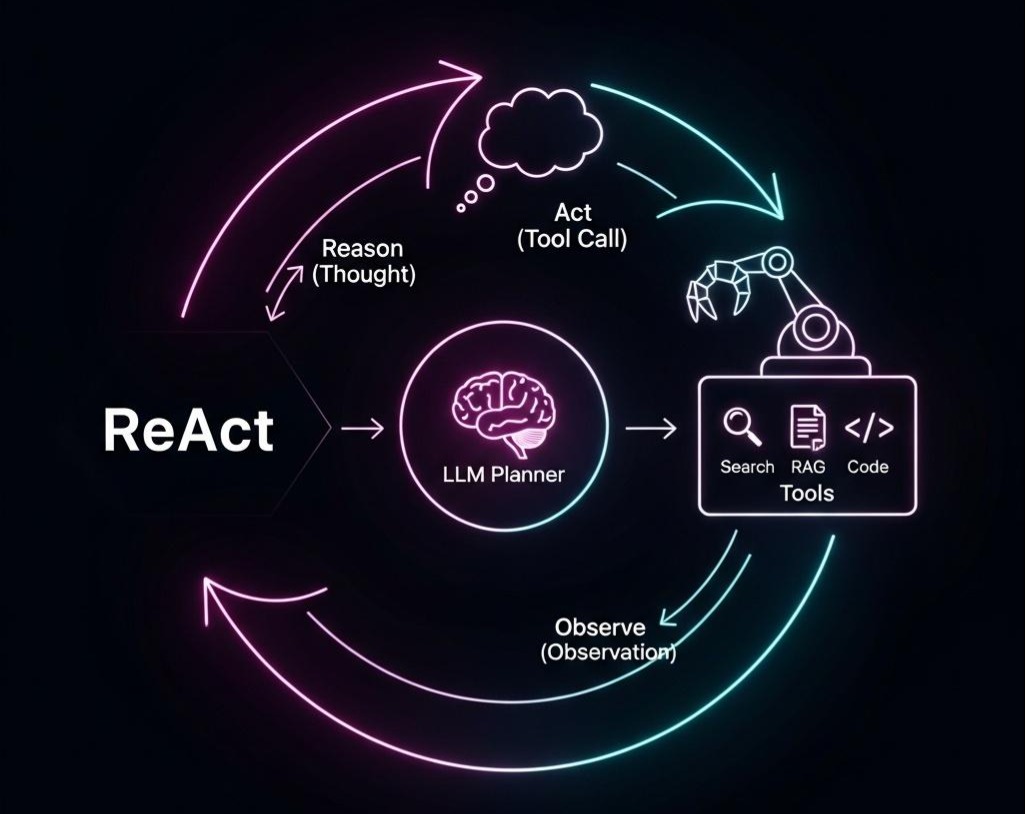
RAG篇(3):LLM原生OCR革命——从文字识别到DeepSeek-OCR视觉上下文压缩,深入RAG七层模型之解析层
导语:RAG的“阿喀琉斯之踵”——那份无法被完美解析的PDF
扩展:“阿喀琉斯之踵” (Achilles’ Heel) 源自希腊神话,指英雄阿喀琉斯身上唯一的致命弱点,即被母亲浸泡冥河时握住的未浸到水的脚后跟。这个典故现在比喻任何事物(包括国家、系统)或人看似强大却存在的致命、脆弱的环节或软肋,一旦被攻击就可能导致彻底失败。
让我们从一个你或许无比熟悉的场景开始:
经过数周的奋战,你和团队终于将一个基于RAG的智能知识库系统推上线。意图识别层精准无误,检索算法经过精心调校,LLM也选择了业界最顶尖的模型。你满怀信心地输入了第一个真正来自业务方的查询:“根据我们上一季度的财报PDF,分析一下‘XX业务线’的毛利率变化趋势及其原因。”
系统开始运转。几秒钟后,它返回了一个让你瞬间石化的答案:“根据提供的信息,无法找到关于‘XX业务线’毛利率的相关数据。”
你不信邪,打开调试日志,看到了RAG系统喂给LLM的“上下文”。那是一堆从PDF中提取出的、支离破碎的文本。原本清晰的表格变成了混乱的数字和字符的堆砌,跨页的段落被无情地切断,关键的图表和脚注则完全消失。LLM面对这堆无法理解的“乱码”,除了回答“不知道”,别无选择。
就在那一刻,一种深刻的无力感涌上心头。我们精心构建的、位于下游的、高级的AI逻辑,竟然被最上游的、最基础的“文档解析”环节,如此轻易地击垮了。
这便是RAG实践中一个近乎宿命的困境:企业80%最有价值的知识,都沉睡在这些图文混排、格式复杂的PDF、扫描件中。而我们传统的文档解析流程,就像一个拿着大锤的“拆迁队”,面对这些结构精美的“建筑”,只会一通乱砸,最终留下一地废墟。
我们陷入了一个两难的境地:要么接受“垃圾进,垃圾出”的低质量文本,要么为传统OCR工具提取出的海量、无压缩的文本Token,付出巨额的API调用费用并撑爆上下文窗口。这个看似不起眼的“解析”环节,竟成了整个RAG系统的“阿喀琉斯之踵”。
本篇,我们将深入RAG七层架构的第二层——解析层。我们将见证一场正在发生的、由LLM原生思想驱动的革命。我们将聚焦于以DeepSeek-OCR为代表的“第四波OCR浪潮”,剖析它如何从根本上颠覆了“文档解析”的定义——不再是孤立的“文字识别”,而是为LLM量身定做的“视觉上下文压缩”。
这篇文章将带你潜入这些前沿模型的架构深处,理解其设计背后的第一性原理,并提供一套可量化的评估方法、失败案例的归因分析以及工程上的解决策略。准备好,见证PDF这座“高墙”被推倒的时刻。
第一部分:OCR的四重浪潮:一场与“复杂性”的持久战
要理解DeepSeek-OCR的革命性,我们必须先回顾OCR技术为征服“文档复杂性”而走过的四段崎岖路程。这不仅是一部技术演进史,更是一部思想进化史,每一次浪潮的兴起,都是对上一代核心矛盾的回应。

1.1 第一波浪潮:传统开源的基石 (Tesseract)
核心思想:基于传统的计算机视觉(Computer Vision)技术栈。其流程大致为:
- 图像预处理(如灰度化、高斯模糊去噪、Otsu二值化)
- 版面分析(通过投影、连通域分析等方法进行行、词切分)
- 字符识别(基于模板匹配或早期的机器学习分类器,如SVM)
历史地位:起源于惠普实验室,后由Google接手并开源。作为OCR领域的“Hello, World”,它为无数开发者提供了入门的台阶,至今仍在一些简单的、标准化的场景中被使用。
致命缺陷:
- 脆弱性:其性能高度依赖于理想的输入条件。对图像质量、光照、字体、旋转角度极其敏感。一个轻微的倾斜或阴影,就可能导致切分逻辑的崩溃。
- 版面理解能力缺失:它本质上是在“看”像素点的集合,而非“读”文档的结构。对于表格、多栏布局、图文混排等现代文档的常见元素,其基于简单几何假设的切分逻辑几乎必然失败,输出的文本顺序往往混乱不堪。
- 高昂的工程成本:为了获得可用的结果,工程师需要投入大量时间进行图像预处理的参数调优,编写大量的“补丁”代码来应对不同的文档类型,维护成本极高。
1.2 第二波浪潮:商业API的 “云端力量”
代表:Google Vision API, Azure Cognitive Services, AWS Textract。
核心思想:利用云计算的海量算力和私有数据集,训练更大、更深的深度学习模型,并将这种强大的能力封装为简单易用的REST API。这是深度学习红利在OCR领域的第一次大规模商业化应用。
关键进步:
- 高精度:通过端到端的深度学习模型,识别准确率和鲁棒性远超传统开源工具。
- 结构化识别:AWS Textract等服务是这一浪潮的典范,它开始具备显式的表格(Tables)、表单(Forms)和键值对(Key-Value Pairs)的提取能力。它返回的不再是无序的文本行,而是带有结构化信息的JSON,这是一个巨大的进步。
核心矛盾:
- 成本与隐私:按页或按API调用次数收费,对于需要处理数百万甚至数十亿页文档的企业级RAG系统,成本会成为一个无法忽视的障碍。同时,将可能包含商业机密或用户隐私的文档上传到公有云,带来了严重的数据安全合规风险。
- 黑盒与不可控:开发者对模型本身没有任何控制权。无法针对特定类型的文档(如特定格式的财务报表、法律文书)进行优化,只能被动接受厂商提供的通用能力,当遇到识别错误时,除了提交工单,别无他法。
1.3 第三波浪潮:深度学习开源的 “民主化”
代表:PaddleOCR (百度飞桨),EasyOCR。
核心思想:将在学术界和工业界被验证有效的深度学习架构在开源社区进行高质量的实现和预训练。其主流架构为 CRNN + CTC。
- CRNN (Convolutional Recurrent Neural Network):这是一个精巧的组合。CNN部分(如ResNet变体)负责从输入图像中提取鲁棒的视觉特征序列,将图像的二维信息转化为一维的特征向量序列。RNN部分(通常是双向LSTM或GRU)则负责对这个特征序列进行时序建模,以捕捉字符间的上下文依赖关系(例如,识别出q后面很大概率是u)。
- CTC (Connectionist Temporal Classification):这是第三波浪潮的技术灵魂。在CTC出现之前,训练OCR模型需要精确地对每个字符在图像中的位置进行标注和切分,成本极高。CTC损失函数则巧妙地解决了这个问题,它允许模型在只知道整行文本标签的情况下进行端到端训练,而无需关心每个字符的精确对齐。它通过引入一个“空白”标签,并利用动态规划算法,来计算所有可能的、能生成正确文本序列的路径概率之和,从而进行反向传播。CTC的出现,是OCR领域能够大规模利用弱标注数据进行训练的关键。
优点:
- 性能逼近商业级:在许多标准数据集上,其性能与商业API不相上下。
- 可私有化部署:彻底解决了数据隐私和安全的核心痛点。
- 可定制化:允许有能力的团队在自己的数据集上进行微调,以优化特定场景的识别效果。http://unstructured.io等流行的文档解析库,其底层也大量依赖这类工具。
尚未解决的根本问题:这些工具的最终输出仍然是大量的、无压缩的文本字符。它们完美地解决了“识别准”的问题,却没有解决“成本高”和“上下文过长”的问题。对于一份100页的PDF,它们会忠实地返回几十万个字符,这对于下游需要按Token计费且有上下文窗口限制的LLM来说,依然是一场工程和成本上的灾难。
1.4 第四波浪潮:LLM原生的 “范式革命”
- 代表:DeepSeek-OCR。
- 核心思想:彻底抛弃 “先OCR再喂给LLM” 的分离式思想。它不再将OCR视为一个孤立的 “识别” 工具,而是一个端到端的视觉语言模型(VLM),其设计目标只有一个:为LLM生成最优的、可理解的、且经过高度压缩的上下文。
- 范式转变:从 “文字提取 (Text Extraction)” 到 “视觉上下文压缩 (Visual Context Compression)”。
工程启示: OCR技术的演进史,就是一部不断向 “文档保真度” 和 “工程实用性” 这两大目标妥协与平衡的历史。前三波浪潮,都在致力于提升 “识别” 本身的准确率,它们的共同假设是 “输出的文本要和原文档一模一样”。而第四波浪潮的出现,标志着我们终于意识到:OCR的最终目的,不是为了让人类阅读,而是为了让LLM理解。这个视角的转变,带来了一系列颠覆性的架构设计。
第二部分:DeepSeek-OCR架构深潜:“压缩”与“理解”的设计哲学
DeepSeek-OCR的架构设计,充满了对旧时代痛点的回应。它由两大核心构成:一个名为DeepEncoder的视觉编码器和一个名为DeepSeek3B-MoE-A570M的语言解码器。
2.1 灵魂拷问之一:为什么是 “视觉压缩” 而非 “文本提取” ?
这是理解DeepSeek-OCR第一性原理的关键。
- 工作原理:当一张文档图像输入时,DeepEncoder并不急于识别单个字符。相反,它将整个高分辨率图像“压缩”成一小组紧凑的“视觉Token(Vision Tokens)”。这些视觉Token,是图像内容的高度浓缩的语义表示,每个Token都可能蕴含了比单个字符丰富得多的信息(例如,一个Token可能代表了“一个加粗的、居中的标题”的视觉和语义概念)。
- 魔鬼细节:随后,这个小得多的视觉Token序列被送入MoE解码器,由解码器**“重建”**出原始的、包含完整结构和文本的Markdown格式内容。这个过程更像是一种“看图说话”或“视觉摘要”,而不是“逐字抄写”。
- 性能震撼:实验数据显示,在压缩比低于10倍时(例如,用1个视觉Token表示原本需要10个文本Token才能表示的信息),其文本解码精度高达97%。这意味着什么?对于一份原本需要10万个文本Token才能表示的PDF文档,现在可能只需要1万个视觉Token就能喂给下游模型,甚至更少。这从根本上改变了RAG处理长文档的成本函数,从O(字符数)转变为O(视觉复杂性)。
架构师思考时刻: 这种范式转变,意味着我们首次拥有了一种**“有损但语义保持”**的文档压缩技术。在过去,任何对原始文本的压缩都必然导致信息损失。而现在,我们可以通过牺牲极小的文本保真度(那3%的错误),换取10倍的上下文成本降低和处理效率提升。在构建大规模RAG系统时,这是一个极具战略价值的权衡。
2.2 灵魂拷问之二:DeepEncoder的“三叉戟”架构为何如此设计?

如何低成本地处理高分辨率的文档图像,是所有视觉模型的核心挑战。DeepEncoder的设计堪称艺术,它通过“三叉戟”架构应对这一挑战:
- 局部感知 (Window Attention):它借鉴了Meta的**SAM(Segment Anything Model)**模型的核心思想,通过窗口化的自注意力机制(Windowed Self-Attention)在局部进行精细的感知和分割。这使得模型能够像人眼一样,首先关注并理解字符、词组、线条、单元格等细粒度的视觉元素。这是“看清”的基础。其必要性在于,对于高分辨率图像(如1440x1080),标准的全局自注意力机制的计算复杂度是O(N^2),其中N是像素或Patch的数量,这在计算上是不可行的。窗口化将计算限制在局部区域,实现了效率与效果的平衡。
- 16倍卷积压缩器 (16x Convolutional Compressor):这是整个设计的点睛之笔。在计算昂贵的“局部感知”和“全局聚合”这两个阶段之间,插入一个16倍的卷积压缩器。这个压缩器在进入密集的、需要巨大计算量的全局注意力阶段之前,就将视觉Token的数量锐减。它像一个智能的“下采样”层,但与简单的池化(Pooling)不同,卷积层可以通过学习来保留最重要的特征。
- 全局聚合 (Global Attention):它引入了OpenAI的CLIP模型的思想,通过全局的注意力机制,将局部感知到的信息进行聚合,从而理解整个页面的宏观布局、章节关系、图文位置等全局语义。这是“看懂”的基础。没有这一步,模型只能看到“树木”,而无法看到“森林”。
这种“先局部细看 -> 再大幅压缩 -> 最后全局理解”的设计,精妙地平衡了效果与效率,使得模型能够在可控的GPU显存占用下,处理前所未有的高分辨率文档图像。
2.3 灵魂拷问之三:为什么解码器要用MoE(混合专家模型)?
解码器负责将压缩后的视觉Token“翻译”回结构化的Markdown文本。它采用了一个拥有30亿总参数、但每次推理只激活约5.7亿参数的MoE(Mixture of Experts) 架构。
- 设计动机:文档的视觉元素是多种多样的,包括纯文本、表格、代码、公式、图表等。用一个单一的、密集的神经网络(Dense Model)去处理所有这些类型的转换,意味着这个网络的每个部分都需要对所有任务都“略知一二”,难以做到“样样精通”。
- MoE的优势:MoE允许模型内部拥有多个“专家”子网络(通常是FFN层)。可以将其想象成一个“专家委员会”。
- 专家分工:通过训练,一个专家可能变得擅长处理表格的行列结构,另一个专家擅长处理LaTeX公式的语法,还有一个专家擅长处理常规的段落文本。
- 动态激活:在推理时,一个轻量级的“门控网络(Gating Network)”会根据输入的视觉Token,动态地选择激活最相关的少数几个专家(例如2个)。
- 架构收益:这使得模型在保持巨大知识容量(30亿参数)的同时,推理成本(FLOPs)远低于同等规模的密集型模型,实现了高效解码。这是一种典型的用更多的参数量(存储成本)换取更少的计算量(推理成本)的策略,非常适合现代GPU并行计算的特性。
灵魂拷问: DeepSeek-OCR的架构揭示了一个深刻的趋势:它将“文本”视为图像中的一种普通视觉元素,与图表、线条无异。 如果“文本”与“图像”之间的界限,从根本的数据类型差异,演变成了编码策略的选择,这将对我们未来的多模态数据架构产生何等深远的影响?我们过去基于文本的向量索引(如BGE, M3E)和检索引擎(如Elasticsearch),是否也需要一场彻底的革命,去适应这种全新的、融合了视觉与语义的“视觉Token”表示?
第三部分:深入实战:输出、评估与工程策略
理论的优美必须在实践中得到检验。一个架构师不仅要理解其原理,更要掌握如何使用、评估和解决它在现实世界中遇到的问题。
3.1 输出形态:让读者清晰感知的结构化JSON
DeepSeek-OCR的输出并非简单的纯文本,而是一个结构化的JSON对象,这正是其强大版面理解能力的体现。让我们进行一次直观的**“Show, Don’t Just Tell”**。
假设下面是一张pdf中内容截图:
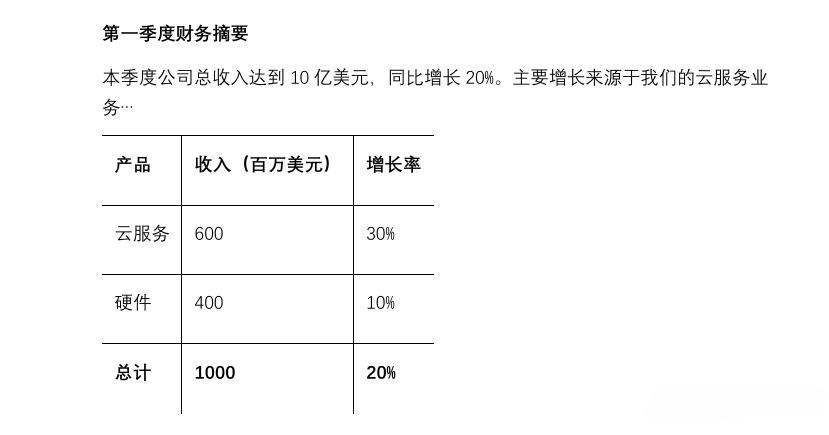
A. 传统OCR(如Tesseract)可能的输出(灾难现场):
1 | 第一季度财务摘要 本季度公司总收入达到10亿美元,同比增长20%。 主要增长来源于我们的云服务业务... 产品 收入(百万美元) 增长率 云服务 硬件 总计 1000 20% 云服务 600 30% 硬件 400 10% |
- 问题分析:表格的结构完全丢失,合并的单元格被错误地解析,文本行交错在一起,这样的“上下文”对LLM来说是纯粹的噪声。
B. DeepSeek-OCR可能的输出JSON(清晰的蓝图):
1 | { |
DeepSeek-OCR优越性:
类型化(type):模型不仅识别了文本,更识别了文本的角色(title, text, table)。这是后续进行语义分块的基础。
空间信息(bbox):保留了每个元素在页面上的精确位置。这对于需要进行视觉问答(VQA)或版面分析的下游任务至关重要。
结构化输出(md_text):最关键的是,它直接生成了Markdown格式的文本。表格被完美地转换成了Markdown表格语法。这意味着,我们无需再编写复杂的后处理逻辑去解析混乱的文本来重建表格。
3.2 如何评估OCR模型的好坏?–量化评估指标

“感觉不错”在工程上毫无意义。我们需要一套量化的指标来评估OCR模型的性能。
- 字符/词级别准确率 (Character/Word Accuracy):
- 方法:使用编辑距离(Levenshtein Distance)来计算模型输出文本与人工标注的“黄金标准”文本之间的差异。Accuracy = 1 - (插入数 + 删除数 + 替换数) / 总字符数。
- 实践要点:这是最基础的指标,但要小心“平均值陷阱”。应分别统计在纯文本区域和表格区域的准确率,后者通常更具挑战性。
- 表格结构准确率 (Table Structure Accuracy - TEDS):
- 方法:Tree-Edit-Distance-based Similarity (TEDS) 是一种专门评估表格识别质量的指标。它将表格的HTML或LaTex结构视为一棵树,然后计算将模型识别的树结构,编辑成“黄金标准”树结构所需的最少操作次数(如插入、删除、重命名节点)。
- 实践要点:对于财报、科研论文等包含大量表格的文档,TEDS是比字符准确率更重要的核心指标。一个TEDS得分高的模型,即使个别单元格字符有误,其整体结构也是可用的。
- 端到端RAG评估:
- 方法:这是一种“黑盒”评估,直接衡量OCR的改进对最终业务指标的贡献。
- 为一份或多份标准文档,人工编写一个高质量的问答对(Q&A)数据集。
- 分别使用待评估的OCR工具(如OCR-A vs OCR-B)处理这些文档。
- 基于两份不同的处理结果,构建两个独立的RAG系统(下游的Chunking、Embedding、LLM等保持一致)。
- 在这两个RAG系统上运行Q&A数据集,并使用RAGAs等框架,从**答案相关性(Answer Relevancy)、事实忠实度(Faithfulness)、上下文精确率(Context Precision)**等维度进行打分。
- 实践要点:这种方法成本最高,但最具说服力。它能直接回答那个终极问题:“花钱/精力升级OCR,到底值不值?”
3.3 失败案例归因与工程解决策略

当OCR效果不佳时,架构师需要像一名侦探,系统性地排查问题根源。
场景一:输出文本乱码或大段缺失
- 可能原因:
- 文档格式问题(最常见):PDF本身可能是“双层PDF”(一层图片,一层不可见的、可复制但混乱的文本),或者包含加密、损坏的嵌入式字体。这会导致所有OCR工具都失败。
- 图像质量过低:扫描件分辨率低于300DPI,或包含严重的光照不均、摩尔纹、手写批注干扰。
工程解决策略:
建立“预检”流程:在送入OCR之前,使用PDFBox(Java)或PyMuPDF(Python)等库,先尝试直接提取文本。
1
2
3
4if (text is clean and long enough):
return text;
else:
proceedToOCR()这个简单的if-else,可以为你节省90%不必要的OCR调用和成本。
标准化渲染:如果需要OCR,不要直接将PDF文件丢给模型。统一将其渲染为高质量、标准化的图像(如300 DPI的PNG),这能消除大量因PDF内部格式差异导致的不确定性。
图像增强模块:在调用OCR API前,可以加入一个基于OpenCV的图像增强模块,进行自动化的倾斜校正(deskew)、对比度增强(CLAHE)和去噪(fastNlMeansDenoising)。
场景二:表格结构错乱
可能原因:
- 无边框表格
- 跨页表格
- 复杂的合并单元格
工程解决策略:
- 选择正确的工具:对于表格处理,DeepSeek-OCR、AWS Textract等第四代和第二代中的佼佼者,其效果远胜于传统工具。优先选择它们。
- 后处理启发式规则:即使是最好的模型,也可能在复杂表格上犯错。可以编写一些后处理脚本,例如,检测到一个表格在页面底部被截断,并且下一页的开头也是一个表格时,尝试将两者的表头进行比对,如果相似,则进行合并。
- 分而治之:对于超大的表格,可以先用版面分析工具(或bbox信息)将其定位并裁剪出来,然后将这个独立的表格图片送入一个专门为表格优化的OCR模型或服务。
场景三:Token数量依然过多(即使使用DeepSeek-OCR)
可能原因:文档本身是纯文本或排版极其简单,视觉信息熵低。
工程解决策略:
构建动态解析器(Hybrid Parser):这是一个关键的架构模式。不要试图用一种工具解决所有问题。你的DocumentParser服务应该是一个复合策略的实现者。
1 | // 架构思想的Java伪代码 |
这个动态解析器,体现了在成本、效率和质量之间进行智能权衡的架构思想。
结语:解析层的范式转移——从 “数据清洗” 到 “语义预处理”
在本篇中,我们直面了RAG的“阿喀琉斯之踵”——非结构化文档解析。
我们见证了OCR技术从传统的“文字搬运工”,到以DeepSeek-OCR为代表的“第四波浪潮”:一个为LLM量身定做的**“视觉上下文压缩器”**。
我们剖析了DeepSeek-OCR的设计哲学:它不再孤立地“识别”,而是端到端地“理解”和“压缩”,其目标并非服务于人,而是服务于机器(LLM)。我们深入了其“三叉戟”式的Encoder架构和高效的MoE Decoder,理解了其在效果与效率之间达成的精妙平衡,看到了顶尖工程实践的影子。
最重要的是,我们建立了一套可落地的工程方法论:通过具体的JSON输出来感知其价值,通过量化的指标来评估其性能,并通过系统的归因分析和策略来解决它在现实世界中可能遇到的问题。
这场革命的本质,是将解析层从一个被动的、充满妥协的“数据清洗”环节,转变为一个主动的、为下游LLM进行“语义预处理”的战略性步骤。高质量的解析,是后续所有RAG步骤的基石。
至此,我们已经“听懂了问题”,并掌握了将“原始矿石”打磨成“精美玉石”的利器。现在,是时候深入数据处理的核心,探讨如何将这些玉石进一步切割、分类和标记了。
在下一篇章 《知识库的“数据供应链”——从高级Chunking到Table表格处理的深水区》 中,我们将深入“七层模型”的第三层——数据处理层。我们将直面Chunking(分块)这一看似简单却充满陷阱的艺术,并专门探讨“表格”这一信息密度最高、也最难处理的数据类型的应对策略。