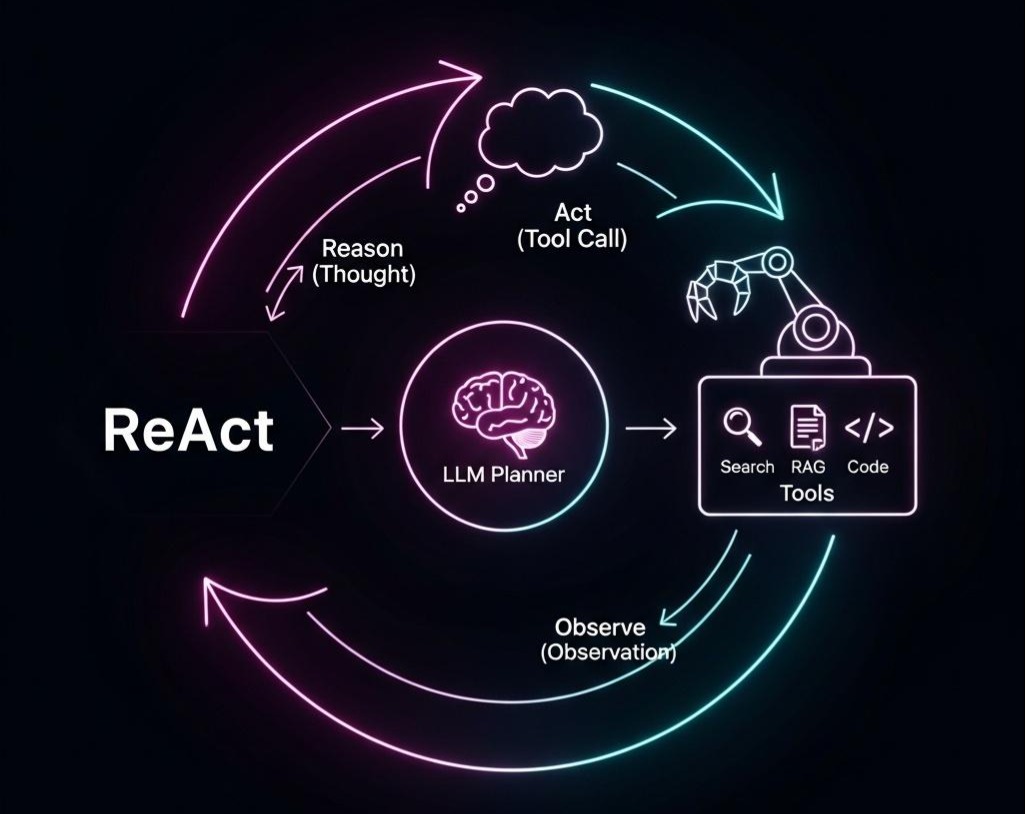
RAG篇(6):Elasticsearch的复兴:从BM25到ELSER,构建稀疏-稠密混合检索的“第二大脑”

导语:当向量检索“词不达意”时,谁来拯救你的RAG?
在上一篇章中,我们深入了Milvus的引擎室,驯服了HNSW这头性能猛兽,构建了一个强大的稠密向量检索系统。我们似乎已经拥有了捕捉“语义”的最强武器。我们的RAG系统能够理解“盈利能力”和“净利润率”之间的关联,这无疑是一次巨大的飞跃。
然而,当你将这个看似完美的系统应用于更广泛、更真实的业务场景时,新的、令人困惑的问题开始浮现:
- 一位开发者在内部知识库中搜索一个特定的函数名 calculate_mrr_for_churned_users,结果返回的却是大量关于“用户流失分析”、“MRR计算方法”的通用文档,而包含那个精确函数定义的文档却排在几十名开外。
- 法务团队查询一个特定的法案编号 GDPR Article 17,系统却因为无法理解这个缩写词的“语义”,返回了一堆关于“数据隐私通用原则”的无关内容。
- 用户搜索一个独特的、新造的产品代号 Project Titan,由于这个词从未在通用语料中出现过,Embedding模型将其编码为一个无意义的向量,导致检索结果为零。
这就是稠密向量检索的**“阿喀琉斯之踵”:它擅长理解“意”,却常常忽略“形”。它在捕捉模糊的语义关联上表现出色,但在处理精确的关键词匹配、专业术语、代码片段、实体名称或罕见词**时,却常常“聪明反被聪明误”。
我们陷入了一个新的困境:我们是否为了追求“语义”,而牺牲了信息检索领域数十年积累下来的“精确匹配”的智慧?我们是否需要为RAG系统装上一个“第二大脑”,一个能够与稠密向量的“感性”互补的、严谨的“理性”大脑?
本篇,我们将回归信息检索的经典——稀疏向量检索 (Sparse Vector Retrieval)。我们将重新审视古老的BM25算法历久弥新的智慧,并见证搜索巨头Elasticsearch如何通过ELSER等前沿技术,将稀疏检索带入神经网络时代。最终,我们将学习如何构建一个**混合检索(Hybrid Search)**系统,将稠密向量的“懂你”与稀疏向量的“精准”完美结合,实现1+1>2的检索效果。
这是一次穿越信息检索技术演进史的旅程,也是一次关于架构权衡与融合的深度思考。让我们开始构建RAG系统的“左右脑”。
第一部分:稀疏向量的经典智慧-从BM25原理到ES架构
在向量嵌入席卷一切的时代,回头去谈论基于词频的BM25,似乎有些“复古”。
但一个成熟的架构师,必须理解其背后深刻的、源于统计学和信息论的价值,以及为其服务的、同样伟大的分布式架构。
1.1 稀疏向量的第一性原理:词袋模型与倒排索引
与稠密向量将整个文本压缩成一个几百维的、每个维度都有值的“密集”浮点数数组不同,稀疏向量的构建方式完全不同:
- 词汇表 (Vocabulary): 首先,你需要为你的整个文档集合构建一个巨大的词汇表,这个词汇表可能包含几十万甚至上百万个唯一的词(Token)。
- 词袋表示 (Bag-of-Words): 对于一个文档,它的稀疏向量就是一个与词汇表等长的、极其巨大的向量。这个向量的大部分维度都是0,只有在文档包含词汇表中某个词的位置上,才有一个非零值。这个值,通常与该词在文档中的重要性相关。
- 倒排索引 (Inverted Index): 由于向量是“稀疏”的,我们不需要存储那些大量的0。相反,我们使用一种名为“倒排索引”的数据结构。它像一本书的目录,记录了每个词(Term)出现在了哪些文档(Documents)里,以及相关的信息(如词频)。
当一个查询到来时,稀疏检索系统会:
- 解析查询,抽取出其中的关键词。
- 通过倒排索引,迅速找到包含这些关键词的所有文档。
- 使用一个排序算法,计算每个文档与查询的相关性得分,并返回Top-K。
1.2 BM25:稀疏检索的“排序之王”及其数学拆解
BM25 (Best Matching 25) 正是这个排序算法中的王者。它不是一个单一的公式,而是一套精妙的、综合了多种启发式思想的计分系统。其核心公式大致如下:
$$\text{Score}(Q, D) = \sum_{q_i \in Q} \left[ \text{IDF}(q_i) \cdot \frac{(k_1 + 1) \cdot \text{tf}(q_i, D)}{k_1 \cdot \left( (1 - b) + b \cdot \frac{|D|}{\text{avgdl}} \right) + \text{tf}(q_i, D)} \right]$$
让我们拆解这个看似复杂的公式,理解其背后的三大核心思想:
IDF(qi) (Inverse Document Frequency) - 逆文档频率:
核心思想: 一个词越稀有,越重要。
原理: IDF衡量一个词qi在整个文档集合中的“罕见”程度。如果一个词在所有文档中都出现了(如“的”、“是”),它的IDF值就接近于0;如果它只在少数几个文档中出现(如 GDPR Article 17),它的IDF值就很高。这赋予了关键词远超停用词的权重。
tf(qi, D)与饱和度因子 k1 - 词频与边际效应递减:
核心思想: 一个词在文档中出现次数越多,可能越相关,但这种相关性的增长不是线性的。
原理: tf(qi, D)衡量词qi在文档D中出现的频率。但简单的tf值会导致问题:一篇文档反复提及“数据库”,其得分会无限膨胀。k1参数(通常设为1.2-2.0)就是用来控制词频饱和度的。当一个词从出现1次增加到10次时,得分会显著增加;但从100次增加到110次时,得分的增加就微乎其微了。这防止了少数高频词过度主导得分。
文档长度归一化因子 b - 长度惩罚与公平性:
核心思想: 一个查询词出现在一篇短小精悍的文档中,比出现在一篇冗长、主题宽泛的文档中,更能说明其相关性。
原理: b参数(通常设为0.75)用于引入文档长度**|D|的影响。公式通过将文档长度|D|与平均文档长度avgdl**进行比较,对长文档进行了巧妙的“惩罚”。b=0意味着不考虑文档长度,b=1则意味着完全根据长度进行归一化。
1.3 倒排索引的物理化身:Elasticsearch的分布式架构
理解了BM25的算法,我们必须回答下一个问题:一个承载了数十亿文档的系统,是如何在毫秒内执行完如此复杂的计算的?答案,就藏在Elasticsearch为“倒排索引”量身打造的分布式架构中。
ES的架构,是倒排索引这种数据结构在物理世界中的必然延伸。

架构的原子 - 段 (Segment):
一个ES索引并非一个单一的巨大文件,而是由多个更小的、独立的倒排索引组成的,这些小索引被称为**“段”**。
核心特性:段是不可变的 (Immutable)。 一旦一个段被写入磁盘,它就永远不会被修改。这带来了巨大的性能优势:无需加锁,可以被操作系统文件系统轻松缓存,极大地提升了读性能。
新写入的文档会先进入内存缓冲区,然后被刷写(flush)成一个新的段。后台会有一个**合并(Merge)**进程,定期将小的段合并成大的段,以控制段的数量并删除已标记为删除的文档。
扩展的单元 - 分片 (Shard):
- 当数据量大到单机无法容纳时,ES会将一个逻辑上的索引(Index),水平切分成多个物理上的分片(Shard)。
- 每个分片,都是一个功能完备、自包含的Lucene实例,它拥有自己的一系列段文件。一个分片就是倒排索引的基本扩展单元,解决了AKF立方体中的**Z轴扩展(数据分区)**问题。
高可用的基石 - 副本 (Replica):
为了实现高可用和读性能的扩展,每个分片(称为主分片 Primary Shard)都可以有一个或多个副本分片(Replica Shard)。
主从关系: 写入请求只能由主分片处理,处理完毕后,数据会并行同步到所有副本分片。读取请求则可以由主分片或任何一个副本分片来处理。
作用:
高可用: 当持有主分片的节点宕机,ES集群会自动从其副本中选举一个新的主分片,服务不中断。
读扩展: 查询负载可以分摊到所有的主分片和副本分片上,实现了AKF中的X轴扩展(水平复制)。
搜索流程:为倒排索引优化的“Scatter-Gather”
查询阶段 (Query Phase):
- 客户端请求发送到集群中的任意一个节点,该节点成为协调节点(Coordinating Node)。
协调节点将查询请求广播到该索引涉及到的所有分片(包括主分片和副本分片)上。
每个分片在本地的段上独立地执行查询:利用倒排索引快速找到包含查询词的文档ID列表,然后计算每个文档的BM25得分。
每个分片返回一个只包含文档ID和分数的、轻量级的本地Top-K结果列表给协调节点。
取回阶段 (Fetch Phase):
协调节点收集所有分片返回的本地结果,进行全局排序,得到最终的全局Top-K文档ID列表。
然后,协调节点只向持有这些最终Top-K文档ID的分片发起“取回”请求,获取这些文档的原始内容(_source字段)。
最后,将文档内容与分数合并,返回给客户端。
1.4 架构对比:ES vs. Milvus —— 两种思想的物理碰撞
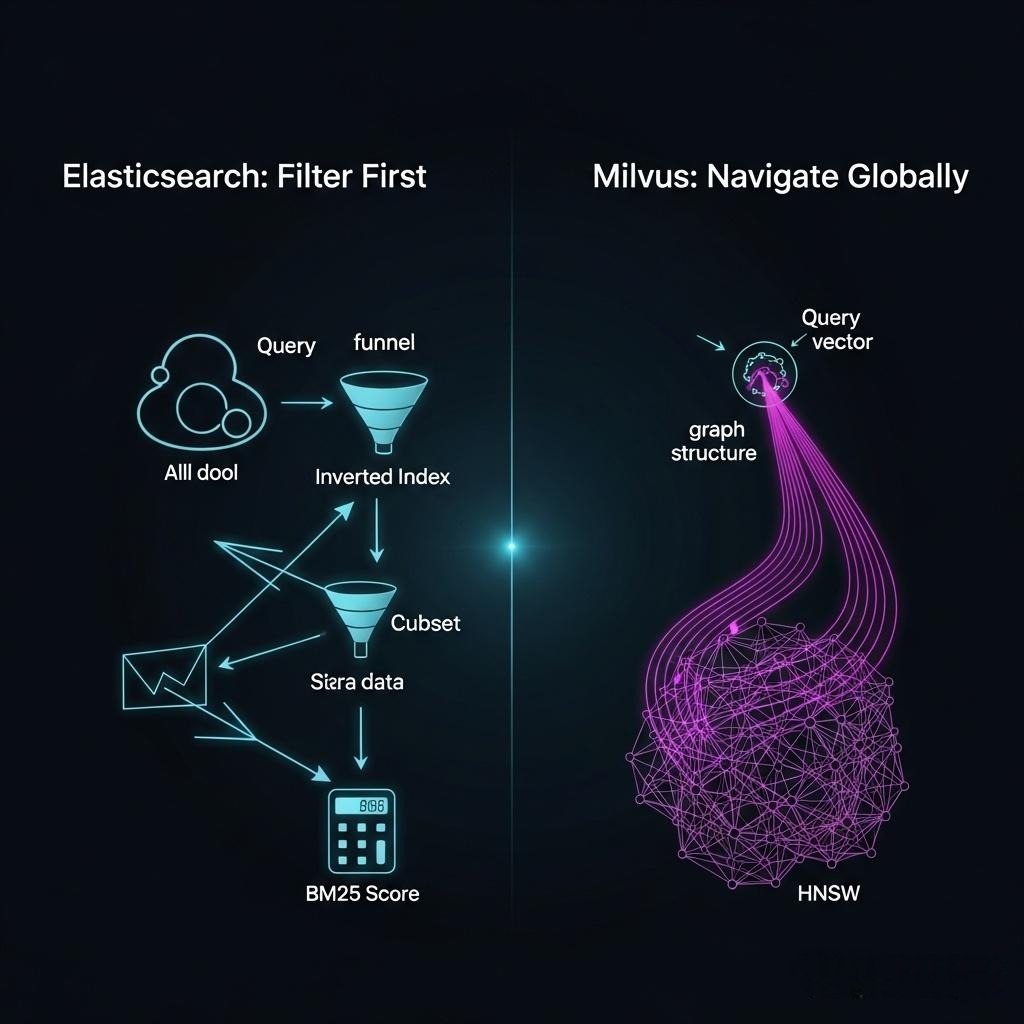
| 对比维度 | Elasticsearch | Milvus |
|---|---|---|
| 核心数据结构 | 倒排索引 (Inverted Index) | ANN图索引 (如HNSW) |
| 设计哲学 | 为关键词快速过滤而生 | 为高维空间全局近邻计算而生 |
| 查询模式 | 1.O(1)查倒排表找到候选集。 2. 对候选集(通常远小于全量)计算BM25。 |
1.O(logN)在整个图上进行导航。 2. 涉及大量的浮点数向量距离计算。 |
| 负载类型 | I/O密集型(倒排表读取) +CPU密集型(BM25打分) | CPU和内存密集型(图的遍历和向量计算) |
| 分布式模型 | 相对同质化的节点,每个节点都能处理查询和数据。通过副本实现读扩展。 | 高度异构化的角色(Query, Index, Data),将不同负载彻底物理隔离。 |
| 数据与计算 | 存算一体(数据和计算在同一节点上) | 存算分离(计算节点无状态,数据在对象存储) |
| 架构结论 | 为“精确”而优化的、紧耦合的分布式系统 | 为“模糊”而优化的、云原生的、松耦合的流式系统 |
架构师的思考: ES的架构是“先过滤,后计算”,它的所有设计都是为了让“过滤”这一步快到极致;而Milvus的架构是“全局导航计算”,它的所有设计都是为了让这个“重计算”的过程可以被无限地、弹性地扩展。它们是两种截然不同的、为解决不同数学问题而演化出的完美物理形态。
1.5 参数调优的艺术:k1与b的物理意义与寻优方法论
k1和b不仅仅是魔法数字,它们具有明确的物理意义,其调优直接影响检索质量。
- k1 (1.2 ~ 2.0): 词频饱和度控制器`
- 低 k1 (如1.2): 词频饱和度曲线更陡峭,适用于短文本场景,关键词出现一次即是强信号。
- 高 k1 (如2.0): 词频饱和度曲线更平缓,适用于长文档,反复提及更能证明主题相关性。
- b (0.0 ~ 1.0): 文档长度归一化器
- 低 b (如0.3): 对长文档的惩罚较轻。
- 高 b (如1.0): 对长文档的惩罚非常重,适用于追求“专一性”的场景。
- 寻优方法论:网格搜索 (Grid Search)
- 准备评估集: 你需要一个包含**(query, relevant_doc_id)**对的标注数据集。
- 定义评估指标: 通常使用NDCG@k或MAP来衡量排序列表的质量。
- 执行网格搜索:
1 | # 伪代码 |
这个过程虽然计算量大,但它是为你的特定数据集找到最优BM25参数的唯一科学方法。
1.6 架构师洞察:精确匹配的心理学
为何在AI时代,用户依然迷恋关键词的“所见即所得”?
这源于一种基本的控制感和可预测性。当用户搜索GDPR Article 17时,他们期望系统像一个忠实的图书管理员,精确地找到这本书的第17条。稠密向量的“智能联想”在这里反而成了一种干扰,它试图“猜测”用户的深层意图,却破坏了用户对系统行为的确定性预期。在处理事实、ID、代码等“非黑即白”的信息时,确定性高于“智能”。 BM25提供的正是这种无可替代的确定性。
第二部分:Elasticsearch的自我革命-从BM25到ELSER
Elasticsearch(ES)作为传统搜索领域的霸主,其核心正是基于BM25和倒排索引。然而,面对稠密向量的崛起,ES也开始了它的“自我革命”,旨在将稀疏检索带入神经网络时代。
2.1 ELSER:用Transformer赋能稀疏检索
尽管BM25很强大,但它无法理解同义词(例如,“修复bug” vs “解决缺陷”)。为了解决这个问题,Elasticsearch推出了ELSER (Elastic Learned Sparse EncodeR)。
- 核心思想: ELSER是一个由Elastic训练的、专门用于生成“稀疏向量”的Transformer模型。它不再是简单地基于词频,而是学习为每个词赋予一个“语义权重”。
- 工作原理:
- 索引阶段: 当你索引一篇文档时,ELSER模型会分析文档内容,并输出一个JSON对象。这个对象包含一系列的词(Token)以及它们对应的“权重”(Weight)。这些词是模型认为最能代表文档语义的“扩展词汇”,可能包含原文中没有的同义词。
- 查询阶段: 当用户查询时,ELSER模型同样会处理查询文本,生成一个带权重的词列表。
- 匹配与排序: ES的搜索引擎会使用一种特殊的加权匹配算法,来计算查询的词权重向量和文档的词权重向量之间的相关性得分。
2.2 底层揭秘:ELSER (SPLADE)是如何训练的?
ELSER是SPLADE(Sparse Lexical and Expansion Model)模型的一种变体。其训练过程是其效果的关键。
基础模型: SPLADE基于一个Masked Language Model(如BERT),但其输出层被修改为直接输出整个词汇表(Vocabulary)的权重 logits。
训练目标:对比学习 (Contrastive Learning)与稠密向量类似,它也使用**(query, positive_doc, negative_doc)**的数据进行训练。其目标是最大化query和positive_doc的得分,同时最小化query和negative_doc的得分。
核心魔法:FLOPS正则化如果只做对比学习,模型会倾向于为词汇表中的很多词都赋予非零权重,结果会变成一个“伪稠密”向量,失去稀疏性带来的效率优势。SPLADE引入了一种L0正则化的变体,称为FLOPS正则化,它直接惩罚模型输出的非零权重的数量。
- Loss = Contrastive_Loss + λ * Sparsity_Loss (FLOPS)
这个Sparsity_Loss项,迫使模型在优化语义相关性的同时,必须学会“精打细算”,只激活那些最重要、最能代表语义的少数词汇。
架构师洞察: ELSER/SPLADE是一次绝妙的“融合创新”。它在一个统一的稀疏向量框架内,试图同时获得关键词匹配的精确性(来自稀疏表示)和神经网络的语义理解能力(来自Transformer和对比学习)。对于那些既需要精确匹配又需要一定语义泛化的场景,ELSER提供了一种比“BM25 + 稠密向量”更原生、更集成的解决方案。
第三部分:混合检索实战-构建RAG的“左右脑”
理论的探讨最终要服务于实践。一个顶级的RAG系统,其检索层必然是一个混合系统。
注:在Milvus的2.5版本中,Milvus系统在支持稠密向量的基础上,已内置了基于BM25算法的稀疏向量存储与检索,并支持基于RRF和加权的融合算法。
3.1 架构模式:检索、融合、重排

一个生产级的混合检索系统,其工作流通常如下:
并行检索 (Parallel Retrieval):将用户的查询同时发送给两个(或多个)并行的检索系统:
系统A (稀疏): Elasticsearch,执行BM25或ELSER查询。
系统B (稠密): Milvus或ES的向量搜索功能,执行KNN查询。
两个系统各自返回其Top-K的结果(例如,各自返回Top-100)。
**结果融合 (Fusion):**将来自不同系统的两个结果列表,通过一个融合算法合并成一个统一的、更高质量的列表。
**重排序 (Re-ranking):**将融合后的列表(例如,取Top-50)送入一个交叉编码器(Cross-encoder)重排模型。重排模型会对每个文档与原始查询进行一次深度的、成对的语义相关性打分,最终输出一个高质量、高精度的Top-N列表(例如,Top-5),作为注入LLM的最终上下文。
3.2 融合算法大比拼:RRF vs. 加权融合 vs. 机器学习
仅仅将结果合并是远远不够的,如何融合,是一门艺术,也是一门科学。
- 方案一:Reciprocal Rank Fusion (RRF) - 倒数排名融合
- 原理: RRF_Score(d) = Σ (1 / (k + rank_i(d)))
- rank_i(d)是文档d在第i个结果列表中的排名。
- k是一个小常数(如60),用于平滑分数,防止排名第一的文档得分过高。
- 优点: 极其简单,无需归一化,无需调参。它不关心原始分数的大小,只关心排名,这巧妙地规避了BM25和向量相似度得分尺度完全不同的问题。
- 缺点: 过于简单,没有利用到原始分数中可能包含的有用信息。
- 方案二:Weighted Fusion - 加权融合
- 原理: Fused_Score(d) = w_sparse * norm_score_sparse(d) + w_dense * norm_score_dense(d)
- 优点:* 直观,可以根据经验(如关键词更重要)赋予不同检索器更高的权重。
- 缺点:
- 分数归一化地狱: BM25的得分是无界的,向量相似度得分通常在[-1, 1]或[0, 1]之间。你需要先对它们进行min-max或z-score归一化,才能相加,而归一化的效果很难控制。
- 调参地狱: 权重w_sparse和w_dense的设置高度依赖于数据集和查询类型,需要大量的实验来找到最优解。
方案三:Logistic Regression Fusion - 机器学习融合
原理: 将其视为一个简单的机器学习问题。
- 特征工程: 对于每个被召回的**(query, doc)**对,将其稀疏得分和稠密得分作为两个特征:X = [score_sparse, score_dense]。
- 数据标注: 你需要一个标注数据集,标记每个**(query, doc)**对是否是真正相关的 (y = 0 or 1)。
- 模型训练: 用这些数据训练一个逻辑回归模型 P(y=1|X)。
优点: 效果最好,能自动学习两种分数的最佳组合方式,无需手动调参。
缺点: 复杂度最高。需要标注数据,需要模型训练和部署的MLOps流程。
| 融合算法 | 原理 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| RRF | 倒数排名相加 | 简单,无需调参,对分数尺度不敏感 | 忽略了原始分数值 | 快速启动项目,或分数尺度差异巨大的场景 |
| 加权融合 | 归一化后加权求和 | 直观,可解释性强 | 分数归一化困难,权重难以确定 | 能够投入时间进行细致调参,且分数分布相对稳定的场景 |
| 逻辑回归 | 机器学习模型 | 效果上限高,自动学习权重 | 复杂度高,需要标注数据和MLOps | 追求极致性能,且有能力支持ML模型训练的成熟项目 |
对于绝大多数项目,从RRF开始,是一个明智且高效的选择。
3.3 Java实战:构建混合检索服务
让我们用Java勾勒出这个混合检索服务的轮廓,重点实现RRF算法。
1 | import java.util.ArrayList; |
结语:没有“银弹”,只有“组合拳”
在本篇中,我们为RAG系统装上了强大的“第二大脑”。我们穿越了信息检索的历史长河,重新发现了BM25算法中蕴含的、关于“精确匹配”的经典智慧,并见证了Elasticsearch如何通过ELSER,用神经网络的力量为这一古老智慧注入新的活力。
- 我们深刻理解了稠密检索与稀疏检索的本质区别与互补关系:前者长于“语义”,后者精于“词汇”。我们甚至从用户心理学的角度,理解了为何“精确”有时比“智能”更重要。
- 我们深入探讨了BM25参数k1和b的物理意义与调优方法,并揭示了ELSER/SPLADE模型训练背后,通过FLOPS正则化实现稀疏性的核心秘密。
- 我们掌握了构建一个生产级混合检索系统的核心架构模式:“并行检索 -> 融合 -> 重排”,并详细比较了RRF、加权融合、机器学习融合等不同算法的优劣与适用场景。
- 我们意识到,在信息检索的世界里,不存在所谓的“银弹”。面对企业知识库的异构性和用户查询的多样性,**“组合拳”**永远是比“单点绝技”更可靠的选择。
至此,我们已经为RAG系统构建了强大的“左右脑”,无论是需要深度语义理解的模糊查询,还是要求精确匹配的专业术语,我们的系统都已具备应对能力。
然而,我们的知识库仍然是“平坦”的。文档与文档之间、概念与概念之间的**“关系”**,这种更高维度的信息,仍然沉睡在我们的系统中,未被利用。如果说稀疏和稠密检索是在一个“平面地图”上寻找地点,那么我们是否能构建一张“三维立体地图”,让检索过程本身具备“推理”能力?
在下一篇章 《GraphRAG协同革命:当“向量”遇上“图”,用Neo4j实现从“入口发现”到“关系推理”》 中,我们将进入RAG的下一个革命性前沿。我们将探索如何将知识图谱(Knowledge Graph)与向量检索相结合,让我们的RAG系统不仅能“找到”信息,更能“理解”信息之间的关系,实现从“信息检索”到“知识推理”的终极飞跃。