RAG篇(9):RAG的“进化飞轮”:从自动化评估(RAGAs)到人工反馈闭环(Human-in-the-loop)
导语:你的RAG系统,是在“进化”还是在“退化”?
让我们回到那个既熟悉又令人焦虑的场景:
你和团队经过数月的鏖战,成功上线了一个集成了混合检索、GraphRAG、上下文工程等各种“屠龙之术”的V2.0版RAG系统。在精心准备的测试集上,它的表现完美无瑕。然而,系统上线一周后,业务方的反馈却让你如坐针毡:“感觉……好像还不如上个版本好用?”、“为什么昨天还能回答对的问题,今天就胡说八道了?”
你陷入了“工程师的噩梦”:你无法量化地证明你的“改进”是真的改进,也无法定位问题到底是出在数据更新、检索模块,还是LLM的随机性上。你对系统的性能评估,还停留在几个“精选案例”和模糊的“体感”上。你的开发过程,变成了一场无法衡量、无法复现、充满玄学的“炼丹”。
这就是绝大多数RAG项目最终走向失败的根本原因:它们缺少一个持续、客观、量化的评估体系,以及一个能够将生产环境的“真实反馈”转化为系统“进化养料”的闭环机制。 没有度量,就无法优化;没有反馈,就无法进化。一个没有“进化飞PEP轮”的RAG系统,其宿命必然是从“上线即巅峰”,在数据的不断变更和用户需求的多样化冲击下,逐渐熵增,最终退化成一个没人敢信、没人愿用的“数字垃圾堆”。
本篇,我们将深入RAG七层架构的最后一层,也是决定其生命力的关键一层——生成与评估层。我们将学习如何搭建一套完整的RAG评估体系,彻底告别“感觉不错”的直觉式开发。我们将分为两大战场:
离线战场:如何使用RAGAs等前沿框架,建立自动化、可重复的离线评估流水线,为你的每一次迭代提供科学、量化的“成绩单”。
在线战场:如何设计高效的人工反馈闭环(Human-in-the-loop),捕获生产环境中最有价值的用户反馈,并将其转化为驱动Embedding、Reranker甚至LLM模型持续微调的“黄金数据”。
这篇文章将为你提供一套从“质检”到“进化”的完整方法论。它将帮助你为你的RAG系统装上“仪表盘”和“导航仪”,让每一次优化都有的放矢,让整个系统拥有真正的、可持续的生命力。
第一部分:离线评估—为RAG系统建立“体检标准”
在将任何新版本的RAG系统推向生产之前,我们必须在受控环境中,对其进行一次全面的、可量化的“体检”。这就是离线评估的意义。
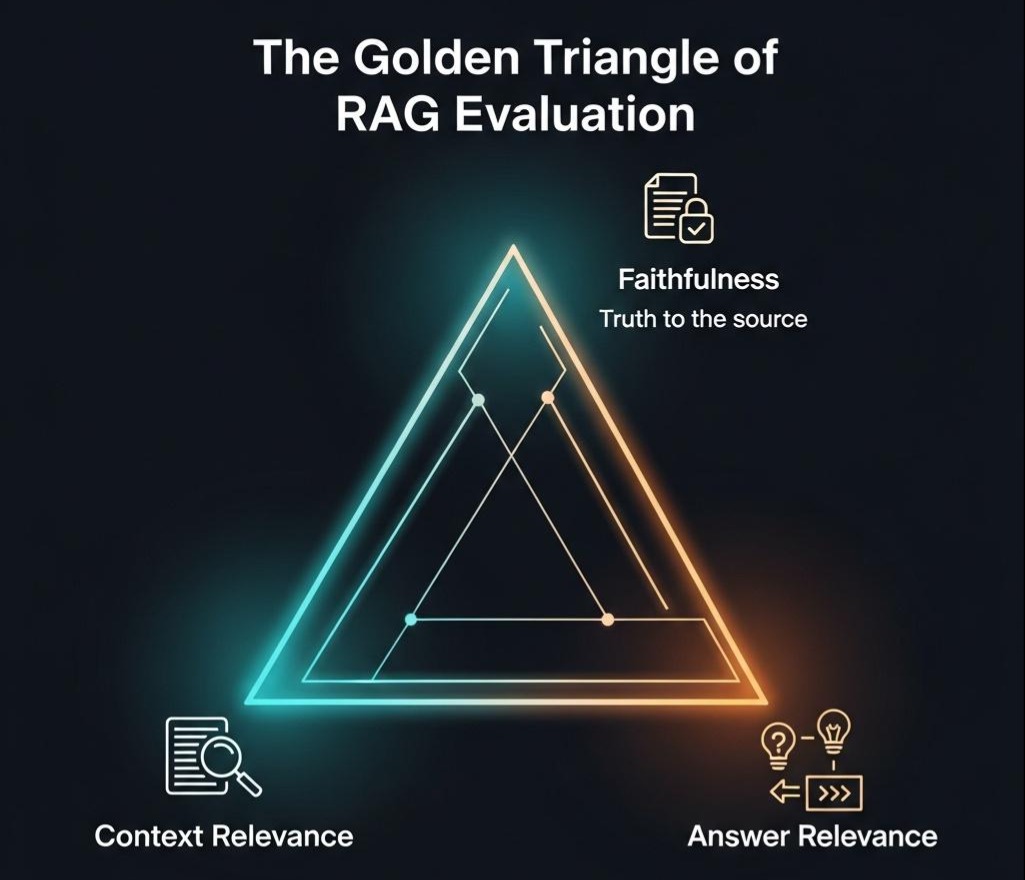
1.1 告别“感觉不错”:RAG评估的“黄金铁三角”
传统的NLP评估指标,如BLEU、ROUGE,在LLM时代已经基本失效。它们只能衡量生成文本与参考答案之间的“字面重合度”,而无法评估答案的“事实准确性”和“逻辑合理性”。
针对RAG的特性,业界逐渐形成了一套更为科学的评估维度,我们称之为**“黄金铁三角”**:
答案的忠实度 (Faithfulness)
核心问题:生成的答案是否完全基于所提供的上下文?它有没有“添油加醋”或“凭空捏造”(即幻觉)?
重要性:这是RAG系统最核心的价值主张。 一个不忠实的答案,比一个“我不知道”的答案更具危害性。
评估方法:利用LLM作为裁判。提取答案中的每一个论点,然后让LLM判断这个论点是否能被给定的上下文所支持。
上下文的相关性 (Context Relevance)
核心问题:检索到的上下文,是否真的与用户的问题相关?有多少是“噪声”?
重要性:衡量检索模块的性能。低相关性的上下文是导致答案质量下降和成本浪费的根源。
评估方法:同样利用LLM作为裁判。让LLM逐句分析上下文,判断每一句话对于回答原始问题是否有用。
答案的相关性 (Answer Relevance)
核心问题:最终生成的答案,是否直接、有效地回答了用户的问题?它有没有“答非所问”?
重要性:衡量整个RAG系统的端到端用户体验。
评估方法:让LLM判断生成的答案与用户原始问题之间的相关性。这通常需要将问题和答案一起Embedding后计算相似度,或者直接进行LLM-based的打分。
架构师洞察: “忠实度”和“上下文相关性”是白盒指标,它们帮助我们诊断系统内部(检索、生成环节)的问题。而“答案相关性”是黑盒指标,它直接反映了最终用户的感受。一个健康的评估体系,必须同时包含这两类指标。
1.2 RAGAs:自动化评估的“瑞士军刀”
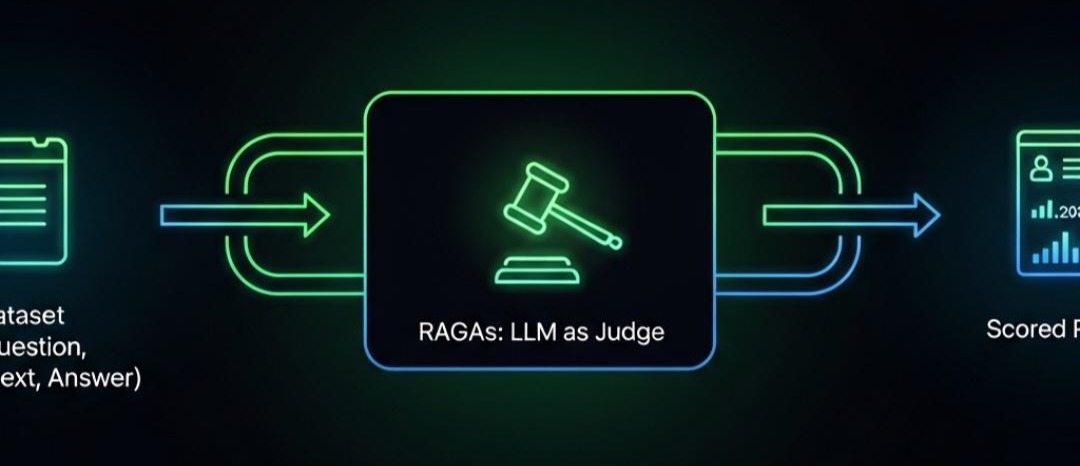
手动评估上述指标既耗时又主观。**RAGAs (RAG Assessment)**等框架的出现,革命性地解决了这个问题。
核心思想:Leveraging LLMs to Evaluate LLMs。利用GPT-4等强大LLM的推理能力和常识,来自动化地、可重复地为“黄金铁三角”进行打分。
工作流程:
- 准备评估数据集:你需要一个包含question、ground_truth(标准答案)的数据集。在RAG流程运行后,你还能得到retrieved_context和generated_answer。
- 调用RAGAs进行评估:RAGAs会自动构建一系列精巧的Prompt,将上述信息组合起来,发送给一个作为“裁判”的LLM(如OpenAI或Azure OpenAI模型),并解析其返回的分数(通常在0-1之间)。
- 生成评估报告:最终得到一个包含各项指标得分的综合报告。
Java生态中的集成:虽然RAGAs主要是Python库,但在Java架构中集成它的思路与OCR、Reranker类似:将其封装为一个评估微服务。
- Java端:在CI/CD流水线中,当一个RAG版本构建完成后,自动触发一个评估任务。Java后端负责准备好评估数据集(包含问题、上下文、答案等),并将其通过REST API发送给Python端的RAGAs评估服务。
- Python端:一个简单的FastAPI或Flask应用,接收数据,调用RAGAs库执行评估,并将最终的JSON格式评估报告返回。
1 | // Java端,触发评估的概念性代码 |
1.3 评估数据集的构建:从“人工标注”到“AI合成”
自动化评估框架解决了“如何评”的问题,但“用什么评”(评估数据集)的挑战依然存在。
传统方法:人工标注
由领域专家或测试人员,针对关键业务场景,编写高质量的question-ground_truth对。
- 优点:质量最高,最贴近真实业务。
- 缺点:成本高昂,耗时,难以大规模覆盖。
前沿方法:利用LLM合成评估数据
LlamaIndex等框架提供了合成数据集的工具。其基本思路是:
- 从你的文档库中随机抽取一些文本块(Chunks)。
- 将每个文本块喂给一个强大的LLM(如GPT-4)。
- Prompt 1: “请你扮演一个可能会对以下文本内容感兴趣的用户,并根据这段内容,提出一个具体的问题。问题:…” -> 得到question。
- Prompt 2: “请根据以下文本内容,用你自己的话总结出一个简短的答案,以回答问题:’{question}’。答案:…” -> 得到ground_truth。
优点:可以低成本、快速地生成大规模的评估数据集。
缺点:合成数据的质量依赖于LLM的能力,可能存在多样性不足或与真实用户问题偏差的问题。
工程实践:最佳策略是**“双管齐下”。使用一个由核心业务场景构成的人工标注的核心集**(例如100-200个问题),作为每次版本发布的“冒烟测试”,确保核心功能不退化。同时,使用一个由AI合成的大规模数据集(例如1000-5000个问题),用于更全面的性能回归测试和发现边缘案例。
第二部分:在线反馈—构建RAG系统的“进化飞轮”
离线评估保证了上线的“质量底线”,而在线反馈则决定了系统能否在真实世界中“持续进化”。
2.1 捕获信号:设计高效的人工反馈机制 (Human-in-the-loop)
我们需要在应用的用户界面上,巧妙地设计一些机制,来捕获用户对答案质量的“隐式”和“显式”反馈。
显式反馈:
- 点赞/点踩 (Thumbs Up/Down):这是最简单、用户最愿意提供的反馈。一个“点踩”就是一个强烈的负样本信号。
- 评分 (Rating):提供1-5星的评分,可以获得更细粒度的反馈。
- 修正意见 (Correction/Suggestion Box):在答案旁边提供一个文本框,允许不满意的用户直接输入他们期望的正确答案,或指出当前答案的问题。这是质量最高的反馈数据。
隐式反馈:
- 复制行为:用户是否复制了生成的答案?这通常是一个强烈的正信号。
- 追问行为:用户在得到答案后,是结束了对话,还是继续追问“你说的这个不对…”或“换个方式说”?后者通常是负信号。
- 会话时长/轮次:一个简短、高效的对话,比一个冗长、反复拉锯的对话,更能说明答案的质量。
2.2 数据闭环:将反馈转化为“进化养料”
捕获到反馈信号后,我们必须建立一个自动化的数据流水线,将其处理并应用到模型的再训练中。
数据收集与清洗:
所有反馈数据,连同其对应的query, retrieved_context, generated_answer等完整链路信息,都应被记录到专门的数据库或数据湖中。
需要对数据进行清洗,例如,过滤掉恶意的或无意义的反馈。
构建再训练数据集:
对于Embedding模型微调:
一个被“点赞”或“复制”的答案,其对应的query和retrieved_context可以构成一个高质量的正样本对。
一个被“点踩”的答案,其retrieved_context可以作为query的硬负例(Hard Negative)。
用户提供的“修正意见”,可以用来生成更精准的query-positive_context对。
对于Reranker模型微调:
我们可以构建一个包含**(query, positive_passage, negative_passage)的三元组列表。其中positive_passage**是最终被证明有用的上下文,negative_passage是用户反馈不满意的上下文。
触发模型再训练:
当收集到的高质量反馈数据达到一定数量时(例如,1000个新的“点踩”样本),可以自动触发一个模型微调的CI/CD Job。
微调完成后,新模型进入离线评估流水线。只有当其在核心评估集上的表现显著优于当前生产环境中的模型时,才会被部署上线。
这个**“在线收集 -> 离线训练 -> 离线评估 -> 上线部署”**的循环,就是RAG系统的“进化飞轮”。
2.3 Java架构中的实现思考
1 | / Java后端,处理用户反馈的Controller示例 |
架构师权衡: 构建一个完整的人工反馈闭环,是一项复杂的系统工程,它涉及前端埋点、后端服务、数据流水线、模型训练平台等多个部分。对于初创项目,可以从最简单的“点赞/点踩”数据收集开始,即使暂时没有能力进行模型再训练,这些数据本身对于分析系统弱点、指导人工优化也具有巨大的价值。不要追求一步到位,而要先让“飞轮”转起来。
结语:从“交付系统”到“培育生命”

在本篇中,我们完成了RAG系统构建之旅的最后、也是最关键的一环——评估与迭代。我们不再仅仅是一个“建设者”,更成为了一个“园丁”和“教练”。
我们学会了使用RAGAs等自动化工具和科学的**“黄金铁三角”指标,为我们的系统建立了严格的、可量化的离线“体检”标准**。这让我们有能力在上线前,就对系统的质量做出客观判断。
我们设计了从显式反馈到隐式信号的捕获机制,并规划了如何将这些来自真实战场的“弹药”,转化为驱动模型持续微调的在线“进化飞轮”。
掌握了评估与迭代的方法论,意味着我们对RAG系统的认知,已经从**“交付一个一次性的软件项目”,升华到了“培育一个可持续进化的智能生命”**。这个“生命”能够感知用户的反馈,从错误中学习,并随着时间的推移变得越来越聪明、越来越可靠。
至此,我们已经系统性地走完了RAG七层架构的每一个核心环节。一个技术上完备、且具备进化能力的知识引擎,其理论蓝图已经清晰地展现在我们面前。
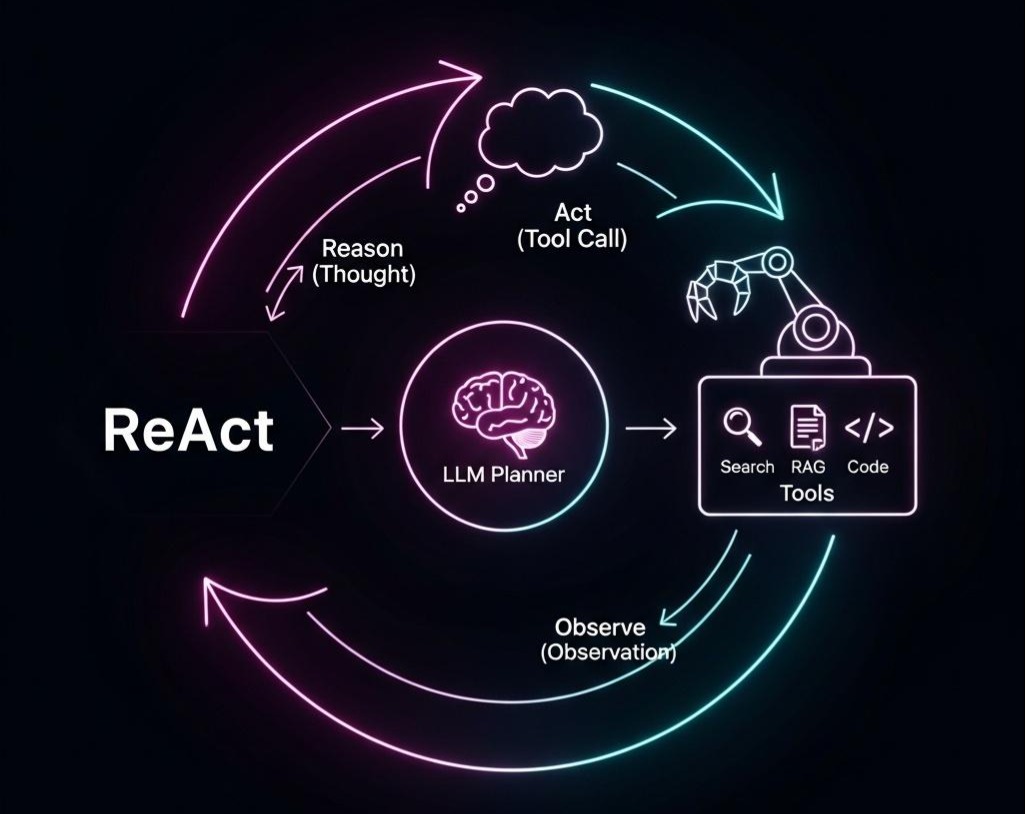
然而,RAG只是更大图景的一部分。在许多复杂的场景中,我们需要的不仅仅是一个“问答专家”,而是一个能够使用多种工具、执行多步任务的“行动者”——智能体(Agent)。
在下一篇章 《Agentic RAG的黎明:当RAG拥有“规划”能力,从“问答机”到“研究助理”的进化》 中,我们将把视野再次拉高,探讨RAG如何与Agent范式进行终极的融合。我们将学习如何为我们的RAG系统装上“大脑”,引入“规划器(Planner)”的角色,让它从一个被动的“问答机”,进化为一个能够主动思考、规划、行动和反思的“研究助理”。这将是通往下一代AI应用的激动人心的起航。