RAG篇(10):Agentic RAG的黎明:当RAG拥有“规划”能力,从“问答机”到“研究助理”的进化
导语:当“答案”本身,不足以构成答案
在过去的九个篇章里,我们经历了一场艰苦卓绝的“军备竞赛”。我们为RAG系统锻造了最锋利的“矛”(基于Milvus、Elasticsearch、Neo4j三位一体的检索引擎),构建了最坚固的“盾”(上下文工程),并为其装上了最精密的“眼”(评估与反馈飞轮)。我们似乎已经打造出了一台终极的“问答机器”。
然而,当我们带着这台“完美机器”去面对一个真实、开放、充满不确定性的商业问题时,一种新的、更深层次的无力感开始浮现。
想象一下,你的CEO向你提出了一个看似简单的问题:“我们应该收购初创公司A吗?请给我一份决策备忘录。”
你的RAG系统会怎么做?它可能会去知识库里检索关于“公司A”的文档,找到一些零散的信息,然后告诉你“公司A是一家成立于2022年的AI公司,主营业务是…”。这个答案是正确的,但它毫无价值。因为它没有回答CEO的真正问题。
一个合格的分析师会如何解决这个问题?他的脑海中会浮现一个复杂的**“行动计划”**:
信息收集:首先,我需要从多个来源收集信息:
查询内部数据库,看我们与公司A是否有过接触(RAG)。
在网上搜索公司A的创始人背景、融资历史和媒体报道(Web Search)。
分析公司A的技术专利和产品(RAG/Web Search)。
查询我们的主要竞争对手是否 也对A公司感兴趣(Web Search)。
分析与评估:然后,我要对收集到的信息进行综合分析:
- 进行SWOT分析。
- 评估其技术与我们现有业务的协同效应。
- 初步估算其潜在价值和收购风险
生成报告:最后,将所有分析结果,整合成一份结构清晰的决策备忘录。
这就是“问答”与“解决问题”之间的天壤之别。前者只需要“检索-生成”,而后者需要**“规划-行动-反思”**。
本篇,我们将迎来RAG演进的终极形态——Agentic RAG。这不再是关于RAG本身的又一次优化,而是一场**“认知升维”。我们将为我们强大的RAG“工具箱”,装上一个真正的大脑——规划器(Planner)。我们将深入剖析以ReAct (Reason + Act)为代表的规划框架,学习如何让我们的系统从一个被动的“问答机”,进化为一个能够主动思考、分解任务、使用多种工具、并从错误中学习**的“AI研究助理”。
这篇文章将是连接“信息检索”和“自主智能”两大领域的关键桥梁。它将为你揭示,如何通过引入“规划”这一核心能力,让你的AI应用真正拥有“解决问题”的智慧。
第一部分:Agent的“灵魂”—规划器(Planner)的理论基石
要构建一个Agent,我们首先要理解它的“大脑”是如何工作的。这个“大脑”就是规划器,它的职责是制定一个能够达成最终目标的行动序列。
1.1 从“思维链”到“行动链”:CoT与ReAct
思维链 (Chain-of-Thought, CoT)
核心思想:在回答复杂问题前,先让LLM在Prompt中一步步地“思考”和“推理”,将复杂的推理过程分解成中间步骤。这极大地提升了LLM在数学、逻辑推理等任务上的表现。
示例:
问题: “如果一个篮子里有5个苹果,我又放进去了3个,然后吃掉了2个,还剩几个?”
CoT Prompt: “请一步步思考并回答。首先,篮子里有5个苹果。然后,放进去3个,现在总共有5+3=8个苹果。接着,吃掉了2个,所以剩下8-2=6个。因此,最终剩下6个苹果。”
局限性:CoT是一种**“封闭世界”**的思考。整个推理过程完全依赖于LLM自身的参数化知识,它无法与外部世界互动,无法获取新信息,也无法验证其推理步骤的真实性。
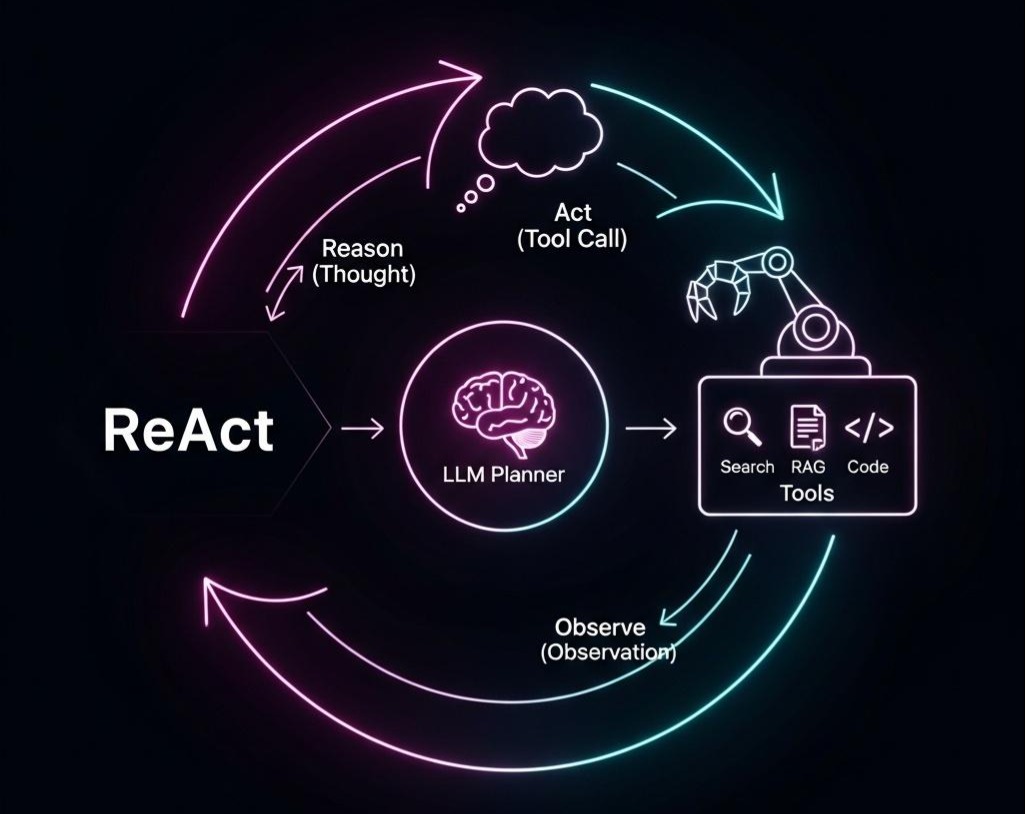
ReAct (Reason + Act)
核心思想:这是将CoT与Agent范式结合的革命性一步。ReAct框架将LLM的每一次输出,都结构化为“思考(Thought)”和“行动(Action)”两部分。
工作循环:这是一个经典的**“感知-规划-行动”**循环的实现。
- Reason (思考):LLM基于当前的用户问题和历史步骤(观察),进行一次“内心独白”(Thought)。它分析任务进展,判断下一步是应该生成最终答案,还是需要调用一个工具来获取额外信息。
- Act (行动):如果LLM决定需要获取信息,它会输出一个明确的“行动(Action)”,这个行动通常是一个结构化的指令,如 [Tool: a_search_engine, Input: “LangChain的作者是谁?”]。
- Observe (观察):Agent的“执行器(Executor)”解析这个Action,调用相应的工具(如搜索引擎API),并将工具返回的结果(Observation)包装起来。
- Repeat (重复):执行器将这个“观察”结果,作为新的上下文,连同历史记录一起,再次喂给LLM,开始新一轮的“Reasoning”。
与CoT的根本区别:ReAct打破了“封闭世界”,它让LLM的思考链条能够与外部世界的真实反馈进行互动。每一次“观察”,都是一次对外部世界的“采样”,LLM可以基于这些采样来修正自己的思考路径。
架构师洞察: ReAct框架的设计,是构建现代Agent系统的基石。它提供了一种可解释、可调试的机制来观察LLM的“思考过程”。通过查看Thought -> Action -> Observation的完整轨迹,我们可以清晰地知道Agent在每一步都在想什么、做什么,以及它看到了什么。这种“白盒化”的思考过程,对于构建可靠、可控的Agent至关重要。
1.2 超越线性链条:从“思维树”到“思维图”
ReAct虽然强大,但它的思考路径本质上仍然是线性的。如果某一步走错了,它很难进行有效的“回溯”或探索其他可能性。为了解决这个问题,更高级的规划策略应运而生。
思维树 (Tree-of-Thoughts, ToT)
核心思想:不再生成单一的思考链,而是在每个思考节点上,生成多个不同的下一步思考(分支),从而构建一棵“思维树”。
工作模式:
- 生成分支:在每一步,让LLM提出多个可能的下一步解决方案。
- 评估分支:使用另一个LLM(或启发式规则)作为“评估器”,对每个分支的“价值”或“可行性”进行打分。
- 搜索/剪枝:采用经典的图搜索算法(如广度优先搜索BFS或深度优先搜索DFS),在思维树上进行探索,并剪掉那些价值低的分支。
优点:显著增强了Agent在需要探索和复杂决策(如解决数学难题、进行创意写作)任务上的表现。
思维图 (Graph-of-Thoughts, GoT) / LangGraph
核心思想:将思维树的思想推向极致,允许思考路径形成任意的图结构,包括合并(Merge)和循环(Cycle)。
与ToT的区别:
合并:不同的思考分支在后续步骤中可以被合并,综合它们的信息来产生新的思考。
循环:允许Agent进行“自我修正”和“迭代改进”。例如,生成一个草稿 -> 评估草稿 -> 根据评估意见返回修改草稿 -> 再次评估… 直到满意为止。
工程实现:Python的LangGraph框架正是这一思想的杰出工程实现。它将Agent的工作流显式地建模为一个状态图(State Graph),开发者可以像定义一个软件流程一样,精确地定义节点(工作单元)和边(控制流),包括条件分支和循环。
架构师思考: 从CoT到ReAct,再到ToT和GoT,我们看到了一条清晰的演进路径:从“封闭的线性思考” -> “与世界互动的线性思考” -> “可探索的分支思考” -> “可循环、可迭代的图状思考”。规划器的能力越来越强,Agent的自主性和解决复杂问题的能力也随之指数级增长。
第二部分:Agentic RAG的架构实现—“规划器”与“工具箱”的协同
理解了规划器的理论,我们现在可以着手构建一个真正的Agentic RAG系统。其核心架构包含两大组件:一个负责思考的规划器(Planner)和一个包含多种能力的工具箱(Toolbox)。
2.1 架构蓝图

一个典型的Agentic RAG系统架构如下:
用户接口 (User Interface):接收用户的复杂任务请求。
主控Agent (Master Agent / Orchestrator):
规划器 (Planner):其核心是一个配置了ReAct或更高级规划Prompt的LLM。它负责任务分解和步骤规划。
工作记忆 (Working Memory / Scratchpad):用于存储整个任务执行过程中的所有中间结果:历史思考、行动、观察。
执行器 (Executor):负责解析规划器生成的Action,并调用相应的工具。
工具箱 (Toolbox):
RAG工具:我们之前精心构建的、用于查询私有知识库的RAG服务。
Web搜索工具:用于获取实时、公开信息的工具(如调用Google/Bing/Tavily API)。
代码执行工具:一个沙箱环境,可以执行Python或SQL等代码,用于数据分析和计算。
其他API工具:任何企业内部的API(如查询订单、更新CRM等)。
2.2 Java实战:使用LangChain4j构建一个简单的ReAct Agent
LangChain4j为在Java中构建Agent提供了强大的支持。让我们构建一个具备RAG和Web搜索能力的简单研究助理。
- 定义工具 (Tools)首先,我们将RAG服务和Web搜索服务封装成Agent可以调用的@Tool。
1 | // RagToolProvider.java (承接上一章的思路) |
关键点:@Tool注解中的描述文本至关重要。规划器LLM会完全依赖这些描述来判断在何时、何种情况下应该使用哪个工具。描述必须清晰、准确、无歧义。
- 构建Agent (AI Service)LangChain4j的AiServices工厂可以将一个接口和一个工具列表,神奇地组合成一个功能完备的Agent。
1 | import dev.langchain4j.service.AiServices; |
当我们调用executeResearch(“LangChain的作者是谁?他现在在哪家公司工作?”)时,在LangChain4j内部(如果开启了日志),你将看到一个清晰的ReAct轨迹:
- LLM Thought: “The user is asking two questions. First, who is the author of LangChain. Second, which company does he work for. I should first search the web to find the author’s name.”
- LLM Action: searchWeb(“who is the author of LangChain”)
- Tool Observation: “Harrison Chase is the creator of LangChain…”
- LLM Thought: “OK, I know the author is Harrison Chase. Now I need to find his company. I will search the web again.
- LLM Action: searchWeb(“Harrison Chase company”)
- Tool Observation: “Harrison Chase is the CEO and Co-founder of LangChain, the company.
- LLM Thought: “I have all the information needed. I can now provide the final answer.
- Final Answer: “LangChain的作者是Harrison Chase,他目前在自己联合创办的公司LangChain担任CEO。”
第三部分:从“能动”到“智能”—Agentic RAG的挑战与高级策略
构建一个能跑通的ReAct循环只是第一步。在生产环境中,Agent会遇到各种预想不到的挑战,需要更高级的策略来保证其鲁棒性和智能性。
3.1 核心挑战
- 规划僵化 (Planning Rigidity):简单的ReAct Agent容易陷入线性思维,一旦某个工具调用失败或返回无用信息,它可能不知道如何调整计划。
- 工具选择错误 (Incorrect Tool Selection):由于Prompt描述的微小歧义,或LLM自身的理解偏差,Agent可能选错工具,例如用RAG工具去查实时天气。
- 循环陷阱 (Looping Traps):在某些情况下,Agent可能陷入无意义的循环。例如,反复用同一个关键词进行搜索,却始终得不到有用信息。
- 结果综合能力弱 (Poor Synthesis):Agent可能成功地调用了多个工具并收集到了所有信息片段,但在最后一步,无法将这些碎片化的信息有机地整合成一个逻辑清晰、全面的答案。
3.2 高级策略与未来方向
引入反思与自我修正 (Reflection & Self-Correction)
思想:这是解决规划僵化和循环陷阱的关键。在Agent执行完一个或一系列动作后,引入一个专门的“反思”步骤。
实现:让LLM扮演一个“批判者”的角色,审查当前的执行轨迹和结果,并提出改进建议。
反思Prompt示例: “你已经执行了以下操作:[…执行历史…]. 当前得到的结果是:[…当前结果…]. 请评估当前的结果是否已经足够回答用户的原始问题 ‘{query}’?如果不够,请指出还缺少哪些信息,并提出下一步的具体行动建议。”
框架支持:LangGraph的循环能力,正是为实现这种“行动-反思-修正”循环而设计的。
多Agent协作 (Multi-Agent Collaboration)

思想:将“鸡蛋放在不同的篮子里”。与其构建一个无所不能的“全能Agent”,不如构建一个由多个“专家Agent”组成的团队。
架构:
规划Agent (Planner Agent):负责顶层的任务分解和协调。
研究Agent (Research Agent):专门负责使用RAG、Web搜索等工具进行信息收集。
写作Agent (Writing Agent):专门负责将研究Agent收集到的原始资料,润色和整合成高质量的报告。
审查Agent (Reviewer Agent):专门负责评估写作Agent的输出,并提供修改意见。
实现:Python的AutoGen和CrewAI是实现多Agent协作的优秀框架。在Java中,可以利用Akka等Actor模型框架,或基于消息队列,来构建Agent之间的通信和协作机制。
记忆的进化 (Memory Evolution)
挑战:Agent的“工作记忆”(Scratchpad)通常是短暂的,任务结束后即被清空。它无法从过去的成功或失败中学习。
解决方案:为Agent建立一个**长期记忆(Long-term Memory)**模块,通常也由一个向量数据库实现。
存储什么? 不再是简单的文档Chunk,而是成功的“思考-行动-结果”轨迹,或是失败案例的“反思总结”。
如何使用? 在新任务开始规划时,先从长期记忆中检索与当前任务相似的、过去成功的“经验”,并将这些经验作为“启发式知识”注入到规划Prompt中,引导LLM做出更优的决策。
架构师的终极思考: Agentic RAG的演进,本质上是在模拟一个人类专家的工作流程。一个初级专家只会机械地执行指令(Naive RAG)。一个高级专家懂得使用工具(ReAct Agent)。一个顶尖的专家团队,则懂得规划、协作、反思、并从经验中学习(高级Agentic系统)。我们作为架构师的使命,就是用代码和架构,一步步地复现这个从“新手”到“大师”的进化之路。
结语:RAG的终点,Agent的起点
在本篇中,我们完成了从RAG到Agent的决定性一跃。我们不再将RAG视为一个孤立的系统,而是将其定位为更宏大智能体架构中的一个核心“工具”。
我们深入了ReAct框架的“思考-行动-观察”循环,理解了它是如何打破LLM的“封闭世界”,让思考与现实互动。
我们展望了从思维树到思维图的更高级规划策略,看到了构建能够探索、回溯、甚至自我修正的复杂Agent的可能性。
我们通过LangChain4j的实战代码,亲手构建了一个具备多工具使用能力的简单Agent,感受到了其背后的工程之美。
我们直面了Agent在生产环境中可能遇到的四大挑战,并探讨了通过反思、协作、记忆等高级策略来构建更鲁棒、更智能的下一代Agent系统。
RAG的终点,是成为Agent强大的“感知”器官;而Agent的出现,则为RAG的应用价值插上了“翅膀”。 二者的结合,标志着AI应用正在从被动的“信息服务”,真正走向主动的“价值创造”。
至此,我们已经系统性地走完了RAG七层架构的每一个核心环节,并将其成功地融入了更宏大的Agentic范式。一个技术上完备、且具备初步智能的知识引擎蓝图已经绘制完成。
然而,一座宏伟的建筑,不仅需要精妙的设计图,更需要对每一块“砖石”——模型本身——有着深刻的理解和驾驭能力。我们如何选择、微调、部署和优化我们所依赖的LLM?
在下一篇章 《从混沌到智慧:解读大模型生命周期——预训练、微调、对齐与部署的系统性思考》 中,我们将把目光从“应用层”下潜到“模型层”。我们将系统性地梳理一个大模型从“诞生”到“服役”的全过程,为驾驭AI这头“巨兽”,建立起最根本的认知框架。