
RAG篇(8):Context Engineering的终极实践:从信息过载到精准洞察,为LLM打造“完美工作记忆”
Context Engineering终极实践——从信息过载到精准洞察,通过上下文压缩、窗口管理与优先级排序为LLM打造完美工作记忆。

RAG篇(7):GraphRAG协同革命:当“向量”遇上“图”,用Neo4j实现从“入口发现”到“关系推理”
GraphRAG协同革命——将向量检索与Neo4j知识图谱结合,实现从入口发现到多跳关系推理的深度知识挖掘。

RAG篇(6):Elasticsearch的复兴:从BM25到ELSER,构建稀疏-稠密混合检索的“第二大脑”
Elasticsearch在RAG中的复兴——从BM25经典检索到ELSER稀疏向量,构建稀疏-稠密混合检索的第二大脑。

RAG篇(5):深入Milvus:从Embedding微调到HNSW索引调优,构建企业级分布式稠密向量检索系统
深入Milvus向量数据库——从Embedding模型微调到HNSW索引参数调优,构建企业级分布式稠密向量检索系统的完整实践。

RAG篇(4):知识库的“数据供应链”——从高级Chunking到Table表格处理的深水区
RAG七层之分块层——知识库的数据供应链,从语义分块、递归分块等高级Chunking策略到表格Table处理的深水区实践。

RAG篇(3):LLM原生OCR革命——从文字识别到DeepSeek-OCR视觉上下文压缩,深入RAG七层模型之解析层
RAG七层之解析层——LLM原生OCR革命,从传统文字识别到DeepSeek-OCR视觉上下文压缩,实现多模态文档的高质量解析。

RAG篇(2):智能总控的诞生——从意图识别到任务路由,深入RAG七层模型之意图层
RAG七层之意图层——从简单关键词匹配到意图识别与智能任务路由,构建RAG系统的智能总控大脑。
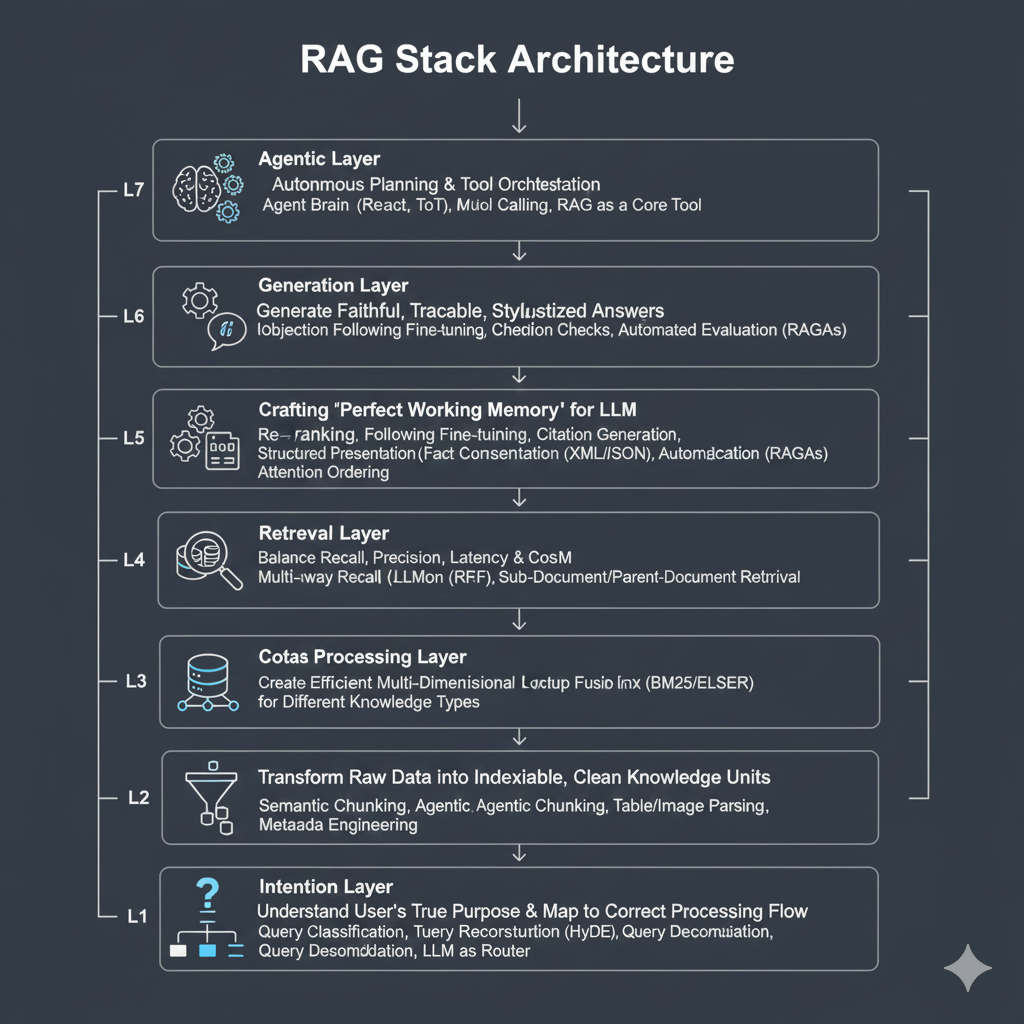
RAG篇(1):RAG的星辰大海——从朴素检索到Agentic范式,重构企业级RAG的七层架构
RAG七层架构总览——从朴素向量检索到Agentic RAG范式,系统性重构企业级RAG的意图层、解析层、索引层、检索层、生成层、评估层与编排层。
企业新基建:MCP + LLM + Agent架构,将打通AI Agent的“神经中枢”
详解MCP模型上下文协议——打破大模型只能说不能做的边界,通过标准化协议让LLM连接数据库、调用API、执行代码,构建企业级AI Agent的神经中枢架构。
构建完全本地的MCP客户端:让AI智能体与数据库无缝对话
实战教程:构建完全本地化的MCP客户端——基于Model Context Protocol让AI智能体直接操作SQLite数据库,实现自然语言到SQL的智能交互。