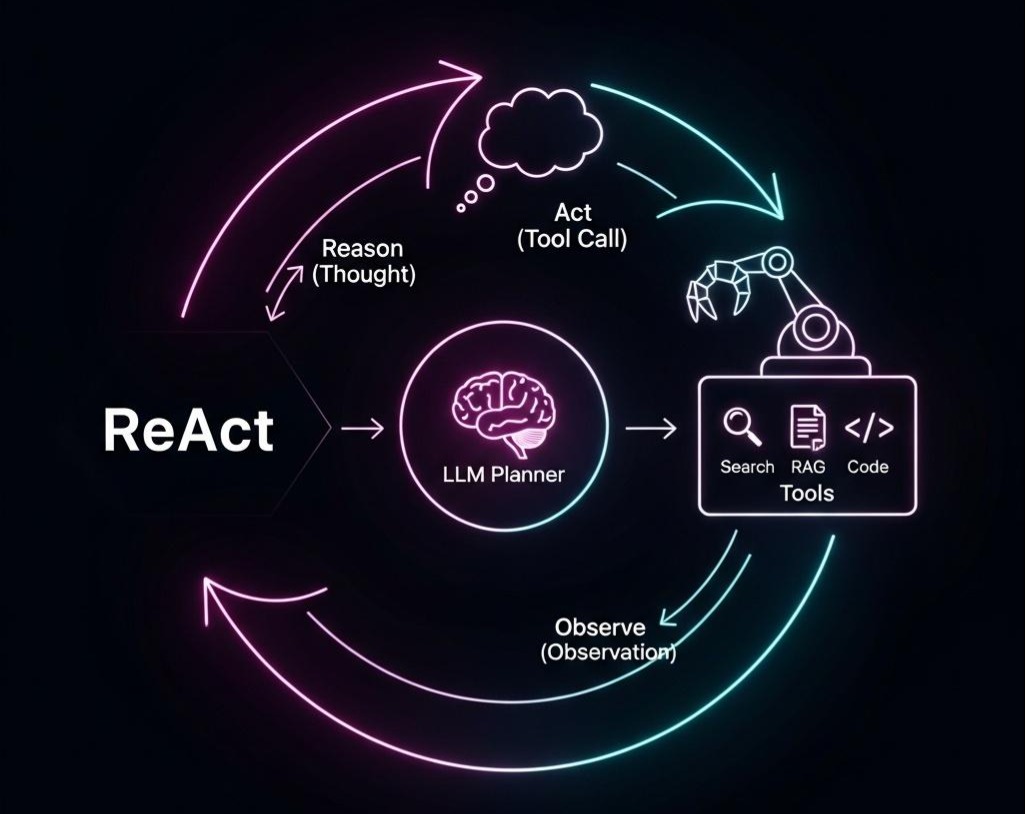
RAG篇(5):深入Milvus:从Embedding微调到HNSW索引调优,构建企业级分布式稠密向量检索系统

导语:RAG的“引擎轰鸣”——当毫秒级的响应成为生死线
在前面的篇章里,我们已经像精密的工匠一样,完成了知识的“原料”准备。我们学会了如何听懂用户的真实意图,如何将混乱的PDF通过OCR解析为结构化的“玉石”,以及如何将这些玉石切割成语义完整的“知识单元”(Chunks)。我们的数据供应链已经就绪。
现在,我们面临一个更具速度与激情挑战的环节:检索。
想象一下这个场景:在一个高并发的在线问答系统中,用户的每一次提问,都要求你在毫秒之内,从一个可能包含数千万甚至数十亿个知识单元的巨大“仓库”中,精准地找到最相关的那几条信息。
任何超过200毫秒的检索延迟,都会让用户感受到明显的卡顿,直接扼杀用户体验。
任何一次错误的召回(召回了不相关的Chunk),都会导致下游的LLM产生“一本正经的胡说八道”,让系统的可靠性荡然无存。
这就是RAG系统的“引擎室”——向量检索系统。它的性能,直接决定了你的AI应用是风驰电掣的“超级跑车”,还是停在原地无法启动的“老爷车”。在这个战场上,我们手中的核心武器,就是Embedding模型和向量数据库。然而,90%的开发者对它们的使用,都停留在一种“黑盒”式的调用:embeddingModel.embed(text),vectorStore.similaritySearch(query)。他们满足于默认的Embedding模型,满足于向量数据库“开箱即用”的配置。这种做法,在小规模的Demo中或许可行,但在企业级的生产环境中,却隐藏着巨大的性能瓶颈和精度陷阱。
本篇,我们将深入RAG七层架构的第四和第五层(索引与检索),聚焦于稠密向量检索这一核心技术。我们将扮演一名“性能工程师”和“数据库内核专家”,深入业界领先的开源向量数据库Milvus。我们将直面并解决两个终极问题:
- 精度问题: 如何超越“通用”Embedding模型,通过微调,让它真正“理解”你所在领域的专业术语?
- 性能问题: 如何洞穿Milvus的架构,通过对HNSW索引等核心参数的精细调优,实现检索性能的极限压榨?
这不再是关于“用什么”的讨论,而是关于**“如何用到极致”**的、属于顶尖AI架构师的进阶之战。让我们启动引擎,感受向量检索的速度与激情。
第一部分:Embedding的“道”与“术”-攻克语义鸿沟的精度之战
向量检索的起点,也是其质量的上限,都取决于Embedding模型的质量。一个错误的向量表示,再强大的数据库也无力回天。
1.1 从“文字狱”到“语义场”:为何必须拥抱向量?
让我们先回到问题的原点。传统的数据库(如MySQL)或搜索引擎(如Elasticsearch的早期版本),它们的世界是建立在“文字匹配”的基础上的。

一个真实的困境: 假设你在电商平台卖一款“冰丝速干裤”。用户搜索的是**“夏天穿的凉快裤子”**。
- MySQL的窘境: SELECT * FROM products WHERE name LIKE ‘%夏天%’ AND name LIKE ‘%凉快%’ AND name LIKE ‘%裤子%’; 结果是0。因为你的商品名里没有这些确切的词。
- 传统搜索引擎的挣扎: 也许它能通过分词,匹配到“裤子”,但“夏天”和“凉快”的语义,它无法理解。在它看来,“冰丝”和“夏天”是两个毫无关联的字符串。
这就是传统技术的**“语义鸿沟”**。它陷入了一场“文字狱”:只有字面上存在关联,才能被检索。
向量的破局之道: 向量技术,或者说Embedding,实现了一次彻底的范式革命。它不再关心文本的“字面”,而是捕捉其“意义”。
它通过一个深度学习模型,将任何一段文本,映射到一个高维度的数学空间(比如768维)中的一个具体坐标点。这个坐标点,就是文本的**“语义坐标”**,即向量。
- “冰丝速干裤” → [0.12, -0.45, 0.88, …]
- “夏天穿的凉快裤子” → [0.15, -0.41, 0.85, …]
- “羽绒服” → [-0.76, 0.53, -0.21, …]
在这个空间里,语义相近的文本,它们的坐标点就彼此靠近;语义无关的,则相互远离。
检索,从“字符串匹配”变成了“寻找空间中最近的邻居”。
现在,系统能够理解“冰丝”就意味着“凉快”和“适合夏天”,从而精准地召回你的商品。
我们从一场必败的“文字狱”,进入了一个可以计算“意义”远近的“语义场”。这就是我们必须拥抱向量的根本原因。
1.2 Embedding的“道”:从MTEB榜单看模型选型哲学
- MTEB是什么? 它是一个全面的、多任务的文本嵌入模型评测基准,涵盖了分类、聚类、检索、重排序等多种任务,是目前评估Embedding模型综合能力最权威的参考。
- 选型哲学:
- 拒绝“唯分数论”: 榜单上的Top 1模型,不一定就是最适合你的。你需要关注的是与你任务最相关的子榜单。对于RAG应用,我们最应该关注的是**“Retrieval”**榜单的平均分。
- 平衡“效果”与“成本”: 一个7B参数的Embedding模型,效果可能比一个700M参数的模型好5%,但其推理延迟和部署成本可能是后者的10倍。在资源有限的情况下,选择一个性价比最高的模型(如BGE-M3, Jina-embeddings-v2等在各自量级中的佼佼者)是更明智的决策。
- 关注“多语言”与“上下文长度”: 如果你的知识库包含多种语言,或者你的Chunk长度较长,你需要选择一个明确支持多语言或长上下文(如8K)的模型。
1.3 Embedding的“术”:何时以及如何微调(Fine-tuning)?
“通用”的Embedding模型是在海量的通用语料(如维基百科、网页)上预训练的,它们能理解通用语言,但对于你所在领域的“黑话”(如金融领域的“alpha”、“beta”,医学领域的“免疫检查点抑制剂”)可能理解不足。

何时需要微调?
- 信号一:低召回率。 当你发现,对于一些包含领域术语的查询,RAG系统总是无法召回最相关的文档时,这很可能就是Embedding模型“听不懂”你的黑话。
- 信号二:语义混淆。 当你发现模型将两个在你的领域内含义截然不同、但字面相似的词映射到了相近的向量空间时。
如何微调?—构建高质量的“三元组”数据集
微调Embedding模型,最核心的工作是构建一个高质量的训练数据集。
最常见、最有效的数据格式是**“三元组”(Triplets):(anchor, positive, negative)**。
- Anchor:一个查询或一个文档片段。
- Positive:与Anchor语义高度相关的一个文档片段。
- Negative:与Anchor语义不相关的一个文档片段。
微调的目标: 通过训练,让模型学会拉近anchor和positive在向量空间中的距离,同时推远anchor和negative的距离。这通常通过TripletLoss损失函数来实现。
高质量三元组的来源:
- 从业务日志中挖掘: 如果你有用户的搜索日志,那么“用户点击并停留时间长的结果”可以作为positive,“用户直接跳过的结果”可以作为negative。
- 利用LLM生成: 对于一个文档Chunk(作为anchor),可以利用GPT-4等强大的LLM来:生成一个非常匹配这个Chunk的问题(作为positive query)。 生成一个看似相关但实际错误的**“硬负例”(Hard Negative)**,这是提升模型辨别能力的关键。
- 人工标注: 成本最高,但质量也最高。由领域专家来判断文档之间的相关性。
架构师思考: Embedding微调是一项高杠杆的投入。它不是一个常规操作,而是一项战略性投资。在RAG项目的中后期,当其他优化手段(如Chunking策略、重排序)都已用到极致时,通过微调来提升Embedding的“领域认知”,往往是突破精度瓶颈的最后、也是最有效的一招。
第二部分:实战核心痛点-系统性排查与解决“低分值”难题
这是每个RAG开发者都会遇到的“绝望时刻”。你确信知识库里有答案,用户提的问题也直截了当,但召回结果的相似度得分却低得离谱,甚至根本召不回。本章将提供一个完整的、包含可运行Java代码的系统性解决方案。
2.1 问题复现:一个真实且完整的Java代码案例
我们将用一段完整的Java代码来复现这个痛点。下面的程序将:
- 连接到一个本地Milvus实例。
- 使用DJL(Deep Java Library)在Java环境中直接加载一个通用的HuggingFace Embedding模型(bge-small-zh-v1.5)。
- 插入几条关于金融的文本。
- 演示一个“失败”的查询—明明有答案,分值却很低。
前置条件:
- Java环境: JDK 11或更高版本。
- Maven项目: 在你的pom.xml中加入依赖。
- Milvus服务: 确保你已经通过Docker启动了一个Milvus实例。
完整可运行的Java类 (LowScoreProblemDemo.java):
1 | import ai.djl.ModelException; |
运行结果分析:
当你运行此Java程序,你会清晰地看到,对于查询**“这只股票的贝塔系数是多少?”,召回的第一条结果很可能不是那条包含beta为1.2的文档,或者即使是,其distance值也相对较大(相似度低)。而对于“这只股票的市场风险敞口(beta)是多少?”这个查询,它会以一个非常小的distance**值(高相似度)精准命中正确文档。
这就是我们的核心痛点:模型的“领域盲区”。
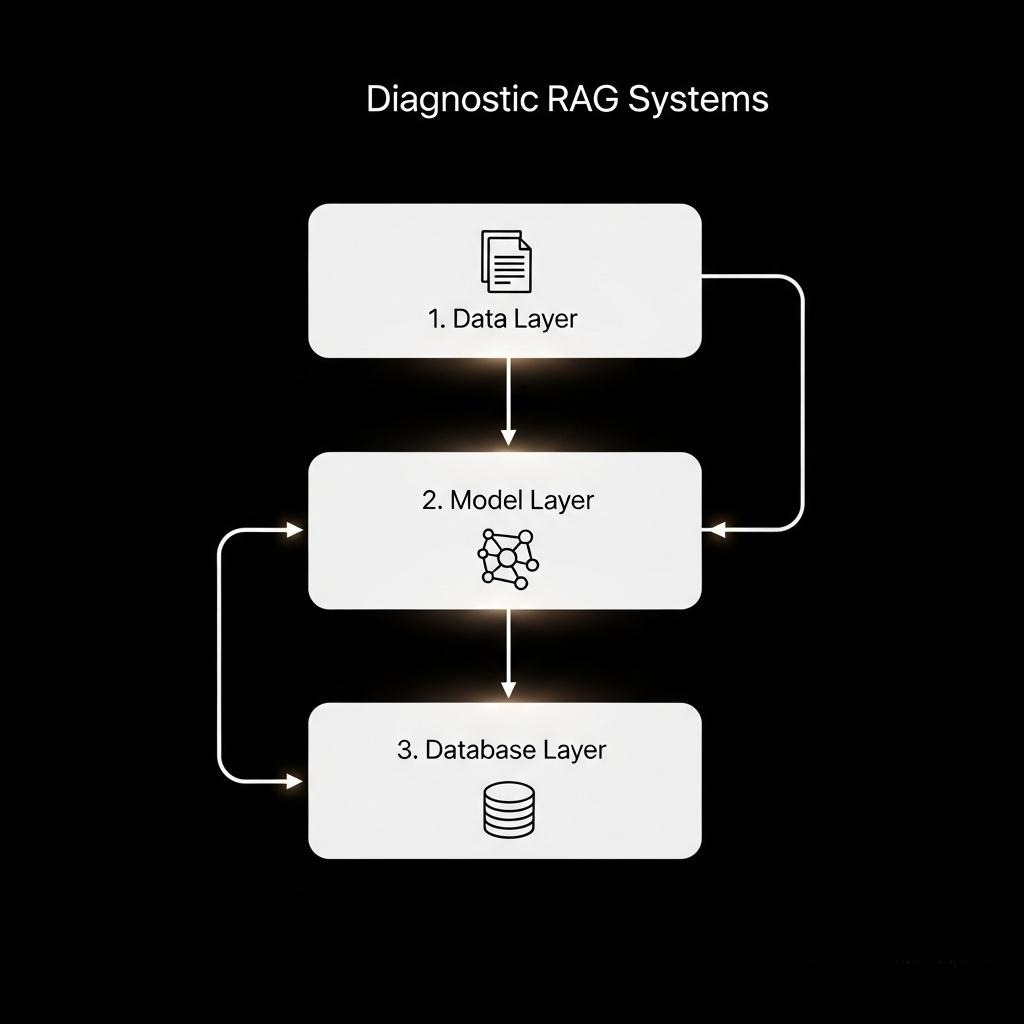
2.2 系统性排查与解决方案:一个Java架构师的诊断流程
面对上述问题,一个经验丰富的Java架构师会遵循一个清晰的诊断流程,从上到下排查问题。
第一阶段:数据层诊断 (Data Layer Investigation)
这是最基础也最容易被忽略的。在将数据喂给模型之前,先确保“食材”是干净的。
检查分块(Chunking)策略:
问题: 你的分块算法是否粗暴地从句子中间或一个关键术语中间切断了文本?
诊断: 随机抽取一些知识库中的源文档及其生成的Chunks,人工检查是否存在“断章取义”的情况。
解决方案: 采用按句子、按段落,或者使用更智能的、基于语义的分割方法。在Java生态中,可以考虑使用如Apache OpenNLP等库进行句子检测来辅助分块。
检查数据清洗(Data Cleaning):
问题: 文本中是否包含大量无意义的噪声,如HTML标签、Markdown标记、多余的换行符和空格、OCR识别错误等?
诊断: 检查你的数据预处理管道,确保有严格的清洗步骤。
解决方案: 在Java中,可以使用正则表达式或Jsoup等库,在文本嵌入之前,进行彻底的清洗。
第二阶段:模型层诊断 (Model Layer Investigation)
如果数据层没有问题,那么90%的概率问题出在模型本身。
战术级修复:查询重写/扩展 (Query Rewriting/Expansion)
适用场景: 需要快速上线、来不及微调模型的紧急情况。
核心思想: 既然模型听不懂用户的“人话”,那就在检索前,把“人话”翻译成模型能听懂的“机器话”。
Java实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31// 伪代码 - 在search方法中增加
// 引入OpenAI Java SDK或一个HTTP Client
// import com.theokanning.openai.service.OpenAiService;
private String rewriteQueryWithLLM(String originalQuery) {
// final String OPENAI_API_KEY = "YOUR_API_KEY";
// OpenAiService service = new OpenAiService(OPENAI_API_KEY);
String prompt = "你是一个金融领域的专家。请将以下用户提问,改写或扩展成一个更专业、更可能在专业研报中出现的查询。\n" +
"用户提问:" + originalQuery + "\n" +
"改写后的查询:";
// CreateCompletionRequest completionRequest = CreateCompletionRequest.builder()
// .model("text-davinci-003") // or newer models
// .prompt(prompt)
// .maxTokens(60)
// .build();
// String expandedQuery = service.createCompletion(completionRequest).getChoices().get(0).getText().trim();
// 模拟返回
String expandedQuery = originalQuery;
if (originalQuery.contains("贝塔系数")) {
expandedQuery = originalQuery + " 或 市场风险敞口(beta)";
}
System.out.println("原始查询: '" + originalQuery + "' -> 扩展查询: '" + expandedQuery + "'");
return expandedQuery;
}
// 在search方法的开头调用
// String finalQuery = rewriteQueryWithLLM(queryText);
// ...然后用 finalQuery 进行 embedding 和搜索优缺点: 见效快,但增加了额外的LLM调用成本和延迟,且效果依赖于Prompt和LLM的能力,治标不治本。
战略级修复:模型微调 (Fine-tuning)
适用场景: 追求极致精度、希望从根本上解决问题的长期项目。
核心思想: 与其绕开问题,不如直接“教会”模型。用我们领域的专业数据,去重塑它的向量空间。
Java世界的现实:模型微调通常在Python生态中完成。 Java应用的角色是消费微调后的模型。
工作流:
ML团队(Python端):
构建三元组数据集: 这是最核心的工作。
1
2
3
4
5
6
7[
{
"anchor": "这只股票的贝塔系数是多少?",
"positive": "我们测算,该标的在过去一年的市场风险敞口(beta)为1.2...",
"negative": "公司的alpha收益(超额收益)主要来源于其卓越的成本控制能力..."
}
]使用sentence-transformers进行微调,并将模型保存到本地或上传到Hugging Face Hub。
1
model.save('path/to/my-finetuned-bge-model')
Java应用端:
无缝切换: 只需修改一行代码,将EMBEDDING_MODEL_URL指向新的模型路径。
1
2
3private static final String EMBEDDING_MODEL_URL = "path/to/my-finetuned-bge-model";
// 或者如果是私有Hugging Face Hub
private static final String EMBEDDING_MODEL_URL = "djl://ai.djl.huggingface.pytorch/YourHFUsername/my-finetuned-bge-model";重新运行LowScoreProblemDemo.java,你会发现,现在即使是通俗的查询,也能获得极高的相似度得分。
优缺点: 一劳永逸,从根本上提升精度。但需要投入数据标注和模型训练的资源,并涉及Python和Java团队的协作。
第三阶段:数据库层诊断 (Database Layer Investigation)
如果在微调模型后,通过简单的向量计算(如本地计算余弦相似度)发现查询和目标文档的相似度很高,但在Milvus中召回时排名依然靠后或找不到,那问题就在数据库的检索参数上。
- 问题根源: ef参数设置过低。ef控制了HNSW在搜索时的“探索广度”。ef太低,意味着搜索算法非常“短视”,可能在图的早期导航中就走上了一条错误的岔路,从而“完美地”错过了真正最近邻所在的区域。
- 诊断与解决方案: 在SearchParam中,逐步增大ef的值(如从64 -> 128 -> 256),观察召回结果的变化。如果随着ef增大,正确的文档出现了,并排名上升,那就证明了是搜索广度不足的问题。我们将在第四部分详细探讨ef与其他参数的权衡。
第三部分:分布式向量数据库的架构演进与核心差异
选择了合适的Embedding模型后,我们需要一个能够承载海量向量、并提供高性能查询的“仓库”。那么Milvus集群方式和我们熟知的Mysql或者Redis集群有何异同呢?答案,藏在一部波澜壮阔的分布式系统演进史中。
3.1 从单体到集群:AKF扩展立方体的启示与局限
让我们从最经典的**AKF扩展立方体(Scale Cube)**理论出发,来审视一个系统是如何变“大”的。

第一阶段 - X轴扩展 (水平复制/克隆):
- 架构模式:主备(Active-Passive)或双活(Active-Active)。 这是最简单的扩展方式。你将单体应用服务器完整地复制多份,部署在不同机器上,前面挂一个负载均衡器。
- 解决了什么: 提高了系统的吞吐量和高可用性。一台机器挂了,负载均衡器会自动将流量切到另一台。
- 留下了什么问题:
- 数据全量冗余: 每个节点都持有全量数据。如果数据量是1TB,那么10个节点就需要10TB的存储,资源浪费严重。
- 容量瓶颈: 后端的数据库本身还是单点,它的容量和写入性能是整个系统的天花板。
第二阶段 - Y轴扩展 (功能分解/服务化):
- 架构模式:读写分离(Read-Write Splitting)。 按职责,将数据库的操作拆分。最典型的就是MySQL的主从复制(Master-Slave Replication)。
- 工作原理: 写操作全部走主库(Master),主库通过binlog将数据变更同步到多个从库(Slave)。读操作则可以分摊到多个从库上。
- 高可用保障: 为了解决Master单点故障,引入了哨兵(Sentinel)机制(在Redis中)或MHA/Orchestrator(在MySQL中),用于监控Master状态,并在其宕机时自动执行主从切换。
- 解决了什么: 极大地提高了系统的读性能。
- 留下了什么问题:
- 写瓶颈: 主库仍然是唯一的写入点,写入压力依然存在。
- 容量天花板: 主库的存储容量依然是整个系统的上限。当单表数据达到几十亿行时,主库的磁盘和内存都将不堪重负。
第三阶段 - Z轴扩展 (数据分区/分片):
架构模式:分片(Sharding)。 这是解决容量问题的终极手段。将数据按某个规则(如用户ID哈希)水平切分到多个不同的数据库实例(分片)上。
实现方式:
- MySQL: 引入分库分表中间件(如MyCAT, ShardingSphere)。中间件根据你定义的shard_key,自动将SQL路由到正确的分片上。
- Redis: 采用官方的Cluster模式,数据被分散在16384个哈希槽(slots)中,每个节点负责一部分槽。
解决了什么: 彻底解决了容量和写入瓶颈问题。理论上可以无限水平扩展。
3.2 向量检索的“特殊性”:传统Z轴扩展的崩溃
现在,问题来了。当我们把Z轴扩展的成熟思想,套用到向量检索上时,会发现它瞬间失灵了。
- MySQL分库分表的窘境: 它的核心是shard_key。UPDATE users SET … WHERE user_id = 123,中间件知道123这个用户在3号分片,于是将请求只发给3号分片。但向量检索没有shard_key! 一个查询向量,它的最近邻可能分布在任何一个分片上。你必须把查询请求广播(Scatter)到所有分片,等待所有分片返回各自的Top-K结果,然后再在中间件层面进行聚合排序(Gather)。传统的MySQL中间件,并非为这种重量级的“Scatter-Gather”模式而设计。
- Redis Cluster的窘境: Redis的设计哲学是极致的“快”,其单线程事件循环模型非常适合处理海量的、O(1)复杂度的轻量级操作。但向量检索(即使是O(logN)的HNSW)是一次重度的CPU计算。在一个Redis节点上执行一次需要消耗几十毫秒的向量搜索,会阻塞整个事件循环,导致该节点上成千上万个其他的轻量级请求被延迟,引发“雪崩”。这违背了Redis的立身之本。
结论: 一个真正的分布式向量数据库,必须在架构层面原生解决两个核心矛盾:
为“Scatter-Gather”模式而生的查询协调机制。
将“重计算负载”与“I/O负载”进行彻底的物理隔离。
3.3 Milvus的架构:为解决矛盾而生的新范式
Milvus的架构,正是上述矛盾的完美答案。它不是凭空设计的,而是分布式系统演进到向量检索时代,合乎逻辑的必然产物。
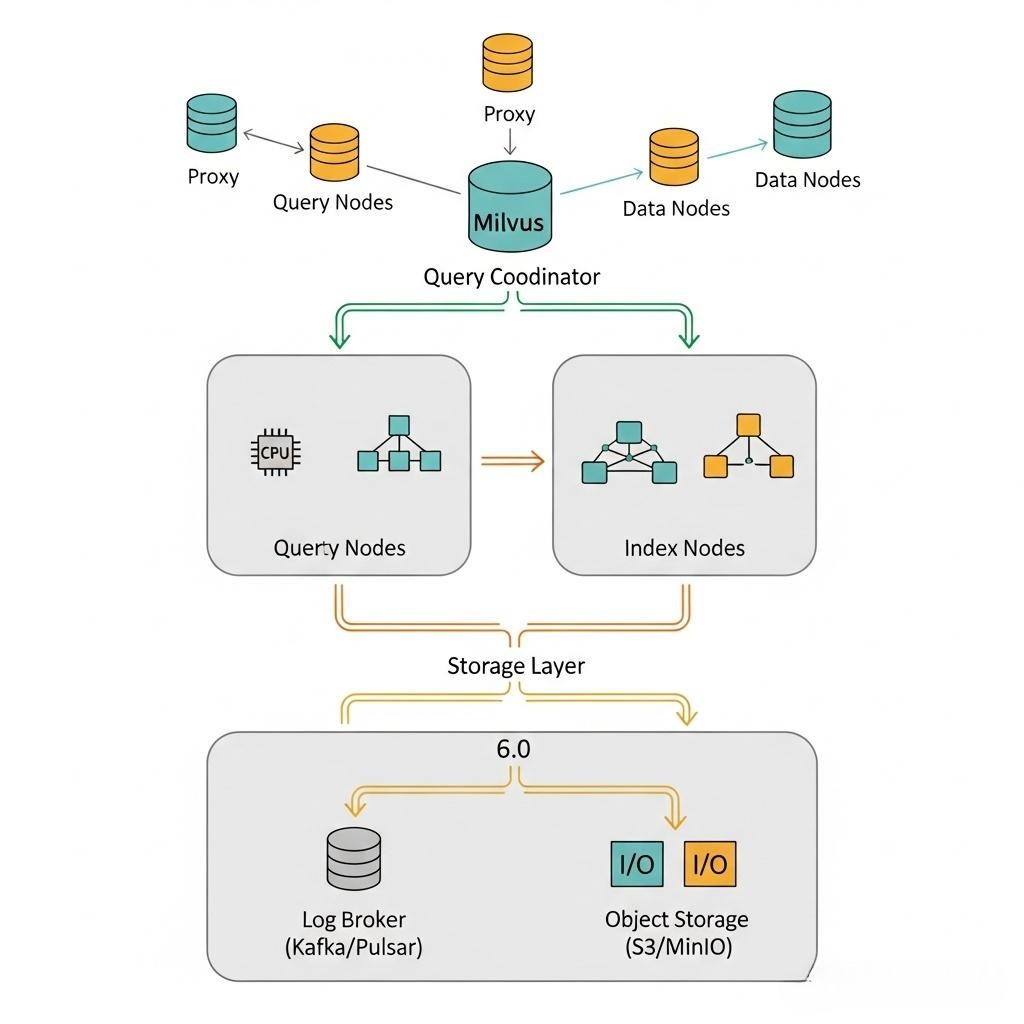
- Proxy + Query Coordinator: 这两个组件组合起来,就是那个为“Scatter-Gather”而生的强大查询协调器。Proxy负责接入,QueryCoord负责管理分片信息,并将查询广播给所有相关的Query Node,最后对结果进行聚合。
- Query Node vs. Data Node/Index Node: 这就是对Y轴功能分解思想的极致应用。Query Node是纯粹的计算节点,只负责在内存中执行CPU密集的搜索。Data Node是I/O节点,负责吞吐数据流。Index Node是后台计算节点,负责索引构建。三者物理隔离,互不干扰,这个思想可以解决了Redis的“重计算污染”问题。
- Log Broker (Pulsar/Kafka) + 对象存储 (S3/MinIO): 这是其“存算分离”的基石。所有的数据变更先写入不可变的日志系统,保证了可靠性。数据和索引的本体,最终躺在廉价、高可用的对象存储里。计算节点(Query/Index Node)是无状态的(相对于持久化数据而言),可以随时按需弹性伸缩。
现在,你应该能感受到Milvus架构的精妙之处。它不是简单的微服务堆砌,而是对分布式系统核心矛盾的深刻洞察和优雅回应。
3.4 主流向量数据库的核心差异
| 特性/数据库 | Milvus (CNCF毕业) | Pinecone (商业闭源) | Weaviate (开源) | Qdrant (开源, Rust) |
|---|---|---|---|---|
| 架构哲学 | 云原生微服务,存算分离 | Serverless,黑盒托管 | 单体或微服务可选,应用驱动 | 性能优先,内存优化 |
| 核心差异 | 专为大规模、私有化部署设计,极致的弹性与组件解耦。 | 极致的易用性(Serverless),用户无需关心底层架构,按用量付费。 | 内置数据模块(如文本、图片),提供GraphQL API,对应用开发者友好。 | 基于Rust,追求极致的单机性能和内存效率,支持磁盘量化索引,成本效益高。 |
| 最佳场景 | 需要私有化部署、数据量巨大、对弹性要求高的企业级场景。 | 追求快速上线、开发效率、希望将运维外包的中小企业和初创团队。 | 构建完整的语义搜索应用,希望数据库能处理部分数据转化工作的场景。 | 资源受限环境(如边缘计算),或对性能和成本极度敏感的场景。 |
第四部分:HNSW索引调优-在“精度”与“速度”之间走钢丝

4.1 HNSW的第一性原理:高维空间中的“智能导航”
想象一下,在一个有十亿人口的巨大城市里找一个人。
暴力搜索(Flat索引): 相当于你拿着照片,挨家挨户地敲门比对。这在数学上是**O(N)**的复杂度,是不可接受的。
HNSW索引的智慧: 它不像你一样在地面上走,而是建立了一个“多层立体交通网”。
分层图结构:
顶层(比如第3层): 是城市的“航空网”,只连接了几个相距很远的交通枢纽(比如北京、上海、广州)。
中间层(第2、1层): 是“高铁网”和“高速公路网”,连接了更多的主要城市和区域中心。
底层(第0层): 是城市的“地面路网”,连接了所有的街道和门牌号,极其密集。
贪婪搜索过程:
你的查询(目标人物的照片)从顶层的一个随机入口点(比如北京)开始。
在北京,你问离目标最近的下一个航空枢纽是哪里?答案是上海。你立刻飞到上海。
在上海,你发现航空网上没有更近的枢纽了。于是你“下沉”到高铁网。
在高铁网上,你从上海出发,找到了最近的高铁站是杭州。
这个过程不断重复,你从航空网->高铁网->高速公路->地面路网,一步步地逼近你的目标,最终在底层找到那个最相似的人。
HNSW正是利用这种从宏观到微观的逐级逼近思想,将搜索的复杂度从O(N)奇迹般地降低到了O(logN)。
4.2 魔鬼在细节:HNSW三大核心参数的深度解析
HNSW的性能和精度,由三个“魔鬼参数”共同决定。调优它们,就是在“精度”、“延迟”和“成本”之间进行一场精密的博弈。
M (Max Connections per Node) - 路网密度
含义: 在构建索引时,每个节点最多可以连接多少个邻居。
影响: M值越高,图的连接越密集,“路网”越发达,从A到B的路径选择就越多,查询时“走错路”的概率就越低,召回率(精度)越高。但同时,索引占用的内存也越大,构建索引的时间也越长。
调优建议: M通常取值在16到64之间。这是一个一次性的构建成本投资,用于换取更高的查询质量上限。对于需要高精度的场景,可以从32开始尝试。
efConstruction (Ef for Construction) - 修路工的视野
含义: 在构建索引时,为每个新加入的节点寻找邻居的过程中,动态维护的候选列表的大小。
影响: efConstruction值越高,“修路工”的“视野”就越开阔,越有可能为新节点找到“真正”的最佳邻居,从而构建出更高质量的“高速公路网”。这会直接提升最终的查询召回率。但代价是索引构建时间会显著增加。
调优建议: efConstruction通常设置为M的数倍,例如100到500。如果你的应用对索引构建时间不敏感(例如可以离线构建),那么适当提高efConstruction是提升最终查询质量的好方法。
ef (or search_k) - 查询时的探索广度
含义: 在查询时,动态维护的候选列表的大小。它与efConstruction类似,但作用于查询阶段。
影响: ef值越高,搜索过程越“详尽”,越不容易错过真正的最近邻,召回率越高,但访问的节点更多,查询延迟也越高。
调优建议: 这是延迟与精度最直接的权衡杠杆。ef的值必须大于等于你想要的top_k。一个常见的起点是,如果你需要top_k=10,可以将ef设置为32或64。然后通过压测,找到在你的SLA(服务等级协议)要求下,能够达到的最高ef值,从而在延迟和精度之间取得最佳平衡。
架构师的最终权衡: HNSW的调优,是一场经典的**“精度-延迟-成本”**三体博弈。
- 追求极致精度? -> 提高M, efConstruction, ef,并准备好为此支付更高的内存成本和查询延迟。
- 追求极致低延迟? -> 降低M和ef,但必须接受召回率可能下降的风险,并建立起监控机制来度量这种下降。
- 没有银弹。最佳的参数组合,永远来自于针对你的数据集和业务场景的、严谨的、量化的A/B测试。
结语:从“能用”到“精通”,向量检索的工程深度

在本篇中,我们完成了一次从理论演进到架构实践的深度穿越。我们不再满足于对Embedding和向量数据库的“黑盒”调用,而是深入其内部,追求极致的精度与性能。
- 我们从分布式系统演进的第一性原理(AKF)出发,推导出了传统架构在向量检索时代的必然困境,并由此揭示了Milvus云原生架构设计的精妙与必然。
- 我们直面了实践中最痛苦的**“低分值”难题**,并给出了一套从数据、到模型、再到数据库的系统性排查和解决方案,甚至附上了可直接运行的Java复现代码。
- 最重要的是,我们揭开了HNSW索引的神秘面纱,洞悉了M, efConstruction, ef这三大核心参数如何像三体问题一样,共同决定了向量检索在精度、延迟和成本之间的最终平衡点。
精通向量检索,是区分普通AI应用开发者与资深AI系统架构师的关键能力。它要求我们具备跨领域的知识:从深度学习(Embedding),到分布式系统(Milvus架构),再到底层算法(HNSW)。
然而,稠密向量检索并非万能。它在捕捉语义相似性上表现出色,但在处理精确的关键词匹配、专业术语或代码片段时,却常常“词不达意”。
在下一篇章 《Elasticsearch的复兴:从BM25到ELSER,构建稀疏-稠密混合检索的“第二大脑”》 中,我们将为我们的RAG系统装上“第二大脑”。我们将回归经典的稀疏向量检索,探索BM25算法的智慧,并见证Elasticsearch如何通过ELSER等新技术,让这种古老的智慧在AI时代焕发新生。我们将学习如何构建一个混合检索系统,将稠密向量的“懂你”与稀疏向量的“精准”完美结合。