RAG篇(2):智能总控的诞生——从意图识别到任务路由,深入RAG七层模型之意图层
导语:在“回答问题”之前,先要“听懂问题”
在上一篇中,我们对RAG的宏大演进史进行了一次深度穿越,并最终得到了一个清晰的结论:RAG的未来,是作为更高层智能体(Agent)的一个“可调用工具”。然而,一个幽灵般的问题随之而来:当一个用户的请求到达系统时,谁来决定应该调用哪个工具? 是调用RAG工具进行知识库查询,调用搜索引擎获取实时信息,调用API执行一个动作,还是直接让LLM进行一段轻松的闲聊?
让我们回到一个你或许无比熟悉的场景:一个刚刚上线的、看似智能的客服系统。
用户输入:“你好。” -> 系统应该礼貌地回应,启动闲聊模式。
用户输入:“你们最新的退货政策是什么?” -> 系统需要查询内部知识库,启动RAG流程。
用户输入:“帮我查一下订单号OD11-2345-6789的物流状态。” -> 系统需要识别实体、调用订单API,启 动MCP工具调用。
用户输入:“对比一下A和B两款手机的优缺点,顺便查下今天北京的天气怎么样。” -> 这是一个复杂任务,需要分解、并行执行、再汇总。
90%的AI应用之所以显得“笨拙”,其根源并非在于“回答”得不好,而在于它们在第一步就失败了——它们根本没有真正“听懂”用户的真实意图。 它们试图用一套单一、僵化的流程去应对千变万化的用户输入,这无异于想用一把锤子去解决世界上所有的工程问题,包括拧螺丝。
这便是AI应用的“意图识别困境”。它标志着AI应用的核心任务正在从“回答问题”向“解决问题”进化。“解决问题”需要的能力,远不止于识别意图,更关键的是任务规划(Task Planning)和执行调度(Execution Orchestration)。
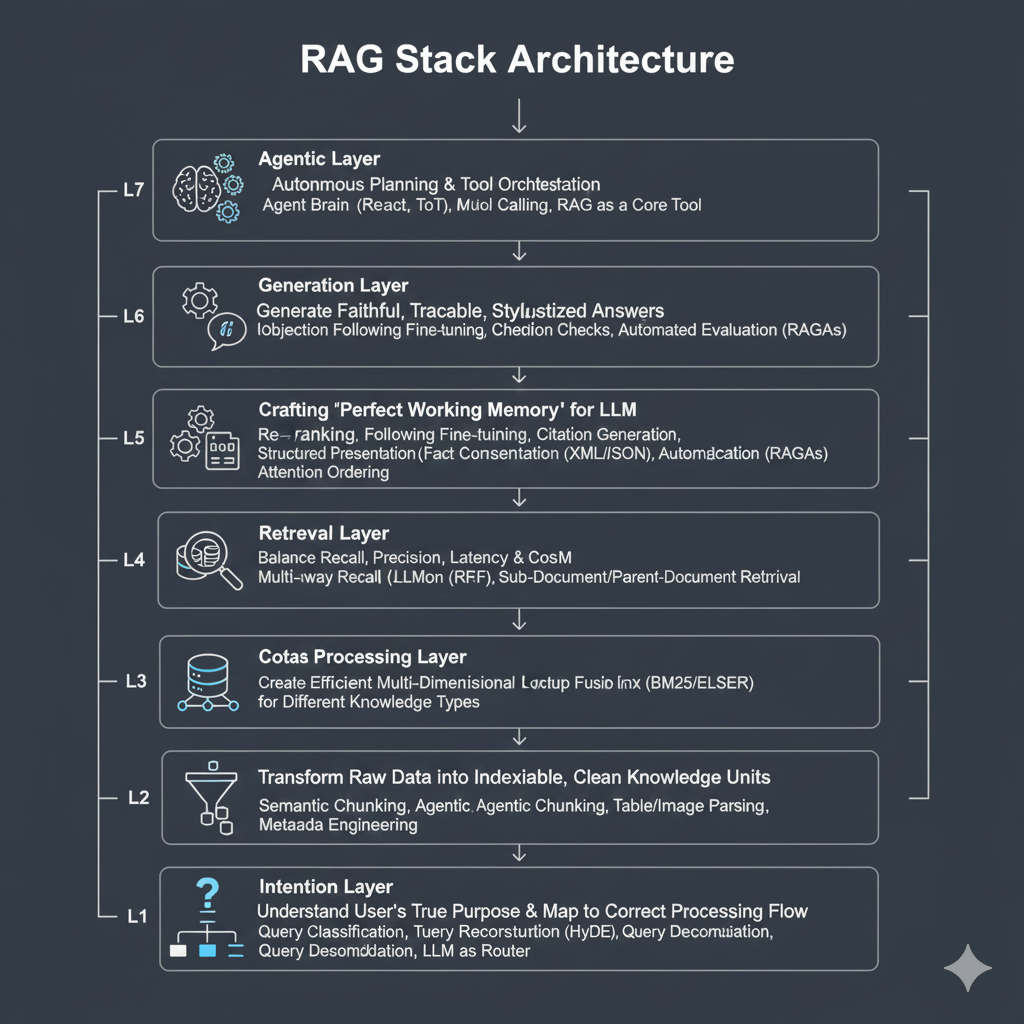
本文,我们将深入RAG七层架构模型的L1-意图层。它不只是一个“守门员”,更是整个系统的“中央神经系统”和“智能总控”。准备好从AI的使用者,进阶为AI的架构师了吗?
1. 思想的进化:从“分类选择”到“图的遍历”
要构建坚固的大厦,必先有牢固的地基。在深入具体架构前,我们必须厘清“意图层”背后核心思想的深刻变革:它已经完成了从“单点选择”到“路径规划”的进化。

1.1 从 “分类器” 到 “路由器” 的范式转移
传统意图识别:本质上是一个分类任务。例如,在传统NLU(自然语言理解)中,我们将“我的订单到哪了?”分类到query_order_status意图。它适用于目标有限且固定的场景,但面对开放、多变的语言,其模型训练成本高昂,泛化能力弱。
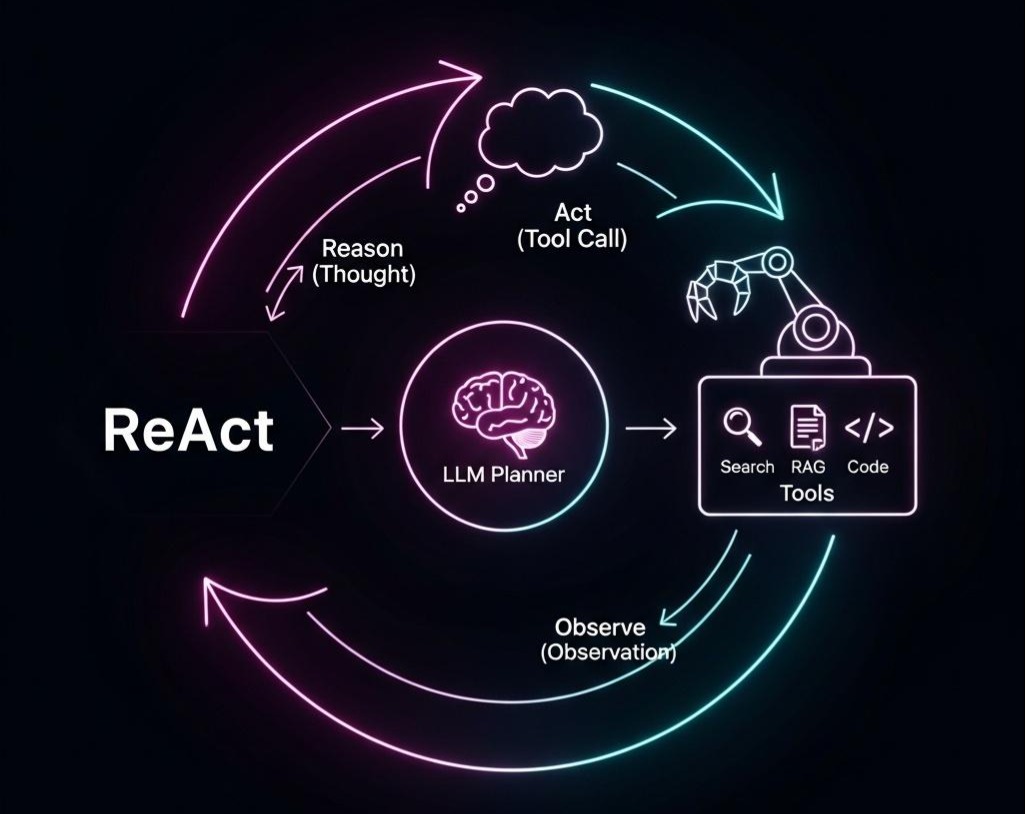
LLM驱动的意图识别:利用LLM强大的零样本/少样本能力,我们可以动态、灵活地识别更开放的意图。通过Function Calling/MCP技术,LLM可以直接“选择”一个预定义的“工具”并提取参数。这解决了“做什么(What)”的问题,将“分类器”升级为了“路由器”。但这依然是一种“单点决策”,它假设用户的整个请求可以通过一次工具调用来满足。
1.2 从 “选择” 到 “规划” 的必然升维
当用户的请求超越单个动作时,例如 “帮我写一个快速排序的Java实现,并为它写一篇解释其时间复杂度的博客”,单纯的 “单点决策” 就失效了。这个任务的本质是一个有向无环图(DAG - Directed Acyclic Graph):
- 节点(Node):代表一个原子任务,如 generate_code、analyze_complexity、write_blog_post。
- 边(Edge):代表任务间的依赖关系。write_blog_post 依赖于 generate_code 和 analyze_complexity 的完成。
这就是为什么我们需要将 “路由” 的概念,从 “选择一个目标”,升维到**“规划一条路径”。我们需要一个机制来描述和执行任务之间的依赖、并行、分支和循环关系。Python生态的LangGraph**正是这一思想的杰出代表,它将执行流程显式地建模为图,从而解放了控制流。
架构师箴言:意图层的演进,是从一个“选择题”到一个“论述题”的过程。初级系统只会在A、B、C中选一个;而高级系统需要先将问题分解成一、二、三点,然后规划出解决这些点的先后顺序和依赖关系。
2. 架构实践:构建 “多层防御” 的智能总控
一个成熟的意图层,并非单一的模型或组件,而是一个分层的、兼顾效率与智能的复杂系统。它就像一个组织精密的指挥中心,有负责快速分诊的“前台”,有负责深度诊断的“专家”,还有负责制定作战计划的“参谋部”。
2.1 第一层:“护城河”——低成本的混合路由
这是系统的“前台接待”,其核心目标是以最低的成本和延迟,处理掉80%的高频、明确的查询,避免它们无谓地消耗昂贵的LLM资源。这一层采用的是规则与语义相结合的混合策略。

1. 成本与智能的平衡术:规则路由
在追求“智能”的浪潮中,我们常常忽视了“规则”的价值。对于高度确定性的模式,基于规则的路由是最高效、最可靠的选择。
- 场景:识别订单号(如OD-XXXX)、手机号、身份证号,或触发特定的关键词(如“人工客服”)。
- 实现:使用正则表达式(Regex)或关键词列表。在用户输入进入任何模型之前,进行一次快速匹配。
- 优势:零成本,毫秒级响应,100%准确。
2. 快速分诊:轻量级语义路由 (Semantic Router)
对于那些意图明确但表达方式多样的查询(如各种关于FAQ的问法),我们可以使用轻量级的语义路由。
实现细节:
定义路由(Routes):为每个处理流程(如faq_rag、tech_doc_rag、general_chat)定义一组能代表其语义核心的“样例查询”(Utterances)。
向量化缓存:系统启动时,使用Embedding模型将所有样例查询转换为向量,并缓存在内存或Redis中。
相似度匹配:当用户查询到来时,将其向量化,并与所有缓存的样例向量计算余弦相似度。
决策与阈值:选择相似度得分最高的路由。关键在于设置一个合理的相似度阈值(如0.85)。如果最高分低于阈值,说明这不是一个常规问题,应将其“放行”给下一层的LLM路由器。
Java代码示例 (概念性):
1 |
|
2.2 第二层:“指挥官”——LLM作为路由器与规划器
当“护城河”无法拦截查询时,LLM路由器便登场了。它利用LLM强大的推理能力,将不同的处理流程抽象为“工具(Tools)”,并智能地选择、编排它们。
1. 查询分解 (Query Decomposition)
这是处理复杂任务的第一步。LLM扮演“任务规划师”,将一个模糊的、多意图的请求,分解成一个结构化的任务计划(Task Plan),这个计划通常是一个DAG。
实现细节:
处理流程工具化:将每一种处理流程(RAG查询、API调用、Web搜索等)封装成一个标准化的“工具”,并用自然语言清晰地描述其功能、输入和输出。
构建规划Prompt:这是核心技术。一个好的Prompt应包含:角色扮演、可用工具列表、用户请求、以及最重要的——严格的JSON输出格式约束,该JSON需要能表达任务间的依赖关系。
执行与状态管理:一个**编排器(Orchestrator)**负责解析LLM生成的计划。在Java中,我们可以用状态机来模拟LangGraph的思想:
1 | i. 解析计划:将LLM返回的JSON反序列化为任务对象列表。 |
Java代码示例 (使用状态机模拟LangGraph思想进行复杂任务规划):
1 | // 1. 定义任务计划的POJO (使用Jackson注解) |
2. 查询重构 (Query Rewriting)

在任务被分解并路由到具体工具(如RAG)后,执行前的最后一步“精加工”。它承认一个基本事实:用户的提问方式,不一定是机器检索的最佳方式。
- 后退一步思考 (Step-Back Prompting):当问题过于具体时,让LLM生成一个更泛化的上位问题去检索。
用户:“Java中如何用CompletableFuture实现一个带500ms超时的异步调用?”
Step-Back后:“Java中处理异步操作和超时的常用模式有哪些?” -> 这个查询更容易找到高层次、指导性的文档。
- 多视角查询生成 (Multi-perspective Query Generation):让LLM扮演不同角色(“初学者”、“专家”)来生成多个查询,合并检索结果,提高召回的全面性。
- 假设性文档嵌入 (HyDE):让LLM先“脑补”一个完美的答案,再用这个答案的向量去检索,因为“答案”的语言形态与知识库中的段落更匹配。
架构师箴言:查询分解是“战略规划”,决定了“打哪几场仗”;查询重构是“战术优化”,决定了“每一场仗怎么打才能赢”。二者结合,才能在意图层实现运筹帷幄。
3. 终极挑战:拥抱 “不可知性” 的艺术
一个强大的意图层,不仅要善于处理已知,更要优雅地处理未知。当所有智能都失灵,面对一个系统完全无法理解的全新意图时,我们该怎么办?这触及了人机交互的哲学核心——对“不可知性”的敬畏和处理。
3.1 挑战:延迟、错误与状态的泥潭
- 路由模糊性:用户查询的模糊性可能导致规划从第一步就走偏。
- 延迟叠加:每一次LLM规划调用和工具执行都会累积延迟。
- 错误传播:上游步骤的微小错误会被下游放大,导致雪崩式失败。
3.2 关键优化策略
- 规划缓存:对用户查询进行向量化,对于语义相似的查询,直接复用已有的执行计划(TaskPlan),避免重复的LLM规划调用。
- 异步化与并行化:对于无依赖的子任务,使用CompletableFuture或Project Reactor在Java中并行执行,最大化资源利用率。
- 微调专用路由器:与其依赖昂贵且通用的GPT-4,不如在特定领域的任务规划数据上,微调一个更小的开源模型(如Llama 3 8B),使其成为高效、低成本的专用“规划师”。
3.3 设计优雅的“降级”阶梯 (Graceful Fallback)
当面对一个真正无法理解的意图时,一个鲁棒的系统不应崩溃或胡言乱语,而应启动一个预设的、优雅的降级(Fallback)阶梯。

第一级:工具级重试与自修正
- 机制:当一个工具执行失败(如API超时、RAG未找到信息),规划器(Agent)应能捕捉到错误,并决定是重试、更换参数,还是调用另一个工具。
- 例子:RAG工具返回“未找到相关信息”,Agent可以决定调用WEB_SEARCH工具。
第二级:任务级澄清式提问
- 机制:如果Agent多次尝试后仍无法完成任务,或者从一开始就发现用户意图极度模糊,它不应继续盲目尝试,而应主动向用户求助。
- 例子:“对不起,我不太理解您的意思。您是想查询‘产品A的退货政策’,还是想了解‘如何处理已损坏的产品’?” -> 将模糊问题转化为一个选择题,引导用户明确意图。
第三级:系统级透明化致歉
- 机制:如果用户多次澄清后,系统依然无法理解,此时必须放弃。系统应给出一个诚实、透明的回答,承认自己的局限性,并提供最终的解决方案(如转人工)。
- 例子:“非常抱歉,我暂时无法处理您这个复杂的问题。我已经为您记录了该问题以供改进。如果您需要立即帮助,建议您联系[人工客服]。”
架构师箴言:一个系统的智能水平,不仅体现在它能解决多复杂的问题,更体现在它“不知道”的时候会怎么做。优雅的降级机制,是AI应用从一个“聪明的工具”走向一个“可靠的伙伴”的成人礼。
结语:意图层,AI应用的“大脑前额叶”
在本篇中,我们深入了RAG七层架构的“咽喉”要道——意图层。我们见证了它从一个传统的、基于分类的“守门员”,进化为一个由LLM驱动的、能够进行复杂路由、分解和重构的“智能指挥官”,是AI应用的“大脑前额叶”,负责判断、规划与决策。
我们学会了利用规则和语义的混合路由进行“快速分诊”,并用LLM的规划能力作为“深度诊断”的强大武器,实现了成本与智能的平衡。
我们通过查询分解的图执行思想,赋予了意图层真正的“规划能力”,使其能够将不可控的复杂任务,拆解为一系列可执行的、有依赖关系的简单步骤。
我们掌握了查询重构的艺术,通过在检索前对问题本身进行“精加工”,极大地提升了下游RAG流程的成功率。
最重要的是,我们直面了意图的“不可知性”,并设计了一套优雅的“降级阶梯”,让我们的系统在面对失败时,依然能保持谦逊、透明和可靠。
一个设计精良的意图层,是构建一个高效、智能、用户体验流畅的AI应用的绝对基石。它决定了系统的第一反应是否正确,决定了后续所有的计算资源是否被用在了“刀刃”上。
至此,我们已经“听懂了问题”。但新的挑战接踵而至:我们的知识库(文档)本身,往往是一堆格式混乱、难以解析的PDF、图片或网页。在将这些“原始矿石”送入RAG的熔炉之前,我们必须先对其进行高质量的解析和清洗。
在下一篇章 《LM原生OCR革命——从文字识别到DeepSeek-OCR视觉上下文压缩,深入RAG七层模型之解析层》 中,我们将深入“七层模型”的第二层。我们将直面RAG实践中最大的“拦路虎”——非结构化文档处理。我们将见证以DeepSeek-OCR为代表的“第四波”OCR技术,如何彻底改变游戏规则,将文档解析从一个工程难题,变成一个为LLM“预处理”和“压缩”视觉上下文的战略优势。