每个文本块的向量嵌入,并存储于向量数据库中。
- 检索 (Retrieval):接收用户查询,计算其向量嵌入,并在向量数据库中执行相似度搜索,召回Top-K个最相似的文本块。
- 生成 (Generation):将用户查询与检索到的文本块粗暴地拼接,形成一个统一的上下文(Context),并提交给LLM以生成最终答案。
无论是在Python的LangChain,还是在Java的Spring AI中,几行代码就能构建这样一个原型,这散发着一种“致命的诱惑”,让开发者误以为已经掌握了RAG的精髓。
Python - LangChain 示例
1 | # Python LangChain 示例 |
Java - Spring AI 示例
1 | // Java Spring AI 示例 |
然而,当真实、复杂的业务问题涌入时,其架构的内在缺陷便暴露无遗。朴素RAG从诞生之日起,就背负着三大难以饶恕的**“原罪”**。
原罪一:检索质量的脆弱性
如前所述,它过度依赖“向量相似度”等同于“语义相关性”这一脆弱假设。
- 语义鸿沟:用户的查询用词与文档中的表述可能存在巨大差异(例如,用户问“公司挣钱能力怎么样?”,文档中为“本季度净利润率同比提升5%”),导致基于表层向量相似度的检索彻底失败。
- 查询的抽象性:对于需要综合多个信息源才能回答的抽象问题(例如,“分析公司的主要风险”),单一的向量检索难以召回所有必需的、分散在不同文档中的证据。
- 忽略关键词:对于产品ID、错误码、法律条款编号等需要精确匹配的场景,语义模糊的向量检索就是一场灾难。
原罪二:上下文处理的浪费性
将检索到的文本块直接拼接,是对LLM宝贵的上下文窗口和注意力的一种野蛮浪费。
- 注意力黑洞(Lost in the Middle):大量研究表明,LLM在处理长上下文时,对处于中间位置的信息存在显著的“注意力衰减”。直接拼接,无异于将关键信息随机扔进一个可能被忽略的“黑洞”。
- 上下文噪声污染:不相关或低质量的检索结果会“污染”上下文,像噪声一样干扰LLM的判断,甚至引发基于错误信息的“次生幻觉”。
- 信息冗余与稀释:多个文本块可能包含大量重复信息,这不仅降低了上下文的“信噪比”,也无谓地挤占了有限且昂贵的上下文窗口。
原罪三:生成过程的不可控性
该范式对LLM的生成行为几乎没有任何有效的约束和引导。
- 信息冲突下的“薛定谔”:当检索到的不同文本块包含相互矛盾的信息时,LLM缺乏明确的指令来解决冲突,其选择行为变得不可预测,如同“薛定谔的猫”,结果难以预料。
- 知识边界的混淆:若检索的上下文中不包含答案,朴素RAG下的LLM有很大概率会退回到其内部的参数化知识进行“自由创作”(即幻觉),而不是诚实地返回“根据已有信息无法回答”,这完全违背了RAG抑制幻觉的初衷。
- 答案的可追溯性缺失(No Citation):生成的答案与其所依据的源文档段落之间缺乏明确的关联,这在需要高可审计性、高可靠性的企业应用(如金融、法务、医疗)中是致命缺陷。
架构师箴言:朴素RAG是一个功能性的基线(Functional Baseline),其唯一价值在于提供一个低成本的、用于验证想法的端到端环境。任何将其直接部署于生产的决策,都是在为未来埋下技术债的深坑,必将导致后期高昂到无法承受的维护与优化成本。
3. 增量优化——高级RAG(Advanced RAG)的“补丁”哲学
为克服朴素RAG的原罪,社区和业界发展出了一系列在核心工作流前后进行“预处理”和“后处理”的工程策略,我们称之为高级RAG。这一阶段的演进,标志着从业者从简单的“黑盒调用”向精细化的“流程干预”转变,如同在一个漏水的管道上,精准地打上各种“补丁”。
3.1 检索前优化:打磨“问题”本身
核心思路是:与其直接用用户的原始输入去检索,不如先“打磨”一下这个输入,让它成为更锋利的“探针”。
- 查询扩展 (Query Expansion):将一个单一查询扩展为一组语义相近或相关的子查询,进行多路并行检索后合并结果。例如,将“RAG性能优化”扩展为“如何提升RAG检索准确率”、“RAG上下文压缩技巧”、“RAG评估指标”等。此举以增加计算开销为代价,换取更高的召回率。
- 查询转换 (Query Transformation):利用LLM的理解能力对查询进行重写,以弥合查询与文档之间的语义鸿沟。最著名的例子是HyDE(Hypothetical Document Embeddings),它让LLM先根据原始问题“凭空”生成一个假设性的、完美的答案,再用这个假答案的向量去检索。因为“答案”的语言形态和措辞风格,天然地比“问题”更接近知识库中的文档段落。
3.2 检索后优化:净化注入LLM的“燃料”
核心思路是:在将检索结果送入LLM这个“昂贵的引擎”之前,对其进行严格的筛选、排序和浓缩,确保每一滴“燃料”都是高纯度的。
- 重排序 (Re-ranking):这是一种经典的“粗筛-精排”两阶段策略。
召回(Recall):首先,使用计算高效但精度较低的方法(如向量相似度或BM25)从海量文档中快速召回一个较大的候选集(例如Top-50)。
精排(Re-rank):然后,使用计算密集但精度极高的模型(如交叉编码器Cross-encoder)对这个小得多的候选集进行重新排序。Cross-encoder会把查询和每个文档拼接起来,让模型进行更深度的相关性判断。最终,我们只取精排后的Top-K(如Top-3)结果。此策略能以可控的延迟增加,换来精确率的巨大提升。
- 结果融合 (Fusion):当采用多种检索方法时(例如,同时进行向量检索和BM25关键词检索),需要一个机制来合并不同的结果列表。**倒数排序融合(Reciprocal Rank Fusion, RRF)**算法提供了一种无需调参的、出奇有效的优雅方法。它不关心每个检索器的原始得分,只关心文档在不同结果列表中的“排名”。一个文档在多个列表中都排名靠前,其最终得分就会很高。
架构师箴言:高级RAG的各项策略,本质上是在一个固定的线性工作流中,通过增加“插件”模块来弥补核心算法的不足。这些策略行之有效,但也导致了系统复杂度的线性增长。每个新增模块都带来了新的延迟、成本和配置开销。这种“打补丁”式的优化,虽然提升了性能,但并未从根本上改变RAG架构的“刚性”——它仍然是一个无法根据中间结果进行动态决策的“死流程”。
4. 架构革命——模块化RAG(Modular RAG)与控制流的解放
高级RAG的线性流程无法支持需要判断、循环或动态分支的复杂决策过程。例如,系统无法在初步检索后,判断信息是否足够,如果不够,就换个关键词再检索一次。这一根本性限制,催生了RAG架构的一次真正革命:模块化。

模块化RAG的核心思想是将RAG系统从一个固定的“脚本”,重塑为一个由可编排的、独立的“模块”构成的图(Graph)或状态机(State Machine)。这使得控制流得以彻底解放。
在Python生态中,LangGraph的出现是这一思想转变的标志性事件。它将应用逻辑显式地建模为一个状态图 (State Graph):
- 节点 (Nodes):代表一个原子化的功能单元(如:retrieve, rewrite_query, grade_documents, generate)。
- 边 (Edges):代表流程的走向。特别是条件边 (Conditional Edges),它允许系统根据当前状态(例如,grade_documents节点判断所有文档都不相关)动态决定下一步去往哪个节点(例如,回到rewrite_query节点,而不是直接去generate)。
这种思想对于身经百战的Java架构师而言并不陌生。虽然Java生态目前缺乏与LangGraph直接对标的专用AI框架,但其核心理念可以通过业界成熟的工作流引擎(如Camunda, Flowable)或自定义的状态机模式来优雅地实现。
我们可以将RAG的各个步骤(检索、重排、生成、评估)封装为独立的、高内聚的Service Bean,然后由工作流引擎根据预定义的业务规则(BPMN图)进行调度:
- 在BPMN图中,节点 (Nodes) 对应一个服务任务(Service Task),如RetrievalTask、ReRankingTask、GenerationTask。
- 边 (Edges) 则对应顺序流(Sequence Flow)和由排他网关(Exclusive Gateway)控制的条件流。网关可以根据流程变量(即系统的State,如retrieval_quality_score)的值,决定流程是继续、是重试、还是直接返回失败。
架构师箴言:模块化RAG的出现,标志着RAG的设计者从一个“流程执行者”的角色,转变为一个真正的**“系统架构师”**。我们的关注点从“如何实现一个步骤”,转向了“如何设计一个包含状态、分支、循环和容错的鲁棒系统”。RAG系统因此获得了前所未有的灵活性和可扩展性,能够处理以往线性流程无法应对的、需要多步推理和自我修正的复杂任务。
5. 范式重塑——Agentic RAG与RAG的“组件化”
模块化RAG赋予了我们构建复杂工作流的能力,但工作流本身(即图的结构)仍需由开发者预先定义。面对开放式的、无法预知所有可能性的复杂任务,任何预定义的图结构也终将显得力不从心。
这就引出了RAG演进的第四个、也是当前最前沿的阶段:Agentic RAG。这一阶段的核心并非单纯的技术升级,而是一次深刻的架构范式重塑。
核心范式转变:RAG的“降级”与“组件化”
在Agentic范式中,RAG系统不再是整个应用的中心,它被“降级”为一个可被调用的、封装良好的**“工具(Tool)”**。

决策的中心从RAG工作流,上移到了一个更高层次的智能体(Agent)。这个Agent的大脑(通常是一个具备强大推理能力的LLM,如GPT-4、Claude 3 Opus)拥有任务分解、规划和多工具协调的能力。
Agentic RAG的工作流范式如下:
- 任务分解与规划:Agent接收一个高层次的、复杂的任务(例如,“对比我们公司和竞品X在最新财报中体现的盈利能力差异,并总结原因”)。Agent的大脑负责将此任务分解为一系列可执行的子步骤(1. 查找我司最新财报;2. 查找竞品X最新财报;3. 提取两份财报的关键盈利指标;4. 对比指标并生成摘要;5. 查找分析师评论以总结原因)。
- 工具选择与调用:在执行某个子步骤时,如果Agent判断需要从内部知识库获取信息(如步骤1),它会选择并调用RAG系统作为其工具箱中的一个工具。如果需要获取公开信息(如步骤2),它会调用搜索引擎工具。
- 信息整合与推理:Agent能够调用多种工具,并对其返回的多源信息进行综合、比较、验证和推理。
- 生成最终响应:在完成所有子步骤后,Agent根据整合后的信息生成最终的、全面的答案。
在Python中,LangChain的AgentExecutor是实现这一模式的经典方案。在Java生态中,LangChain4j同样提供了强大的Agent构建能力,允许我们将一个精心打造的RAG服务,轻松封装为一个**@Tool**,供Agent调用。
Java - LangChain4j 示例:将RAG服务封装为Agent工具
1 | import dev.langchain4j.agent.tool.Tool; |
架构师箴言:Agentic RAG是RAG架构演进的逻辑终点。它将RAG从一个试图解决所有问题的**“万能端到端系统”,重新定位为一个专注于解决特定问题的“高内聚、低耦合的智能组件”。对于架构师而言,这意味着RAG的设计目标发生了根本性变化:我们的目标不再是构建一个无所不能的对话机器人,而是为更高层次的智能体,提供一个API清晰、性能稳定、结果可靠**的知识交互服务。RAG的设计必须服从于上层Agent系统的整体架构需求,成为整个智能系统中最坚实的那块“基石”。
6. 架构师的实践框架:重构企业级RAG的七层模型
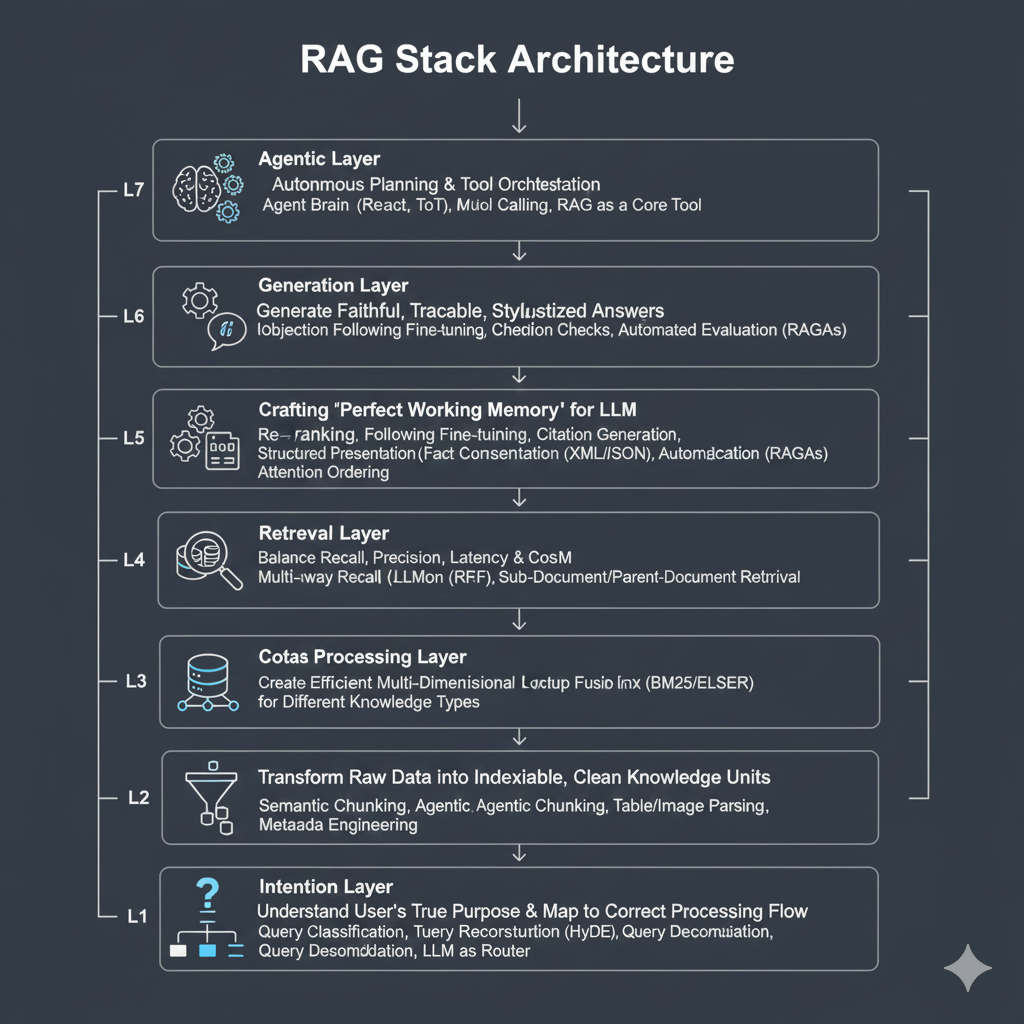
基于上述演进逻辑,为了系统性地指导工业级RAG系统的设计、诊断与优化,我提炼出一个**“企业级RAG七层架构模型”**。这个模型不仅是一个技术栈的清单,更是一个结构化的思维框架,帮助我们像剥洋葱一样,层层深入地审视和构建RAG系统。
| 层次 | 层级名称 | 核心目标 (Why) | 关键技术与范式 (What & How) |
|---|---|---|---|
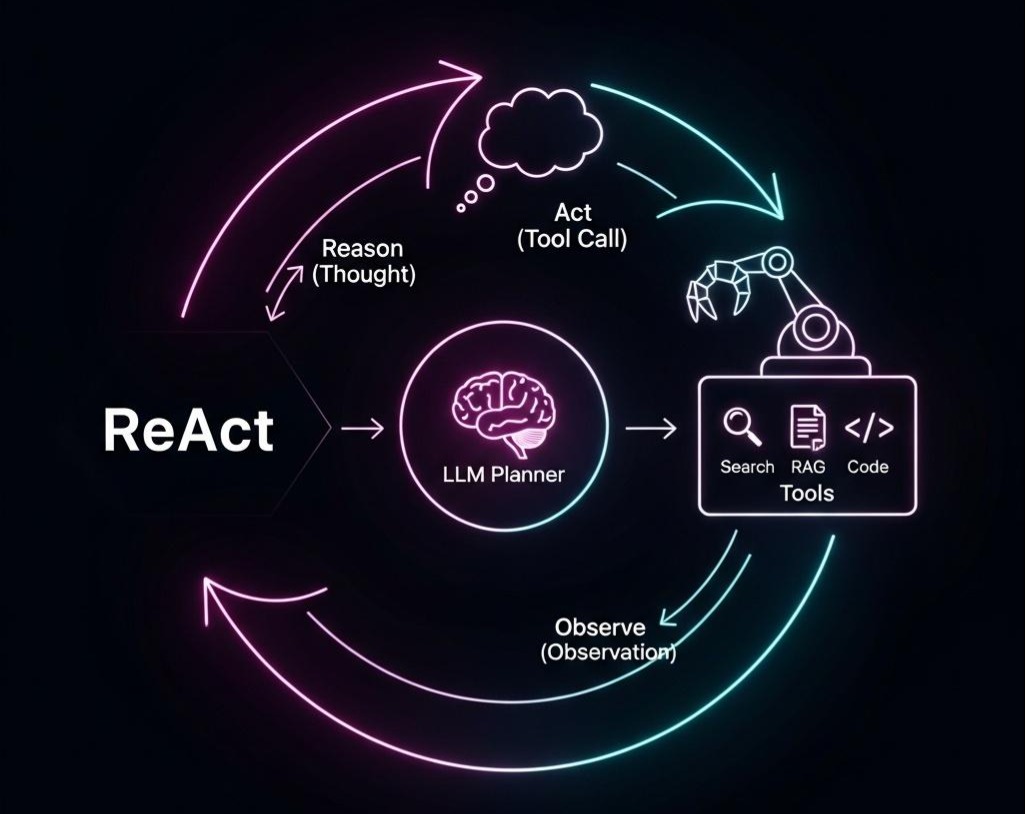
| L7 | Agentic层 | 任务的自主规划与工具协同 | Agent大脑(ReAct, ToT)、多工具调用、将RAG作为核心工具之一 |
| L6 | 生成层 | 生成忠实、可追溯、风格化的答案 | 指令遵循微调、引用生成(Citation)、事实一致性校验、自动化评估(RAGAs) |
| L5 | 上下文工程层 | 为LLM打造“完美工作记忆” | 重排序(Re-ranking)、上下文压缩(LLMLingua)、结构化呈现(XML/JSON)、注意力排序 |
| L4 | 检索层 | 平衡召回、精确、延迟与成本,召回最佳候选集 | 混合检索(Hybrid Search)、多路召回、结果融合(RRF)、子文档/父文档检索 |
| L3 | 索引层 | 为不同类型知识创建高效的多维查找结构 | 向量索引(HNSW)、稀疏/关键词索引(BM25/ELSER)、图索引(Graph)、多模态索引 |
| L2 | 数据处理层 | 将原始数据转化为可被索引的、干净的知识单元 | 语义分块(Semantic Chunking)、Agentic Chunking、表格/图像解析、元数据工程 |
| L1 | 意图层 | 理解用户真实目的,并将其映射到正确的处理流程 | 查询分类、任务路由、查询重构(HyDE)、查询分解、LLM作为路由器 |
这个模型自下而上,从理解用户输入开始,到最终由Agent完成任务,构成了一个完整的、可扩展的RAG体系。在未来的文章中,我们将逐层深入探讨每一层的技术细节和工程挑战。
7. 未来已来:超越文本与上下文工程的战略价值
在结束这次宏大的架构穿越之前,我们还需要将目光投向两个决定未来RAG系统竞争力的关键领域。
7.1 超越文本:多模态RAG的挑战与机遇
我们至今的讨论都默认RAG处理的是文本。但企业的知识远不止于此:设计图、PPT、会议录音、产品演示视频……未来的RAG必须是多模态的。
- 图像RAG:如何“分块”一张复杂的架构图或财务报表截图?如何用“视觉问题”去检索相关的图像片段?CLIP及其后继者通过统一的图文Embedding空间打开了大门,但如何设计高效的索引和检索策略仍是开放性问题。
- 代码RAG:代码不是无结构的纯文本,它有抽象语法树(AST)、有函数调用关系、有依赖图。真正的代码RAG,应该能在代码的结构和语义层面进行检索,例如“查找所有调用了deprecated_api并且没有做异常处理的函数”。
多模态RAG将极大地拓展RAG的应用边界,但它也对我们的L2-数据处理层和L3-索引层提出了全新的、艰巨的挑战。
7.2 性能的决胜手:上下文工程(Context Engineering)
在七层模型中,如果说其他层决定了RAG的“下限”,那么L5-上下文工程层则决定了其性能的“上限”。它正迅速成为区分平庸与卓越RAG系统的核心“胜负手”。
上下文工程,其本质是在将信息注入LLM这个“CPU”之前,进行一次精密的“寄存器分配”和“指令优化”,以最大化其有限的计算和注意力资源。其关键实践包括:
- 精选 (Selection & Re-ranking):确保只有最高质量、最相关的信息能进入上下文,这是基础。
- 排序 (Ordering):通过“两端置顶”(Lost-in-the-Middle-Mitigation)等策略性排序,将最重要的信息放在LLM注意力最集中的开头和结尾,对抗“中间遗忘”。
- 呈现 (Formatting):使用XML标签等结构化格式来明确信息的角色(, )和关系,像给LLM画重点一样,引导其注意力。
- 压缩 (Compression):在保留核心语义的前提下,通过LLMLingua等技术,减少上下文的Token数量,以在有限的窗口内塞入更多信息,同时降低成本和延迟。
未来,RAG系统的竞争优势将越来越多地体现在上下文工程的精细化、智能化程度上。
结语:从“线性脚本”到“智能组件”,RAG的架构宿命
在本篇超过万字的系统性梳理中,我们完成了一次对RAG架构演进的深度穿越。我们不再将RAG看作一个单一的技术,而是将其视为一个持续进化、为解决核心矛盾而不断重塑的复杂工程体系。
- 我们从信息论和经典IR的理论高度出发,深刻理解了RAG的本质及其与历史的连接,这解释了为何朴素RAG会存在“理论贫困”。
- 在从朴素RAG到高级RAG的演进中,我们学会了如何通过检索前后的“预处理”和“后处理”来缝补裂痕,这是从“能用”到“好用”的必经之路。
- 在模块化RAG的架构革命里,我们见证了“图”思维如何解放了“链”的束缚,赋予了我们构建复杂、非线性工作流的能力,这是从“死流程”到“活系统”的飞跃。
- 最终,在Agentic RAG的范式重塑中,我们洞察了RAG的最终宿命——从一个试图包揽一切的“端到端系统”,回归为一个可被更高层智能体调用的、高内聚的“知识组件”。
“七层RAG架构模型”为我们提供了一张宝贵的“作战地图”,它让我们能够系统性地诊断、设计和优化生产级的RAG系统。而“上下文工程”和“多模态”的崛起,则指明了在未来RAG性能竞赛中的核心战场。
理解RAG的演进逻辑,是成为“AI深水区建造者”的必修课。因为在未来更复杂的Agentic系统中,RAG将作为最基础、最核心的“感知”模块而存在。一个不可靠、不智能的RAG,将导致整个智能体大厦的根基不稳。
至此,我们已经为RAG的宏观架构建立了清晰、深刻的认知框架。但真正的魔鬼,全部隐藏在细节之中。在这七层架构的每一层,都潜藏着无数的技术挑战和工程权衡。
在下一篇章 《智能总控的诞生——从意图识别到任务路由,深入RAG七层模型之意图层》 中,我们将深入“七层模型”的第一层。我们将直面那个最源头的问题:当用户输入一句话时,我们如何精确判断其真实意图,并将其智能地分发到RAG、Agent或其他处理流程中去?这将是一场关于“理解”的深度探索,也是构建一个真正“懂你”的AI系统的起点。