RAG篇(8):Context Engineering的终极实践:从信息过载到精准洞察,为LLM打造“完美工作记忆”
导语:找到了“七颗龙珠”,却念错了“咒语”
让我们回到那个激动人心的时刻:在经历了意图识别、文档解析、混合检索、图谱推理等一系列复杂而精密的工序后,你的RAG系统终于成功地从亿万字节的知识海洋中,召回了10个与用户问题高度相关的、金子般的文本块(Chunks)。你感觉自己就像集齐了七颗龙珠的勇士,即将召唤出无所不能的“神龙”(LLM)。
于是,你采取了最简单、最直观的方式:将这10个文本块一股脑儿地拼接在一起,塞进Prompt里,然后满怀期待地对LLM说:“请根据以上信息,回答我的问题。”
然而,“神龙”的回应却让你大失所望:
它只回答了基于第一个和最后一个文本块的信息,中间的8个关键信息仿佛人间蒸发。
它被一个相关性稍低、但位置靠前的文本块“带偏”,得出了一个片面的、甚至是错误的结论。
它抱怨上下文过长,或者直接给出了一个被截断的、不完整的答案。
这就是RAG实践中一个极其普遍、却又极易被忽视的“最后一公里”问题:我们精心准备的“高质量上下文”,并没有被LLM高质量地“吸收”。我们找到了龙珠,却念错了召唤神龙的咒语。
这个问题的根源在于,我们错误地将LLM视为一个理想的、注意力无限且均匀的“信息处理器”。但现实是,LLM像人类一样,存在认知偏见和注意力局限。它对输入信息的顺序、结构、密度和噪声都极其敏感。
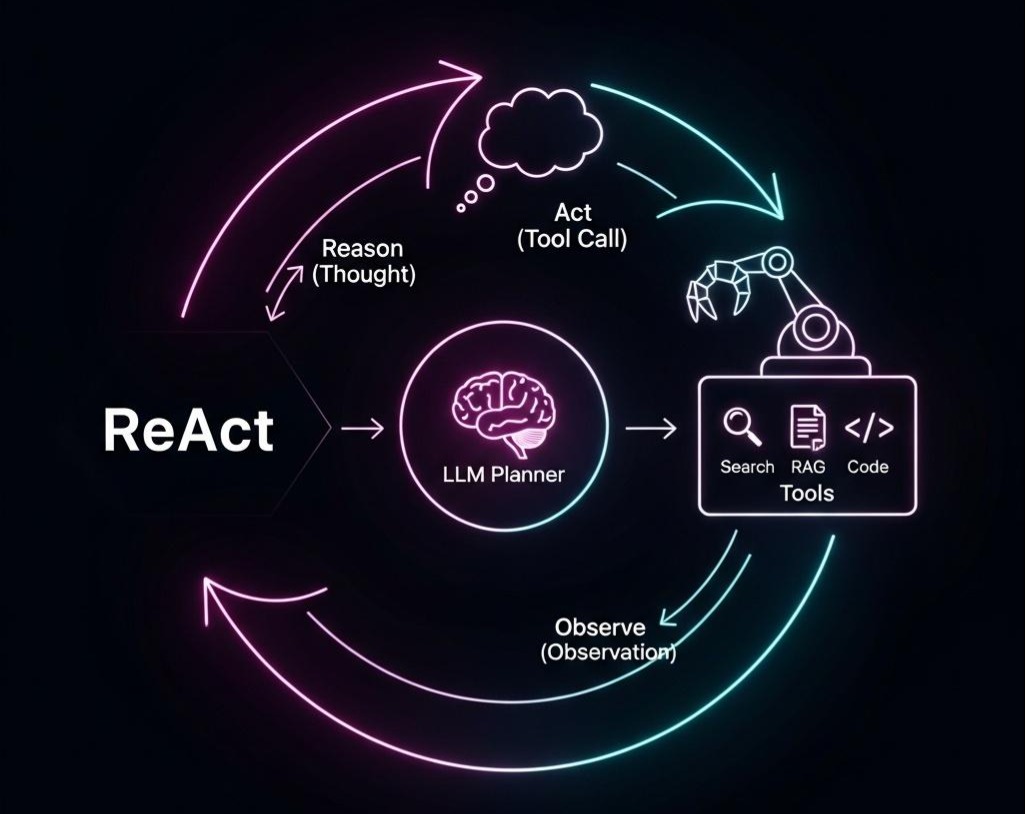
本篇,我们将深入RAG七层架构的第六层——上下文工程层 (Context Engineering)。这不再是关于“找到什么”,而是关于“如何呈现”的艺术与科学。我们将直面“中间遗忘(Lost in the Middle)”、“上下文污染”等痛点,并系统性地学习如何通过**精选(Selection)、排序(Ordering)、呈现(Formatting)、压缩(Compression)**这四大核心操作,为LLM打造一份它最乐于“阅读”、也最能激发其能力的“完美工作记忆”。
这是一场深入LLM“认知心理学”的工程实践,也是决定你的RAG系统最终输出质量的最后一道、也是最精细的一道“打磨工序”。让我们开始学习如何成为一名LLM的“金牌沟通师”。
第一部分:LLM的“认知缺陷”—为何上下文工程是必要的?
在设计解决方案之前,我们必须深刻理解我们所面对的“敌人”——LLM在处理长上下文时暴露出的三大固有缺陷。
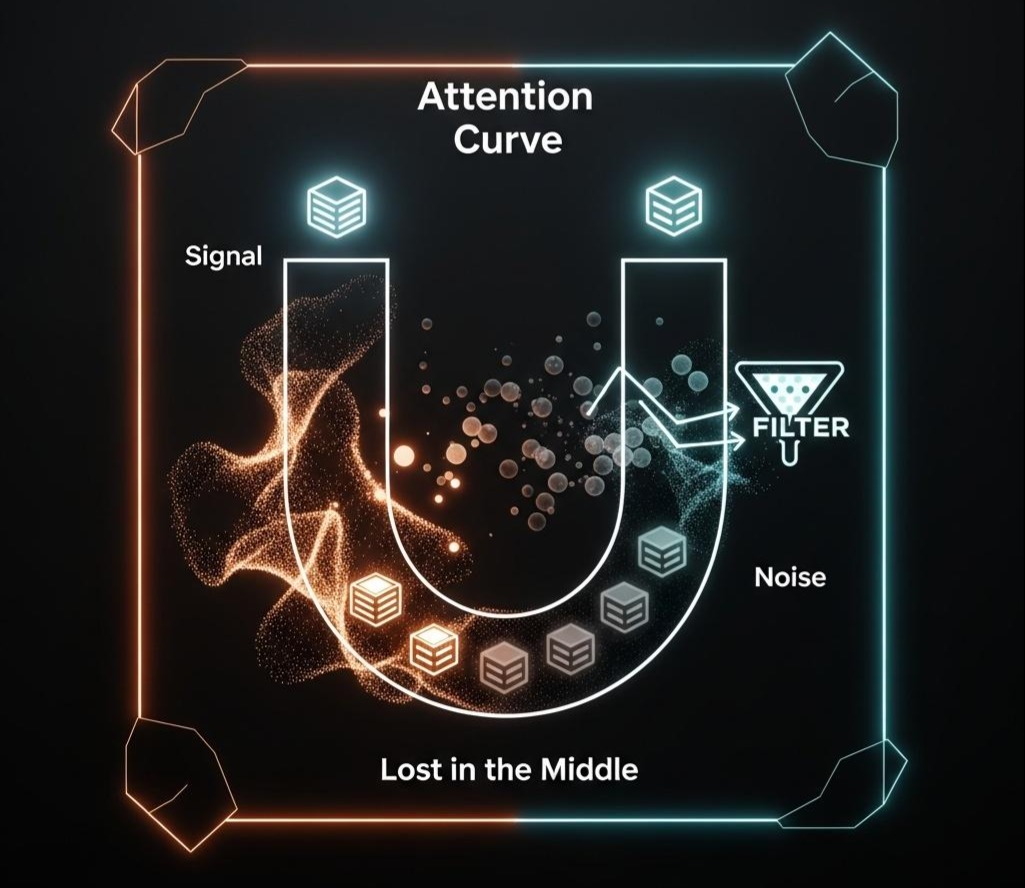
1.1 缺陷一:“中间遗忘”效应 (Lost in the Middle)
- 现象:大量研究(如斯坦福大学的《Lost in the Middle: How Language Models Use Long Contexts》)明确指出,LLM在处理一个长长的、由多个独立信息块组成的上下文时,其对信息的提取能力呈现出一种“U”型曲线。它对位于上下文开头和结尾部分的信息,回忆和利用的准确率最高;而对于夹在中间部分的信息,其性能会显著下降,仿佛被“遗忘”了。
- 工程影响:如果我们只是简单地按检索得分从高到低拼接Chunks,那么得分第二、第三高的关键信息,很可能恰好落入这个“注意力低谷”,被LLM直接忽略,导致答案不完整。
1.2 缺陷二:“首因效应”与“近因效应” (Primacy & Recency Effect)
- 现象:这与“中间遗忘”是同一枚硬币的两面。LLM倾向于更重视它最先读到(Primacy)和最后读到(Recency)的信息。如果开头的文档片段存在误导性,可能会为整个生成过程定下错误的基调。
- 工程影响:一个相关性得分不高、但因为某种随机性被排在第一位的Chunk,可能会对最终答案产生不成比例的巨大影响,造成“上下文污染”。
1.3 缺陷三:对“噪声”和“结构”的敏感性
- 噪声敏感:LLM的推理能力会被上下文中的无关信息(噪声)所稀释。如果10个Chunks里有3个是低质量或不相关的,LLM不仅需要耗费额外的“算力”去甄别它们,还可能被它们误导。
- 结构敏感:LLM并非一个简单的“词袋”处理器。它对输入的格式和结构有着惊人的理解力。一段用Markdown标题和列表组织得井井有条的上下文,比一段杂乱无章的纯文本,能让LLM更好地理解信息的主次和层次关系。
架构师洞察: 上下文工程的全部意义,就是正视并主动管理LLM的这些“认知缺陷”。我们不能再天真地假设LLM是一个完美的逻辑机器。相反,我们必须像一个优秀的教师或沟通者那样,通过精心组织和呈现信息,来引导LLM的“注意力”,弥补其“记忆缺陷”,并最大化其“理解能力”。这是一种从“喂数据”到“教模型”的思想转变。
第二部分:上下文工程的四大核心操作
一个完整的上下文工程流水线,可以分解为四个连续的核心操作:精选、排序、呈现、压缩。

2.1 操作一:精选 (Selection & Re-ranking)——确保进入上下文的是“真金”
在我们的混合检索流程中,我们已经通过并行检索和RRF融合,得到了一个初步的、可能包含几十个文档的候选列表。但这个列表的排序依据(如BM25得分、向量相似度)仍然是相对粗糙的。
**重排序 (Re-ranking)**是精选的核心手段。
核心思想:使用一个更强大、更精确但计算量也更大的模型,对初步召回的候选集进行二次“精加工”,只选出真正与查询高度相关的“黄金”文档。
技术实现:
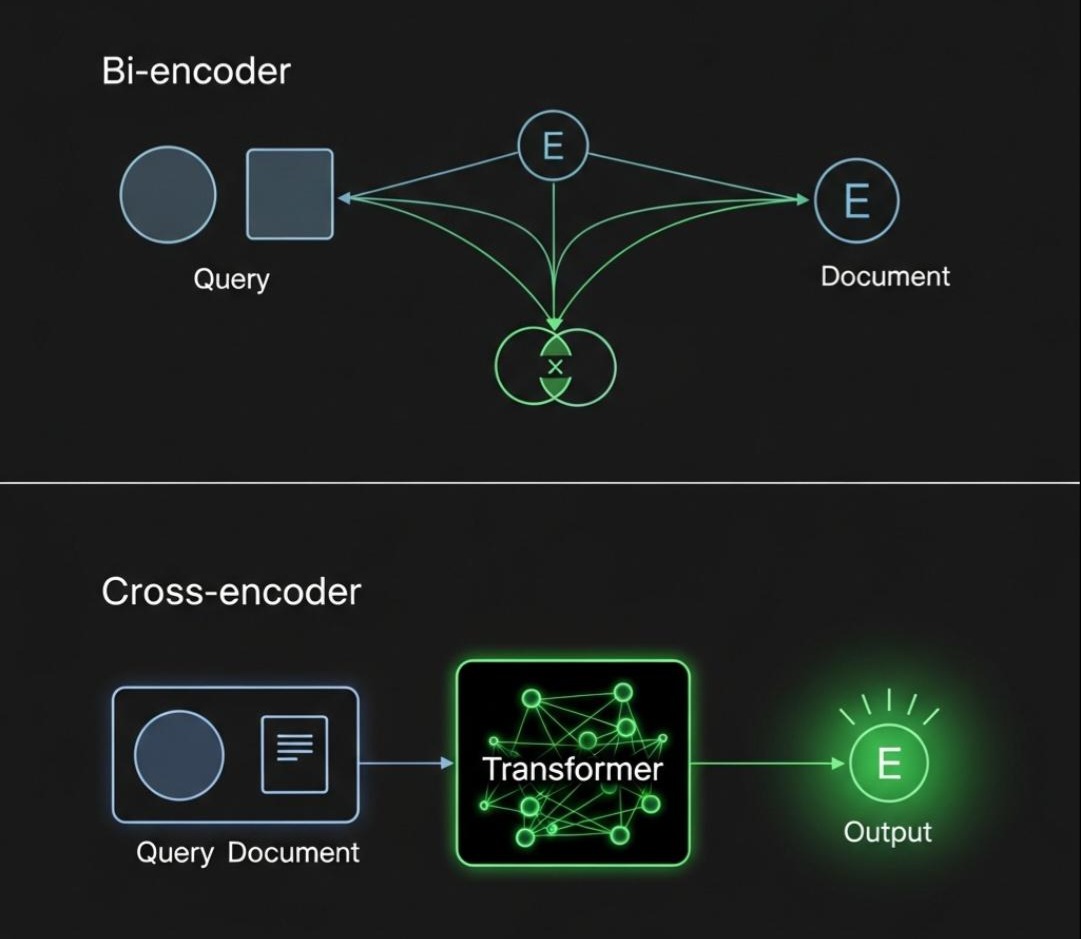
交叉编码器 (Cross-encoder):这是重排序的SOTA技术。与在检索阶段使用的双编码器(Bi-encoder,将查询和文档分开编码)不同,交叉编码器会将查询和每个候选文档拼接在一起(例如,用**[SEP]**分隔),然后作为一个整体输入到Transformer模型中。
为什么更准? 因为交叉编码器允许模型在每一层都进行深度的、细粒度的注意力交互,能够捕捉到查询词与文档中特定词汇之间的复杂关联,其判断相关性的精度远高于仅依赖单个向量的“距离计算”。
业界代表:Cohere Rerank API, 以及开源的bge-reranker-large等模型。
Java实战中的集成思考:
与OCR服务类似,Reranker模型通常也通过一个独立的微服务来提供。Java后端在获得融合后的文档列表后,将查询和文档列表发送给Reranker服务,获取一个带有更高精度分数的新列表。
1 | // 概念性Java代码 |
- 工程权衡:重排序是一次典型的**“计算换精度”**的交易。它会增加几十到几百毫秒的延迟,但能极大地提升注入LLM的上下文信噪比,从而显著降低幻觉,提升答案质量。对于大多数对答案质量有要求的RAG应用,这笔“投资”是极其划算的。
2.2 操作二:排序 (Ordering)——对抗“中间遗忘”的策略艺术
经过精选后,我们得到了一个高质量的Top-K(例如,Top-5)文档列表。现在,我们应该以什么顺序将它们呈现给LLM?简单地按重排分数从高到低排列,恰恰最有可能让次重要的信息落入“中间遗芳”的陷阱。
**“两端置顶”策略 (Lost-in-the-Middle Mitigation Strategy)**是一种被广泛验证的有效方法。
核心思想:既然LLM对开头和结尾最敏感,那我们就把最重要的信息放在这两个位置。
实现方式:
- 获取经过重排序的Top-K文档列表。
- 将得分最高的文档放在上下文的最开始。
- 将得分第二高的文档放在上下文的最末尾。
- 将其余的文档(第三、第四…)夹在中间。
Java伪代码:
1 | public String buildOptimalContext(List<Document> sortedDocs) { |
- 效果:这种简单的顺序调整,能够以零成本的方式,显著提升LLM对关键信息的利用率。
2.3 操作三:呈现 (Formatting)——为LLM提供“阅读指南”
我们应该给LLM一堆纯文本,还是一个结构化的文档?答案是后者。为上下文增加结构,就像为一本书添加章节标题和目录,能极大地帮助LLM理解信息的主次和关联。
核心思想:利用LLM对XML、JSON、Markdown等结构化格式的天然理解力,来引导其注意力。
有效策略:
- 使用XML标签包裹:这是Anthropic公司在研究中力推的方法,效果显著。将每个文档块用**…**这样的标签包裹起来。
- 注入元数据:将每个Chunk的元数据(如来源文件名、页码、作者、日期)一并注入上下文中。这不仅能帮助LLM理解信息的出处,还能让它在生成答案时进行引用(Citation)。
- 明确的角色指令:在Prompt的开头,明确告诉LLM它将要阅读的文档结构和它需要扮演的角色。
结构化Prompt示例:
1 | 你是一个严谨的AI助手,你的任务是根据下面提供的、由<document>标签包裹的多个文档,来回答用户的问题。在回答时,你必须引用你所依据的文档索引号,例如 `[doc 1]`。 |
- 架构收益:结构化呈现,是一种几乎零成本,但收益巨大的优化。它将上下文从“信息的堆砌”变成了“知识的陈列”,显著提升了答案的忠实度(Faithfulness)和可追溯性(Traceability)。
2.4 操作四:压缩 (Compression)—在信息过载时的最后一道防线
即使经过了精选,有时多个高质量的文档块加起来,仍然可能超过上下文窗口的限制,或者我们希望为了降低成本而主动减少Token数。此时,就需要上下文压缩技术。
核心思想:在不损失核心语义的前提下,对上下文进行有损压缩。
技术实现:
- LLMLingua:这是一个代表性的框架。它的核心思想是利用一个小型LLM(如GPT-2 Small)来识别和移除上下文中的“非必要词汇”(例如,停用词、客套话、重复描述)。它通过计算每个词对于整体语义的“困惑度(Perplexity)”来决定哪些词可以被安全地移除。
- 选择性压缩:更精细的策略是,只对相关性得分较低的文档块进行压缩,而保持最高分文档的原汁原味。
工程权衡:
- 优点:能有效减少Token数,降低成本,并可能因为提升了信噪比而略微提升性能。
- 缺点:压缩过程本身是有损的,存在丢失关键信息的风险。同时,压缩过程也需要额外的计算时间。
- 适用场景:上下文压缩更像是一个“保险丝”或“降级”策略,在上下文长度即将溢出,或成本压力巨大时启用。它不应被用作常规流程中的首选优化手段。
结语:从“喂数据”到“教模型”—上下文工程的价值升华

在本篇中,我们完成了RAG流程中至关重要的“最后一公里”——上下文工程。我们不再天真地将LLM视为一个完美的逻辑机器,而是正视其“认知缺陷”,并像一个优秀的沟通者一样,通过一系列精巧的工程手段来引导和赋能它。
我们通过精选(Re-ranking),确保了喂给LLM的是最高质量的“精神食粮”。
我们通过**排序(Ordering)**的艺术,巧妙地规避了LLM的“中间遗忘”陷阱。
我们通过**呈现(Formatting)**的结构化技巧,为LLM提供了清晰的“阅读指南”,提升了答案的忠实度与可追溯性。
我们将**压缩(Compression)**定位为一种在资源受限时的战略性降级手段。
上下文工程的实践,标志着我们与LLM交互模式的一次深刻升华:从被动地“喂数据”,到主动地“教模型”如何思考。它要求我们不仅要懂检索,更要懂LLM的“脾气秉性”,将认知科学的洞察融入到工程设计之中。
至此,我们已经走完了构建一个高质量RAG流水线的所有核心技术环节:从意图理解,到文档解析,再到数据处理,历经三路检索,最终完成了上下文的精细打磨。一个强大的知识引擎已初具雏形。
然而,一个新的问题浮出水面:我们如何科学地、量化地知道我们所做的这一切优化,是真的有效,还是仅仅是“工程师的自我感动”?当业务方问你“这次上线的RAG版本,性能到底提升了多少?”时,你该如何作答?
在下一篇章 《RAG的“进化飞轮”:从自动化评估(RAGAs)到人工反馈闭环(Human-in-the-loop)》 中,我们将深入“七层模型”的最后一层——生成与评估层。我们将学习如何搭建一套完整的RAG评估体系,从使用RAGAs等框架进行自动化、可重复的离线评估,到设计高效的人工反馈闭环,让我们的RAG系统拥有真正的、可持续的“进化能力”。