RAG篇(4):知识库的“数据供应链”——从高级Chunking到Table表格处理的深水区
导语:RAG的“隐形杀手”——一次糟糕的文本分块(Chunking)
在上一篇章中,我们借助DeepSeek-OCR等前沿工具,成功地将一份格式混乱的PDF“原始矿石”,打磨成了结构清晰、语义保真的“精美玉石”:一份高质量的Markdown或JSON。我们似乎已经解决了RAG流程中最棘手的数据输入问题。
然而,一个更隐蔽、也更致命的挑战,正悄然等待着我们:
想象一下,你拿到了一份完美的、包含章节标题、段落和表格的万字长文。现在,你需要将它“喂”给一个有上下文长度限制(如8K Tokens)的LLM。你无法将整篇文章一次性塞进去。你必须对它进行切分,也就是Chunking。
于是,你采取了最简单、最直观的方法:固定大小分块(Fixed-size Chunking)。你大刀阔斧地将文章每1000个字符切成一段。然后,你惊恐地发现:
一个关键的定义,它的前半句在Chunk A的末尾,后半句在Chunk B的开头。LLM在检索到任何一个Chunk时,都无法获得完整的语义。
一个完整的代码块或一段关键的法律条文,被无情地拦腰斩断。
一个巨大的表格,其表头在Chunk C,数据在Chunk D和E,LLM在检索到数据时,完全不知道这些数字代表什么。
这就是RAG的“隐形杀手”。一次糟糕的文本分块,就像一个拙劣的剪辑师,它会破坏原始文档的语义连贯性,制造大量毫无意义、支离破碎的“信息孤岛”。当你用用户的查询去检索时,很可能只召回了这些“孤岛”中的一个,LLM基于这片残缺的“瓦砾”,自然无法重建出完整的“宫殿”。
Garbage In, Garbage Out. 在RAG的世界里,即使原始文档是黄金,糟糕的分块也会把它变成粪土。
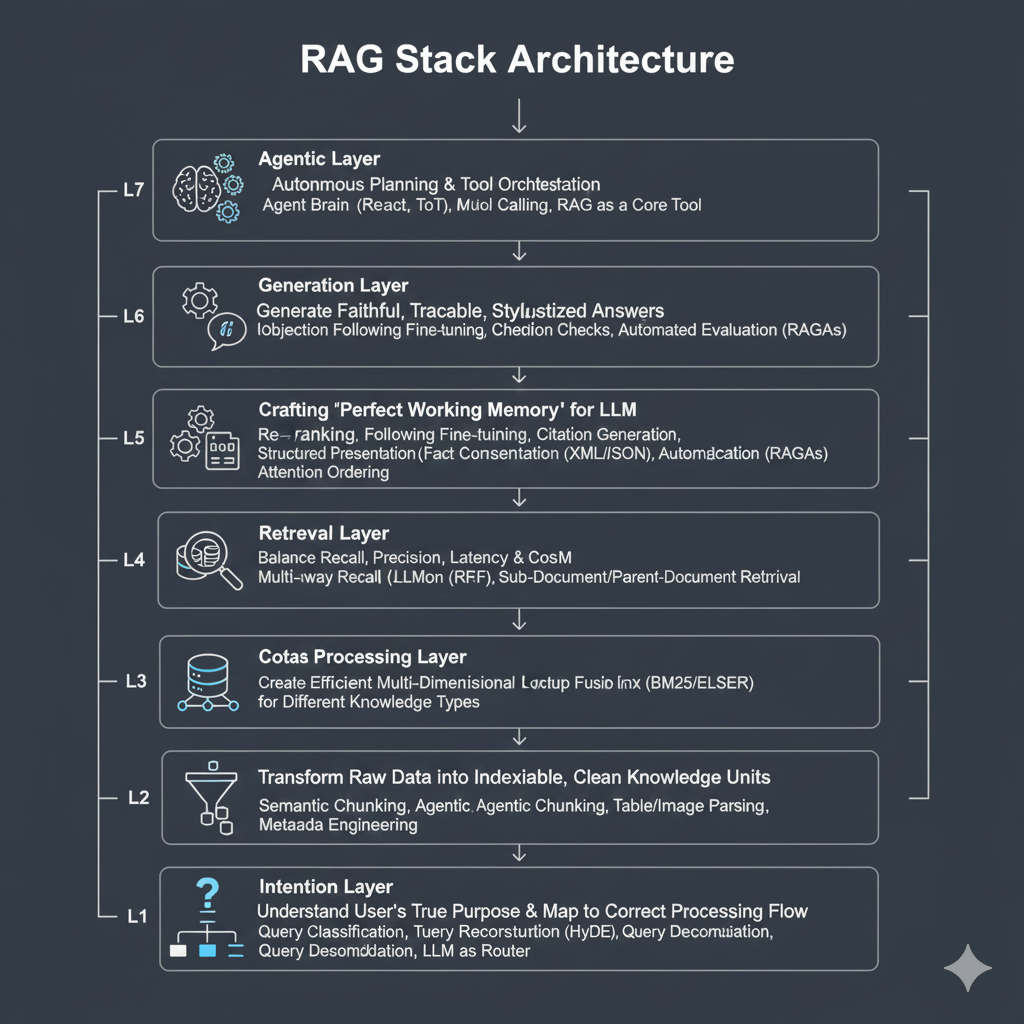
本篇,我们将深入RAG七层架构的第三层——数据处理层。我们将直面Chunking这一看似简单却充满陷阱的艺术。我们将超越简单的“固定大小”切分,探索语义分块(Semantic Chunking)、基于Agent的分块(Agentic Chunking)等高级策略。更重要的是,我们将深入探讨“表格”这一信息密度最高、也最难处理的数据类型的应对之道。
这篇文章将为你构建一个关于知识库“数据供应链”的完整认知框架,让你学会如何像一个专业的数据工程师那样,对你的知识进行精细化、结构化的预处理。这是决定你的RAG系统是“能用”还是“卓越”的分水岭。
第一部分:Chunking的第一性原理:为何必须分块,以及理想分块的“黄金标准”
在深入各种复杂的策略之前,我们必须回归原点,理解两个根本性问题。
1.1 为何必须分块?—来自Embedding模型和LLM的双重约束
分块并非RAG的可选项,而是其成立的必要条件。这源于两大技术约束:
Embedding模型的输入限制与语义焦点:
输入限制:大多数主流的Embedding模型(如BGE、M3E、Jina等)都有一个最大输入序列长度(通常是512或1024个Token)。如果你试图将一个超长的文本块喂给它,模型会进行截断,导致文本末尾的信息完全丢失。
语义焦点:Embedding模型的核心任务是将一个文本块压缩成一个固定维度的向量(如768维)。这个向量是整个文本块的“语义平均值”。如果一个文本块过长,包含了太多无关的主题,其最终生成的向量就会变得“模糊”和“泛化”,无法精确地代表任何一个具体的主题,从而在检索时降低匹配的精确度。
LLM的上下文窗口限制与自身机制以及成本考量:
窗口限制:即使我们拥有了像GPT-4-128K或Claude-200K这样巨大的上下文窗口,它依然是有限的。你无法将整个企业的所有文档都放入上下文中。
成本与延迟:LLM的API调用成本和推理延迟,与输入的Token数量几乎成正比。将一个巨大的、包含大量无关信息的Chunk作为上下文,不仅浪费金钱,还会显著增加用户的等待时间。
注意力“稀释”:如前所述的“中间遗忘”问题,过长的、未经筛选的上下文会稀释LLM的注意力,导致它忽略关键信息。
1.2 理想分块的“黄金标准”—语义完整性与粒度适中
既然必须分块,那么一个“好”的Chunk应该满足什么标准?
语义完整性 (Semantic Integrity):这是最重要的标准。每个Chunk本身应该是一个逻辑上自洽、语义完整的单元。它不应该在句中、段中,或一个完整的逻辑块(如一个函数定义、一个法律条款)的中间被切断。
粒度适中 (Appropriate Granularity):Chunk的大小应该与你期望回答的问题的粒度相匹配。
如果你的问答场景是关于一些非常具体的事实(例如,“函数X的第三个参数是什么?”),那么你的Chunk就应该切得更小,可能小到一个函数或一个段落。
如果你的问答场景是需要对一个章节进行总结,那么你的Chunk就应该更大,可能包含整个章节。
上下文感知 (Context-awareness):一个理想的Chunk,不仅包含其自身的文本,还应该携带足够的上下文信息。这可以通过**重叠(Overlap)或元数据(Metadata)**来实现。
结构保留 (Structure Preservation):分块过程不应破坏原始文档的结构信息。例如,表格应该被视为一个整体,而不是被切成零散的行。
工程启示: Chunking的本质,是在**“保持语义完整性”和“控制块大小以适应模型”这两个相互冲突的目标之间,寻找最佳的平衡点。没有一种“万能”的分块策略,最佳策略总是相对于你的数据类型和应用场景**而言的。架构师的核心工作,就是理解各种策略的权衡,并为你的系统做出明智的选择。
第二部分:Chunking策略的演进:从“蛮力切割”到“智能分割”
Chunking策略的演进,同样遵循着从简单粗暴到精细智能的路径。
2.1 策略一:固定大小分块 (Fixed-size Chunking)

这是最基础、最容易实现的策略,也是大多数框架(如LangChain、LlamaIndex)的默认选项。
- 实现方式:设定一个固定的chunk_size(如1000个字符)和一个chunk_overlap(如200个字符),然后像一个滑动的窗口一样,依次从文本中切割出块。chunk_overlap的作用是提供一些上下文连续性,确保在块的边界处被切断的句子,其另一部分能出现在相邻的块中。
1 | import dev.langchain4j.data.document.Document; |
- 优点:实现简单,计算速度快。
- 致命缺陷:完全忽略文本的语义结构。它就像一个对语言一无所知的屠夫,只按固定的尺寸切割,极大概率会破坏句子的完整性、段落的逻辑性,是造成语义破碎的万恶之源。在生产环境中,应极力避免直接使用这种策略。
2.2 策略二:递归字符分块 (Recursive Character Text Splitting)

这是固定大小分块的一个智能变体,也是LangChain等框架推荐的通用策略。
实现方式:它不再使用单一的分隔符,而是提供一个分隔符列表,按优先级进行递归尝试。
- 首先,尝试用最高优先级的的分隔符(通常是**\n\n**,代表段落)来分割文本。
- 如果分割后的块仍然大于chunk_size,则对这个过大的块,使用次一级的分隔符(如**\n**,代表换行)进行再次分割。
- 如果还大,再用更次一级的分隔符(如。(句号) 或 ,(逗号)代表句子或空格分割。
- 这个过程递归进行,直到所有块都小于chunk_size。
优点:相比固定大小分块,它尽可能地尊重了文本的自然边界(段落、句子),在很大程度上保持了语义的完整性。
局限性:它仍然是一种基于规则和字符的启发式方法,无法真正“理解”文本的逻辑结构。对于没有明显分隔符的文本(如紧凑的法律文件),它会退化成简单的字符分割。
2.3 策略三:语义分块 (Semantic Chunking)

这是一种更前沿、更智能的策略,它试图让分块过程本身具备语义理解能力。
- 核心思想:不再依赖固定的字符数或分隔符,而是根据相邻句子之间的语义相似性来决定切分点。如果一个句子与下一个句子的语义差异突然变大,那么这里很可能是一个新的主题的开始,是一个理想的切分点。
- 实现方式:
- 将整个文档分割成独立的句子。
- 为每个句子计算Embedding向量。
- 遍历所有相邻的句子对(句i,句i+1),计算它们Embedding向量之间的余弦相似度。
- 识别出相似度得分的“拐点”或“低谷”,这些地方就是语义上的分割点。
- 将位于两个分割点之间的所有句子合并成一个Chunk。
- 优点:
- 高度的语义内聚性:每个Chunk都围绕一个核心主题展开,内部的句子高度相关。
- 动态的块大小:块的大小不再是固定的,而是根据内容的自然长度动态变化,有的块可能很长(讨论一个复杂主题),有的可能很短(一个独立的定义)。
- 权衡:
- 计算成本:需要为每个句子计算一次Embedding,对于超长文档,这可能是一个不小的开销。
- 阈值敏感:如何定义“相似度低谷”需要设置一个阈值,这个阈值的选择对分块效果有很大影响,需要实验调优。
2.4 策略四:Agentic分块 (Agentic Chunking)

这是目前最前沿的探索,它将分块的任务,交给了LLM本身。
核心思想:让LLM扮演一个“图书管理员”或“内容摘要师”的角色,去阅读原始文本,并主动地决定如何将其分割成有意义的、自包含的逻辑块。
实现方式 (概念性):
- 将整个文档(或一个大块)作为上下文提供给LLM。
- 在Prompt中给出明确的指令,例如:“你是一个专业的文档分析师。请阅读以下文本,并将其分割成多个独立的、围绕单一主题的JSON对象。每个JSON对象应包含一个summary字段,用一句话概括这个块的核心内容,以及一个content字段,包含该块的完整原文。”
- LLM会返回一个结构化的输出,我们直接将其作为分块结果。
优点:理论上能达到最佳的语义分割效果,因为它利用了LLM强大的上下文理解和推理能力。
巨大挑战:
- 成本与延迟:调用LLM进行分块,成本极高,延迟极长,不适用于大规模的、需要实时索引的场景。
- 稳定性:LLM的输出具有不确定性,可能无法总是遵循你要求的格式。
- 上下文窗口限制:这种方法本身也受限于LLM的上下文窗口,无法一次性处理超长的文档。
架构师思考: 这四种策略代表了从**“规则驱动”到“数据驱动”再到“模型驱动”的演进路径。在实践中,没有银弹。一个健壮的数据处理流水线,应该是混合策略的。例如,先用递归字符分块进行初步的、成本较低的分割,然后对于其中特别重要或特别长的块,再调用语义分块或Agentic分块**进行精细化处理。
第三部分:深水区中的硬骨头:表格处理的挑战与策略

如果说常规文本的Chunking是“困难模式”,那么表格处理就是“地狱模式”。表格是信息密度最高、结构性最强的元素,但也是最容易在分块中被破坏的。
3.1 核心挑战
- 结构丢失:简单的文本分割会完全破坏表格的行列关系,使其变成一堆毫无意义的数字和文本。
- 上下文缺失:即使我们能按行分割表格,单独的一行数据(如**”Apple”, “$2,000B”, “30%”)如果没有表头(“Company”, “Market Cap”, “YoY Growth”)和表格标题(“2023 Tech Giants Performance”**),其语义也是不完整的。
- 巨大的Token消耗:一个中等大小的表格,如果用Markdown格式表示,可能会消耗数千个Token。
3.2 解决方案与策略
在上一章我们讨论了,使用DeepSeek-OCR等工具可以将表格直接解析为Markdown或HTML。在此基础上,我们有以下几种高级处理策略。
策略一:将表格作为一个完整的Chunk
做法:在分块时,将整个Markdown/HTML格式的表格视为一个不可分割的原子单元。
优点:完美地保留了表格的完整结构和所有信息。
缺点:如果表格过大,这个Chunk本身就可能超过LLM或Embedding模型的输入限制。
适用场景:小到中等大小的表格。
策略二:按行分块,并注入上下文
做法:
- 将表格的标题、表头提取出来,作为“共享上下文”。
- 将表格的每一行或每几行作为一个独立的Chunk。
- 在每个“行Chunk”的文本内容前,拼接上共享的“标题和表头”信息。
伪代码:
1
2
3
4
5
6
7
8
9
10String tableTitle = "Table 1: Financial Summary";
String tableHeader = "| Metric | Q1 2023 | Q2 2023 |";
String sharedContext = tableTitle + "\n" + tableHeader;
List<String> rows = List.of("| Revenue | $100M | $110M |", "| Profit | $20M | $22M |");
for (String row : rows) {
String chunkContent = sharedContext + "\n" + row;
// 将chunkContent送去Embedding
}
- 优点:Chunk粒度变小,更利于精确检索。每个Chunk都具备了理解自身所需的最小上下文。
- 缺点:增加了大量的冗余信息(每个Chunk都重复了表头),总的Token数和存储成本会显著增加。
策略三:将表格转换为自然语言描述(Textual Summarization)
- 做法:这是最激进也最智能的方法。在索引阶段,就利用LLM将整个表格“翻译”成一段或多段自然语言描述。
- 示例:“根据财务摘要表,公司在2023年第一季度的收入为1亿美元,利润为2000万美元;在第二季度,收入增长到1.1亿美元,利润增长到2200万美元。”
- 优点:
- 语义丰富:自然语言描述比结构化的表格更接近人类的提问方式,可能更容易被向量检索匹配到。
- 高度压缩:LLM的总结能力可以显著减少Token消耗。
- 缺点:
- 信息损失风险:LLM的总结过程必然是有损的,可能会遗漏某些细节或精确的数字。
- 索引成本高:需要在索引阶段就调用LLM,成本较高。
架构师权衡: 面对表格,最佳实践往往是混合索引(Hybrid Indexing)。
为整个表格创建一个摘要Chunk(策略三),用于捕捉宏观语义,回答总结性问题。
为表格的每一行(或逻辑相关的几行)创建一个带上下文的行Chunk(策略二),用于精确查找特定数据点。
甚至可以为整个表格的Markdown原文创建一个完整Chunk(策略一),作为最终生成答案时提供给LLM的“黄金上下文”。
在检索时,可以并行地从这几种不同类型的Chunk中进行检索,然后将结果融合,送给LLM。这最大化了信息检索的全面性和精确性。
结语:数据处理,RAG系统的“数据中台”

在本篇中,我们深入了RAG系统的“数据供应链”核心——数据处理层。我们意识到,Chunking远非简单的文本切割,它是一门在语义完整性与粒度适中性之间寻找平衡的艺术。
我们系统性地梳理了从固定大小分块的“蛮力切割”,到递归字符分块的“规则优化”,再到语义分块和Agentic分块的“智能分割”的演进路径。
我们直面了表格处理这一“地狱级”的挑战,并探索了完整分块、按行注入上下文、LLM总结以及最终的混合索引等多种高级实战策略。
一个健壮的数据处理流水线,应该像一个现代化的“数据中台”,它能够根据不同的数据源(文本、表格)和不同的应用场景,动态地采用最合适的处理策略。它产出的不再是零散的数据片段,而是富含元数据、语义内聚、结构清晰的“知识资产”。
至此,我们已经拥有了高质量的、可供检索的知识单元。下一步,我们将进入RAG系统的心脏地带——索引与检索。如何为这些“知识资产”建立高效的索引?如何从亿万个Chunk中,在毫秒之间精准地找到用户需要的那几个?
在下一篇章 《深入Milvus:从Embedding微调到HNSW索引调优,构建企业级分布式稠密向量检索系统》 中,我们将深入“七层模型”的第四和第五层,聚焦于稠密向量检索。我们将从Embedding模型的选型与微调开始,深入探索向量数据库Milvus的架构核心,并揭示HNSW索引参数调优背后不为人知的秘密。这将是一场关于“速度”与“精度”的极限探索。