Agent篇(15):编排治理层 (Layer 7) —— 上帝视角:全链路追踪、成本监控与自动化评估体系

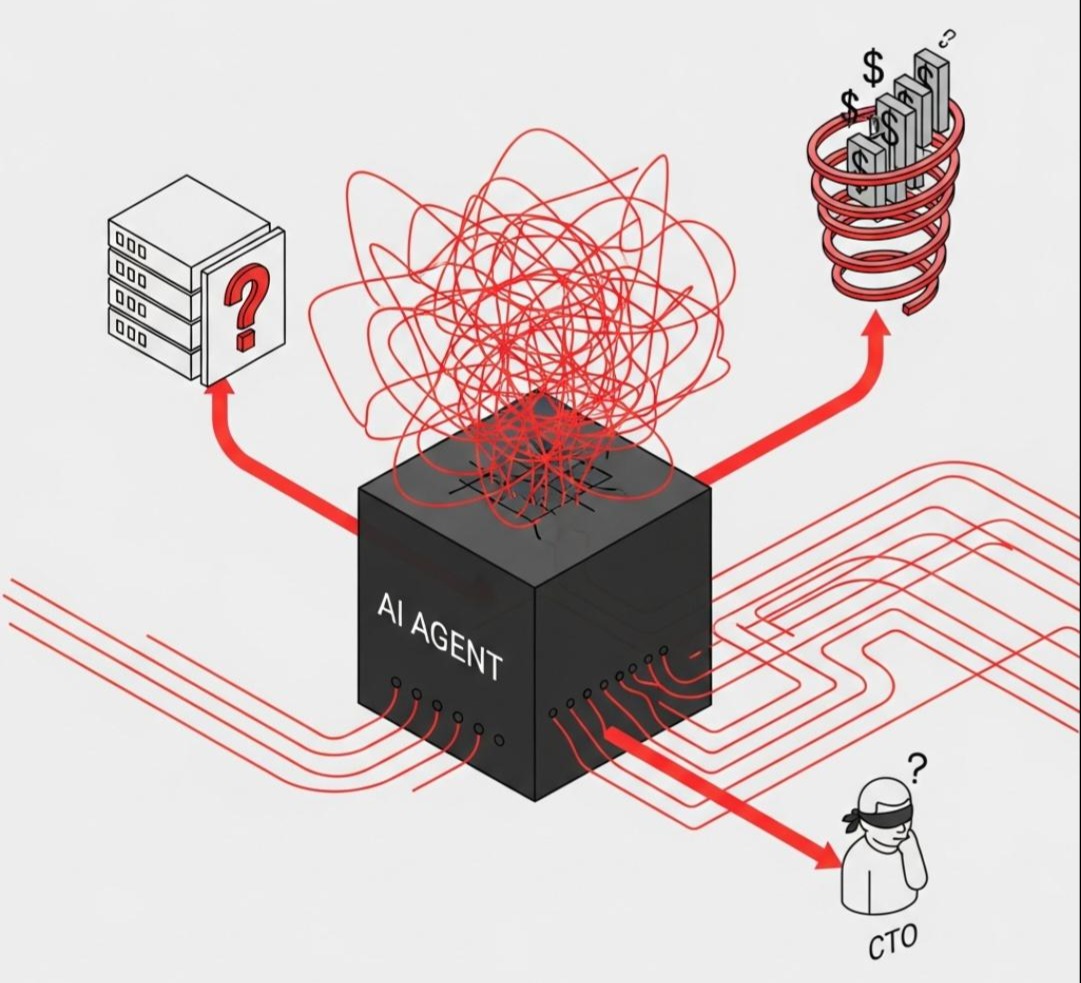
导语:CFO 的愤怒
月末,财务总监(CFO)拿着一张 $50,000 的 OpenAI 账单冲进了 CTO 的办公室。
“谁能解释一下,为什么上个月 Token 费用翻了十倍?是哪个业务线跑出来的?是那个写诗的 Bot,还是那个查报表的 Bot?”
没人能回答。
大家面面相觑。后端工程师只能看到日志里满屏的 200 OK。
我们知道系统在跑,但我们不知道它在裸奔。
- 盲区一: 你不知道一个简单的“帮我查下这周数据”,背后 Agent 到底循环了多少次,调用了多少次 GPT-4。
- 盲区二: 你不知道昨天上线的那个 Prompt 优化,到底是让 AI 变聪明了,还是变傻了。没有单元测试,只有“体感”。
- 盲区三: 某个用户恶意刷量,你的系统还在傻乎乎地陪聊,直到把预算烧光。
这就是缺乏治理的代价。
在 L7 编排治理层 (Orchestration & Governance Layer),我们要为这个黑盒装上 CT 扫描仪。我们要把每一次思考、每一个 Token、每一分钱,都映射到可视化的大屏上。
第一部分:第一性原理——从日志到链路 (From Logs to Traces)
传统的 log.info("start processing") 在 Agent 系统里是废纸。
因为 Agent 的执行是非线性的:有嵌套(L2 调 L3)、有循环(L4 Loop)、有并发(Map-Reduce)。
我们需要的是 分布式追踪 (Distributed Tracing)。
我们要把一次用户请求,看作是一个 Trace;把其中的每一次 LLM 调用、每一次工具执行、每一次 RAG 检索,看作是一个 Span。
L7 层铁律: 不可视,不优化。
第二部分:全链路追踪——用 OpenTelemetry 照亮黑盒
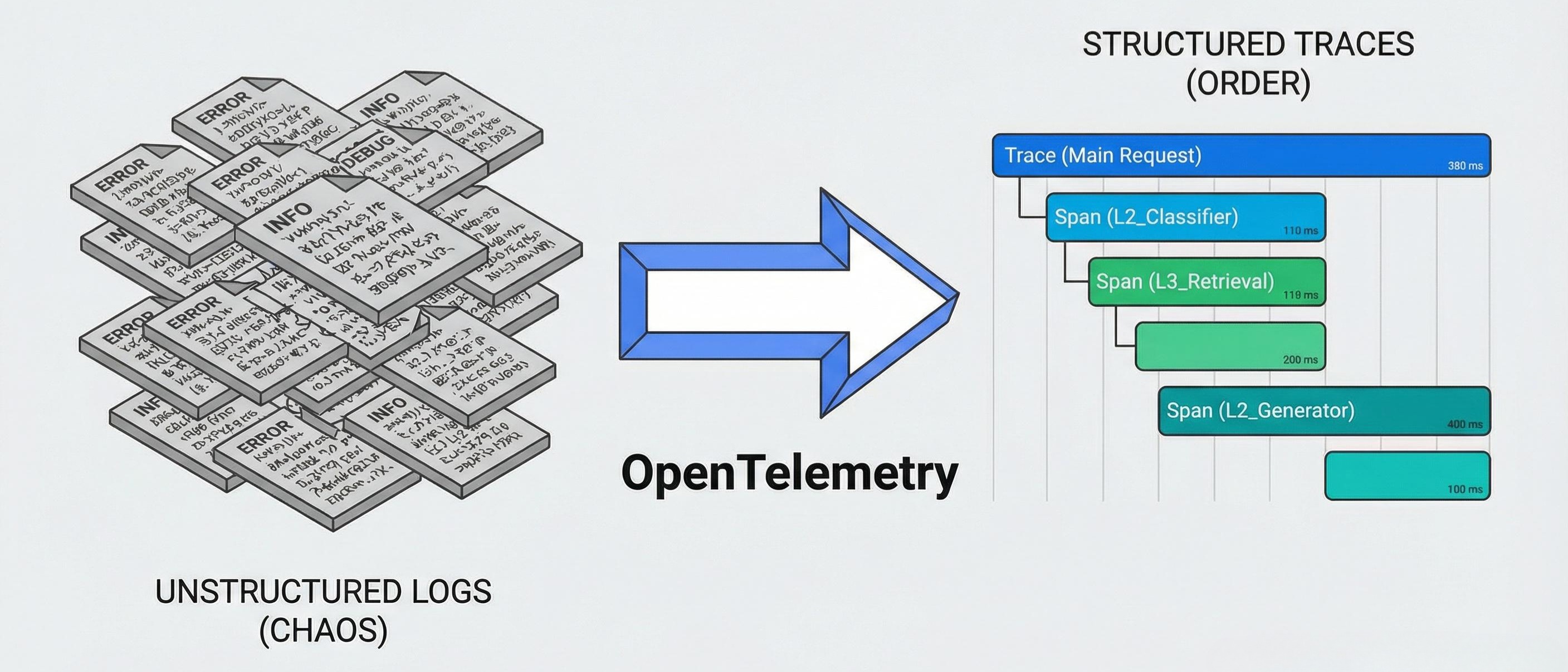
业界标准是 OpenTelemetry (OTel)。我们需要将 Agent 的内部状态映射到 OTel 的语义中。
2.1 显微镜下的 Span 设计
一个标准的 LLM Span 必须包含以下 Attribute(属性):
llm.model: “gpt-4-turbo”llm.prompt_tokens: 1200llm.completion_tokens: 300llm.temperature: 0.7gen_ai.system: “OpenAI”
2.2 Java 核心实现:自动埋点
不要在业务代码里到处写 span.start()。我们要利用 AOP (面向切面编程) 或 Java Agent 字节码注入。
1 |
|
可视化效果:
当我们在 Jaeger 或 LangSmith 中打开这个 Trace 时,我们会看到一个精美的瀑布图:
[Total: 5.2s] User Request[300ms] L1_Template_Render[2.1s] L2_Intent_Classifier (GPT-3.5)[1.8s] L3_RAG_Retrieval[50ms] Vector_Search[150ms] Rerank[800ms] L2_Generator (GPT-4)
这一刻,黑盒变成了白盒。你可以一眼看出:哦,原来是 RAG 的 Rerank 步骤拖慢了整体速度。
第三部分:成本监控——Token 计费学 (Tokenomics)
Token 就是钱。L7 层必须做一个精明的会计。
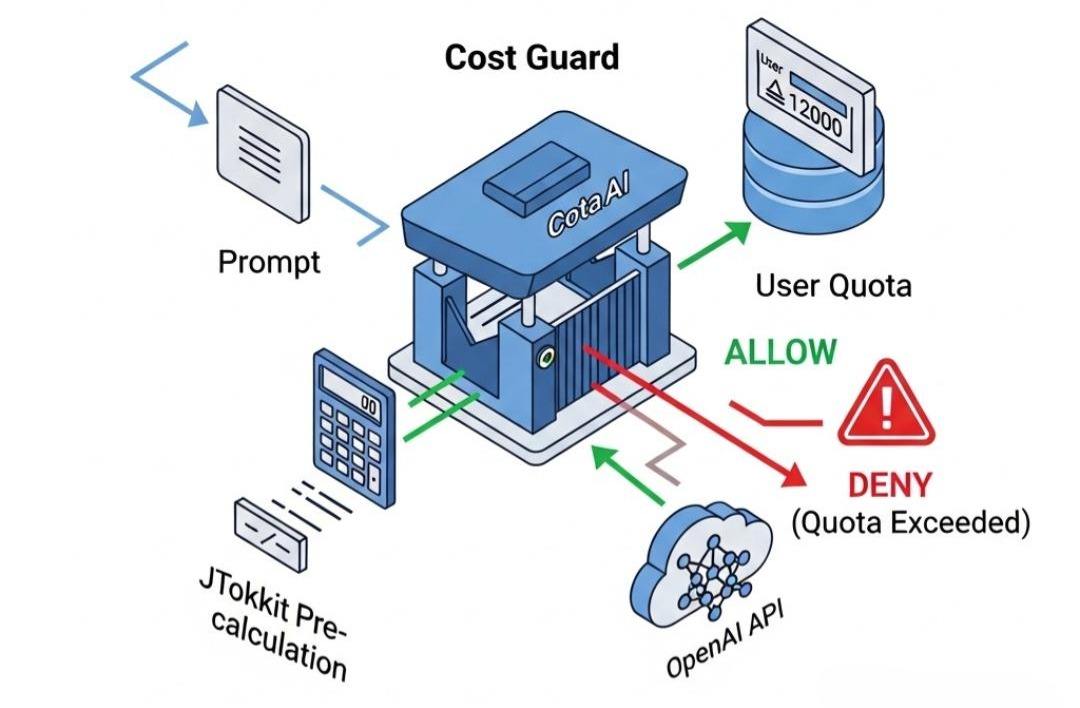
3.1 痛点:事后诸葛亮
很多系统是月底看账单才知道超支了。我们需要实时成本计算。
3.2 演进:JTokkit 预计算与配额熔断
在发送请求给 OpenAI 之前,我们就要在本地算出这个 Prompt 会消耗多少 Token。
Java 实现:
1 | public class CostGuard { |
架构师策略:
对于内部员工,设置 Soft Limit(报警);对于外部用户,设置 Hard Limit(阻断)。
同时,监控 Input/Output Ratio。如果一个 Agent 总是输入 10k Token 却只输出 “OK”(2 Token),这说明 Prompt 效率极低,需要优化。
第四部分:自动化评估 (Evaluation) —— 给 AI 打分
这是 L7 层最难、也最高级的部分。
软件工程有 Unit Test,只要 Assert 1+1=2 即可。
但 AI 工程怎么测试?Assert GPT("写首诗") == "..."?这是不可能的。
4.1 痛点:凭感觉上线
改了 Prompt,觉得“好像变好了”,直接上线。结果导致特定场景下的回复质量雪崩。
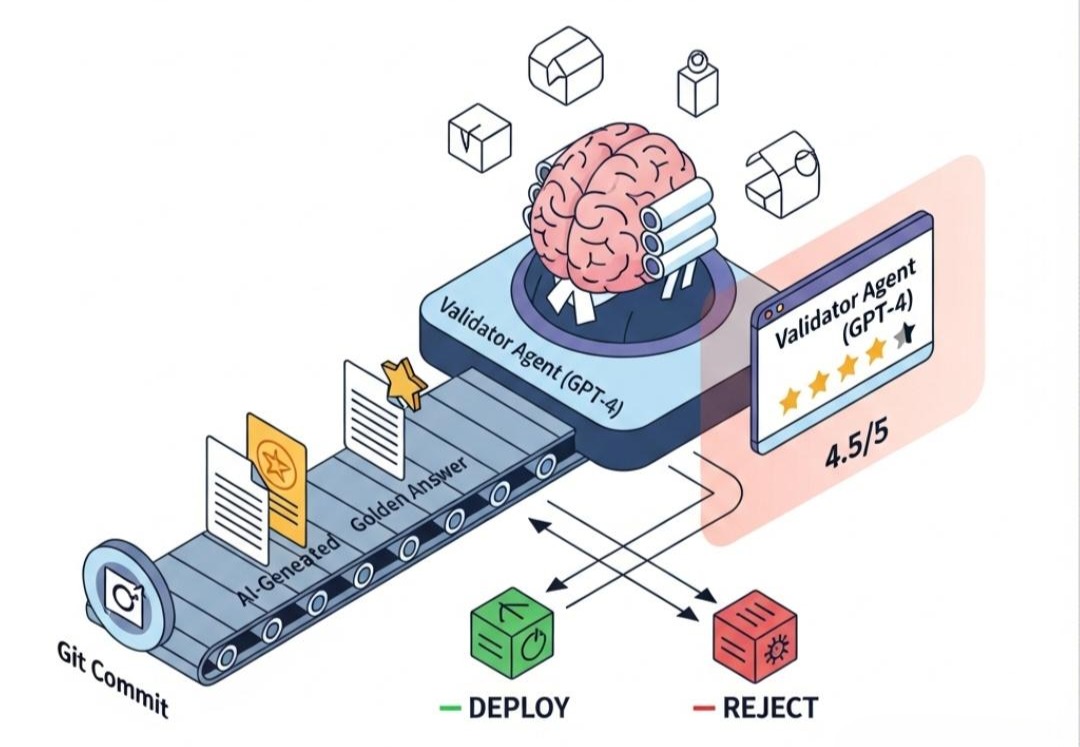
4.2 演进:LLM-as-a-Judge (让 AI 评价 AI)
我们构建一条自动化评估流水线。
- 构建黄金数据集 (Golden Dataset):
收集 100 个历史真实的高质量问答对:{question: "...", expected_answer: "..."}。 - 回归测试 (Regression Test):
每次代码/Prompt 变更,自动触发 CI/CD,跑这 100 个 Case。 - 裁判打分 (Validator Agent):
让 GPT-4 充当裁判,对比actual_output和expected_answer。
评估器 Prompt 设计:
1 | 你是一名公正的考官。 |
架构实现:
在 Jenkins/GitLab CI 中集成这个流程。如果平均分低于 4.0,禁止上线。
这标志着 AI 开发从“炼丹术”走向了“工业化”。
架构师的权衡 (The Architect’s Trade-off)
- 采样率 (Sampling Rate) vs 成本:
全链路追踪数据量巨大。如果 QPS 很高,Trace 数据可能会撑爆 ElasticSearch。
- 权衡: 生产环境采用 1% 采样,或者 Head-Based Sampling(只记录报错的 Trace 和耗时超过 5s 的 Trace)。
- 隐私 (Privacy) vs 可调试性:
Trace 中包含了用户的 Prompt 和 AI 的回答。如果包含敏感数据(如身份证号),这是严重的合规事故。
- 权衡: 在 OTel 的 Exporter 层增加 PII Masking (隐私脱敏) 过滤器。把
13800138000替换为[PHONE],虽然牺牲了部分调试便利性,但保住了合规底线。
结语:通天塔建成
至此,我们的七层架构蓝图终于完整拼合。
- L1 原子层:奠定了 Java 的确定性基石。
- L2 算子层:封装了 LLM 的认知能力。
- L3 增强层:接通了世界的知识与工具。
- L4 控制层:编排了复杂的逻辑迷宫。
- L6 状态层:战胜了时间的遗忘。
- L5 交互层:学会了与人类共情。
- L7 治理层:开启了上帝的视角。
这不再是一个简单的 Python 脚本,也不是一个玩具 Demo。
这是一座工业级的通天塔。它是健壮的、可观测的、可扩展的、安全的。
它可以部署在世界 500 强的生产环境中,每天处理数百万次复杂的业务请求,而不会让 CTO 担心明天系统会崩溃,或者 CFO 担心明天公司会破产。
The Next Step:
理论的征途已到终点,但工程的征途才刚刚开始。
纸上得来终觉浅,绝知此事要躬行。
在接下来的 《实战篇》 中,我们将把这七层架构的所有代码片段,拼装成一个完整的、可运行的**“企业级智能标书生成系统”**。我们将亲手从 File -> New Project 开始,见证这套架构如何在 IDE 里落地生根。
