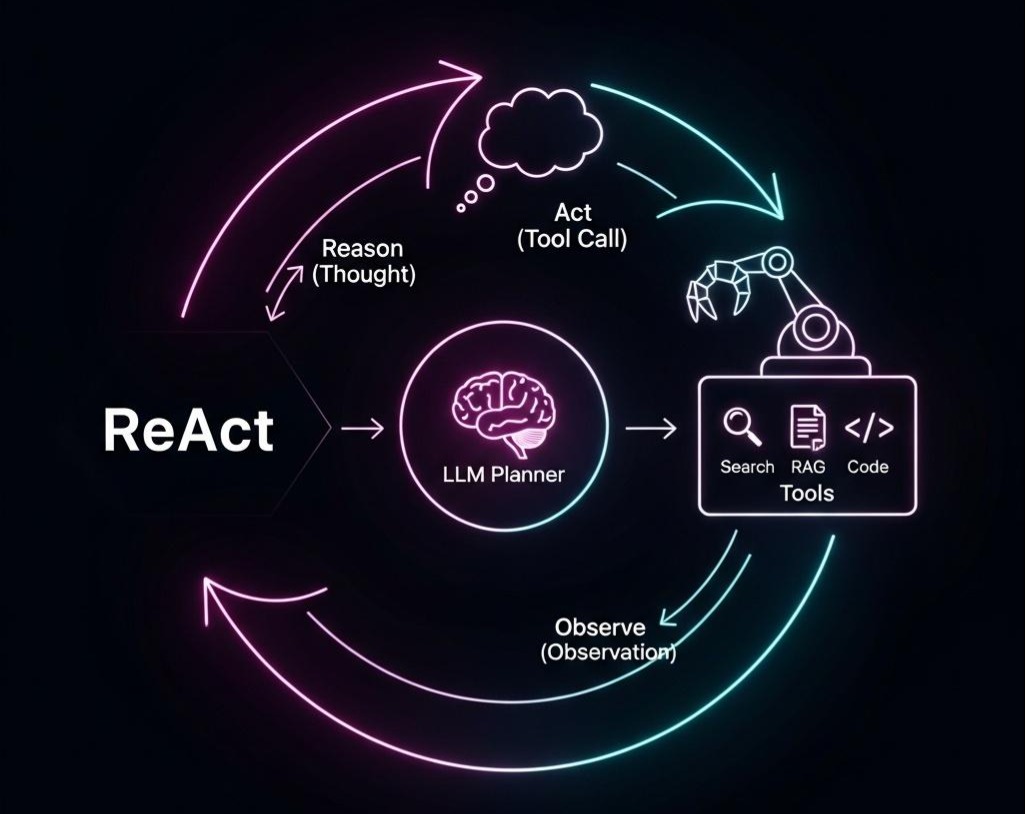
RAG篇(7):GraphRAG协同革命:当“向量”遇上“图”,用Neo4j实现从“入口发现”到“关系推理”

导语:RAG的“认知天花板”——被割裂的上下文
在前面的篇章里,我们已经为RAG系统构建了一个堪称豪华的“检索引擎”。我们拥有了Milvus驱动的稠密向量检索“左脑”,它能理解语义的微妙之处;我们还拥有了Elasticsearch驱动的稀疏向量检索“右脑”,它能精确捕捉关键词的锋芒。通过混合检索与重排序,我们似乎已经能从海量文档中找到任何我们想要的信息。
然而,一种更深层次的无力感,在处理某些特定问题时,依然会悄然浮现:
- 你问:“与‘Project Titan’项目相关的、所有直接汇报给张三的工程师,最近都提交了哪些代码?”
- 你问:“在我们的供应链中,哪些供应商同时为‘A产品线’和‘B产品线’提供核心组件,并且他们的风险评级是‘高’?”
- 你问:“这位患者的基因突变(KRAS G12C),与我们知识库中提到的哪些靶向药物有关联,这些药物的三期临床试验结果如何?”
面对这些问题,你那强大的检索引擎,无论是稠密还是稀疏,都显得步履维艰。它或许能分别找到关于“张三”、“Project Titan”、“代码提交”的文档片段,但它无法理解它们之间**“汇报给”、“相关于”这种结构化的“关系”。它检索到的上下文,依然是一堆语义相关但逻辑上“碎片化”、“平面化”**的文本块。LLM需要耗费巨大的推理能力,才能在这些碎片中艰难地重建出它们之间的联系,而且极易出错。
这就是传统RAG的“认知天花板”。它的世界是由独立的“文档”构成的,它看不到文档之间、实体与实体之间那张无形的、却至关重要的**“关系之网”**。
本篇,我们将发起对这一天花板的最后冲击。我们将引入一个全新的维度——知识图谱(Knowledge Graph)。我们将深入探讨GraphRAG这一前沿范式,看它如何将RAG从一个“信息检索器”进化为一个初级的“知识推理引擎”。我们将聚焦于业界领先的图数据库Neo4j,学习如何将我们已经掌握的向量检索,与图的“关系遍历”能力进行协同作战。
这不再是关于如何“找到”信息,而是关于如何**“连接”信息,并从连接中涌现出新的洞察**。这是一场从“平面思维”到“立体思维”的认知升级,也是我们构建下一代企业级知识引擎的关键一步。
第一部分:图数据库的物理本质—为何“关系”需要一种新架构?
在深入GraphRAG之前,我们必须回答一个根本性问题:为什么我们不能用熟悉的MySQL或PostgreSQL来存储和查询“关系”,而需要一种像Neo4j这样的全新数据库?答案,藏在数据库的物理存储模型中。

1.1 关系型数据库的“原罪”:昂贵的JOIN操作
在关系型数据库(RDBMS)中,我们如何表示“关系”?答案是外键(Foreign Key)和连接表(Join Table)。
表示方式:
- 一个employees表,一个projects表。
- 一个employee_project连接表,包含employee_id和project_id两个外键。
查询方式: 当你想找到“张三参与的所有项目”时,你需要执行一个JOIN操作:
1 | SELECT p.name FROM employees e JOIN employee_project ep ON e.id = ep.employee_id JOIN projects p ON ep.project_id = p.id WHERE e.name = '张三'; |
- 架构痛点: JOIN操作在计算上是极其昂贵的。数据库需要在两个巨大的表中,通过索引查找匹配的行,然后将它们合并。当你的查询需要进行**多跳(Multi-hop)**遍历时(例如,“查找张三的同事的同事参与的所有项目”),JOIN的数量和计算复杂度会呈指数级增长。在RDBMS中,关系不是一种“物理存在”,而是每次查询时通过计算“临时发现”的。
1.2 Neo4j的架构革命:原生图存储与“无索引邻接”
Neo4j从根本上颠覆了这种模式。它的架构哲学是:关系是一等公民(Relationships as First-Class Citizens)。
物理存储模型: Neo4j在磁盘上并非使用传统的行式或列式存储。它拥有专门的、高度优化的存储文件:
节点文件 (neostore.nodestore.db.*): 存储所有的节点,每个节点有一个固定的记录大小,通过ID可以**O(1)**定位。
关系文件 (neostore.relationshipstore.db.*): 存储所有的关系,同样可以通过ID **O(1)**定位。
属性文件 (neostore.propertystore.db.*): 存储节点和关系的所有属性,与节点/关系本身分离,以优化遍历性能。
标签/关系类型文件: 存储标签和关系类型的索引。
**核心魔法:“无索引邻接”(Index-Free Adjacency)**这是Neo4j与所有其他数据库(包括文档数据库、键值数据库)最本质的区别,也是其性能来源的核心秘密。
在Neo4j中,每个节点记录中,都包含了指向其第一个关系的物理指针。
每个关系记录中,包含了指向其源节点和目标节点的物理指针,以及指向该节点的上一个关系和下一个关系的物理指针。
这构成了一个双向链表。当你找到一个节点后,你不需要通过任何索引去“查找”它的邻居。你只需沿着这些物理指针,就能以**O(1)**的代价直接“跳”到它的邻居节点。
重点来了:
- 在MySQL中,找到一个人的朋友,你需要去friendship表中进行一次**WHERE user_id = ?**的索引查找。
- 在Neo4j中,找到一个人的朋友,就像你已经站在他身边,他直接用手指着他的朋友们一样,是一个常数时间的操作。
对于多跳查询,这种优势是碾压性的。查询“张三的同事的同事”:
- MySQL: JOIN … JOIN … JOIN …,性能随跳数增加而急剧下降。
- Neo4j: (张三)-[]->()-[]->()-[]->(同事的同事),性能几乎与跳数无关,因为每一步遍历都是一次**O(1)**的指针跳转。
架构师洞察: Milvus为向量距离计算而生,其核心是ANN图和分布式计算。Elasticsearch为关键词过滤而生,其核心是倒排索引和分片广播。而Neo4j为关系遍历而生,其核心是“无索引邻接”和原生图存储。它们分别是为解决不同数学问题而演化出的、无可替代的物理形态。试图用一种架构去完美解决所有问题,本身就是反工程学的。
第二部分:LLM时代的知识图谱自动化构建
在过去,构建知识图谱是劳动密集型的。但在LLM时代,我们拥有了前所未有的自动化工具。
2.1 现代知识图谱的构建流水线

一个现代化的、由LLM驱动的知识图谱构建流程,通常包含以下几个关键步骤:
Schema定义 (Schema Definition):
做什么: 由领域专家定义图谱中包含哪些类型的实体(如Person, Project, Company)和关系(如WORKS_ON, MANAGES, ACQUIRED_BY)。
为什么重要: 这是整个项目的“宪法”。一个定义良好、边界清晰的Schema,是保证后续信息提取质量和图谱可用性的前提。
实体与关系提取 (Entity and Relation Extraction):
做什么: 设计一个精巧的Prompt,指示LLM在阅读一段文本后,严格按照你定义的Schema,以JSON格式输出它识别出的所有三元组。
挑战: 如何让LLM既能识别到所有信息,又不会产生幻觉,输出原文不存在的实体或关系。这需要大量的Prompt工程和Few-shot示例。
实体消歧与链接 (Entity Disambiguation and Linking):
做什么: 这是最困难也最关键的一步。当LLM从不同文档中都提取出“Apple”时,它指的是苹果公司,还是苹果水果?当它提取出“张三”时,是指A部门的张三,还是B部门的张三?
解决方案:
基于上下文的消歧: 在Prompt中加入指令,要求LLM根据上下文判断实体类型。
基于现有实体的链接: 在提取前,先从图谱中检索可能相关的现有实体,将其作为上下文注入Prompt,要求LLM优先链接到这些实体。
建立权威ID: 为每个唯一的实体创建一个权威ID,并要求LLM在输出时尽可能关联上这个ID。
数据注入与验证 (Data Ingestion and Validation):
- 做什么: 将LLM输出的、经过消歧的JSON三元组,解析并批量导入到图数据库(如Neo4j)中。在导入时,应有验证步骤,确保数据符合Schema定义。
第三部分:GraphRAG的核心范式—“图”如何革命性地赋能“检索”
将知识图谱引入RAG,并非简单地增加一个数据源,而是带来了两种全新的、革命性的检索范式。
3.1 范式一:查询转换 (Text-to-Cypher) — 精确事实的终极答案

这种范式适用于回答那些事实性、结构化的问题。
核心思想: 不再用用户的自然语言问题去检索文本,而是将自然语言问题**“翻译”**成一段图数据库的查询语言(如Neo4j的Cypher),然后直接在图上执行查询,得到精确的、事实性的答案。
工作流程:
- 构建翻译Prompt: 这是核心。你需要在一个Prompt中,向LLM提供:- 图数据库的Schema: 实体类型、关系类型、属性。- 用户的自然语言问题。- 一些Few-shot示例: 从简单到复杂的问题及其对应的Cypher查询,这能极大地提升LLM的生成质量。- 明确的错误处理指令: 指示LLM,如果无法将问题转换为Cypher,则返回一个特定的错误标识(如**”I don’t know”**)。
- LLM生成Cypher: LLM根据Prompt,生成Cypher查询语句。
- 执行与格式化: 在Neo4j中执行生成的Cypher语句,并将查询结果(通常是JSON格式)格式化为自然语言,或直接呈现给用户。
优点: 对于事实性问题,能提供100%准确的答案,彻底消除幻觉。
缺点: 严重依赖LLM生成Cypher的准确性,对Prompt工程要求极高,且不适用于开放性、总结性的问题。
3.2 范式二:协同检索 (Graph + Vector/Keyword Co-retrieval) — 深度上下文的构建艺术
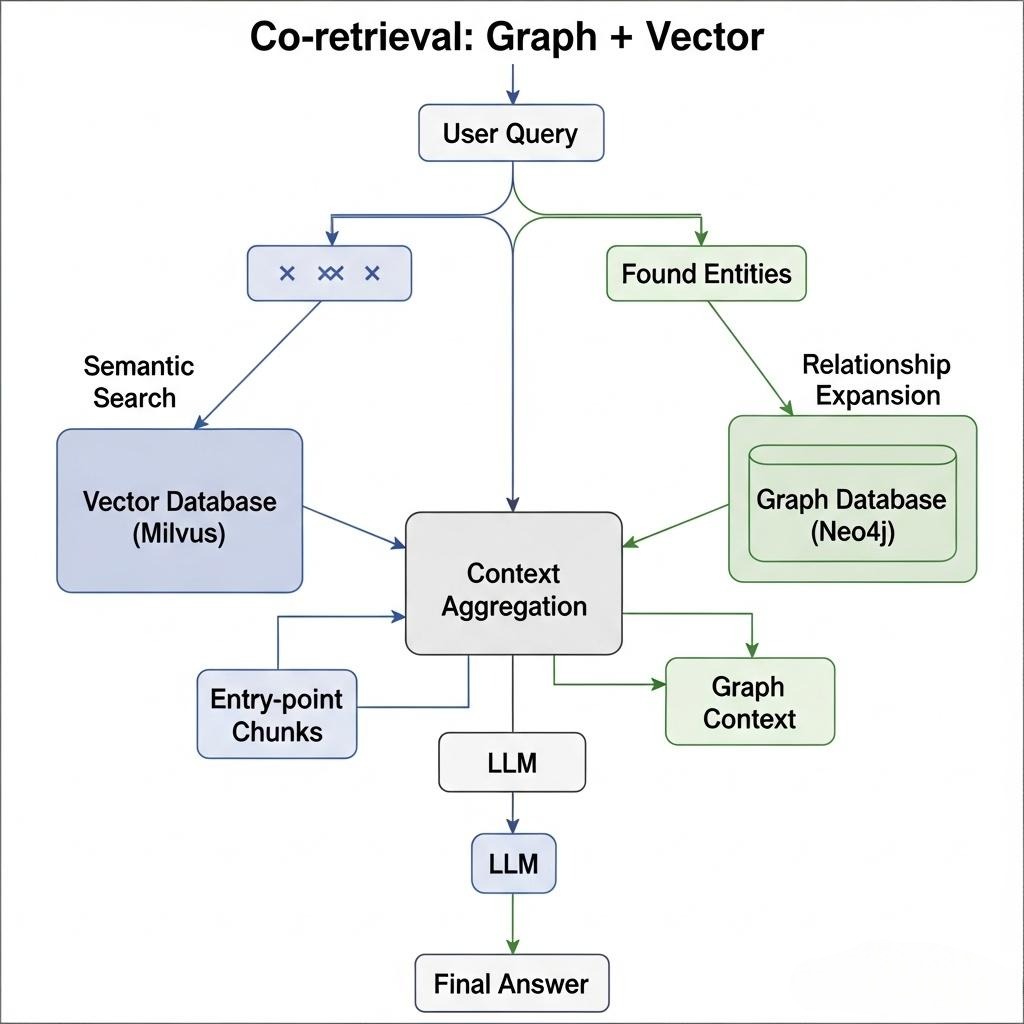
这种范式更通用、更强大,它旨在用图来丰富和扩展我们已有的检索能力。
- 核心思想: 它不是用图查询“替代”向量/关键词检索,而是将它们协同作战。利用向量/关键词检索的语义匹配能力找到**“入口点”,再利用图的“关系遍历”**能力来扩展和深化上下文。
- 典型工作流:入口发现 -> 关系扩展
- 入口发现 (Entity-centric Search):- 首先,使用一个LLM(或传统的NER工具)从用户查询中提取出核心实体(如“张三”、“Project Titan”)。- 然后,使用我们上一章构建的混合检索引擎,去搜索与这些实体直接相关的文本Chunk。这些Chunk可以被视为我们进入知识网络的“入口”。
- 关系扩展 (Knowledge Graph Traversal):- 从“入口Chunk”中,我们可能已经知道了“张三”这个实体。现在,我们以“张三”为起点,在知识图谱中进行遍历。- 执行Cypher查询,例如:MATCH (p:Person {name: ‘张三’})-[r]-(neighbor) RETURN r, neighbor。- 这个查询会返回与张三直接相连的所有邻居实体(如他参与的项目、他的经理、他的下属)以及它们之间的关系。
- 上下文聚合 (Context Aggregation):- 将第一步中检索到的非结构化文本Chunk,和第二步中从图谱中遍历出的结构化关系信息,共同组合成一个丰富、立体的上下文,最后再喂给LLM。
架构师思考: 这种“协同检索”的模式,是GraphRAG最核心、最精髓的应用。它完美地结合了两种检索范式的优点:
- 向量/关键词检索,解决了在海量非结构化文本中,如何高效定位相关信息的问题(“大海捞针”)。
- 图检索,解决了在找到相关信息后,如何理解其深层联系、发现隐藏关系的问题(“顺藤摸瓜”)。
这种模式,让RAG系统从一个简单的“问答机”,进化为了一个能够进行初步**探索性数据分析(Exploratory Data Analysis)**的智能助手。
第四部分:终极架构之辩:分离式 vs. 集成式

在实现“协同检索”时,我们面临一个关键的架构抉择。
架构A:分离式架构 (Specialized Stores)
- 组成: Milvus/ES处理向量检索 + Neo4j处理图检索。
- 工作流: Java应用层作为“指挥官”,先去Milvus/ES找到入口点,再根据结果去Neo4j进行图遍历,最后在应用层聚合上下文。
- 优点:
- 专业的人做专业的事: 每个数据库都在其最擅长的领域工作,可以独立优化和扩展,性能上限更高。
- 技术栈解耦: 可以灵活替换某个组件(比如用Qdrant替换Milvus)。
- 缺点:
- 架构复杂: 需要维护两套异构的数据库系统。
- 数据冗余与一致性: 实体信息可能同时存在于两个系统中,需要维护数据同步,增加了复杂性。
- 多步查询延迟: 网络开销和跨系统调用的延迟累加。
架构B:集成式架构 (Integrated Store)
组成: 完全在Neo4j中进行。Neo4j 5.x版本之后,自身也引入了强大的向量索引能力。
工作流: 将文本Chunk的内容和其向量嵌入,都作为节点的属性存储起来。可以在一个Cypher查询中,无缝地完成向量搜索和图遍历。
优点:
架构极简: 只需要维护一个数据库。
查询优雅: 可以在一个原子查询中完成复杂的协同检索,避免了应用层的复杂编排和网络开销。
数据一致性: 数据不存在冗余,事务性得到保证。
- 缺点:
- 性能权衡: Neo4j的向量检索性能和功能,在面对超大规模(数十亿级)向量时,可能还无法与专用的、内存优化的Milvus集群相媲美。
架构师的决断:
- 对于初创项目或中小型应用,集成式架构是更好的起点。它极大地降低了架构复杂度和运维成本,可以让你快速验证业务逻辑。
- 对于超大规模、性能要求极致的企业级应用,分离式架构可能更合适。它允许你对向量检索和图检索进行独立的、针对性的极限优化。
集成式架构下的协同检索Cypher实战
让我们看一个在集成式架构下,回答“与‘Project Titan’最相关的工程师是谁?”的优雅Cypher查询。
1 | // 步骤1: 创建向量索引 (一次性操作) |
重点来了: 这个单一的Cypher查询,无缝地、原子化地完成了:
- 向量空间的语义搜索 (CALL db.index.vector.queryNodes)
- 图空间的结构化遍历 (MATCH (chunk)-[:MENTIONS]->(p:Person))
- 节点属性的精确过滤 (WHERE p.title CONTAINS ‘Engineer’)
这就是集成式架构的魅力所在,它将不同范式的数据查询,统一在了一种优雅的声明式语言之下。
结语:从“信息检索”到“知识推理”的黎明
在本篇中,我们为RAG系统引入了决定性的第三个“大脑”——知识图谱。我们不再满足于在“平面”的文本世界中进行检索,而是将视角提升到了“立体”的关系网络。
- 我们从数据库物理存储的第一性原理出发,揭示了为何“关系”的查询需要像Neo4j这样的原生图数据库架构,理解了其“无索引邻接”相比传统JOIN的碾压性优势。
- 我们深入探讨了在LLM时代,自动化知识图谱构建的完整工程流水线,以及其中最核心的挑战——实体消歧。
- 我们剖析了GraphRAG的两大核心范式,并对分离式与集成式架构进行了深度的利弊权衡与思辨。
GraphRAG的出现,标志着RAG系统的一次深刻进化。它让我们的系统第一次拥有了进行初步**“推理”的能力——不是LLM那种基于概率的、可能会出错的推理,而是基于图谱中确定性关系的、可靠的逻辑推理。系统不再仅仅是“找到”信息,而是开始“连接”和“理解”信息**。
至此,我们已经为RAG的“检索”环节,构建了一个包含稠密、稀疏、图三种能力的“三位一体”的强大引擎。我们已经拥有了市面上最顶尖的“寻宝工具”。
然而,找到了宝藏(高质量的上下文)之后,如何将它们最优雅、最高效地呈现给“国王”(LLM)?这同样是一门精深的艺术。如果呈现方式不当,再好的上下文也可能被LLM忽略或误解。
在下一篇章 《Context Engineering的终极实践:从信息过载到精准洞察,为LLM打造“完美工作记忆”》 中,我们将深入“七层模型”的第六层——上下文工程层。我们将直面“中间遗忘”、“上下文污染”等痛点,学习如何通过重排序、格式化、压缩等一系列精巧的技术,为LLM打造一份它最乐于“阅读”、也最能激发其能力的“完美简报”。